Muon in Vision Transformers: Optimizer-Recipe Interactions and Gradient Spectra
Pith reviewed 2026-06-30 13:47 UTC · model grok-4.3
The pith
Muon optimizer outperforms AdamW in vision transformers, with gains tied to data augmentation strength and broader QKV gradient spectra.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
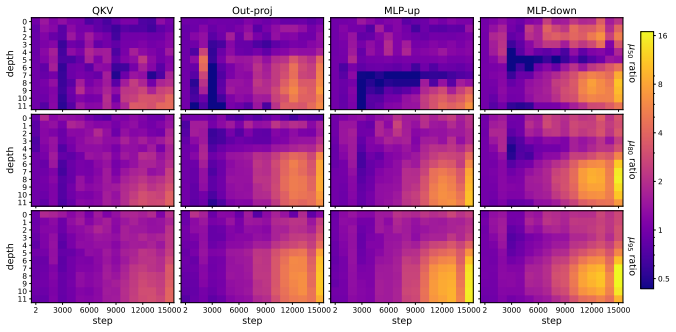
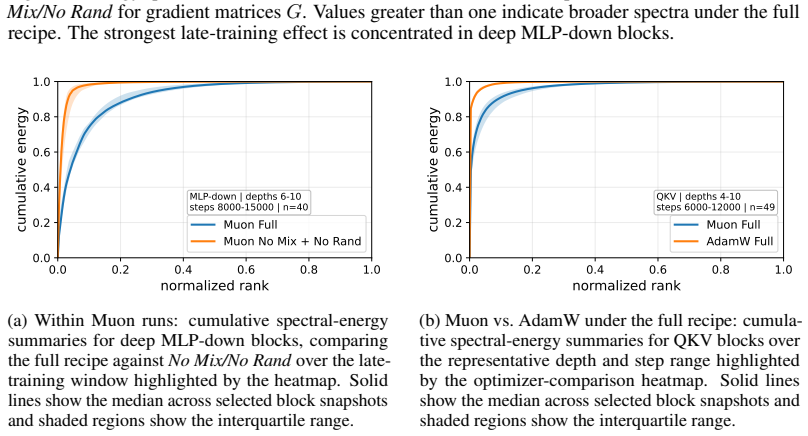
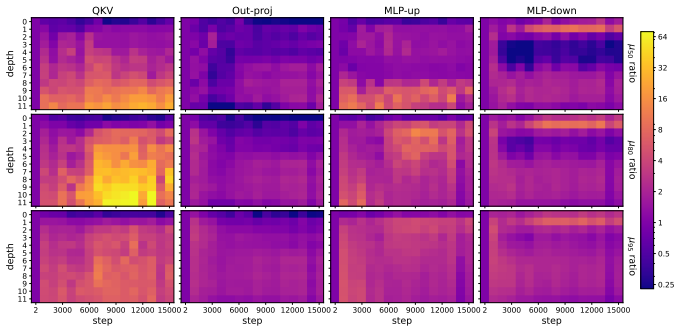
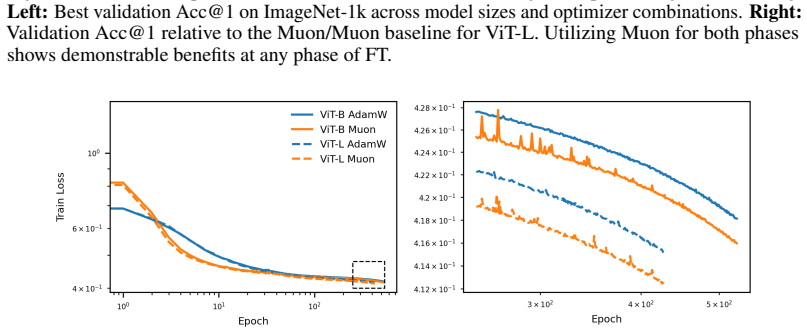
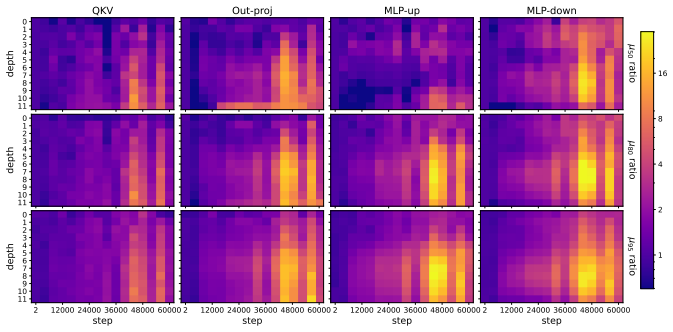
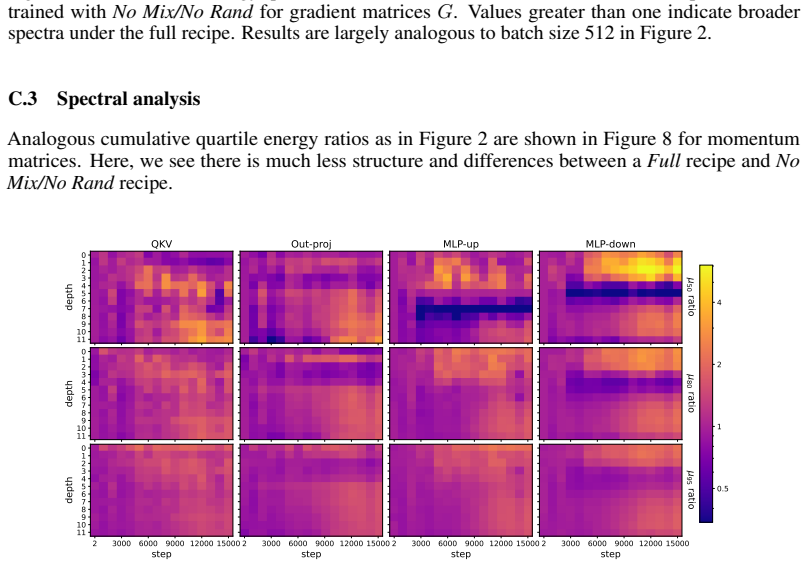
