Mix-MoE: Improving Multilingual Machine Translation of Large Language Models through Mixed MoEs
Pith reviewed 2026-06-30 13:20 UTC · model grok-4.3
The pith
Mix-MoE splits LLM experts into monolingual and translation groups to reduce parameter interference in multilingual MT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
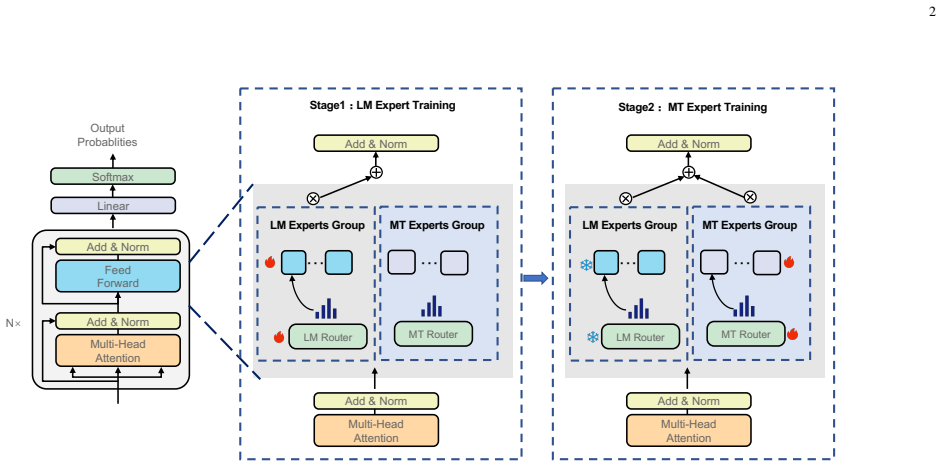
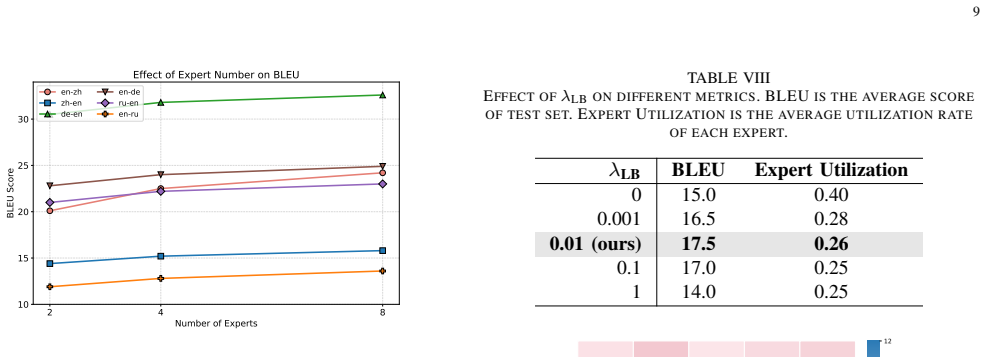
Mix-MoE divides the MoE layers into LM Experts trained solely on monolingual corpora to preserve pre-trained knowledge and MT Experts trained on parallel corpora to learn translation abilities, using a Fourier Transform-enhanced routing mechanism for better expert interaction, leading to improved multilingual MT performance and reduced parameter interference.
What carries the argument
The split of MoE layers into Language Model Experts and Machine Translation Experts combined with Fourier Transform routing.
If this is right
- Multilingual machine translation performance will increase beyond standard fine-tuning methods.
- Parameter interference between monolingual and bilingual training will decrease.
- Models will retain more of their original monolingual capabilities after translation training.
- The Fourier routing will improve how experts are selected based on text structure.
Where Pith is reading between the lines
- This method could extend to other fine-tuning scenarios where general and specialized knowledge need separation.
- Fixed expert groups might be replaced with learned groupings in future versions for more flexibility.
- Similar expert splitting could apply to tasks like multilingual question answering or summarization.
Load-bearing premise
That dividing experts into fixed monolingual and translation groups with Fourier routing will prevent interference without causing new problems or wasting model capacity.
