Beyond the Aggregation Dilemma: Prior-Retaining Decoupled Learning for Multimodal Graphs
Pith reviewed 2026-06-30 14:41 UTC · model grok-4.3
The pith
Decoupled dual-pathway learning resolves the aggregation dilemma in multimodal graphs with strong foundation model priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
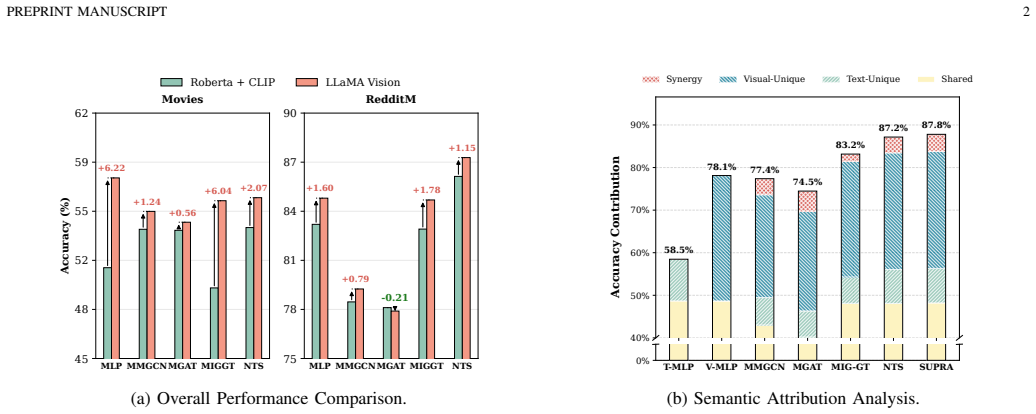
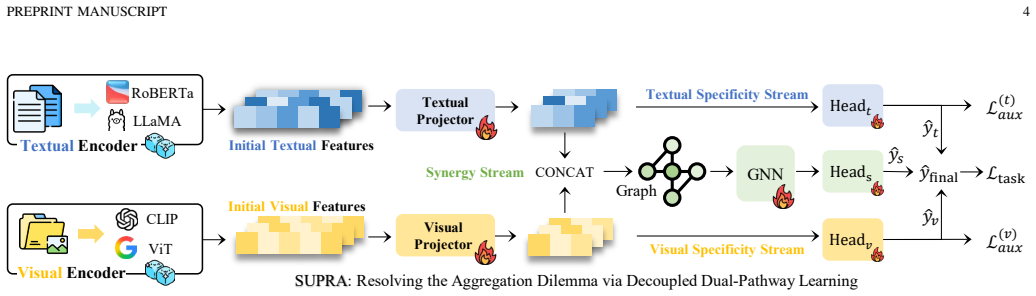
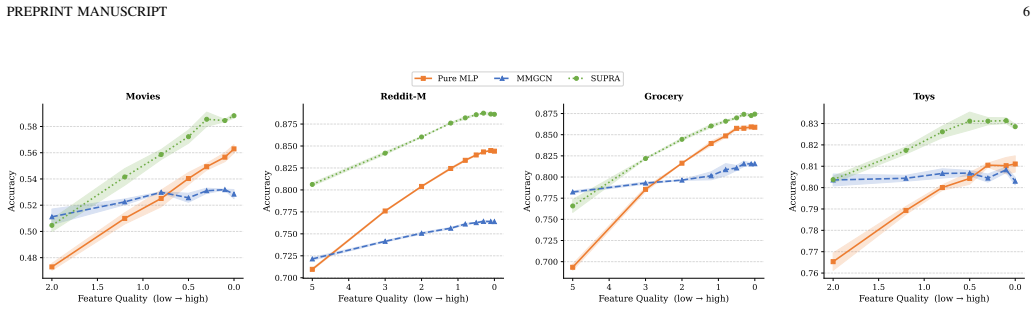
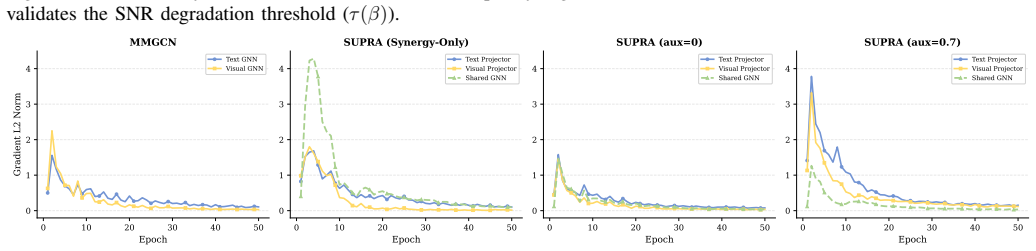
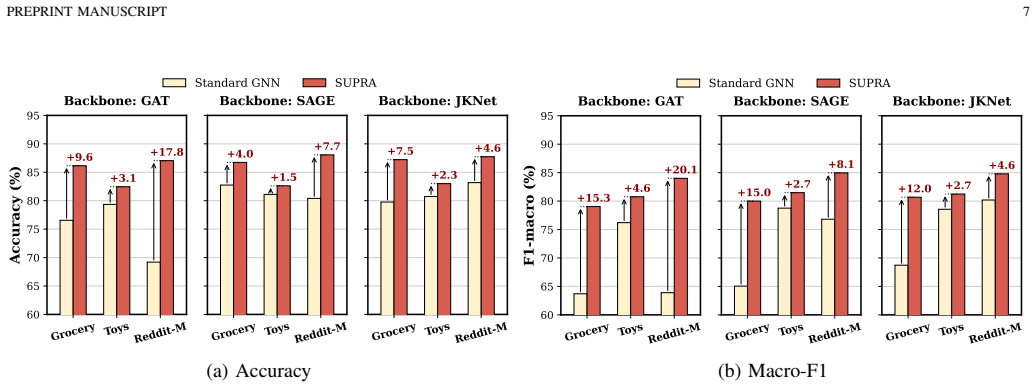
