Parameter-Efficient VLMs for Gastrointestinal Endoscopy: Medical Image Generation and Clinical Visual Question Answering
Pith reviewed 2026-06-30 12:35 UTC · model grok-4.3
The pith
Parameter-efficient fine-tuning enables high-scoring visual question answering and privacy-preserving synthetic image generation for gastrointestinal endoscopy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a parameter-efficient dual pipeline, built on Florence-2 for visual question answering and rank-4 LoRA adaptation of Stable Diffusion 2.1 for image synthesis, delivers ROUGE-1 of 0.92, ROUGE-L of 0.91, BLEU improvement from 0.08 to 0.24, fidelity 0.290, agreement 0.730, and Frechet BiomedCLIP Distance of 1450 on the Kvasir-VQA dataset, reduces computational cost by nearly 90 percent, and produces better image-text coherence than FLUX, MSDM, and Kandinsky 2.2 while performing even better after fine-tuning on private data.
What carries the argument
The dual-pipeline parameter-efficient fine-tuning framework that combines the Florence-2 vision-language model for visual question answering with Low-Rank Adaptation on Stable Diffusion 2.1 for medical image generation.
If this is right
- Fine-tuning on private datasets produces better results than fine-tuning on public datasets alone.
- The rank-4 LoRA setting gives the best combination of fidelity, agreement, and Frechet BiomedCLIP Distance among the ranks tested.
- The generated images achieve lower Frechet BiomedCLIP Distance than those from FLUX, MSDM, and Kandinsky 2.2, showing stronger semantic alignment.
- Training cost drops by almost 90 percent relative to standard fine-tuning while maintaining the reported metric levels.
Where Pith is reading between the lines
- The same pipeline could be tested on other endoscopy tasks such as polyp detection or lesion segmentation to check whether synthetic data helps there as well.
- Hospitals without large public datasets might still obtain usable models by combining limited private data with the generated images.
- If the synthetic images preserve enough clinical detail, they could reduce the need to share real patient images across institutions.
- The observed advantage of private-data fine-tuning implies that deployment would likely require each site to run its own adaptation step.