What would settle it
Finding that a Mix-MoE model shows the same degradation in monolingual task performance after parallel data training as a standard fine-tuned model would indicate the claim is not holding.
Figures


read the original abstract
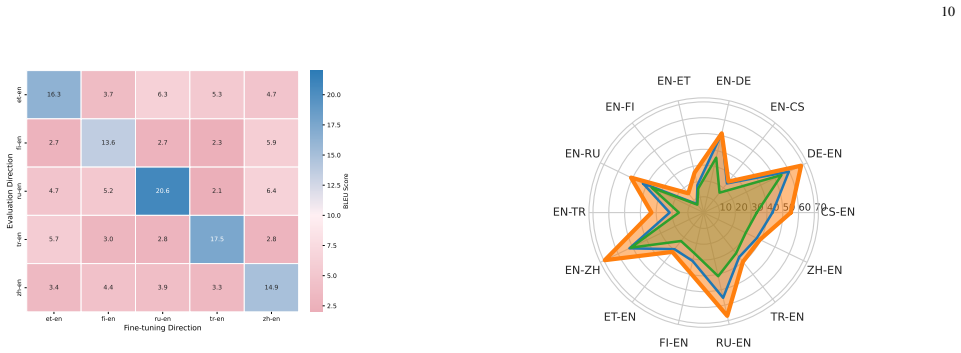
Large Language Models (LLMs) have shown great promise in multilingual machine translation (MT), even with limited bilingual supervision. However, fine-tuning LLMs with parallel corpora presents major challenges, namely parameter interference. To address these issues, we propose Mix-MoE, a mixed Mixture-of-Experts framework designed to train LLMs for multilingual MT. Our framework operates in two distinct stages: (1) post-pretraining with MoE on monolingual corpora, and (2) post-pretraining with MoE on parallel corpora. Crucially, we divide the MoE layers into two specialized groups: Language Model Experts (LM Experts) and Machine Translation Experts (MT Experts). LM Experts are designed to capture and retain the monolingual knowledge learned by the pre-trained LLM. MT Experts, on the other hand, are specifically trained to acquire and store bilingual translation knowledge. Furthermore, to facilitate effective interaction between these specialized experts and leverage potential underlying structural patterns in text, we introduce a routing mechanism enhanced by Fourier Transform features derived from model representations. The experimental results demonstrate that Mix-MoE excels in multilingual MT, significantly outperforming existing baselines and showing notable progress in mitigating parameter interference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mix-MoE, a two-stage post-pretraining Mixture-of-Experts framework for multilingual machine translation in LLMs. Stage 1 applies MoE to monolingual corpora with LM Experts; stage 2 applies MoE to parallel corpora with MT Experts. The MoE layers are partitioned into these two fixed groups, and a Fourier Transform feature-enhanced router is introduced to enable interaction while mitigating parameter interference. The central claim is that this design yields significant gains over baselines in multilingual MT and reduces interference.
Significance. If the empirical claims hold with proper controls and ablations, the work would offer a concrete architectural approach to separating monolingual and bilingual knowledge in LLM fine-tuning for MT, which could be useful for scaling multilingual capabilities without proportional increases in interference.