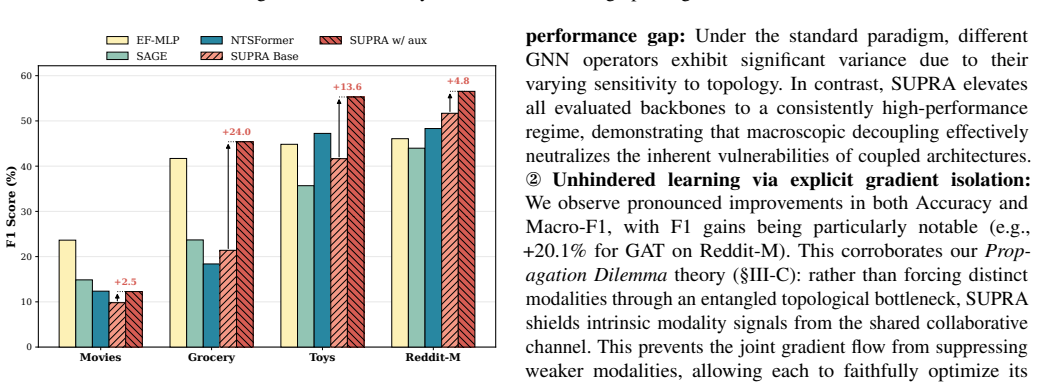
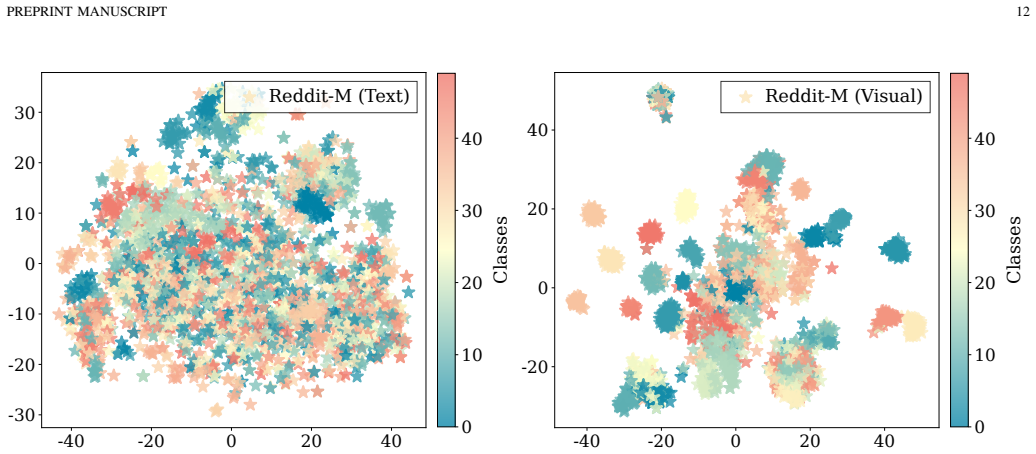
Under high-confidence LFM priors, mandatory aggregation in MAGL triggers a fundamental aggregation dilemma with representational pathology (SNR degradation) and optimization pathology (gradient starvation), resulting in sophisticated architectures underperforming topology-agnostic MLPs; this is resolved by the SUPRA decoupled dual-pathway paradigm that uses modality-specific topology-agnostic MLPs, a lightweight shared GNN for synergy, and auxiliary deep supervision.