Load-bearing premise
The performance numbers measured on the public Kvasir-VQA dataset indicate real clinical usefulness and that the synthetic images will improve downstream tasks without further checks on private clinical data.
What would settle it
Running the trained VQA model on a new private clinical endoscopy dataset and measuring whether adding the synthetic images raises accuracy would show whether the reported gains transfer outside the public test set.
Figures
read the original abstract
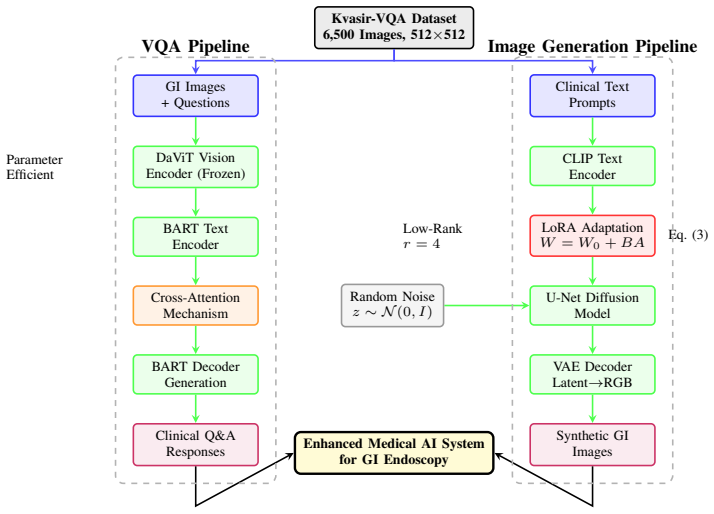
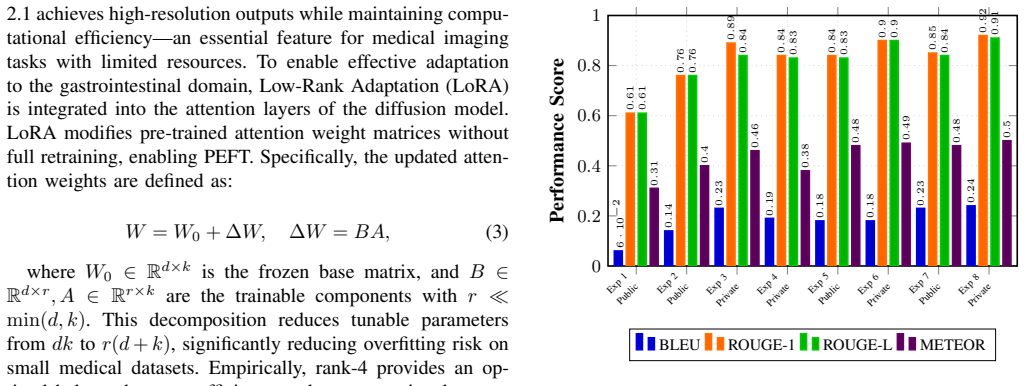
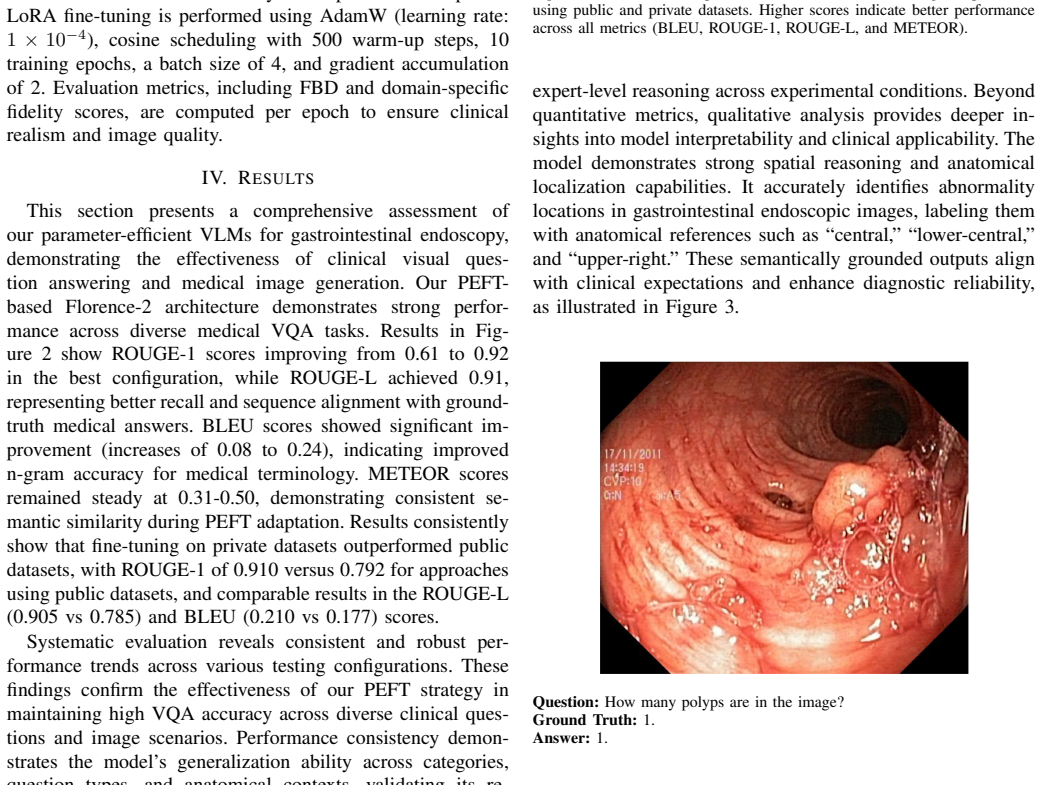
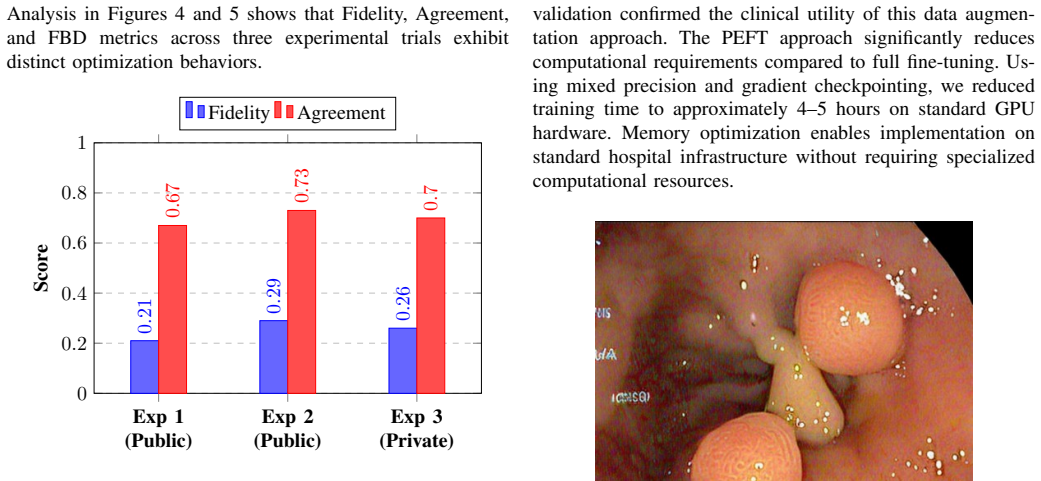
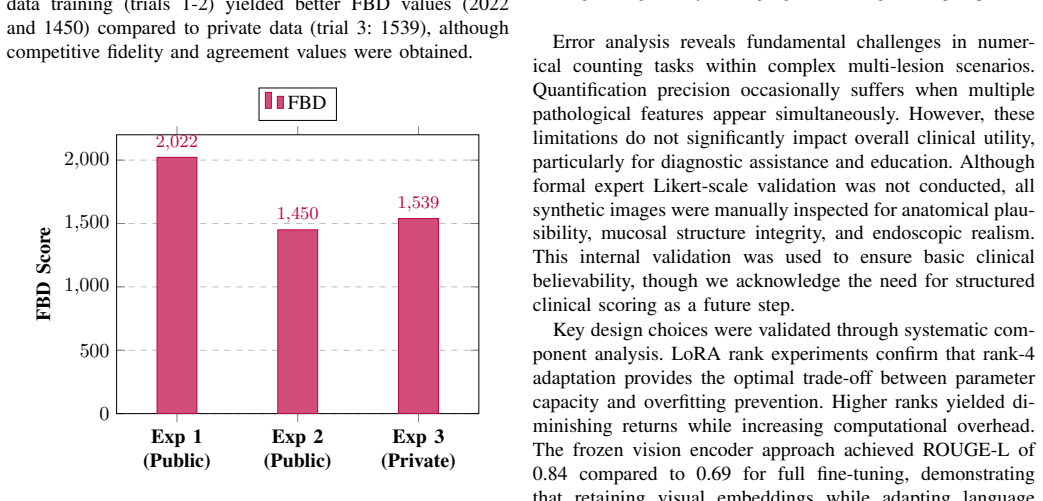
The major limitations of gastrointestinal (GI) endoscopy AI systems arise from a shortage of annotated data, strict privacy policies, and significant bottlenecks in conventional model fine-tuning. Such limitations impede the successful application of sophisticated AI models in clinical practice, particularly affecting the reliability and scalability of diagnosis. In this paper, we present a dual-pipeline PEFT model that addresses two fundamental problems: medical Visual Question Answering (VQA) and the generation of privacy-preserving synthetic data. For clinical VQA, we adopt the Florence-2 vision-language model. Leveraging PEFT enhances model interpretability while substantially reducing the computational cost of training. Simultaneously, we employ Low-Rank Adaptation (LoRA) with Stable Diffusion 2.1 to generate high-quality GI images that enhance training databases without violating patient privacy. This research utilized the Kvasir-VQA dataset. Our Florence-2 VQA model achieved ROUGE-1 of 0.92, ROUGE-L of 0.91, and BLEU score improvements from 0.08 to 0.24. Fine-tuning on private datasets consistently showed better results than fine-tuning on public datasets. The rank-4 LoRA synthesis achieved optimal performance with a fidelity score of 0.290, an agreement score of 0.730, and a Frechet BiomedCLIP Distance (FBD) of 1450, reducing computational costs by almost 90 percent. This framework improves the clinical potential of AI in GI endoscopy. Compared to FLUX, MSDM, and Kandinsky 2.2, our model demonstrates superior FBD