CP-Agent: A Calibrated Risk-Controlled Agent for Feedback-Driven Competitive Programming
Pith reviewed 2026-06-30 13:16 UTC · model grok-4.3
The pith
Modeling feedback as a calibrated stopped process lets an agent improve LLM contest programming without any parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
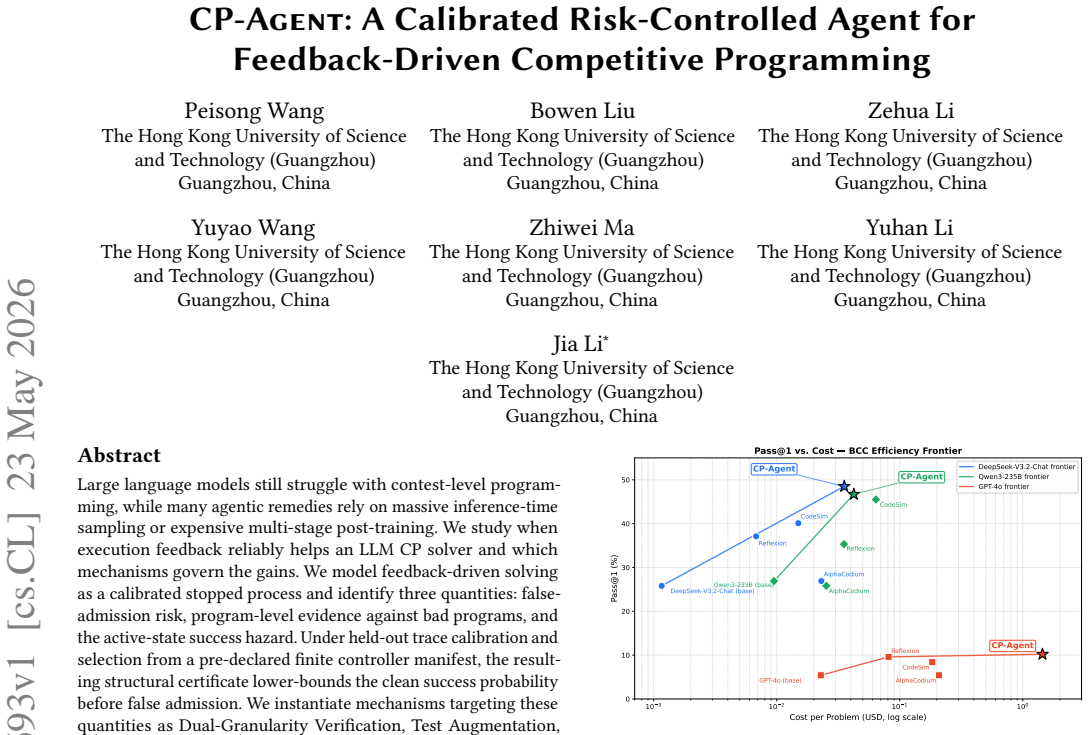
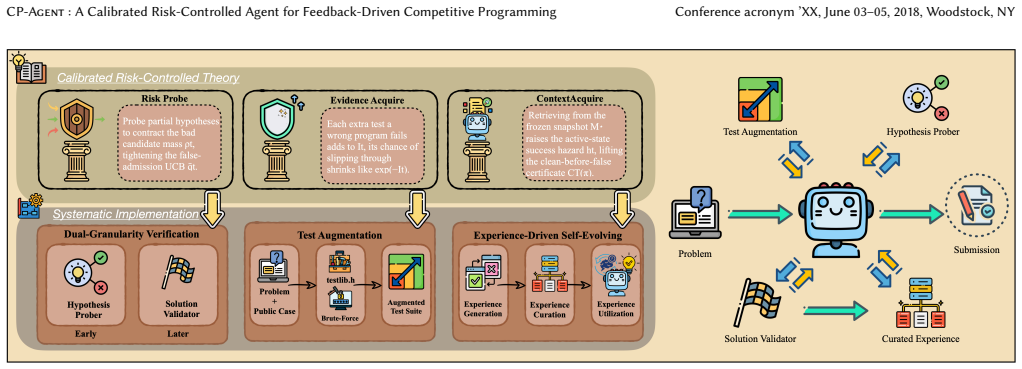
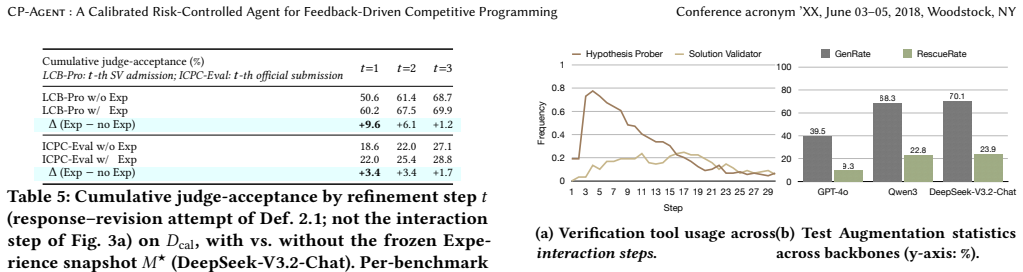
By modeling feedback-driven solving as a calibrated stopped process and identifying false-admission risk, program-level evidence against bad programs, and the active-state success hazard, the authors derive a structural certificate that lower-bounds clean success probability before false admission under held-out trace calibration. Instantiating mechanisms that target each quantity produces CP-Agent, which