What carries the argument
SUPRA (Shared-Unique Prior-Retaining Architecture), a decoupled dual-pathway paradigm that separates modality-specific feature processing through topology-agnostic MLPs from structural synergy via a lightweight shared GNN, with auxiliary deep supervision to prevent gradient starvation.
Load-bearing premise
The observed performance inversion is caused by mandatory aggregation under high-confidence LFM priors, rather than by differences in hyperparameters, model capacity, or dataset artifacts.
What would settle it
Train both aggregated and decoupled models on the same multimodal graph datasets but using encoders with deliberately lowered confidence or non-foundation-model features, and check whether the performance inversion disappears.
Figures
read the original abstract
Multimodal Attributed Graph Learning (MAGL) integrates intrinsic node attributes with structural topology via graph aggregation. However, as pretrained encoders evolve into Large Foundation Models (LFMs), the landscape of MAGL fundamentally shifts: under high-confidence LFM priors, mandatory aggregation introduces topological noise that overwhelms discriminative signals, triggering a counter-intuitive performance inversion where sophisticated MAGL architectures underperform simple topology-agnostic MLPs. Through systematic empirical and theoretical analysis, we identify that this inversion stems from a fundamental aggregation dilemma characterized by two concurrent pathologies: (1) Representational Pathology (SNR Degradation) - mandatory aggregation dilutes robust intrinsic features with topological noise, causing the noise penalty to outweigh its collaborative benefit; and (2) Optimization Pathology (Gradient Starvation) - topological aggregation attenuates gradient flow, while a shared task loss causes dominant modalities to prematurely suppress weaker ones. To resolve this dilemma, we propose SUPRA (Shared-Unique Prior-Retaining Architecture), a decoupled dual-pathway paradigm. SUPRA processes modality-specific features through topology-agnostic MLPs while capturing structural synergy via a lightweight shared GNN, with auxiliary deep supervision counteracting gradient starvation. Extensive evaluations demonstrate that SUPRA achieves state-of-the-art performance while requiring 3.5x lower peak GPU memory and up to 4.4x faster training time than Multimodal Graph Transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that with high-confidence LFM priors in multimodal attributed graph learning, mandatory topological aggregation induces a performance inversion (MAGL models underperform topology-agnostic MLPs) via two pathologies: representational SNR degradation and optimization gradient starvation under shared task loss. It proposes SUPRA, a decoupled dual-pathway model that routes modality-specific features through separate MLPs while using a lightweight shared GNN for structural synergy plus auxiliary deep supervision, reporting SOTA accuracy together with 3.5× lower peak GPU memory and up to 4.4× faster training than Multimodal Graph Transformers.