major comments (2)
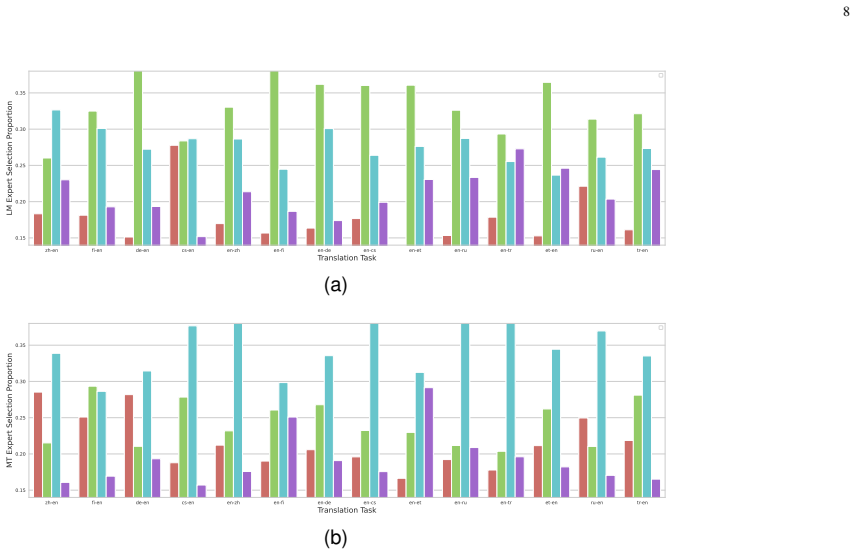
- [Abstract / framework] Abstract and framework description: the central claim that the fixed LM/MT expert split plus Fourier routing reduces parameter interference rests on the unverified assumption that the router will not route monolingual tokens to MT Experts (or vice versa) at inference; no analysis, routing statistics, or ablation is supplied to show that cross-group routing is prevented or that capacity does not collapse.
- [Abstract] Abstract: the assertion of 'significantly outperforming existing baselines' and 'notable progress in mitigating parameter interference' is stated without any reported metrics, baselines, language pairs, model sizes, or statistical significance; the soundness of the headline result cannot be assessed from the supplied evidence.
minor comments (2)
- [Method] The precise mathematical form of the Fourier features added to the router and how they are combined with the standard gating function should be stated explicitly (e.g., as an equation).
- [Method] Clarify whether the two expert groups share any parameters or whether the router is trained jointly or in separate phases.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point by point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / framework] Abstract and framework description: the central claim that the fixed LM/MT expert split plus Fourier routing reduces parameter interference rests on the unverified assumption that the router will not route monolingual tokens to MT Experts (or vice versa) at inference; no analysis, routing statistics, or ablation is supplied to show that cross-group routing is prevented or that capacity does not collapse.
Authors: We agree that the current manuscript lacks explicit routing statistics, cross-group routing analysis, or dedicated ablations to verify that the router largely respects the LM/MT expert partition at inference. The architectural intent is that the fixed grouping plus Fourier features limits harmful interference while still permitting interaction, but this remains an assumption without direct empirical support in the submitted version. We will add routing distribution statistics across expert groups and an ablation isolating cross-group routing in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'significantly outperforming existing baselines' and 'notable progress in mitigating parameter interference' is stated without any reported metrics, baselines, language pairs, model sizes, or statistical significance; the soundness of the headline result cannot be assessed from the supplied evidence.
Authors: The abstract is written as a high-level summary; all quantitative results, baselines, language pairs, model sizes, and significance tests appear in the experimental sections of the full manuscript. This follows common practice for abstracts. If the editor prefers, we can insert a small number of key headline metrics into the abstract during revision. revision: partial
Circularity Check
No circularity: Mix-MoE is an empirical architecture proposal with no derivation chain
full rationale
The paper proposes a two-stage post-pretraining process, a fixed split of MoE layers into LM Experts (monolingual data) and MT Experts (parallel data), and a Fourier-feature router. These are explicit design choices presented as solutions to parameter interference. No equations, fitted parameters, or first-principles derivations are described that reduce to self-defined quantities or self-citations. Claims rest on experimental comparisons to baselines, which are external evaluations rather than internal reductions. The method is therefore self-contained as an engineering contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Specialized LM and MT expert groups can be trained sequentially on monolingual then parallel data without destructive interference.
invented entities (1)
-
LM Experts and MT Experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Multilingual mix: Example interpolation improves multilingual neural machine translation,
Y . Cheng, A. Bapna, O. Firat, Y . Cao, P. Wang, and W. Macherey, “Multilingual mix: Example interpolation improves multilingual neural machine translation,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicenc...