improves Pass@1 from 25.8% to 48.5% on LiveCodeBench Pro and Refine@5 by 11.0% on ICPC-Eval without parameter updates and lies on the cost-accuracy efficiency frontier for three LLM backbones.
What carries the argument
The calibrated stopped process defined by false-admission risk, program-level evidence against bad programs, and active-state success hazard, which yields a structural certificate under held-out trace calibration and finite manifest selection.
If this is right
- CP-Agent raises Pass@1 from 25.8% to 48.5% on LiveCodeBench Pro without parameter updates.
- CP-Agent improves Refine@5 by 11.0% on ICPC-Eval.
- Across three LLM backbones CP-Agent lies on the cost-accuracy efficiency frontier.
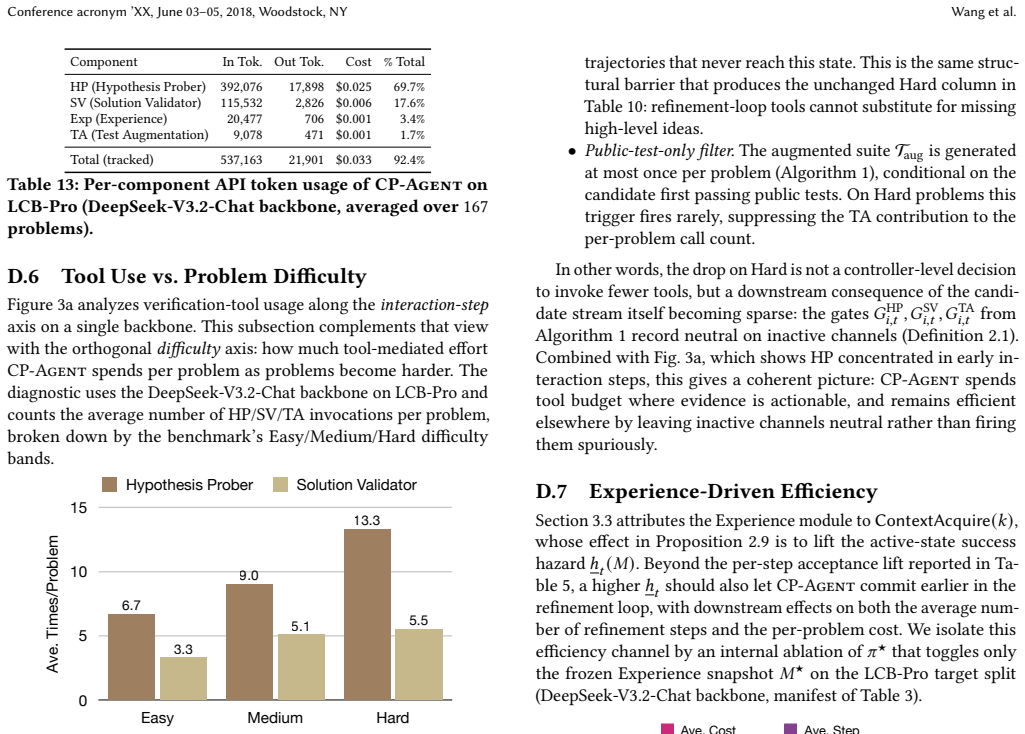
- Ablations show each component primarily affects its targeted certificate quantity.