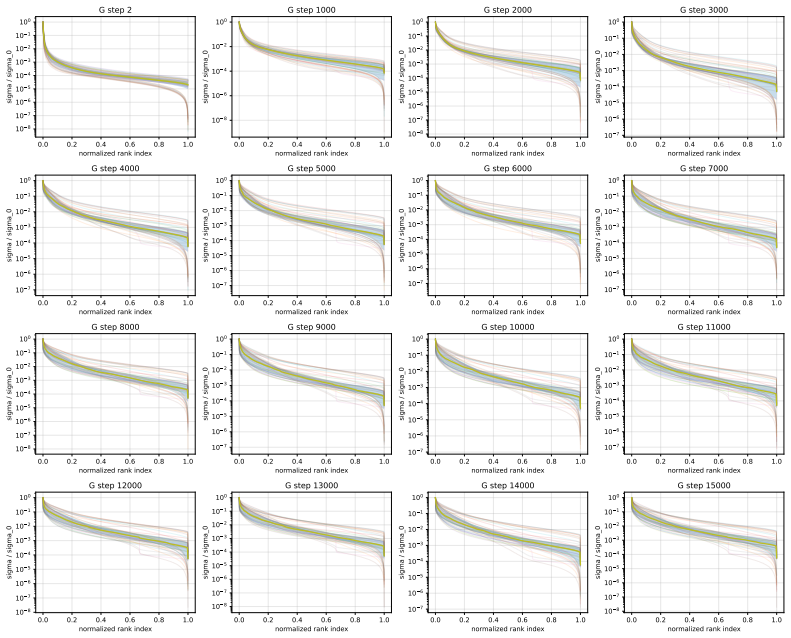
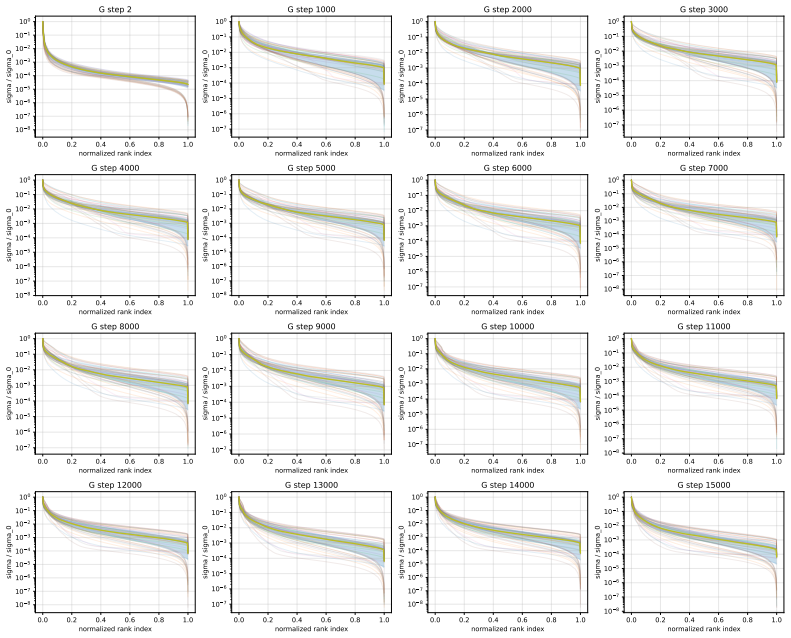
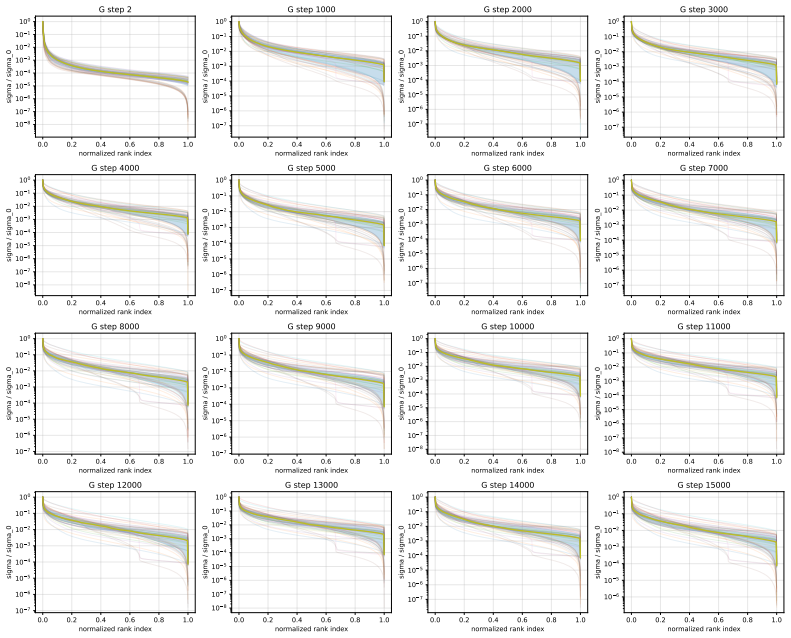
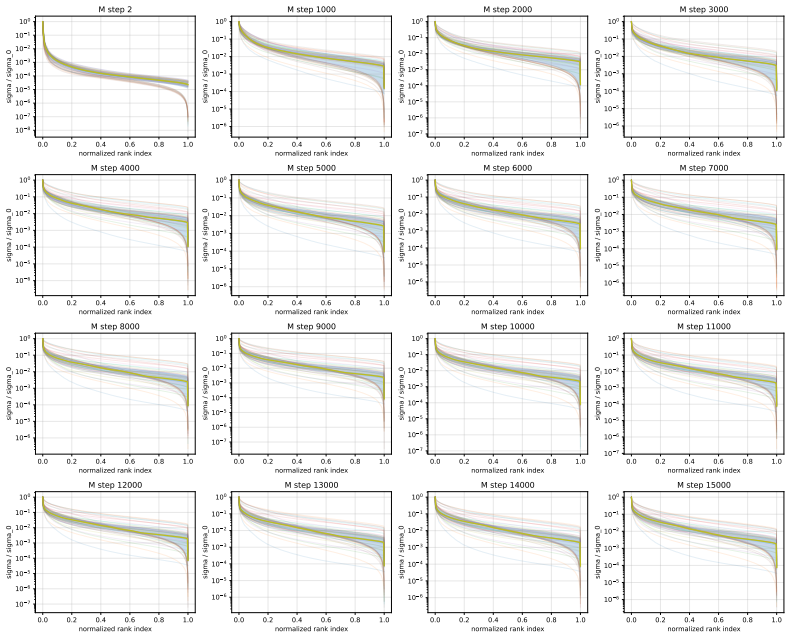
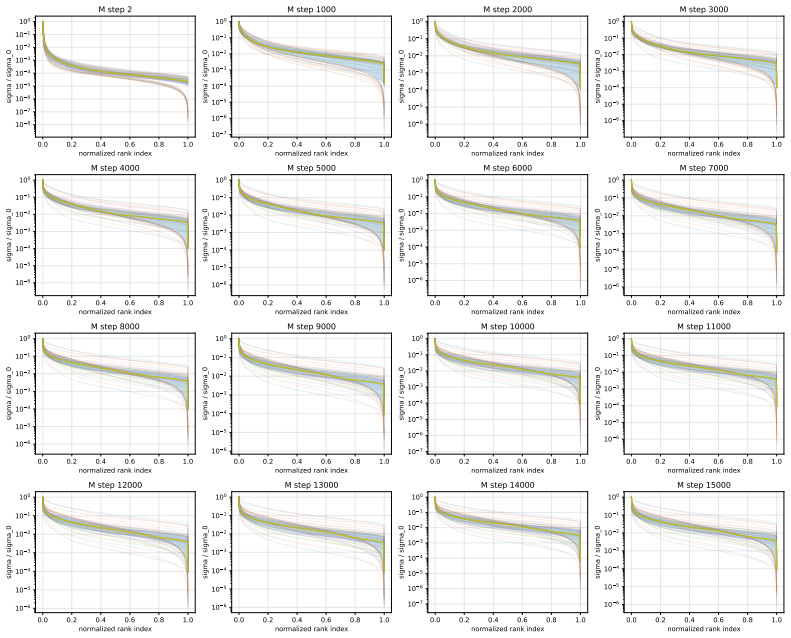
Muon consistently outperforms AdamW across ViT tasks. Under fixed full augmentation the clearest contrast is in QKV gradients, where Muon maintains a broader singular basis while AdamW remains concentrated. Within Muon, full augmentation prevents late-training mode collapse in deep feedforward blocks. Performance gains are largest on long-tailed data and scale with augmentation intensity.