and strong semantic alignment. While other models lead in Fidelity or Agreement, our lower FBD indicates better image-text coherence. These results establish our approach as a robust solution for enhancing VQA and synthetic data generation in clinical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a dual-pipeline PEFT framework for GI endoscopy AI: (1) Florence-2 with parameter-efficient fine-tuning for clinical VQA on the Kvasir-VQA dataset, reporting ROUGE-1 of 0.92, ROUGE-L of 0.91, and BLEU improvement from 0.08 to 0.24; (2) rank-4 LoRA on Stable Diffusion 2.1 for privacy-preserving synthetic image generation, achieving fidelity 0.290, agreement 0.730, and FBD 1450 while claiming ~90% compute reduction. It asserts that the approach addresses data scarcity/privacy, outperforms FLUX/MSDM/Kandinsky 2.2 on FBD, and improves clinical potential, with a note that private-dataset fine-tuning outperforms public.
Significance. If the unshown link between synthetic images and improved VQA performance holds and generalizes beyond Kvasir-VQA, the work would offer a practical, compute-efficient route to dataset augmentation under privacy constraints. The explicit use of LoRA rank-4 and direct comparison of FBD against three other generators are concrete strengths; however, the absence of any ablation or downstream evaluation means the significance remains conditional on those missing experiments.
major comments (3)
- [Abstract / Results] Abstract and results: the central claim that synthetic images 'enhance training databases' and improve clinical VQA is unsupported because no experiment trains the Florence-2 VQA model on real + synthetic data and reports the resulting ROUGE/BLEU change on a held-out set. The two pipelines are evaluated separately.
- [Abstract] Abstract: the statement 'Fine-tuning on private datasets consistently showed better results than fine-tuning on public datasets' is presented without the corresponding table, split, or test-set details; the headline ROUGE/BLEU numbers are given only for Kvasir-VQA, leaving the clinical-utility claim without a private test-set evaluation.