Where Pith is reading between the lines
- The same calibration logic could be tested on other feedback-rich agent tasks such as automated theorem proving.
- Expanding the pre-declared controller manifest while preserving calibration would trade extra verification cost for potentially higher success bounds.
- The approach is compatible with later parameter updates, though the paper isolates the zero-update regime.
Load-bearing premise
The modeling of feedback-driven solving as a calibrated stopped process with the three quantities yields a structural certificate that lower-bounds clean success probability before false admission, under held-out trace calibration and selection from a pre-declared finite controller manifest.
What would settle it
On a fresh held-out collection of contest problems, if the observed rate of clean success before any false admission falls below the numerical lower bound supplied by the calibration, the structural certificate is falsified.
Figures

read the original abstract
Large language models still struggle with contest-level programming, while many agentic remedies rely on massive inference-time sampling or expensive multi-stage post-training. We study when execution feedback reliably helps an LLM CP solver and which mechanisms govern the gains. We model feedback-driven solving as a calibrated stopped process and identify three quantities: false-admission risk, program-level evidence against bad programs, and the active-state success hazard. Under held-out trace calibration and selection from a pre-declared finite controller manifest, the resulting structural certificate lower-bounds the clean success probability before false admission. We instantiate mechanisms targeting these quantities as Dual-Granularity Verification, Test Augmentation, and Experience-Driven Self-Evolving, yielding CP-Agent. Without updating any parameters, CP-Agent raises Pass@1 from 25.8\% to 48.5\% on LiveCodeBench Pro and improves Refine@5 by 11.0\% on ICPC-Eval. Across three LLM backbones, CP-Agent lies on the cost--accuracy efficiency frontier, and ablations show that each component primarily affects its corresponding certificate quantity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models feedback-driven competitive programming solving as a calibrated stopped process defined by three quantities (false-admission risk, program-level evidence against bad programs, and active-state success hazard). Under held-out trace calibration and selection from a pre-declared finite controller manifest, these yield a structural certificate that lower-bounds clean success probability before false admission. The authors instantiate mechanisms targeting each quantity (Dual-Granularity Verification, Test Augmentation, Experience-Driven Self-Evolving) in CP-Agent. Without parameter updates, CP-Agent improves Pass@1 from 25.8% to 48.5% on LiveCodeBench Pro and Refine@5 by 11.0% on ICPC-Eval, lies on the cost-accuracy frontier across three LLM backbones, and ablations link each component to its target quantity.
Significance. If the structural certificate is valid, non-vacuous, and independent of the calibration fit, the work supplies a principled risk-control framework for feedback-driven agents in contest-level programming. The parameter-free empirical gains, cross-backbone efficiency frontier position, and component-wise ablations are strengths that would make the contribution notable for agentic LLM systems.
major comments (3)
- [§3] §3 (calibrated stopped process and structural certificate): the certificate is defined directly in terms of the three quantities that are themselves obtained by calibration on held-out traces; the manuscript must supply the explicit derivation (including any inequality) showing that the lower bound on clean success probability is not tautological with or reducible to the observed success rate on the calibration distribution.
- [§4] §4 (finite controller manifest): the guarantee relies on selection from a pre-declared finite manifest; the paper needs to confirm that the manifest is fixed prior to any test-set exposure and that its coverage is sufficient to prevent the bound from becoming vacuous or distribution-dependent on LiveCodeBench Pro and ICPC-Eval.
- [Experimental section] Experimental section (ablations and reported gains): while ablations indicate each mechanism affects its corresponding quantity, the manuscript should report the numerical value of the structural certificate bound evaluated on the test sets to demonstrate that the bound is informative and tracks the observed Pass@1 and Refine@5 improvements.
minor comments (2)
- [§3] Notation for the three quantities (false-admission risk, etc.) should be introduced with consistent symbols and restated when the certificate is defined.
- [Figures] Figure captions for efficiency-frontier plots should explicitly state which backbones and cost metrics are used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (calibrated stopped process and structural certificate): the certificate is defined directly in terms of the three quantities that are themselves obtained by calibration on held-out traces; the manuscript must supply the explicit derivation (including any inequality) showing that the lower bound on clean success probability is not tautological with or reducible to the observed success rate on the calibration distribution.