2022
-
[2]
Towards higher pareto frontier in multilingual machine translation,
Y . Huang, X. Feng, X. Geng, B. Li, and B. Qin, “Towards higher pareto frontier in multilingual machine translation,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational...
2023
-
[3]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” in3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7- 9, 2015, Conference Track Proceedings, Y . Bengio and Y . LeCun, Eds., 2015
2015
-
[4]
New trends in machine translation using large language models: Case examples with chatgpt,
C. Lyu, J. Xu, and L. Wang, “New trends in machine translation using large language models: Case examples with chatgpt,”CoRR, vol. abs/2305.01181, 2023
-
[5]
Multilingual machine translation with large language models: Empirical results and analysis,
W. Zhu, H. Liu, Q. Dong, J. Xu, S. Huang, L. Kong, J. Chen, and L. Li, “Multilingual machine translation with large language models: Empirical results and analysis,” inFindings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024, K. Duh, H. G ´omez-Adorno, and S. Bethard, Eds. Association for Computational L...
2024
-
[6]
Revolutionising translation with ai: Unravelling neural machine translation and generative pre-trained large language models,
S. C. Siu, “Revolutionising translation with ai: Unravelling neural machine translation and generative pre-trained large language models,” inNew Advances in Translation Technology: Applications and Pedagogy. Springer, 2024, pp. 29–54
2024
-
[7]
Continual learning with semi-supervised contrastive distillation for incremental neural machine translation,
Y . Liang, F. Meng, J. Wang, J. Xu, Y . Chen, and J. Zhou, “Continual learning with semi-supervised contrastive distillation for incremental neural machine translation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, L. Ku, A. Martins, and ...
2024
-
[8]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang, “An empir- ical study of catastrophic forgetting in large language models during continual fine-tuning,”CoRR, vol. abs/2308.08747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Simple and scalable strategies to continually pre-train large language models,
A. Ibrahim, B. Th ´erien, K. Gupta, M. L. Richter, Q. G. Anthony, E. Belilovsky, T. Lesort, and I. Rish, “Simple and scalable strategies to continually pre-train large language models,”Trans. Mach. Learn. Res., vol. 2024, 2024
2024
-
[10]
Breaking the script barrier in multilingual pre-trained language models with transliteration-based post- training alignment,
O. Xhelili, Y . Liu, and H. Sch ¨utze, “Breaking the script barrier in multilingual pre-trained language models with transliteration-based post- training alignment,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, Y . Al-Onaizan, M. Bansal, and Y . Chen, Eds. Association for Computational...
2024
-
[11]
Towards incremental learning in large language models: A critical review,
M. Jovanovic and P. V oss, “Towards incremental learning in large language models: A critical review,”CoRR, vol. abs/2404.18311, 2024
-
[12]
H. Zhou, Z. Wang, S. Huang, X. Huang, X. Han, J. Feng, C. Deng, W. Luo, and J. Chen, “Moe-lpr: Multilingual extension of large language models through mixture-of-experts with language priors routing,”CoRR, vol. abs/2408.11396, 2024
-
[13]
Overcoming language barriers via machine translation with sparse mixture-of-experts fusion of large language models,
S. Zhu, L. Pan, D. Jian, and D. Xiong, “Overcoming language barriers via machine translation with sparse mixture-of-experts fusion of large language models,”Information Processing & Management, vol. 62, no. 3, p. 104078, 2025
2025
-
[14]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S...
2017
-
[15]
Transfer learning for low- resource neural machine translation,
B. Zoph, D. Yuret, J. May, and K. Knight, “Transfer learning for low- resource neural machine translation,” inProceedings of the 2016 Con- ference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016, J. Su, X. Carreras, and K. Duh, Eds. The Association for Computational Linguistics, 2016, pp. 1568–1575
2016
-
[16]
Rapid adaptation of neural machine translation to new languages,
G. Neubig and J. Hu, “Rapid adaptation of neural machine translation to new languages,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Association for Computational Linguistics, 2018, pp. 875–880
2018
-
[17]
Improving neural machine translation models with monolingual data,
R. Sennrich, B. Haddow, and A. Birch, “Improving neural machine translation models with monolingual data,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Papers. The Association for Computer Linguistics, 2016
2016
-
[18]
Zero-shot cross-lingual transfer of neural machine translation with multilingual pretrained encoders,
G. Chen, S. Ma, Y . Chen, L. Dong, D. Zhang, J. Pan, W. Wang, and F. Wei, “Zero-shot cross-lingual transfer of neural machine translation with multilingual pretrained encoders,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, M. Moens...
