Reinforcement Learning for Reachability: Guaranteeing Asymptotic Optimality
Pith reviewed 2026-06-30 14:12 UTC · model grok-4.3
The pith
Iteratively refining estimates of unknown MDP parameters allows reinforcement learning to achieve exact optimality for reachability in the limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We argue that while these parameters are unknown in RL, they can be iteratively refined and estimated with increasing accuracy. By iteratively satisfying PAC conditions, we show that exact optimality can be achieved in the limit.
What carries the argument
Iterative refinement of MDP parameters within the PAC learning framework to satisfy guarantees with increasing accuracy until exact optimality holds in the limit.
If this is right
- Exact optimality for reachability is achieved in the limit through the iterative process.
- Convergence dynamics receive explicit theoretical explanation via successive PAC satisfaction.
- Empirical evaluations on standard benchmarks confirm the predicted convergence behavior.
Where Pith is reading between the lines
- The same iterative estimation technique could extend to reachability variants with continuous state spaces.
- Sample efficiency might improve if early loose estimates are used before tightening.
- Links exist to online model learning methods where transition probabilities are updated during execution.
Load-bearing premise
Unknown MDP parameters can be iteratively refined and estimated with increasing accuracy while the PAC guarantees remain valid at each step.
What would settle it
A demonstration that parameter estimates fail to improve sufficiently over iterations or that PAC validity breaks during refinement would show the limit does not reach exact optimality.
Figures

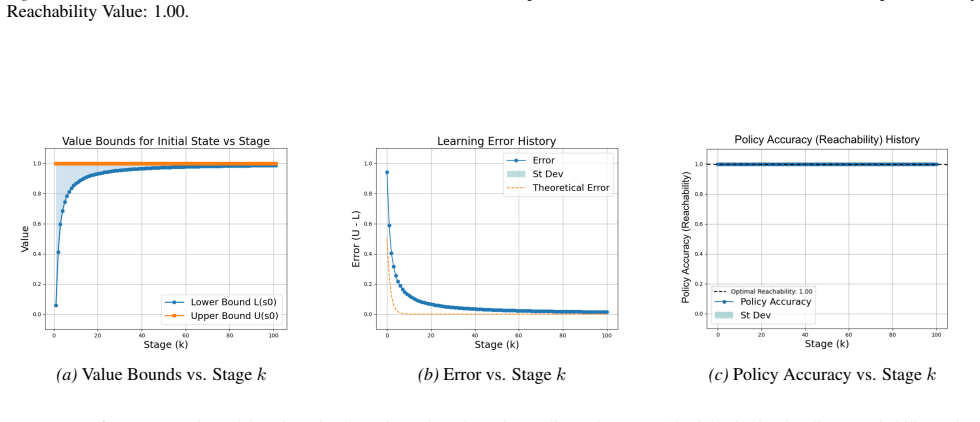
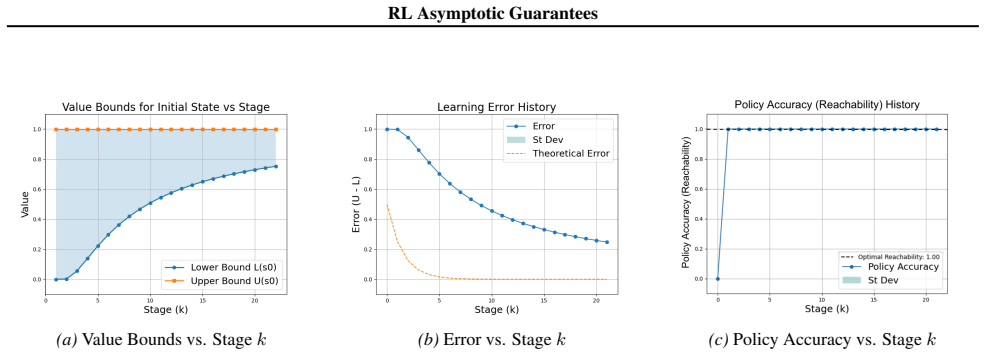
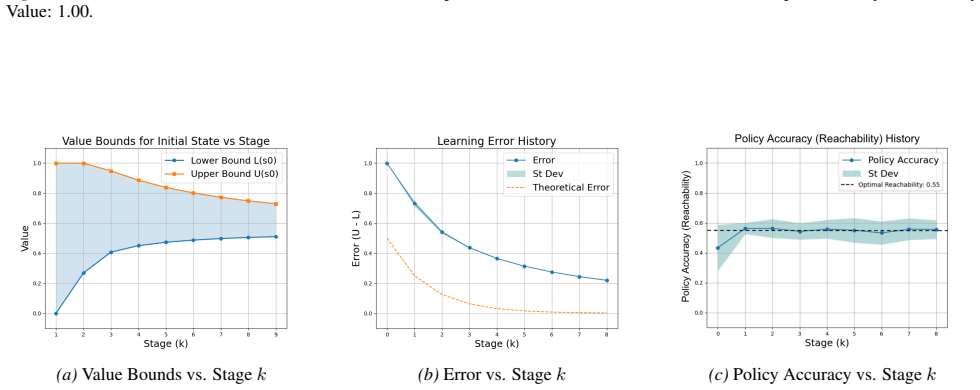