Authors: We agree that an explicit derivation is required for clarity. The lower bound arises from the stopped-process analysis: the calibrated false-admission risk supplies an upper bound on erroneous termination, the program-level evidence supplies a multiplicative factor reducing the probability of admitting bad programs, and the success hazard governs the continuation probability; these are combined via the finite manifest selection to yield a lower bound on clean success that holds for new traces by virtue of the held-out calibration, independent of the calibration set's own success rate. We will insert the full inequality chain and stopping-time argument into the revised §3. revision: yes
-
Referee: [§4] §4 (finite controller manifest): the guarantee relies on selection from a pre-declared finite manifest; the paper needs to confirm that the manifest is fixed prior to any test-set exposure and that its coverage is sufficient to prevent the bound from becoming vacuous or distribution-dependent on LiveCodeBench Pro and ICPC-Eval.
Authors: The manuscript already characterizes the manifest as pre-declared and finite. We confirm it was fixed before any exposure to LiveCodeBench Pro or ICPC-Eval, as the manifest is part of the method definition and independent of evaluation data. Empirical non-vacuous gains indicate adequate coverage; we will add an explicit confirmation paragraph and coverage discussion in the revised §4. revision: yes
-
Referee: [Experimental section] Experimental section (ablations and reported gains): while ablations indicate each mechanism affects its corresponding quantity, the manuscript should report the numerical value of the structural certificate bound evaluated on the test sets to demonstrate that the bound is informative and tracks the observed Pass@1 and Refine@5 improvements.
Authors: We will evaluate and report the numerical values of the structural certificate lower bound on both test sets in the revised experimental section, placing them alongside the observed Pass@1 and Refine@5 figures to illustrate that the bound is informative and tracks the reported gains. revision: yes
Circularity Check
No circularity: structural certificate is a derived bound from calibrated quantities, not a re-expression of inputs
full rationale
The paper models feedback-driven solving as a stopped process, identifies three quantities (false-admission risk, program-level evidence, active-state success hazard), calibrates them on held-out traces, and derives a structural certificate that lower-bounds clean success probability. The reported gains (Pass@1 25.8% to 48.5%, Refine@5 +11.0%) are empirical outcomes of instantiated mechanisms (Dual-Granularity Verification, etc.), not predictions forced by the calibration itself. No equations or self-citations in the provided text reduce the certificate to the observed success rate by construction; the bound is presented as an independent mathematical guarantee under the stated assumptions. This is the common case of a self-contained modeling claim supported by separate experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anastasios Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster
-
[2]
InInternational conference on learning representa- tions, Vol
Conformal risk control. InInternational conference on learning representa- tions, Vol. 2024. 55198–55218
2024
-
[3]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. 2025. Researchagent: Iterative research idea generation over scientific literature with large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
2025
-
[4]
Matej Balog, Alexander L Gaunt, Marc Brockschmidt, Sebastian Nowozin, and Daniel Tarlow. 2016. Deepcoder: Learning to write programs.arXiv preprint arXiv:1611.01989(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Rajiv D Banker, Abraham Charnes, and William Wager Cooper. 1984. Some models for estimating technical and scale inefficiencies in data envelopment analysis.Management science30, 9 (1984), 1078–1092
1984
-
[6]
Abraham Charnes, William W Cooper, and Edwardo Rhodes. 1978. Measuring the efficiency of decision making units.European journal of operational research 2, 6 (1978), 429–444
1978
-
