Automated Detection and Classification of Delusion-related Content in Naturalistic Audio Diaries Using Multi-Agent Language Models
Pith reviewed 2026-06-30 13:00 UTC · model grok-4.3
The pith
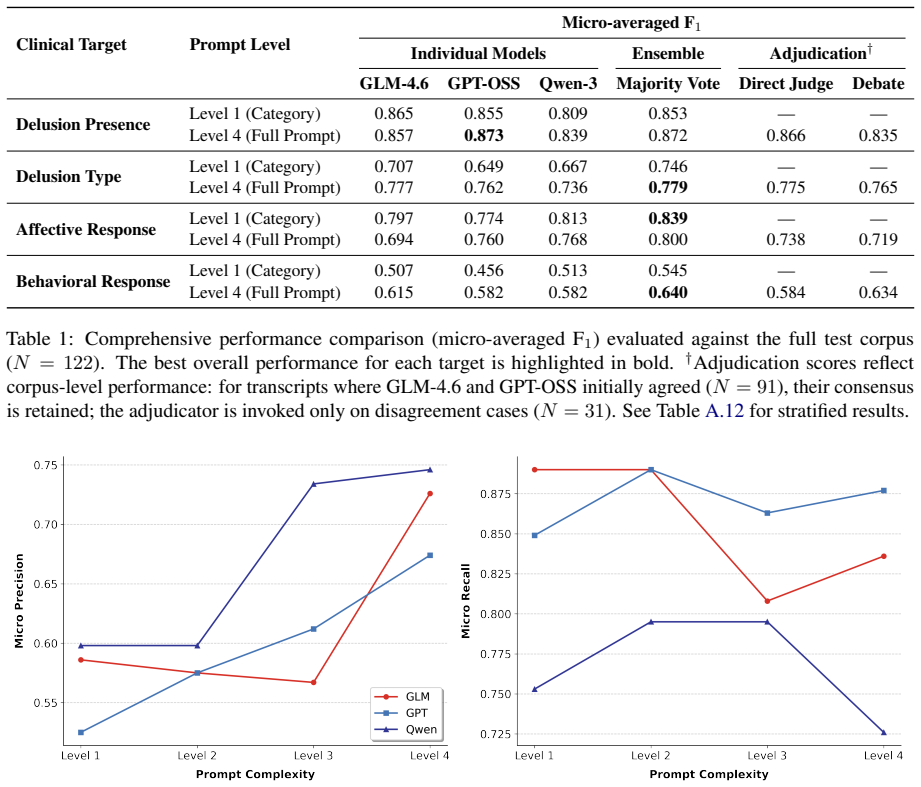
Majority voting among three language models detects delusion-related content in naturalistic audio diary transcripts at Micro F1 scores of 0.872 for detection and 0.779 for classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
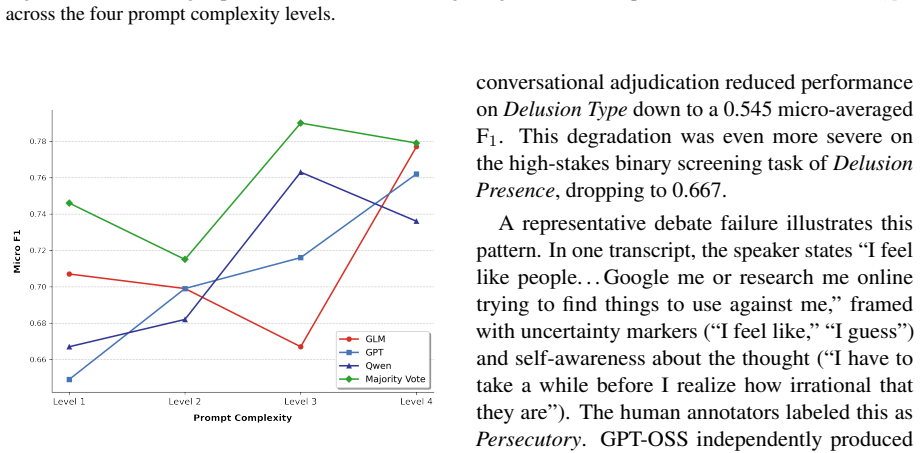
An ensemble of foundation models guided by diagnostic prompts and aggregated via majority voting forms a validated pipeline for multi-label extraction of delusional themes, affective responses, and behavioral responses from naturalistic audio diary transcripts; detailed prompts reduce false positives on theme classification while majority voting yields more reliable results than complex agent debate on clinically ambiguous text.