Significance. If the claimed inversion is shown to be causally due to aggregation rather than capacity or hyper-parameter confounds, the work would challenge the default assumption that graph aggregation remains beneficial once strong pretrained priors are available and would supply a practical decoupled alternative with clear efficiency gains. The efficiency numbers, if reproducible under matched budgets, constitute a concrete practical contribution.
major comments (3)
- [§4, Table 2] §4 (Empirical Analysis) and Table 2: the reported performance inversion and SOTA claims rest on comparisons to MLPs and Multimodal Graph Transformers that do not report or control for total parameter count, effective capacity, or matched training compute; without these controls the attribution of the inversion specifically to mandatory aggregation (rather than capacity mismatch) remains unisolated.
- [§3.2, Eq. (7)–(9)] §3.2 (Theoretical Analysis), Eq. (7)–(9): the gradient-starvation derivation assumes that the shared task loss causes dominant modalities to suppress weaker ones under aggregation, yet the argument provides no formal bound or counter-example showing that this attenuation is strictly larger than in a capacity-matched non-aggregated baseline.
- [§5.1] §5.1 (Ablation Studies): the dual-pathway ablations do not include a controlled variant that applies aggregation only to the shared GNN path while keeping the MLP paths and total parameters identical, leaving open whether the observed gains are due to decoupling per se or to other architectural differences.
minor comments (2)
- [§2] The notation for “high-confidence LFM priors” is used throughout without a precise mathematical definition (e.g., a threshold on predictive entropy or calibration error); a short formal statement would improve reproducibility.
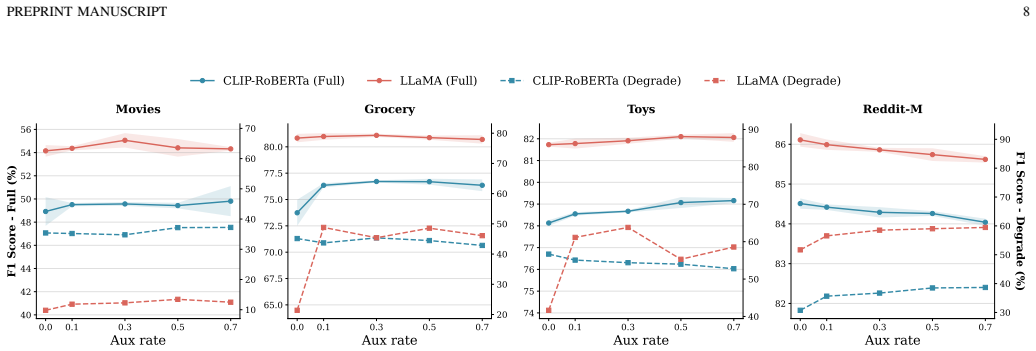
- [Figure 4] Figure 4 (memory and runtime curves) would benefit from explicit reporting of the hardware and batch-size settings used for the 3.5× and 4.4× claims so that readers can verify the efficiency numbers under comparable conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, clarifying our experimental design, theoretical analysis, and planned revisions to strengthen isolation of the aggregation effect.
read point-by-point responses
-
Referee: [§4, Table 2] §4 (Empirical Analysis) and Table 2: the reported performance inversion and SOTA claims rest on comparisons to MLPs and Multimodal Graph Transformers that do not report or control for total parameter count, effective capacity, or matched training compute; without these controls the attribution of the inversion specifically to mandatory aggregation (rather than capacity mismatch) remains unisolated.
Authors: We agree that explicit controls for parameter count and capacity would more rigorously isolate the aggregation pathology. In the revision we will add a table reporting exact parameter counts for all baselines and SUPRA variants. We will also run new experiments with capacity-matched MLP baselines (scaling hidden dimensions to equal total parameters of the MAGL models) and report training FLOPs under matched budgets. The original MLP baselines follow standard configurations from prior MAGL literature, but these additions will confirm the inversion is not due to capacity mismatch. revision: yes
-
Referee: [§3.2, Eq. (7)–(9)] §3.2 (Theoretical Analysis), Eq. (7)–(9): the gradient-starvation derivation assumes that the shared task loss causes dominant modalities to suppress weaker ones under aggregation, yet the argument provides no formal bound or counter-example showing that this attenuation is strictly larger than in a capacity-matched non-aggregated baseline.