[7]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. Codet: Code generation with generated tests.arXiv preprint arXiv:2207.10397(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Koen Claessen and John Hughes. 2000. QuickCheck: a lightweight tool for random testing of Haskell programs. InProceedings of the fifth ACM SIGPLAN international conference on Functional programming. 268–279
2000
-
[11]
Charles J Clopper and Egon S Pearson. 1934. The use of confidence or fiducial limits illustrated in the case of the binomial.Biometrika26, 4 (1934), 404–413
1934
-
[12]
Debrup Das, Debopriyo Banerjee, Somak Aditya, and Ashish Kulkarni. 2024. MATHSENSEI: a tool-augmented large language model for mathematical reason- ing. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 942–966
2024
- [13]
-
[14]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language models. In International conference on machine learning. PMLR, 10764–10799
2023
- [15]
-
[16]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yujiu Yang, Minlie Huang, Nan Duan, Weizhu Chen, et al. 2024. Tora: A tool-integrated reasoning agent for mathe- matical problem solving. InInternational Conference on Learning Representations, Vol. 2024. 48362–48395
2024
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6864–6890
2024
- [19]
-
[20]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Mea- suring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. 2021. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics49, 2 (2021), 1055–1080
2021
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2024. Map- coder: Multi-agent code generation for competitive problem solving. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 4912–4944
2024
-
[24]
Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2025. Codesim: Multi-agent code generation and problem solving through simulation-driven planning and debugging. InFindings of the Association for Computational Lin- guistics: NAACL 2025. 5113–5139
2025
-
[25]
Naman Jain, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Livecodebench: Holistic and contamination free evaluation of large language models for code. In International Conference on Learning Representations, Vol. 2025. 58791–58831
2025
- [26]
-
[27]
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, et al. 2024. Autowebglm: A large language model-based web navigating agent. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5295–5306
2024
-
[28]
2023.AlphaCode 2 Technical Report
Rémi Leblond, Felix Gimeno, Florent Altché, Alaa Saade, Anton Ruddock, Corentin Tallec, George Powell, Jean-Bastien Grill, Maciej Mikuła, Matthias Lochbrunner, et al . 2023.AlphaCode 2 Technical Report. Technical Re- port. Google DeepMind. https://storage.googleapis.com/deepmind-media/ AlphaCode2/AlphaCode2_Tech_Report.pdf Accessed: 2025-01-14
2023
-
[29]
Jierui Li and Raymond Mooney. 2025. AlgoSimBench: Identifying Algorithmically Similar Problems for Competitive Programming.arXiv preprint arXiv:2507.15378 (2025). CP-Agent: A Calibrated Risk-Controlled Agent for Feedback-Driven Competitive Programming Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode.Science378, 6624 (2022), 1092–1097
2022
-
[31]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha
-
[33]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, et al . 2024. Repoagent: An llm-powered open-source framework for repository-level code documentation generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 436–464
2024
-
[35]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[36]
Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems36 (2023), 46534–46594
2023
-
[37]
Zohar Manna and Richard Waldinger. 1980. A deductive approach to program synthesis.ACM Transactions on Programming Languages and Systems (TOPLAS) 2, 1 (1980), 90–121
1980
-
[38]
David A McAllester. 1999. PAC-Bayesian model averaging. InProceedings of the twelfth annual conference on Computational learning theory. 164–170
1999
-
[39]
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. 2025. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models. InProceedings of the 31st ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining V. 2. 6140–6150
2025
-
[40]
OpenAI. 2025. OpenAI o3 System Card.Technical Report(2025)
2025
-
[41]
OpenAI. 2025. System Card: OpenAI o4-mini (including the o4-mini-high variant). https://openai.com/index/o3-o4-mini-system-card/
2025
-
[42]
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. 2025. A new era of intelligence with gemini 3.Google. URL: https://blog. google/products-and- platforms/products/gemini/gemini3 (2025)