2021
-
[19]
Towards robust in-context learning for machine translation with large language models,
S. Zhu, M. Cui, and D. Xiong, “Towards robust in-context learning for machine translation with large language models,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy, N. Calzolari, M. Kan, V . Hoste, A. Lenci, S. Sakti, and N. Xue, E...
2024
-
[20]
T. Kojima, I. Okimura, Y . Iwasawa, H. Yanaka, and Y . Matsuo, “On the multilingual ability of decoder-based pre-trained language mod- els: Finding and controlling language-specific neurons,”CoRR, vol. abs/2404.02431, 2024
-
[21]
A paradigm shift: The future of machine translation lies with large language models,
C. Lyu, Z. Du, J. Xu, Y . Duan, M. Wu, T. Lynn, A. F. Aji, D. F. Wong, and L. Wang, “A paradigm shift: The future of machine translation lies with large language models,” inProceedings of the 2024 Joint Interna- tional Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy, N. Calzolari...
2024
-
[22]
Improving translation of out of vocabulary words using bilingual lexicon induction in low-resource machine translation,
J. Waldendorf, A. Birch, B. Hadow, and A. V . M. Barone, “Improving translation of out of vocabulary words using bilingual lexicon induction in low-resource machine translation,” inProceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Volume 1: Research Track), AMTA 2022, Orlando, USA, September 12- 16, 20...
2022
-
[23]
S. Ranathunga, S. Nayak, S. C. Huang, Y . Mao, T. Su, Y . R. Chan, S. Yuan, A. Rinaldi, and E. A. Lee, “Exploiting domain-specific par- allel data on multilingual language models for low-resource language translation,”CoRR, vol. abs/2412.19522, 2024
-
[24]
Catastrophic interference in reinforcement learning: A solution based on context division and knowledge distillation,
T. Zhang, X. Wang, B. Liang, and B. Yuan, “Catastrophic interference in reinforcement learning: A solution based on context division and knowledge distillation,”IEEE Trans. Neural Networks Learn. Syst., vol. 34, no. 12, pp. 9925–9939, 2023
2023
-
[25]
Understanding catas- trophic forgetting in language models via implicit inference,
S. Kotha, J. M. Springer, and A. Raghunathan, “Understanding catas- trophic forgetting in language models via implicit inference,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[26]
Efficient continual pre-training for building domain specific large language models,
Y . Xie, K. Aggarwal, and A. Ahmad, “Efficient continual pre-training for building domain specific large language models,” inFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, L. Ku, A. Martins, and V . Srikumar, Eds. Association for Computational Linguistics, 2024, pp. 10 184–10 201
2024
-
[27]
Overcoming catastrophic forgetting in graph neural networks,
H. Liu, Y . Yang, and X. Wang, “Overcoming catastrophic forgetting in graph neural networks,” inThirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Appli- cations of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, ...
2021
-
[28]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
D. Kalajdzievski, “A rank stabilization scaling factor for fine-tuning with lora,”CoRR, vol. abs/2312.03732, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
arXiv preprint arXiv:2112.10684 , year=
M. Artetxe, S. Bhosale, N. Goyal, T. Mihaylov, M. Ott, S. Shleifer, X. V . Lin, J. Du, S. Iyer, R. Pasunuruet al., “Efficient large scale language modeling with mixtures of experts,”arXiv preprint arXiv:2112.10684, 2021
-
[30]
Distributed learning of mixtures of experts,
F. Chamroukhi and N. T. Pham, “Distributed learning of mixtures of experts,”CoRR, vol. abs/2312.09877, 2023
-
[31]
Mmoe: Enhancing multimodal models with mixtures of multimodal interaction experts,
H. Yu, Z. Qi, L. Jang, R. Salakhutdinov, L. Morency, and P. P. Liang, “Mmoe: Enhancing multimodal models with mixtures of multimodal interaction experts,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, Y . Al-Onaizan, M. Bansal, and Y . Chen, Eds. Association for ...