What carries the argument
Singular-value decomposition of matrix gradients, applied to track how optimizer choice and augmentation recipe control the spread of gradient energy across modes in QKV attention projections and MLP layers.
If this is right
- Muon benefits more than AdamW from advanced data augmentation, especially on long-tailed macro metrics.
- Removing heavy augmentation induces spectral concentration and mode collapse in Muon deep MLP-down blocks.
- Under fixed recipe, Muon spreads gradient energy across substantially more singular modes than AdamW in QKV projections.
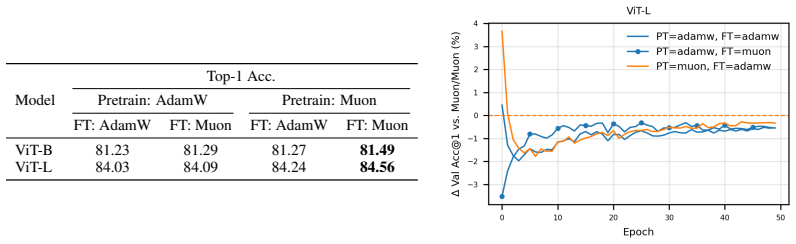
- Muon outperforms AdamW when training ViTs for segmentation and masked autoencoding.
Where Pith is reading between the lines
- Recipe-optimizer matching may be necessary when switching between AdamW and matrix-aware methods in vision tasks.
- Spectral spread in attention gradients could be monitored as a training diagnostic independent of final accuracy.
- The same augmentation dependence might appear when Muon is tested on other transformer architectures or modalities.