- [Abstract] Abstract: the reported FBD of 1450 is called 'optimal' and superior for image-text coherence, yet no ablation or human-expert rating demonstrates that images at this FBD level actually raise downstream VQA accuracy when added to training; the metric comparison to FLUX/MSDM/Kandinsky therefore does not yet establish utility for the stated goal.
minor comments (2)
- [Abstract] Abstract: the phrase 'reducing computational costs by almost 90 percent' should be accompanied by the exact baseline (full fine-tuning FLOPs or wall-clock time) and the measured reduction for rank-4 LoRA.
- [Abstract] Abstract: 'Fidelity score of 0.290' and 'agreement score of 0.730' are reported without definitions or references to the exact formulas or human-evaluation protocol used.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We address each major comment point by point below. We agree that several claims in the abstract require clarification or additional support, and we will make revisions to ensure the claims are accurately supported by the presented experiments.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the central claim that synthetic images 'enhance training databases' and improve clinical VQA is unsupported because no experiment trains the Florence-2 VQA model on real + synthetic data and reports the resulting ROUGE/BLEU change on a held-out set. The two pipelines are evaluated separately.
Authors: We acknowledge that the manuscript evaluates the VQA and synthetic image generation pipelines independently, without an experiment that combines synthetic images with real data to measure improvement in VQA metrics. The claim in the abstract that synthetic images enhance training databases is aspirational based on the generation quality, but not empirically demonstrated in this work. We will revise the abstract and introduction to remove or qualify this claim, stating that the generation pipeline provides a means to augment datasets while preserving privacy, with the impact on VQA left for future investigation. revision: yes
-
Referee: [Abstract] Abstract: the statement 'Fine-tuning on private datasets consistently showed better results than fine-tuning on public datasets' is presented without the corresponding table, split, or test-set details; the headline ROUGE/BLEU numbers are given only for Kvasir-VQA, leaving the clinical-utility claim without a private test-set evaluation.