What carries the argument
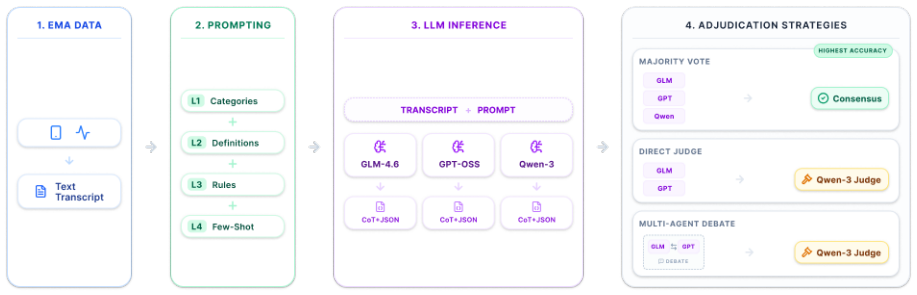
Multi-agent LLM pipeline with majority voting for adjudication of delusion detection and multi-label classification.
If this is right
- Detailed diagnostic prompt instructions reduce false positives during classification of specific delusional themes.
- Complex conversational debate among agents lowers accuracy on clinically ambiguous text through premature consensus.
- Majority voting delivers more robust performance than debate-based adjudication frameworks.
- The resulting pipeline supplies a scalable method for automated characterization of delusion-related content in naturalistic speech.
Where Pith is reading between the lines
- The same prompting and voting approach could be adapted to track other psychiatric symptoms if comparable diagnostic instructions are developed for them.
- Embedding the pipeline in mobile apps might enable passive, longitudinal monitoring of symptom fluctuations in people with persecutory ideation.
- Simpler aggregation rules such as majority voting may prove preferable to elaborate agent interactions in other clinical language tasks that involve interpretive ambiguity.
- Results could shift if the underlying foundation models are replaced with newer versions or with models trained on different clinical corpora.
Load-bearing premise
That diagnostic prompt instructions can be written to cut false positives on delusional theme classification while the models still interpret affective and behavioral cues in ambiguous everyday speech.
What would settle it
A drop in Micro F1 below 0.872 for detection or 0.779 for classification when the same pipeline is run on a fresh collection of audio diary transcripts from a different cohort of participants with comparable persecutory ideation.
Figures
read the original abstract
Speech monologues recorded in naturalistic settings provide opportunities to characterize mental illness phenomenology and detect symptom exacerbation. Large language models (LLMs) offer new possibilities for automating this process, as they require annotated data primarily for evaluation rather than training. In this paper, we present a novel automated, multi-agent LLM pipeline for the fine-grained, multi-label extraction of language suggestive of delusional beliefs, associated affective responses, and behavioral responses from transcripts of naturalistic audio diaries collected from people with moderate persecutory ideation. Evaluating an ensemble of three foundation models, we demonstrate that detailed diagnostic prompt instructions successfully reduce false positives for delusional theme classification, but also constrain the interpretation of affective or behavioral responses. Furthermore, comparing multi-agent adjudication frameworks shows that complex conversational debate between agents diminishes accuracy on clinically ambiguous text by inducing premature consensus. Instead, majority voting establishes robust performance (Micro F1 of 0.872 and 0.779 for delusion detection and classification respectively). This work provides a validated and scalable pipeline for the automated detection and characterization of content suggesting delusional beliefs in naturalistic speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent LLM pipeline for automated, fine-grained, multi-label extraction of delusion-related content (delusional themes, affective responses, behavioral responses) from naturalistic audio diary transcripts of individuals with moderate persecutory ideation. It evaluates an ensemble of three foundation models, shows that detailed diagnostic prompts reduce false positives on theme classification but constrain affective/behavioral interpretation, finds that conversational debate harms accuracy on ambiguous text, and reports that majority voting achieves Micro F1 of 0.872 (detection) and 0.779 (classification).