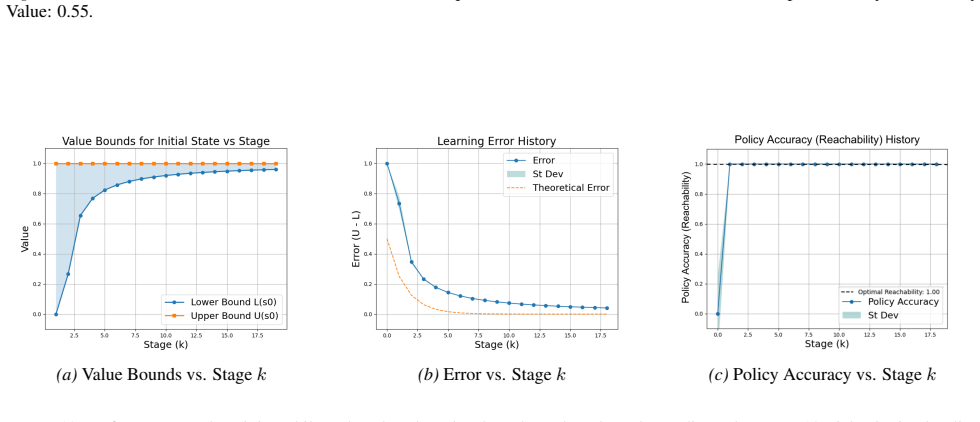
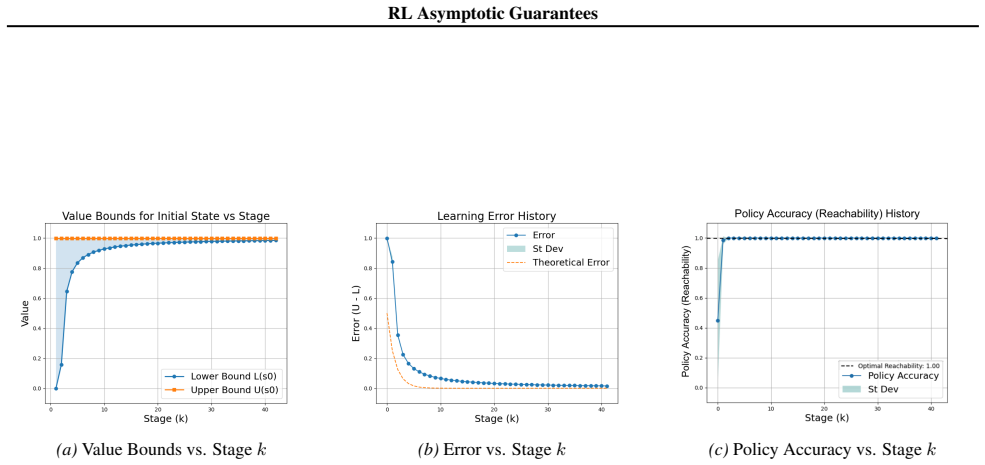
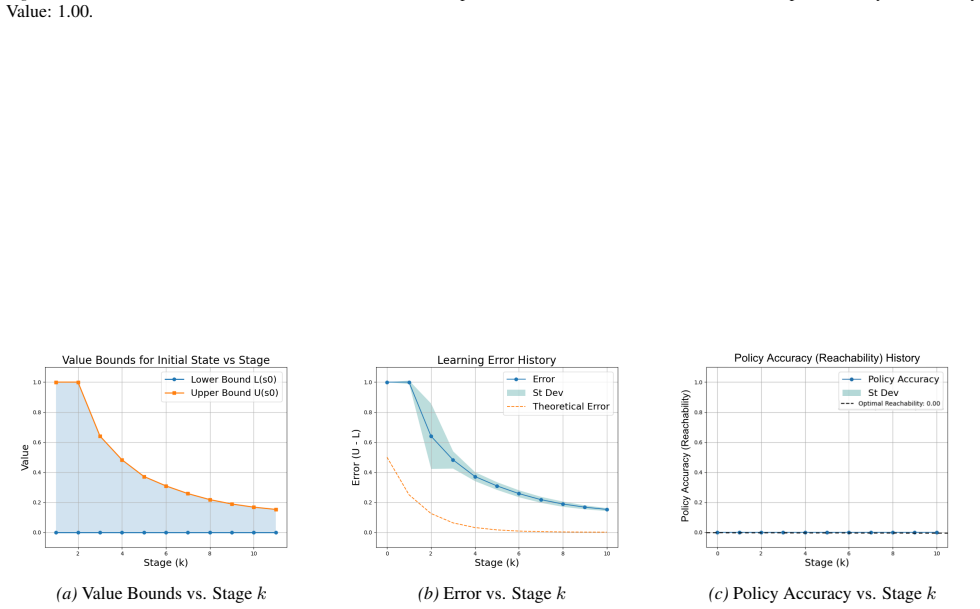
read the original abstract
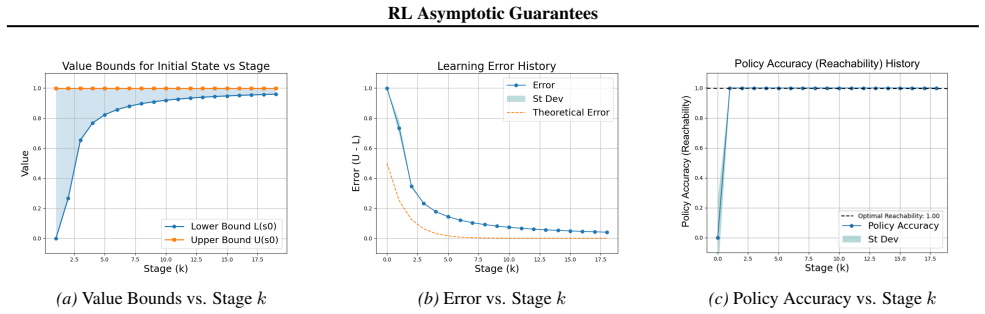
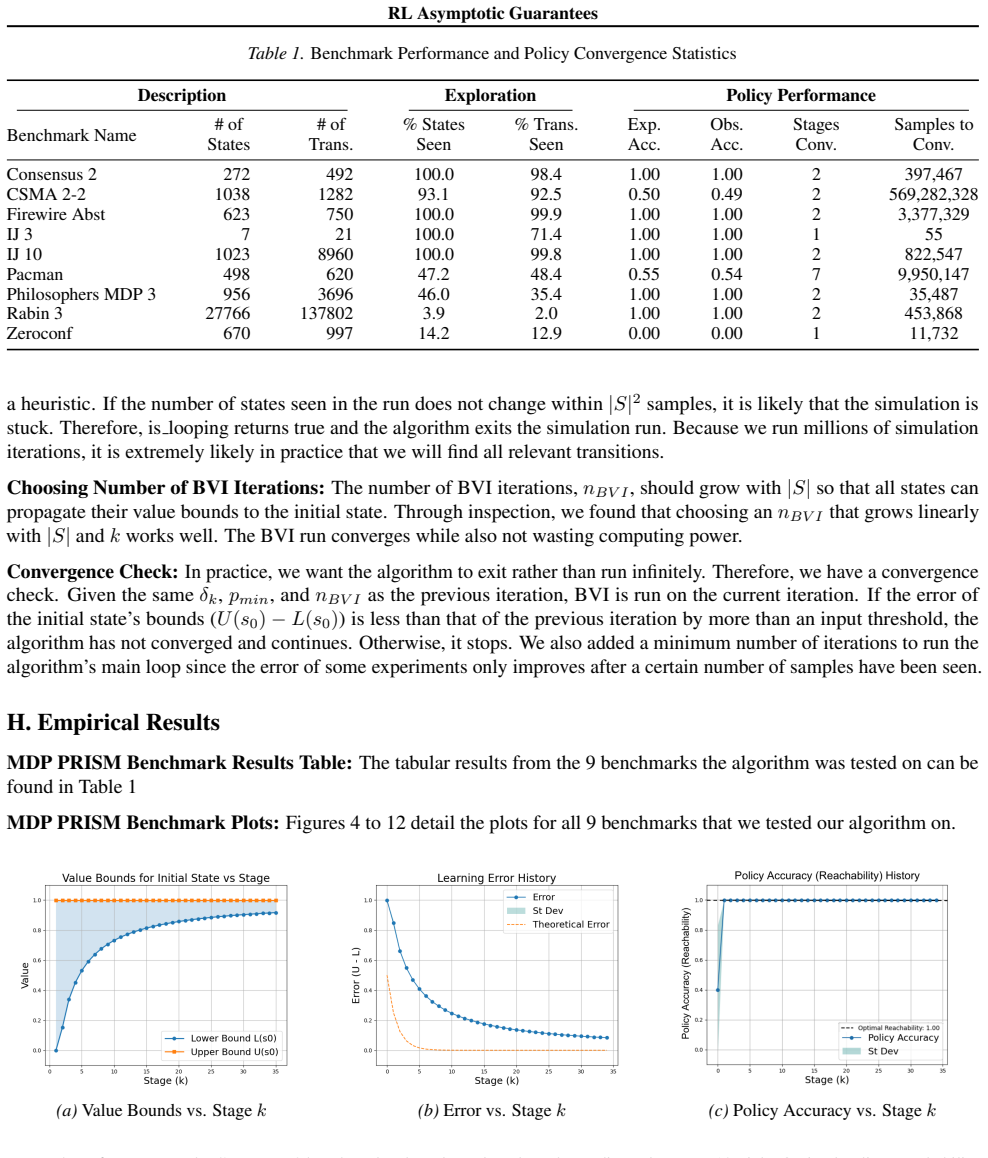
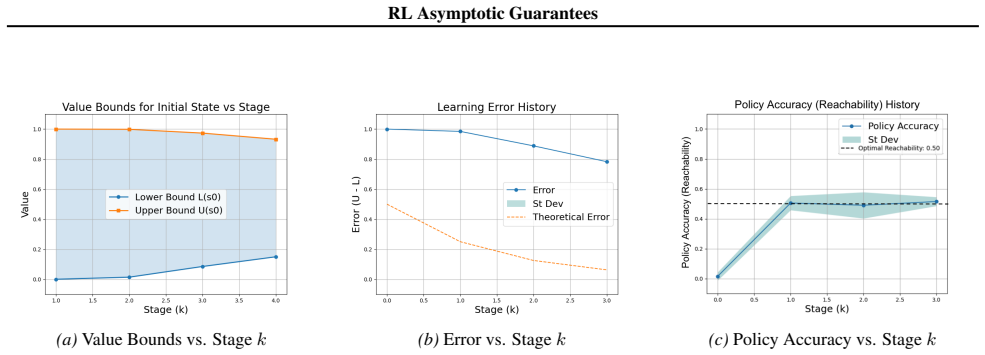
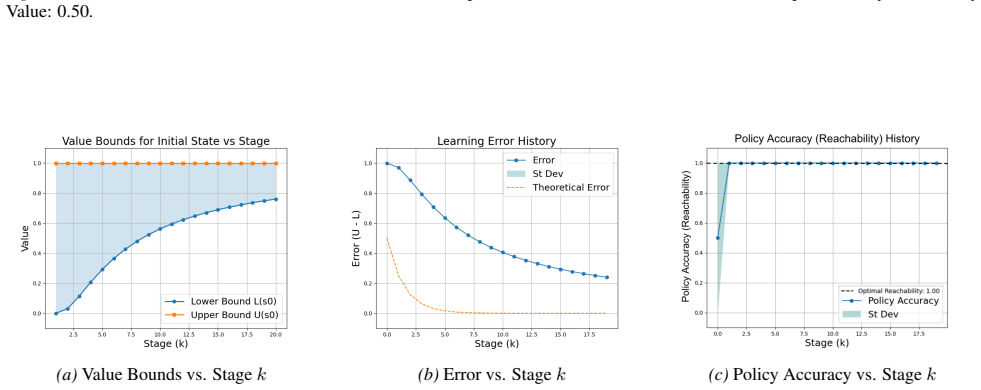
Reinforcement learning (RL) for reachability specifications is fundamental in sequential decision-making, yet theoretical guarantees remain less explored. A recent work achieves asymptotic convergence to optimal policies. However, this approach provides limited insight into convergence dynamics. In this work, we present an alternative approach that provides deeper theoretical insights into convergence. Our approach builds on PAC learning with assumptions. PAC learning guarantees near-optimal policies with high confidence in finite time but requires knowing internal MDP parameters like minimum transition probability. We argue that while these parameters are unknown in RL, they can be iteratively refined and estimated with increasing accuracy. By iteratively satisfying PAC conditions, we show that exact optimality can be achieved in the limit. Empirical evaluations on standard benchmarks validate our theoretical insights into convergence dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for RL with reachability specifications, an iterative procedure can achieve asymptotic optimality by starting from PAC-MDP bounds (which require known parameters such as the minimum transition probability p_min) and successively refining estimates of those parameters from data collected under the current policy; by satisfying the PAC conditions at each iteration with increasingly accurate estimates, the sequence of policies converges to the exact optimum in the limit, yielding deeper insight into convergence dynamics than prior asymptotic results.