Authors: The statement regarding private datasets is based on additional experiments conducted on proprietary data. However, due to privacy constraints, detailed tables and splits were not included in the main manuscript. We will add a note or supplementary material with aggregated results or anonymized details to substantiate this claim, while ensuring compliance with data privacy. revision: partial
-
Referee: [Abstract] Abstract: the reported FBD of 1450 is called 'optimal' and superior for image-text coherence, yet no ablation or human-expert rating demonstrates that images at this FBD level actually raise downstream VQA accuracy when added to training; the metric comparison to FLUX/MSDM/Kandinsky therefore does not yet establish utility for the stated goal.
Authors: The FBD metric is used to compare image-text coherence among generators, and our model achieves a lower FBD indicating better alignment. However, we agree that this does not directly translate to improved VQA performance without further experiments. We will revise the wording in the abstract to describe the FBD result as superior in terms of the metric rather than claiming it as 'optimal' for clinical VQA utility. revision: yes
- The lack of a combined experiment showing synthetic data improving VQA performance cannot be addressed without conducting new experiments, which are beyond the scope of a revision response.
Circularity Check
No circularity: empirical metrics reported directly from evaluations
full rationale
The paper describes an applied dual-pipeline setup (Florence-2 VQA fine-tuned with PEFT; rank-4 LoRA on Stable Diffusion 2.1) evaluated on the public Kvasir-VQA dataset, with reported ROUGE/BLEU/FBD numbers presented as direct outputs of those runs. No equations, derivations, fitted-parameter predictions, or self-citation chains are invoked to justify a central claim; the results do not reduce to inputs by construction. Any potential self-citations would be non-load-bearing for the reported scores, which remain falsifiable external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank
Reference graph
Works this paper leans on
-
[1]
Mayo Clinic, ”Upper endoscopy - Mayo Clinic,” Mayoclinic.org,
-
[2]
Available: https://www.mayoclinic.org/tests- procedures/endoscopy/about/pac-20395197
[Online]. Available: https://www.mayoclinic.org/tests- procedures/endoscopy/about/pac-20395197. Accessed on: Jun. 2025
2025
-
[3]
[Online]
Segmed Team, ”Role of computer vision & synthetic data in transforming medical imaging,” Segmed.ai, 2025. [Online]. Avail- able: https://www.segmed.ai/resources/blog/the-role-of-computer-vision- and-synthetic-data-in-transforming-medical-imaging. Accessed on: Jun. 15, 2025
2025
-
[4]
O. O. Ejiga Peter, O. T. Adeniran, J.-O. A. MacGregor, F. Khalifa, and M. M. Rahman, ”Text-guided synthesis in medical multimedia retrieval: A framework for enhanced colonoscopy image classification and seg- mentation,”Algorithms, vol. 18, p. 155, 2025, doi: 10.3390/a18030155
-
[5]
[Online]
Kanerika, ”Parameter efficient fine tuning,” Kanerika, 2024. [Online]. Available: https://kanerika.com/blogs/parameter-efficient-fine-tuning/. Accessed on: Jun. 15, 2025
2024
-
[6]
B. P. Veasey and A. A. Amini, ”Low-rank adaptation of pre-trained large vision models for improved lung nodule malignancy classifica- tion,”IEEE Open J. Eng. Med. Biol., vol. 6, pp. 296–304, 2025, doi: 10.1109/ojemb.2025.3530841
- [7]
-
[8]
K. Zhuet al., ”Guiding medical vision-language models with explicit visual prompts: Framework design and comprehensive exploration of prompt variations,” inProc. NAACL, vol. 1, pp. 11726–11739, 2025, doi: 10.18653/v1/2025.naacl-long.587