Load-bearing premise
Observed performance and spectral differences are produced by the optimizer itself rather than by unstated hyperparameter schedule differences, random seeds, or implementation details.
What would settle it
A run in which AdamW, under identical full augmentation and matched hyperparameter search, matches or exceeds Muon accuracy while producing equally broad QKV singular spectra.
Figures

read the original abstract
Muon is a recently developed matrix-aware optimizer that has shown strong results in transformer training, but its behavior in vision transformers (ViTs) is not yet well understood. We study Muon for ViT training, largely on ImageNet-100 and Pl@ntNet-300K, comparing against AdamW under standard vision recipes involving mixup, cutmix, smoothing, and random augmentation and erasing. Muon consistently outperforms AdamW, with especially large gains on long-tailed Pl@ntNet macro top-1. These gains are also recipe-dependent, where Muon benefits much more than AdamW from advanced and significant data augmentation techniques. To understand this interaction, we analyze the singular-value structure of matrix gradients throughout the ViT. Within Muon training runs, removing heavy data augmentation induces a late-training spectral concentration and mode collapse in gradient matrices, primarily in deep MLP-down blocks. Under a fixed "full" augmentation recipe, the clearest Muon-AdamW contrast appears instead in QKV gradients, where AdamW gradient energy remains concentrated in a much narrower basis while Muon spreads energy across substantially more singular modes. Muon in ViTs is therefore best understood as an optimizer-recipe interaction. Under a fixed recipe, Muon differs from AdamW most clearly in attention projections, where its gradients consist of a broader spectral basis. Within Muon, a full training recipe is important for preventing late spectral concentration and mode collapse in deep feedforward blocks. We further demonstrate efficacy in training ViTs on image segmentation and masked autoencoder models, where Muon outperforms AdamW in all settings considered.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the Muon optimizer in Vision Transformers, comparing it to AdamW on ImageNet-100 and Pl@ntNet-300K under standard and varied data-augmentation recipes (mixup, cutmix, random augment, erasing). It claims Muon consistently outperforms AdamW, with especially large gains on long-tailed Pl@ntNet macro top-1 accuracy; these gains are recipe-dependent, with Muon benefiting more from advanced augmentations. Gradient singular-value analysis shows that, under a fixed full-augmentation recipe, AdamW QKV gradients concentrate energy in a narrower basis while Muon spreads across more modes; within Muon runs, removing heavy augmentation induces late-training spectral concentration and mode collapse in deep MLP-down blocks. Additional results are reported for image segmentation and masked autoencoders.
Significance. If the performance deltas and spectral contrasts are shown to arise from the optimizer under identical non-optimizer factors, the work would usefully document optimizer-recipe interactions in ViTs and supply a spectral lens on why matrix-aware updates differ from AdamW in attention projections. The observation that augmentation prevents mode collapse inside Muon runs and the extension to segmentation/MAE tasks would add practical value for training vision models.
major comments (3)
- [Experimental setup / results] Experimental setup (results and methods sections): the manuscript supplies no explicit statement that learning-rate schedules, weight-decay values, gradient-clipping norms, batch statistics, or random seeds were locked identically for Muon and AdamW. Because the central claim attributes both the macro top-1 gains on Pl@ntNet and the QKV singular-mode spread to Muon’s matrix-aware rule, the absence of this control is load-bearing; any unstated difference could produce the observed contrasts.
- [Results tables/figures] Performance tables and figures (throughout results): no error bars, standard deviations across seeds, or statistical significance tests are reported for the claimed consistent outperformance or the especially large Pl@ntNet macro gains. Without these, the strength of the optimizer-recipe interaction claim cannot be assessed.
- [Gradient spectra analysis] Gradient spectra analysis (QKV and MLP sections): the statements that AdamW energy remains “concentrated in a much narrower basis” and that Muon “spreads energy across substantially more singular modes” are presented qualitatively; no quantitative metric (e.g., effective rank, cumulative energy threshold, or statistical comparison of singular-value distributions) is supplied to support the contrast under the fixed full-augmentation recipe.
minor comments (2)
- [Gradient analysis] Notation for singular-value spectra is introduced without a clear definition of the matrix whose SVD is taken (e.g., whether it is the full gradient matrix or a per-layer slice).