Significance. If the evaluation holds, the work supplies a scalable, low-training-data approach to characterizing mental-illness phenomenology in real-world speech and supplies a concrete comparison of multi-agent adjudication strategies that is relevant to clinical NLP. The observation that debate induces premature consensus on ambiguous material is a useful domain-specific finding.
major comments (1)
- [Abstract and Evaluation] The central performance claims (Abstract) rest on Micro F1 scores of 0.872 and 0.779 obtained from majority voting over annotated transcripts, yet the manuscript supplies no dataset size, annotation protocol, number or qualifications of raters, or inter-rater reliability statistic (e.g., Cohen’s kappa). Because the transcripts are described as clinically ambiguous, the absence of these details makes it impossible to determine whether the reported scores reflect robust detection or alignment with noisy or inconsistent human labels.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting an important omission in our manuscript. We address the major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The central performance claims (Abstract) rest on Micro F1 scores of 0.872 and 0.779 obtained from majority voting over annotated transcripts, yet the manuscript supplies no dataset size, annotation protocol, number or qualifications of raters, or inter-rater reliability statistic (e.g., Cohen’s kappa). Because the transcripts are described as clinically ambiguous, the absence of these details makes it impossible to determine whether the reported scores reflect robust detection or alignment with noisy or inconsistent human labels.
Authors: We agree that the submitted manuscript omitted these essential details, which are required to properly interpret the reported Micro F1 scores given the clinical ambiguity of the material. In the revised version we will add a dedicated subsection in the Methods section that reports: (1) the total number of transcripts and participants, (2) the full annotation protocol, (3) the number and qualifications of the raters, and (4) the inter-rater reliability statistic (Cohen’s kappa). These additions will directly address the referee’s concern and allow readers to evaluate the quality of the human labels. revision: yes
Circularity Check
No significant circularity; evaluation metrics are independent of model inputs
full rationale
The paper reports Micro F1 scores from majority-voting LLM ensembles evaluated on held-out annotated transcripts. No equations, fitted parameters, or self-citations are used to derive the reported performance; the metrics are computed directly from comparison to external human labels. The abstract explicitly states that annotated data are used only for evaluation, not training. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ChatEval: Towards Better LLM-based Eval- uators through Multi-Agent Debate.arXiv preprint. Version Number: 1. Hyeong Kyu Choi, Xiaojin Zhu, and Sharon Li. 2025. Debate or V ote: Which Yields Better Decisions in Multi-Agent Large Language Models?arXiv preprint. ArXiv:2508.17536 [cs]. Trevor Cohen, Brett Blatter, and Vimla Patel. 2005. Ex- ploring dangerous...
-
[2]
Chandra Kiran and Suprakash Chaudhury
Assessing the sources of unreliability (rater, subject, time-point) in a failed clinical trial using items of the Positive and Negative Syndrome Scale (PANSS).Journal of Clinical Psychopharmacology, 33(1):109–117. Chandra Kiran and Suprakash Chaudhury. 2009. Un- derstanding delusions.Industrial Psychiatry Journal, 18(1):3–18. Yanis Labrak, Mickael Rouvier...
2009
-
[3]
InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Eval- uation (LREC-COLING 2024), pages 2049–2066, Torino, Italia
A Zero-shot and Few-shot Study of Instruction- Finetuned Large Language Models Applied to Clin- ical and Biomedical Tasks. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Eval- uation (LREC-COLING 2024), pages 2049–2066, Torino, Italia. ELRA and ICCL. Aziliz Le Glaz, Yannis Haralambous, Deok-...
2024
-
[4]
Cross-Task Generalization via Natural Language Crowdsourcing Instructions
Machine Learning and Natural Language Pro- cessing in Mental Health: Systematic Review.Jour- nal of Medical Internet Research, 23(5):e15708. Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging Divergent Think- ing in Large Language Models through Multi-Agent Debate. InProceedings...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/wps.20513 2024
-
[5]
SNOMED International
An Empirical Evaluation of Prompting Strate- gies for Large Language Models in Zero-Shot Clini- cal Natural Language Processing: Algorithm Devel- opment and Validation Study.JMIR Medical Infor- matics, 12:e55318. SNOMED International. 2024. SNOMED CT. Yasuaki Sumita, Koh Takeuchi, and Hisashi Kashima
2024
-
[6]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Cognitive Biases in Large Language Mod- els: A Survey and Mitigation Experiments.arXiv preprint. Version Number: 1. Justin Tauscher, Xiruo Ding, Sarah Kopelovich, Arun Nagendra, Kevin Lybarger, Trevor Cohen, and Dror Ben-Zeev. 2025. Automated Flagging of Cognitive Biases in the Spoken Language of People with Hal- lucination Experiences.Journal of Technolo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
I don’t leave my house anymore because I’m scared someone will follow me
Avoidance/Withdrawal: Behaviors aimed at escaping, avoiding, or disengaging from situations, people, or cues linked to distress or delusional beliefs. The individual reduces contact rather than taking action to increase safety. Examples: i. “I don’t leave my house anymore because I’m scared someone will follow me.” ii. “I avoid drinking tap water because ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.