2025
- [43]
- [44]
-
[45]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems36 (2023), 8634–8652
2023
-
[46]
Armando Solar-Lezama, Liviu Tancau, Rastislav Bodik, Sanjit Seshia, and Vijay Saraswat. 2006. Combinatorial sketching for finite programs. InProceedings of the 12th international conference on Architectural support for programming languages and operating systems. 404–415
2006
-
[47]
Lee Spector and Alan Robinson. 2002. Genetic programming and autoconstructive evolution with the push programming language.Genetic Programming and Evolvable Machines3, 1 (2002), 7–40
2002
- [48]
-
[49]
DeepReinforce Team, Xiaoya Li, Xiaofei Sun, Guoyin Wang, Songqiao Su, Chris Shum, and Jiwei Li. 2026. GrandCode: Achieving Grandmaster Level in Com- petitive Programming via Agentic Reinforcement Learning.arXiv preprint arXiv:2604.02721(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, Rishi Hazra, Nicolas Bald- win, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Lupidi, et al. 2026. Ai research agents for machine learning: Search, exploration, and generalization in mle-bench.Advances in Neural Information Processing Systems38 (2026), 35309–35348
2026
-
[51]
Vladimir Vovk and Ruodu Wang. 2021. E-values: Calibration, combination and applications.The Annals of Statistics49, 3 (2021), 1736–1754
2021
-
[52]
Junde Wu, Jiayuan Zhu, Yuyuan Liu, Min Xu, and Yueming Jin. 2025. Agentic rea- soning: A streamlined framework for enhancing llm reasoning with agentic tools. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 28489–28503
2025
-
[53]
Shiyi Xu, Hu Yiwen, Yingqian Min, Zhipeng Chen, Xin Zhao, and Ji-Rong Wen
-
[54]
ICPC-Eval: Probing the Frontiers of LLM Reasoning with Competitive Programming Contests.Advances in Neural Information Processing Systems38 (2026)
2026
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Zhiyu Yang, Zihan Zhou, Shuo Wang, Xin Cong, Xu Han, Yukun Yan, Zhenghao Liu, Zhixing Tan, Pengyuan Liu, Dong Yu, et al. 2024. Matplotagent: Method and evaluation for llm-based agentic scientific data visualization. InFindings of the Association for Computational Linguistics: ACL 2024. 11789–11804
2024
-
[57]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
SU Yuhua, Ping NIe, and Xin MeNG. 2025. OI-Assistant: A Retrieval Augmented System for Similar Problem Discovery and Interactive Learning in Competitive Programming. (2025)
2025
-
[59]
Yao Zhang, Zijian Ma, Yunpu Ma, Zhen Han, Yu Wu, and Volker Tresp. 2025. Webpilot: A versatile and autonomous multi-agent system for web task execution with strategic exploration. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23378–23386
2025
-
[60]
Zihan Zheng, Zerui Cheng, Zeyu Shen, Shang Zhou, Kaiyuan Liu, Hansen He, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, et al. 2026. Livecodebench pro: How do olympiad medalists judge llms in competitive programming?Ad- vances in Neural Information Processing Systems38 (2026)
2026
-
[61]
A Calibrated Risk- Controlled Theory of Feedback Control
Yizhang Zhu, Liangwei Wang, Chenyu Yang, Xiaotian Lin, Boyan Li, Wei Zhou, Xinyu Liu, Zhangyang Peng, Tianqi Luo, Yu Li, et al . 2025. A Survey of Data Agents: Emerging Paradigm or Overstated Hype?arXiv preprint arXiv:2510.23587 (2025). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Wang et al. A Tool-Orchestrated Pseudocode Algorithm 1 formalize...
-
[62]
Fix a frozen controller 𝜋
Setting and Conventions 0.1 Probability space and stopped events. Fix a frozen controller 𝜋. A trajectory is generated by sampling one problem from the benchmark distribution and running 𝜋 for at most 𝑇 refinement steps. All probabilities Pr𝜋 (·) are taken with respect to a fresh evaluation trajectory; calibration probabilities are taken with respect to h...
2018
-
[63]
(7) For fixed 𝜋 and step 𝑡, let 𝑛𝜋 𝑡 be the number of active calibration rows, 𝑓 𝜋 𝑡 the count of false admissions, and𝑠 𝜋 𝑡 the count of clean successes
Validity of the Calibration Estimators in Eq. (7) For fixed 𝜋 and step 𝑡, let 𝑛𝜋 𝑡 be the number of active calibration rows, 𝑓 𝜋 𝑡 the count of false admissions, and𝑠 𝜋 𝑡 the count of clean successes. Define ¯𝑞𝜋 𝑡,raw :=UCB Binom 𝑓 𝜋 𝑡 , 𝑛𝜋 𝑡 , 𝛿 2𝑇 , ℎ 𝜋 𝑡 :=LCB Binom 𝑠𝜋 𝑡 , 𝑛𝜋 𝑡 , 𝛿 2𝑇 .(7) The deployment hazards are 𝑞𝜋 𝑡 :=Pr 𝜋 (𝐹𝑡 = 1 |𝐴 𝑡 ) and ℎ𝜋 𝑡 ...