- [Abstract / results] The abstract states “Muon consistently outperforms AdamW” yet the main text does not quantify how many independent runs underlie this statement.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we have revised the manuscript to address the concerns.
read point-by-point responses
-
Referee: [Experimental setup / results] Experimental setup (results and methods sections): the manuscript supplies no explicit statement that learning-rate schedules, weight-decay values, gradient-clipping norms, batch statistics, or random seeds were locked identically for Muon and AdamW. Because the central claim attributes both the macro top-1 gains on Pl@ntNet and the QKV singular-mode spread to Muon’s matrix-aware rule, the absence of this control is load-bearing; any unstated difference could produce the observed contrasts.
Authors: We confirm that all listed hyperparameters were set identically for both optimizers, with differences only in the optimizer-specific settings (e.g., Muon's momentum parameters). We have added an explicit statement in the Experimental Setup subsection of the Methods section to clarify this: 'Unless otherwise noted, all training hyperparameters including learning rate schedule, weight decay, gradient clipping norm, batch size, and random seeds were identical between Muon and AdamW runs.' This ensures the observed differences are attributable to the optimizer. revision: yes
-
Referee: [Results tables/figures] Performance tables and figures (throughout results): no error bars, standard deviations across seeds, or statistical significance tests are reported for the claimed consistent outperformance or the especially large Pl@ntNet macro gains. Without these, the strength of the optimizer-recipe interaction claim cannot be assessed.
Authors: We acknowledge the value of reporting variability. However, the experiments were conducted with single random seeds due to the substantial computational resources required for training ViTs on these datasets. The performance deltas are substantial (e.g., several percentage points on Pl@ntNet macro accuracy), making them unlikely to be due to random variation. We have added a limitations paragraph noting the single-run nature of the results and encouraging future multi-seed validation. revision: partial
-
Referee: [Gradient spectra analysis] Gradient spectra analysis (QKV and MLP sections): the statements that AdamW energy remains “concentrated in a much narrower basis” and that Muon “spreads energy across substantially more singular modes” are presented qualitatively; no quantitative metric (e.g., effective rank, cumulative energy threshold, or statistical comparison of singular-value distributions) is supplied to support the contrast under the fixed full-augmentation recipe.
Authors: We agree that quantitative support would strengthen this section. We have computed the effective rank (number of singular values exceeding 1% of the largest singular value) for the QKV gradient matrices under the full augmentation recipe. This metric shows Muon gradients having approximately 1.8x higher effective rank than AdamW on average across layers. We have updated the text and added a table summarizing these effective ranks to provide a quantitative basis for the spectral spread claim. revision: yes
Circularity Check
No circularity: purely empirical comparisons and spectral observations
full rationale
The paper consists of experimental runs comparing Muon vs. AdamW on ImageNet-100 and Pl@ntNet-300K under fixed recipes, plus direct singular-value analysis of gradient matrices (QKV and MLP blocks). No equations, predictions, or uniqueness claims are present that could reduce to fitted parameters, self-citations, or ansatzes defined by the authors. All reported deltas and spectral spreads are measured outputs from the runs themselves, not derived quantities. This matches the reader's assessment of score 1.0 and satisfies the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard vision training recipes (mixup, cutmix, label smoothing, random augmentation and erasing) constitute a fair and representative comparison setting for optimizer evaluation.