Significance. If the derivation is free of circularity, the result would supply a concrete mechanism linking finite-time PAC guarantees to asymptotic optimality for reachability objectives, which is a non-trivial theoretical contribution. The manuscript supplies no machine-checked proofs, reproducible code, or explicit parameter-free derivations, so its primary value would rest on whether the iterative estimation argument is rigorously closed.
major comments (2)
- [Abstract] Abstract (and the theoretical argument summarized therein): the claim that PAC conditions can be iteratively satisfied while p_min is estimated on the fly is load-bearing for the asymptotic-optimality result, yet the abstract supplies no derivation showing how sample sizes are chosen to dominate the unknown true p_min at every finite iteration. An overestimate voids the high-probability guarantee; an underestimate may starve exploration needed to refine the estimate further. Without an explicit dominating schedule or a proof that the sequence of PAC policies still converges w.p. 1, the central claim remains unverified.
- [Abstract] The weakest assumption identified in the reader's report (unknown MDP parameters can be iteratively refined while PAC guarantees remain valid) is not discharged by any cited lemma or theorem in the provided text; the circularity risk noted by the skeptic therefore directly threatens the limit claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for pinpointing the need for a more explicit treatment of the iterative estimation procedure. The comments correctly identify that the abstract summarizes a claim whose supporting derivation requires additional formalization to rule out circularity. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the theoretical argument summarized therein): the claim that PAC conditions can be iteratively satisfied while p_min is estimated on the fly is load-bearing for the asymptotic-optimality result, yet the abstract supplies no derivation showing how sample sizes are chosen to dominate the unknown true p_min at every finite iteration. An overestimate voids the high-probability guarantee; an underestimate may starve exploration needed to refine the estimate further. Without an explicit dominating schedule or a proof that the sequence of PAC policies still converges w.p. 1, the central claim remains unverified.
Authors: We agree that the abstract is too terse on this point. The current manuscript develops the iterative argument at a high level but does not supply an explicit schedule that selects sample sizes to dominate the unknown p_min at each finite step, nor a self-contained proof of almost-sure convergence of the policy sequence. We will add a dedicated lemma and subsection that (i) constructs a conservative, data-driven lower bound sequence for p_min, (ii) gives the corresponding sample-complexity schedule, and (iii) proves that the resulting policies converge to the true optimum with probability 1. revision: yes
-
Referee: [Abstract] The weakest assumption identified in the reader's report (unknown MDP parameters can be iteratively refined while PAC guarantees remain valid) is not discharged by any cited lemma or theorem in the provided text; the circularity risk noted by the skeptic therefore directly threatens the limit claim.
Authors: The manuscript presents the iterative-refinement argument narratively rather than via a cited lemma that explicitly rules out circularity. We accept that this leaves the central limit claim insufficiently grounded. In the revision we will insert a new lemma that shows the process is well-defined: at each iteration the data collected under the current PAC policy is sufficient to produce a strictly tighter estimate of p_min, allowing the next PAC condition to be satisfied with the updated bound, thereby closing the argument without circularity. revision: yes
Circularity Check
No circularity: iterative PAC refinement presented as independent argument
full rationale
The abstract describes building on PAC learning (which requires known parameters such as p_min) by arguing that unknown parameters can be iteratively refined with increasing accuracy, allowing exact optimality in the limit via repeated PAC satisfaction. No equations, self-citations, or explicit reductions are quoted that make the claimed optimality equivalent to its inputs by construction, nor is any fitted parameter renamed as a prediction. The derivation is presented as an extension of standard PAC guarantees with an additional iterative estimation step whose validity is asserted separately; this does not trigger any of the enumerated circularity patterns on the basis of the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PAC learning guarantees near-optimal policies with high confidence in finite time but requires knowing internal MDP parameters like minimum transition probability.