-
[9]
[Online]
NVIDIA, ”What are vision-language models?,” NVIDIA, 2025. [Online]. Available: https://www.nvidia.com/en-us/glossary/vision- language-models/. Accessed on: Jun. 15, 2025
2025
-
[10]
A. Yilmaz, F. Yuceyalcin, R. Varol, E. Gokyayla, and O. Er- dem, ”A synthetic data generation framework for scalable and resource-efficient medical AI assistants,” 2025. [Online]. Available: https://doi.org/10.1101/2025.05.17.25327785. Accessed on: Jun. 15, 2025
- [11]
-
[12]
Available: https://doi.org/10.48550/arXiv.2502.20667
[Online]. Available: https://doi.org/10.48550/arXiv.2502.20667. Accessed on: Jun. 15, 2025
-
[13]
L. Janut ˙enas and D. ˇSeˇsok, ”Perspective transformation and viewpoint attention enhancement for generative adversarial networks in endoscopic image augmentation,”Applied Sciences, vol. 15, pp. 5655–5655, 2025, doi: 10.3390/app15105655
-
[14]
[Online]
Bayer, ”Synthetic data in medical imaging,” Pistoia Alliance, 2025. [Online]. Available: https://www.pistoiaalliance.org/new-idea/synthetic- data-in-medical-imaging/. Accessed on: Jun. 2025
2025
- [15]
-
[16]
W. Dong, S. Shen, Y . Han, T. Tan, J. Wu, and H. Xu, ”Generative models in medical visual question answering: A survey,”Applied Sciences, vol. 15, pp. 2983–2983, 2025, doi: 10.3390/app15062983
-
[17]
Z. Zeng, Z. Zhuo, X. Jia, and Erli, ”SurgVLM: A large vision-language model and systematic evaluation benchmark for surgical intelligence,” 2025
2025
- [18]
- [19]
-
[20]
Huang, L
X. Huang, L. Shen, and J. Liu, ”Towards a multimodal large language model with pixel-level insight for biomedicine,” 2025
2025
-
[21]
Gautam, P
S. Gautam, P. Halvorsen, and M. A. Riegler, ”Point, detect, count: Multi-task medical image understanding with instruction-tuned vision- language models,” 2025
2025
-
[23]
D. Yanet al., ”Vision-language large learning model, GPT4V , accu- rately classifies the Boston Bowel Preparation Scale score,”BMJ Open Gastroenterology, vol. 12, p. e001496, 2025, doi: 10.1136/bmjgast-2024- 001496
-
[24]
O. O. Ejiga Peter, O. G. Akingbola, C. R. Amalahu, O. Adeniran, F. Khakifa, and M. M. Rahman, ”Synthetic data-driven multi-architecture framework for automated polyp segmentation through integrated de- tection and mask generation,” inMedical Imaging 2025: Clinical and Biomedical Imaging, p. 78, Mar. 2025, doi: 10.1117/12.3049369
-
[25]
Elamin, S
S. Elamin, S. Johri, P. Rajpurkar, E. Geisler, and T. M. Berzin, ”From data to artificial intelligence: evaluating the readiness of gastrointestinal endoscopy datasets,”, 2025
2025
-
[26]
S. Gautam, A. Stor ˚as, C. Midoglu, S. A. Hicks, V . Thambawita, P. Halvorsen, and M. A. Riegler, ”Kvasir-VQA: A text-image pair GI tract dataset,” in *Proc. 1st Int. Workshop Vision-Language Models for Biomedical Applications (VLM4Bio ’24)*, Melbourne, VIC, Australia, 2024, pp. 10, ACM.Doi: 10.1145/3689096.3689458
-
[27]
O. O. Ejiga Peter, ”Advancing colonoscopy analysis through text-to-image synthesis using generative AI for intelligent data augmentation, image classification, and segmentation,”*ProQuest Dissertations Publishing*, 2024. [Online]. Available: https://www.proquest.com/openview/9a3add722e60af686957df5383de11f5/1?pq- origsite=gscholar&cbl=18750&diss=y [Access...
2024
-
[28]
M. Chaichuk, S. Gautam, S. A. Hicks, and E. Tutubalina, ”Prompt to Polyp: Medical Text-Conditioned Image Synthesis with Diffu- sion Models,” arXiv : arXiv:2505.05573, 2025. [Online]. Available: https://arxiv.org/abs/2505.05573
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.