Reference graph
Works this paper leans on
-
[1]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm, 2025
2025
-
[2]
Fastpose-vit: A vision transformer for real-time spacecraft pose estimation
Pierre Ancey, Andrew Price, Saqib Javed, and Mathieu Salzmann. Fastpose-vit: A vision transformer for real-time spacecraft pose estimation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7873–7882, 2026
2026
-
[3]
Long-tailed learning with muon optimizer
Anonymous. Long-tailed learning with muon optimizer. InInternational Conference on Learning Representations (under review), 2026
2026
-
[4]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[5]
Data2vec: A general framework for self-supervised learning in speech, vision and language
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: A general framework for self-supervised learning in speech, vision and language. In International conference on machine learning, pages 1298–1312. PMLR, 2022
2022
-
[6]
Towards understanding orthogonalization in muon
Valentyn Boreiko, Zhiqi Bu, and Sheng Zha. Towards understanding orthogonalization in muon. InICML Workshop on High-dimensional Learning Dynamics, 2025
2025
-
[7]
Muon optimizes under spectral norm constraints, 2025
Linjian Chen, Jialu Li, and Longqiang Qiang. Muon optimizes under spectral norm constraints, 2025. 10
2025
-
[8]
Weiye Chen, Qingen Zhu, and Qian Long. Muon-accelerated attention distillation for real-time edge synthesis via optimized latent diffusion.arXiv preprint arXiv:2504.08451, 2025
-
[9]
Xception: Deep learning with depthwise separable convolutions
François Chollet. Xception: Deep learning with depthwise separable convolutions. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017
2017
-
[10]
Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V
Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V . Le. Randaugment: Practical automated data augmentation with a reduced search space. InAdvances in Neural Information Processing Systems, 2020
2020
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[12]
To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters
Sara Dragutinovi´c and Rajesh Ranganath. To use or not to use muon: How simplicity bias in optimizers matters.arXiv preprint arXiv:2603.00742, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Pl@ntnet-300k: A plant image dataset with high label ambiguity and a long-tailed distribution
Camille Garcin, Alexis Joly, Pierre Bonnet, Antoine Affouard, Jean-Christophe Lombardo, Mathias Chouet, Maximilien Servajean, Titouan Lorieul, and Joseph Salmon. Pl@ntnet-300k: A plant image dataset with high label ambiguity and a long-tailed distribution. InNeurIPS 2021 Datasets and Benchmarks Track, 2021
2021
-
[14]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[15]
Specformer: Guarding vision transformer robustness via maximum singular value penalization
Xixu Hu, Runkai Zheng, Jindong Wang, Cheuk Hang Leung, Qi Wu, and Xing Xie. Specformer: Guarding vision transformer robustness via maximum singular value penalization. InEuropean Conference on Computer Vision, pages 345–362. Springer, 2024
2024
-
[16]
Orthogonal transformer: An efficient vision trans- former backbone with token orthogonalization
Huaibo Huang, Xiaoqiang Zhou, and Ran He. Orthogonal transformer: An efficient vision trans- former backbone with token orthogonalization. InAdvances in Neural Information Processing Systems, 2022
2022
-
[17]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
2021
-
[18]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. Referenced in later Muon theory papers; public design note available at Keller Jordan blog
2024
-
[19]
Optimal whitening and decorrelation.The American Statistician, 72(4):309–314, 2018
Agnan Kessy, Alex Lewin, and Korbinian Strimmer. Optimal whitening and decorrelation.The American Statistician, 72(4):309–314, 2018
2018
-
[20]
Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
Gyu Yeol Kim and Min-hwan Oh. Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
-
[21]
Polargrad: A class of matrix-gradient optimizers from a unifying preconditioning perspective, 2025
Tim Tsz-Kit Lau, Qi Long, and Weijie Su. Polargrad: A class of matrix-gradient optimizers from a unifying preconditioning perspective, 2025
2025
-
[22]
Muon is scalable for llm training, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, et al. Muon is scalable for llm training, 2025
2025
-
[23]
Fully convolutional networks for se- mantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for se- mantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015
2015
-
[24]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. 11