-
[64]
On held-out calibration traces, let 𝑛𝑡 (𝜃) be the number of active candidate admissions with 𝑟𝑡 (𝑍𝑡 ) ≤𝜃 and 𝑓𝑡 (𝜃) the count of such admissions rejected by hidden evaluation
Theorem 2.5: Calibrated Admission Gate Statement.Assume the pre-declaration of Section 0.6:𝜙 𝜋 , the score func- tion 𝑟𝑡 (𝑍𝑡 )=𝜌 𝑡 exp(−𝐼 𝑡 ), the finite non-empty grid Θ𝑡 (with1 ≤ |Θ 𝑡 |< ∞), and the gate rule are fixed by 𝜋 before label counting; any calibrated scalar entering 𝑟𝑡 is enumerated in the finite, non-empty manifest Π𝛼 (with 1 ≤ |Π 𝛼 |<∞ ). O...
2018
-
[65]
On held-out calibration traces, let 𝑛𝜋 𝑡 be the number of active rows at step 𝑡 under 𝜋, and let 𝑓 probe,𝜋 𝑡 count those rows where both𝐵 𝜖 𝑡 =1and𝑊 probe 𝑡 =1
Proposition 2.7: RiskProbe Bad-and-Survive UCB Statement.Let 𝑊 probe 𝑡 ∈ { 0, 1} be the probe-survival indicator at step 𝑡 (set to1when the probe is not invoked). On held-out calibration traces, let 𝑛𝜋 𝑡 be the number of active rows at step 𝑡 under 𝜋, and let 𝑓 probe,𝜋 𝑡 count those rows where both𝐵 𝜖 𝑡 =1and𝑊 probe 𝑡 =1. Define ¯𝜌probe,𝜋 𝑡 :=UCB Binom 𝑓 ...
-
[66]
Proposition 2.8: Candidate-Level Evidence from EvidenceAcquire Statement.Let 𝑊 evid 𝑡 ∈ { 0, 1} denote the program-level evidence-gate survival at step 𝑡 (set to1when the gate is not invoked). On calibration rows that are simultaneously active, bad, and probe-surviving, let ¯𝑏𝜋 𝑡 (𝑚) be the one-sided Clopper–Pearson UCB on Pr 𝜋 (𝑊 evid 𝑡 =1|𝐵 𝜖 𝑡 , 𝑊 prob...
2018
-
[67]
Validity of the Mechanism Factorization in Eq. (9) Eq. (9) defines ¯𝑞𝜋 𝑡,mech = ¯𝜌probe,𝜋 𝑡 exp[ − Ievid,𝜋 𝑡 ], ¯𝑞𝜋 𝑡,ctrl =min{ ¯𝑞𝜋 𝑡,raw, ¯𝑞𝜋 𝑡,mech }.(9) We show that on the good events of Propositions 2.7 and 2.8, ¯𝑞𝜋 𝑡,ctrl is a valid UCB on𝑞 𝜋 𝑡 :=Pr 𝜋 (𝐹𝑡 =1|𝐴 𝑡 ). Proof.Under the gate-semantics requirement of Section 0.2, on𝐴 𝑡 , {𝐹𝑡 =1} ⊆ {𝐵 𝜖 𝑡 ...
-
[68]
The increment Δℎ𝑡 (𝑘, 𝑍𝑡 ) :=ℎ 𝜋 𝑡 (𝑀 ★) −ℎ 𝜋,∅ 𝑡 is the snapshot-on/off LCB gap, used only as a deployment diagnostic; the certificate uses ℎ𝜋 𝑡 (𝑀 ★) directly
Proposition 2.9: ContextAcquire as a Calibrated Hazard Envelope Statement.Under the split 𝐷mem hist →𝐷 cal →𝐷 test and a frozen memory snapshot𝑀 ★, ContextAcquire(𝑘)assignsℎ 𝑡+ ←ℎ 𝜋 𝑡 (𝑀 ★), where ℎ𝜋 𝑡 (𝑀 ★)=LCB Binom 𝑠𝑀★,𝜋 𝑡 , 𝑛 𝑀★,𝜋 𝑡 , 𝜂 ℎ is a Clopper–Pearson LCB estimated on calibration traces using𝑀★. The increment Δℎ𝑡 (𝑘, 𝑍𝑡 ) :=ℎ 𝜋 𝑡 (𝑀 ★) −ℎ 𝜋,∅ ...