2024
-
[32]
From sparse to soft mixtures of experts,
J. Puigcerver, C. R. Ruiz, B. Mustafa, and N. Houlsby, “From sparse to soft mixtures of experts,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[33]
Efficient large scale language modeling with mixtures of experts,
M. Artetxe, S. Bhosale, N. Goyal, T. Mihaylov, M. Ott, S. Shleifer, X. V . Lin, J. Du, S. Iyer, R. Pasunuru, G. Anantharaman, X. Li, S. Chen, H. Akin, M. Baines, L. Martin, X. Zhou, P. S. Koura, B. O’Horo, J. Wang, L. Zettlemoyer, M. T. Diab, Z. Kozareva, and V . Stoyanov, “Efficient large scale language modeling with mixtures of experts,” in Proceedings ...
2022
-
[34]
A paradigm shift in machine translation: Boosting translation performance of large language models,
H. Xu, Y . J. Kim, A. Sharaf, and H. H. Awadalla, “A paradigm shift in machine translation: Boosting translation performance of large language models,” inThe Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[35]
X-ALMA: plug & play modules and adaptive rejection for quality translation at scale,
H. Xu, K. Murray, P. Koehn, H. Hoang, A. Eriguchi, and H. Khayrallah, “X-ALMA: plug & play modules and adaptive rejection for quality translation at scale,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[36]
Digital signal processing: signals systems and filters,
A. Antoniu, “Digital signal processing: signals systems and filters,” 2006
2006
-
[37]
On the relation between linguistic typology and (limitations of) multilin- gual language modeling,
D. Gerz, I. Vulic, E. M. Ponti, R. Reichart, and A. Korhonen, “On the relation between linguistic typology and (limitations of) multilin- gual language modeling,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, E...
2018
-
[38]
Frequency of basic english grammatical structures: A corpus analysis,
D. Roland, F. Dick, and J. L. Elman, “Frequency of basic english grammatical structures: A corpus analysis,”Journal of memory and language, vol. 57, no. 3, pp. 348–379, 2007
2007
-
[39]
Deep Learning Based Natural Language Processing for End to End Speech Translation
S. Patil, “Deep learning based natural language processing for end to end speech translation,”arXiv preprint arXiv:1808.04459, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Dnn-based cross-lingual voice conversion using bottleneck features,
M. Kiran Reddy and K. Sreenivasa Rao, “Dnn-based cross-lingual voice conversion using bottleneck features,”Neural Processing Letters, vol. 51, no. 2, pp. 2029–2042, 2020
2029
-
[41]
Learn- ing a Fourier transform for linear relative positional encodings in transformers,
K. Choromanski, S. Li, V . Likhosherstov, K. Avinava Dubey, S. Luo, D. He, Y . Yang, T. Sarlos, T. Weingarten, and A. Weller, “Learn- ing a Fourier transform for linear relative positional encodings in transformers,” inProceedings of The 27th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research,...
2024
-
[42]
Learnable fourier features for multi-dimensional spatial positional encoding,
Y . Li, S. Si, G. Li, C.-J. Hsieh, and S. Bengio, “Learnable fourier features for multi-dimensional spatial positional encoding,” inAdvances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 15 816–15 829
2021
-
[43]
Fourier position embedding: Enhancing attention’s periodic extension for length generalization,
E. Hua, C. Jiang, X. Lv, K. Zhang, N. Ding, Y . Sun, B. Qi, Y . Fan, X. K. Zhu, and B. Zhou, “Fourier position embedding: Enhancing attention’s periodic extension for length generalization,”arXiv preprint arXiv:2412.17739, 2024
-
[44]
Transformer feed-forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed-forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, M. Moens, X. Huang, L. Specia, and S. W. Yih, Eds. Association for Computational L...