Authors: The derivation illustrates the attenuation mechanism via the shared loss and aggregation operator but is qualitative. We will add a short numerical simulation (gradient-norm counter-example) under capacity-matched settings to demonstrate that the starvation effect is strictly larger with aggregation. This will be placed in an appendix or expanded §3.2. The empirical gradient measurements in §4 already provide supporting evidence. revision: partial
-
Referee: [§5.1] §5.1 (Ablation Studies): the dual-pathway ablations do not include a controlled variant that applies aggregation only to the shared GNN path while keeping the MLP paths and total parameters identical, leaving open whether the observed gains are due to decoupling per se or to other architectural differences.
Authors: We will add the requested controlled ablation: a variant that restricts aggregation to the shared GNN path only, keeps the modality-specific MLP paths unchanged, and matches total parameter count by adjusting GNN width. Results will be reported in an updated §5.1 to isolate the benefit of full decoupling. revision: yes
Circularity Check
No circularity: derivation chain self-contained with no reductions to inputs
full rationale
The manuscript asserts an aggregation dilemma via empirical/theoretical analysis and proposes SUPRA as a decoupled architecture, but the provided text contains no equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations that reduce the central claims to their own inputs by construction. Performance claims rest on external evaluations against baselines rather than internal redefinitions, and the pathologies are diagnosed through comparisons that do not exhibit the enumerated circular patterns. This is the expected non-finding for a paper whose core argument is empirical rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-confidence LFM priors make mandatory aggregation introduce topological noise that outweighs collaborative benefit.
- domain assumption Shared task loss causes dominant modalities to suppress weaker ones via gradient starvation.
invented entities (1)
-
SUPRA (Shared-Unique Prior-Retaining Architecture)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InProceedings of the 5th International Conference on Learning Representations, 2017
2017
-
[2]
Graph attention networks
Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li`o, and Yoshua Bengio. Graph attention networks. InProceedings of the 6th International Conference on Learning Representations, 2018
2018
-
[3]
Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism
Jun Yin, Zhengxin Zeng, Mingzheng Li, Hao Yan, Chaozhuo Li, Weihao Han, Jianjin Zhang, Ruochen Liu, Hao Sun, Weiwei Deng, Feng Sun, Qi Zhang, Shirui Pan, and Senzhang Wang. Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism. InProceedings of the ACM on Web Conference, pages 216–227, 2025
2025
-
[4]
The netflix recommender system: Algorithms, business value, and innovation.ACM Transactions on Management Information Systems, 6(4), 2016
Carlos Alberto Gomez-Uribe and Neil Hunt. The netflix recommender system: Algorithms, business value, and innovation.ACM Transactions on Management Information Systems, 6(4), 2016
2016
-
[5]
Transformers4rec: Bridging the gap between NLP and sequential / session-based recommendation
Gabriel de Souza Pereira Moreira, Sara Rabhi, Jeong Min Lee, Ronay Ak, and Even Oldridge. Transformers4rec: Bridging the gap between NLP and sequential / session-based recommendation. InProceedings of the 15th ACM Conference on Recommender Systems, 2021
2021
-
[6]
When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning
Hao Yan, Chaozhuo Li, Jun Yin, Zhigang Yu, Weihao Han, Mingzheng Li, Zhengxin Zeng, Hao Sun, and Senzhang Wang. When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5842–5853, 2025
2025
-
[7]
Learning on multimodal graphs: A survey.arXiv preprint arXiv:2402.05322, 2024
Ciyuan Peng, Jiayuan He, and Feng Xia. Learning on multimodal graphs: A survey.arXiv preprint arXiv:2402.05322, 2024
-
[8]
Mmgcn: Multi-modal graph convolution network for personalized recommendation of micro-video
Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. Mmgcn: Multi-modal graph convolution network for personalized recommendation of micro-video. InProceedings of the 27th ACM international conference on multimedia, pages 1437–1445, 2019
2019
-
[9]
Mgat: Multimodal graph attention network for recommendation.Information Processing & Management, 57(5), 2020