2019
-
[25]
Optimizing neural networks with kronecker-factored approx- imate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015
2015
-
[26]
Haruhiko Murata and Kazuhiro Hotta. Svd-vit: Does svd make vision transformers attend more to the foreground?arXiv preprint arXiv:2602.02765, 2026
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[29]
Artem Riabinin, Egor Shulgin, Kaja Gruntkowska, and Peter Richtárik. Gluon: Making muon & scion great again! (bridging theory and practice of lmo-based optimizers for llms).arXiv preprint arXiv:2505.13416, 2025
-
[30]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[31]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Ben S Southworth and Stephen Thomas. Beyond muon: Mud (momentum decorrelation) for faster transformer training.arXiv preprint arXiv:2603.17970, 2026
-
[33]
Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zhong. Loveda: A re- mote sensing land-cover dataset for domain adaptive semantic segmentation.arXiv preprint arXiv:2110.08733, 2021
- [34]
-
[35]
O-vit: Orthogonal vision transformer, 2022
Yikai Wang, Xiang Li, Yawen Huang, Tong He, Hengshuang Zhao, and Hongsheng Li. O-vit: Orthogonal vision transformer, 2022
2022
-
[36]
Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
2021
-
[37]
Efficient adaptation of pre-trained vision transformer underpinned by approximately orthogonal fine-tuning strategy, 2025
Yiting Yang, Hao Luo, Yuan Sun, Qingsen Yan, Haokui Zhang, Wei Dong, Guoqing Wang, Peng Wang, Yang Yang, and Hengtao Shen. Efficient adaptation of pre-trained vision transformer underpinned by approximately orthogonal fine-tuning strategy, 2025
2025
-
[38]
Cutmix: Regularization strategy to train strong classifiers with localizable features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6023–6032, 2019
2019
-
[39]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InInternational Conference on Learning Representations, 2018
2018
-
[40]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 13001–13008, 2020. 12 A Computational cost of Muon From a practical perspective, Muon is computationally more expensive than AdamW due to the approximate orthogonalization. Exac...
2020
-
[41]
If M=UΣV ⊤ =⇒G=UΣ 2U T is the thin singular value decomposition, then fMZCA =U V ⊤, which is exactly the left polar factor of M
ZCA whitening– The ZCA transform is WZCA =G −1/2 =⇒ fMZCA =G −1/2M. If M=UΣV ⊤ =⇒G=UΣ 2U T is the thin singular value decomposition, then fMZCA =U V ⊤, which is exactly the left polar factor of M. Thus, in our setting, ZCA whitening and polar orthogonalization coincide [19, 21]
-
[42]
This is expressed in principal coordinates rather than the original row basis [ 19]
PCA whitening– PCA whitening applies the inverse square root in the eigenbasis of G: fMPCA = Σ −1U ⊤M=V ⊤. This is expressed in principal coordinates rather than the original row basis [ 19]. Unlike ZCA, PCA whitening requires explicit access to the eigenbasis U and therefore does not admit a simple Muon-style polynomial iteration in terms ofGalone. 13
-
[43]
Cholesky whitening– If G=CC ⊤ is the Cholesky factorization, thenfMchol =C −1M. This whitening transformation is asymmetric and ordering-dependent [19], but the factoriza- tion is deterministic rather than iterative in nature (as singular value or eigendecompositions are)
-
[44]
Then ZCA-cor whitening is fMZCAcor =P −1/2D−1/2M
ZCA-cor whitening– Let D= diag(G) , or equivalently Dii =∥M i:∥2, and P= D−1/2GD−1/2. Then ZCA-cor whitening is fMZCAcor =P −1/2D−1/2M. Equivalently, one first row-normalizesM and then applies ZCA whitening. In our matrix-update language, this is arow-normalized polar factor, and can be approximated in analogous ways as Muon
-
[45]
As with PCA whitening, this method requires an explicit eigenspace rotation, which cannot be approximated via cheap polynomial iterations
PCA-cor whitening– Similarly, let fMPCAcor = Θ−1/2H ⊤D−1/2M, where P=HΘH ⊤ is the eigendecomposition of the correlation matrix. As with PCA whitening, this method requires an explicit eigenspace rotation, which cannot be approximated via cheap polynomial iterations. As stated above, PCA and PCA-cor require explicit eigenvector extraction and thus do not a...
-
[46]
convolutional neural network on ImageNet-100 under theNo Mix/No RandandFullrecipes. For 17 0.0 0.2 0.4 0.6 0.8 1.0 normalized rank index 10 8 10 7 10 6 10 5 10 4 10 3 10 2 10 1 100 sigma / sigma_0 G step 2 0.0 0.2 0.4 0.6 0.8 1.0 normalized rank index 10 7 10 6 10 5 10 4 10 3 10 2 10 1 100 sigma / sigma_0 G step 1000 0.0 0.2 0.4 0.6 0.8 1.0 normalized ran...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.