2021
-
[45]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Association for Computational Linguistics, 20...
2022
-
[46]
A mathematical framework for transformer circuits,
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y . Bai, A. Chen, T. Conerlyet al., “A mathematical framework for transformer circuits,”Transformer Circuits Thread, vol. 1, no. 1, p. 12, 2021
2021
-
[47]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. de Las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of experts,” CoRR, vol. ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”J. Mach. Learn. Res., vol. 23, pp. 120:1–120:39, 2022
2022
-
[49]
Mixtral of experts,
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of experts,” 2024
2024
-
[50]
Llama-moe v2: Exploring sparsity of llama from perspective of mixture-of-experts with post-training,
X. Qu, D. Dong, X. Hu, T. Zhu, W. Sun, and Y . Cheng, “Llama-moe v2: Exploring sparsity of llama from perspective of mixture-of-experts with post-training,”CoRR, vol. abs/2411.15708, 2024
-
[51]
Llama-moe: Building mixture-of-experts from llama with continual pre- training,
T. Zhu, X. Qu, D. Dong, J. Ruan, J. Tong, C. He, and Y . Cheng, “Llama-moe: Building mixture-of-experts from llama with continual pre- training,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 15 913–15 923
2024
-
[52]
OLMoE: Open Mixture-of-Experts Language Models
N. Muennighoff, L. Soldaini, D. Groeneveld, K. Lo, J. Morrison, S. Min, W. Shi, P. Walsh, O. Tafjord, N. Lambertet al., “Olmoe: Open mixture- of-experts language models,”arXiv preprint arXiv:2409.02060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” inProceedings of the Third Conference on Machine Translation: Research Papers, WMT 2018, Belgium, Brussels, October 31 - November 1, 2018, O. Bojar, R. Chatterjee, C. Federmann, M. Fishel, Y . Graham, B. Haddow, M. Huck, A. Jimeno-Yepes, P. Koehn, C. Monz, M. Negri, A. N ´ev´eol, M. L. Neves, M. Post...
2018
-
[54]
METEOR: an automatic metric for MT evalu- ation with improved correlation with human judgments,
S. Banerjee and A. Lavie, “METEOR: an automatic metric for MT evalu- ation with improved correlation with human judgments,” inProceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization@ACL 2005, Ann Arbor, Michigan, USA, June 29, 2005, J. Goldstein, A. Lavie, C. Lin, and C. R. V oss, Eds. Associ...
2005
-
[55]
COMET: A neural framework for MT evaluation,
R. Rei, C. Stewart, A. C. Farinha, and A. Lavie, “COMET: A neural framework for MT evaluation,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y . He, and Y . Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 2685–2702
2020
-
[56]
Qa-lora: Quantization-aware low-rank adaptation of large language models,
Y . Xu, L. Xie, X. Gu, X. Chen, H. Chang, H. Zhang, Z. Chen, X. Zhang, and Q. Tian, “Qa-lora: Quantization-aware low-rank adaptation of large language models,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net, 2024
2024
-
[57]
Llama pro: Progressive llama with block expansion,
C. Wu, Y . Gan, Y . Ge, Z. Lu, J. Wang, Y . Feng, Y . Shan, and P. Luo, “Llama pro: Progressive llama with block expansion,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, L. Ku, A. Martins, and V . Srikumar, Eds. Association for Computat...
2024
-
[58]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D....
2022
-
[59]
No Language Left Behind: Scaling Human-Centered Machine Translation
M. R. Costa-Juss `a, J. Cross, O. C ¸ elebi, M. Elbayad, K. Heafield, K. Heffernan, E. Kalbassi, J. Lam, D. Licht, J. Maillardet al., “No language left behind: Scaling human-centered machine translation,” arXiv preprint arXiv:2207.04672, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.