Reference graph
Works this paper leans on
-
[1]
and Henzinger, M
Chatterjee, K. and Henzinger, M. Faster and dynamic algo- rithms for maximal end-component decomposition and re- lated graph problems in probabilistic verification. In Ran- dall, D. (ed.),Proceedings of the Twenty-Second Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2011, San Francisco, California, USA, January 23-25, 2011, pp. 1318–1336. SIAM,
2011
-
[2]
Faster algorithm for turn-based stochastic games with bounded treewidth
Chatterjee, K., Meggendorfer, T., Saona, R., and Svoboda, J. Faster algorithm for turn-based stochastic games with bounded treewidth. In Bansal, N. and Nagarajan, V . (eds.), Proceedings of the 2023 ACM-SIAM Symposium on Dis- crete Algorithms, SODA 2023, Florence, Italy, January 22-25, 2023, pp. 4590–4605. SIAM,
2023
-
[3]
Logically-Constrained Reinforcement Learning
Hasanbeig, M., Abate, A., and Kroening, D. Logically- constrained reinforcement learning.arXiv preprint arXiv:1801.08099,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A pac learning algorithm for ltl and omega-regular objectives in mdps
Perez, M., Somenzi, F., and Trivedi, A. A pac learning algorithm for ltl and omega-regular objectives in mdps. arXiv preprint arXiv:2310.12248,
-
[5]
On the complexity of omega-automata
Safra, S. On the complexity of omega-automata. In29th Annual Symposium on Foundations of Computer Science, White Plains, New York, USA, 24-26 October 1988, pp. 319–327. IEEE Computer Society,
1988
-
[6]
Reinforcement learning from reachability specifications: PAC guaran- tees with expected conditional distance
Svoboda, J., Bansal, S., and Chatterjee, K. Reinforcement learning from reachability specifications: PAC guaran- tees with expected conditional distance. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
2024
-
[7]
Z., Hasanbeig, M., Abate, A., and Kroening, D
Yuan, L. Z., Hasanbeig, M., Abate, A., and Kroening, D. Modular deep reinforcement learning with temporal logic specifications.arXiv preprint arXiv:1909.11591,
-
[8]
In the case of transition probabilities, the empirical and true mean translate to the empirical and true probability of a transition’s probability of occurring
claims that for a random variableX where each Xi is bounded by [ai, bi] P r[| ˆX−µ| ≥ϵ]≤2 exp −2n2ϵ2 Pn i=1(bi −a i)2 where ¯X is the empirical mean, and µ is the true mean. In the case of transition probabilities, the empirical and true mean translate to the empirical and true probability of a transition’s probability of occurring. All transition probabi...
2017
-
[9]
The algorithm runs BVI on the collapsed MDP, which is derived from the discovered partial MDP, as mentioned in Section 3.2
If k≥K P AC, then after running BVI on ˆMC, if P r[U(s C,0)−L(s C,0)≤ε k]≥1−δ T P , then P r[U(s0)−L(s 0)≤ε k]≥1−(δ T P +δ EC) Proof. The algorithm runs BVI on the collapsed MDP, which is derived from the discovered partial MDP, as mentioned in Section 3.2. Therefore, we can only provide guarantees on U(s0)−L(s 0)≤ε k if we provide guarantees on the colla...
2019
-
[10]
By this definition V( ˆMC) is the limit of the best lower bound, L(sC,0), which BVI can obtain using ˆP
V( ˆMC) is the limit of BVI for the partial MDP constructed according to (Ashok et al., 2019). By this definition V( ˆMC) is the limit of the best lower bound, L(sC,0), which BVI can obtain using ˆP . Let the number of BVI iterations be at least r (which can be assumed since the number of BVI iterations increases more than linearly with k). This means tha...
2019
-
[11]
We define Ds,a = lcms′∈S(q(s,a),s′), where lcm is the lowest common multiple of inputs
For s∈S and a∈A , for the row A(s,a),·, we express Pa(s, s′) for a∈A and s, s′ ∈Sas a fraction P(s, a, s ′) = p(s,a),s′ q(s,a),s′ wherep (s,a),s′, q(s,a),s′ ∈Z. We define Ds,a = lcms′∈S(q(s,a),s′), where lcm is the lowest common multiple of inputs. Then, the transition complexity of the whole matrix is defined as the maximum over all rows. In our case, it...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.