Zhulin Tao, Yinwei Wei, Xiang Wang, Xiangnan He, Xianglin Huang, and Tat-Seng Chua. Mgat: Multimodal graph attention network for recommendation.Information Processing & Management, 57(5), 2020
2020
-
[10]
Modality- independent graph neural networks with global transformers for multi- modal recommendation
Jun Hu, Bryan Hooi, Bingsheng He, and Yinwei Wei. Modality- independent graph neural networks with global transformers for multi- modal recommendation. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 11790–11798, 2025
2025
-
[11]
Ntsformer: A self-teaching graph transformer for multimodal isolated cold-start node classification
Jun Hu, Yufei He, Yuan Li, Bryan Hooi, and Bingsheng He. Ntsformer: A self-teaching graph transformer for multimodal isolated cold-start node classification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 14856–14864, 2026
2026
-
[12]
Learning on multimodal graphs: A survey.CoRR, 2024
Ciyuan Peng, Jiayuan He, and Feng Xia. Learning on multimodal graphs: A survey.CoRR, 2024
2024
-
[13]
Deep semantic graph learning via llm based node enhancement.arXiv preprint arXiv:2502.07982, 2025
Chuanqi Shi, Yiyi Tao, Hang Zhang, Lun Wang, Shaoshuai Du, Yixian Shen, and Yanxin Shen. Deep semantic graph learning via llm based node enhancement.arXiv preprint arXiv:2502.07982, 2025
-
[14]
Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, pages 42–61, 2024
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, pages 42–61, 2024
2024
-
[15]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking
Hao Yan, Chaozhuo Li, Ruosong Long, Chao Yan, Jianan Zhao, Wenwen Zhuang, Jun Yin, Peiyan Zhang, Weihao Han, Hao Sun, Weiwei Deng, Qi Zhang, Lichao Sun, Xing Xie, and Senzhang Wang. A comprehensive study on text-attributed graphs: Benchmarking and rethinking. In Proceedings of the 37th Annual Conference on Neural Information Processing Systems, 2023
2023
-
[16]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, 2021
2021
-
[18]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine- tuned chat models.arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Revisiting graph neural networks: All we have is low-pass filters.CoRR, 2019
Hoang NT and Takanori Maehara. Revisiting graph neural networks: All we have is low-pass filters.CoRR, 2019
2019
-
[20]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International conference on machine learning, pages 6861–6871. Pmlr, 2019
2019
-
[21]
Courville, Doina Precup, and Guillaume Lajoie
Mohammad Pezeshki, S ´ekou-Oumar Kaba, Yoshua Bengio, Aaron C. Courville, Doina Precup, and Guillaume Lajoie. Gradient starvation: A learning proclivity in neural networks. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 1256–1272, 2021
2021
-
[22]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 8228– 8237, 2022
2022
-
[23]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In International conference on machine learning, pages 1263–1272, 2017
2017
-
[24]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. InProceedings of the 31th Annual Conference on Neural Information Processing Systems, 2017
2017
-
[25]
Representation learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken- ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. InProceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm¨assan, Stockholm, Sweden, July 10-15, 2018, pages 5449– 5458, 2018
2018
-
[26]
Dgp: A dual-granularity prompting framework for fraud detection with graph- enhanced llms
Yuan Li, Jun Hu, Bryan Hooi, Bingsheng He, and Cheng Chen. Dgp: A dual-granularity prompting framework for fraud detection with graph- enhanced llms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 15171–15179, 2026
2026
-
[27]
Improving multi-modal learning with uni-modal teachers.CoRR, 2021
Chenzhuang Du, Tingle Li, Yichen Liu, Zixin Wen, Tianyu Hua, Yue Wang, and Hang Zhao. Improving multi-modal learning with uni-modal teachers.CoRR, 2021
2021
-
[28]
Kenta Oono and Taiji Suzuki. Graph neural networks exponentially lose expressive power for node classification.arXiv preprint arXiv:1905.10947, 2019
-
[29]
Measuring and relieving the over-smoothing problem for graph neural networks from the topological view
Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. InProceedings of the AAAI conference on artificial intelligence, pages 3438–3445, 2020. PREPRINT MANUSCRIPT 11 APPENDIXA EXPERIMENTALDETAILS ANDADDITIONALRESULTS A. Baseline Algorithms To pro...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.