-
[69]
Assume the stopped-process con- vention of Section 0.1 and the initial-activity conditionPr 𝜋 (𝐴1 )=1
Corollary 2.10: Stopped Clean-Before-False Certificate Statement.Fix a frozen controller 𝜋. Assume the stopped-process con- vention of Section 0.1 and the initial-activity conditionPr 𝜋 (𝐴1 )=1. On a calibration good event giving simultaneous active-step bounds 𝑞𝜋 𝑡 ≤ ¯𝑞𝜋 𝑡 andℎ 𝜋 𝑡 ≥ℎ 𝜋 𝑡 for all𝑡≤𝑇, a fresh evaluation trajectory satisfies Pr 𝜋 (𝜏𝑆 ≤𝑇 , ...
2018
-
[70]
Theorem 2.6: Simultaneously Valid Finite-Manifest Calibration Statement.Let Π𝛼 be a finite, pre-declared, non-empty class of frozen controllers with1 ≤ |Π 𝛼 |<∞ , declared before 𝐷cal is opened. Each 𝜋∈Π 𝛼 specifies the stop/refine rule, risk-probe invocation policy, evidence intensity 𝑚, context intensity 𝑘, prompts, routing and deduplication rules, deco...
-
[71]
We have 𝜕𝐶𝑇 𝜕 ¯𝑞𝑡 =− Ö 𝑠≠𝑡 (1− ¯𝑞𝑠 ) ≤0, so any reduction in ¯𝑞𝑡 does not decrease𝐶 𝑇
Monotonicity of the Certificate In the unclipped regime, define 𝐶𝑇 = 𝑇Ö 𝑠=1 (1− ¯𝑞𝑠 ) − 𝑇Ö 𝑠=1 (1−ℎ 𝑠 ), ¯𝑞𝑡 = ¯𝜌probe 𝑡 exp(− I evid 𝑡 ). We have 𝜕𝐶𝑇 𝜕 ¯𝑞𝑡 =− Ö 𝑠≠𝑡 (1− ¯𝑞𝑠 ) ≤0, so any reduction in ¯𝑞𝑡 does not decrease𝐶 𝑇 . Since CP-Agent: A Calibrated Risk-Controlled Agent for Feedback-Driven Competitive Programming Conference acronym ’XX, June 03–05,...
2018
-
[72]
Summary of Structural Conditions (1) Across-trajectory independence at fixed 𝑡 is required; within- trajectory step independence is not (Section 0.3). (2) The suite-level Bernoulli treatment does not require independence across the 𝑚 generated tests (Section 4.1); test-level independence is needed only for sequential channel accumulation (Section 4.2). (3...
-
[73]
Sasha and the Apartment Purchase
Compact Proof Skeleton (1) Lemma (Clopper–Pearson with random active denominator).Condi- tioning on the active-row count, the CP UCB/LCB is valid; a union bound covers steps, grids, and manifests. (2) Theorem 2.5.For each (𝑡, 𝜃) , calibrate 𝑝𝑡,𝜃 =Pr(𝐹 𝑡 = 1 |𝐴 𝑡 , 𝑟 𝑡 ≤ 𝜃) ; the finite-grid simultaneous UCB yields a post-selection-valid threshold. (3) Pro...
2018
-
[74]
Correct format example: Thought: [Your thought] Next, I will write C++ code to implement this idea
C++ code must be passed to tool functions (e.g., cpp_validation, hypo_validator, final_answer) as a string. Correct format example: Thought: [Your thought] Next, I will write C++ code to implement this idea. {{code_block_opening_tag}} code = ”’ #include <iostream> int main() ... ”’ result = cpp_validation(code) print(result) {{code_block_closing_tag}}
-
[75]
Only use variables that you have defined!
-
[76]
C++ code must not be executed directly by the Python interpreter!
-
[77]
final_answer
Do not name any new variable as any tool name: e.g., do not name a variable "final_answer"
-
[78]
Do not create any dummy variables in the code, because these variables appearing in logs may mislead you
-
[79]
error\_context
Do not give up! You have no time or step limit for writing code. You are the one solving the task, not providing guidance on how to solve it. Please start solving the problem. G.2 Tool Descriptions G.2.1 Test Case Generator. You are an elite competitive-programming assistant. Produce only valid C++17 code. Use standard I/O (cin/cout). Include every helper...
2018
-
[80]
While implementing divide-and-conquer optimized DP
error_context (required): - Describe the scenario and timing of the error. - Examples: "While implementing divide-and-conquer optimized DP", "When handling large-scale array inputs", "When enumerating subsets using bit operations". - Length: 10–30 words
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.