Divide-and-Conquer Inference for Large-Scale Visual Recognition with Multimodal Large Language Models
Pith reviewed 2026-06-30 12:29 UTC · model grok-4.3
The pith
Divide-and-conquer inference overcomes performance collapse in MLLMs on large label spaces by recursive task decomposition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
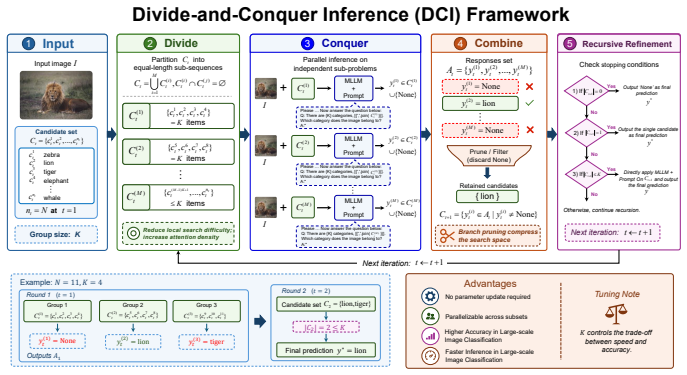
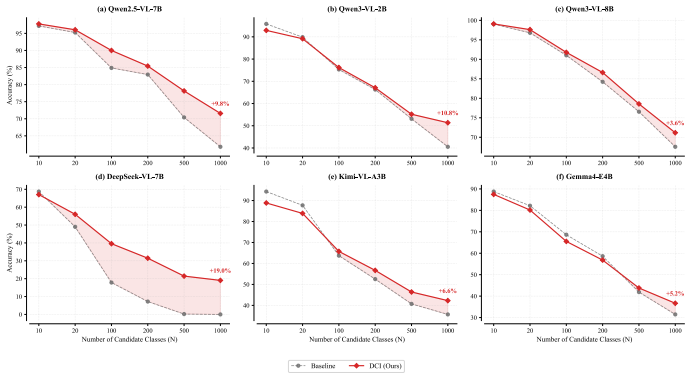
DCI recursively decomposes complex global classification tasks into multiple simpler, localized subproblems and employs a dynamic pruning mechanism to compress the search space, raising local signal-to-noise ratio and mitigating attention dilution without any training or fine-tuning.
What carries the argument
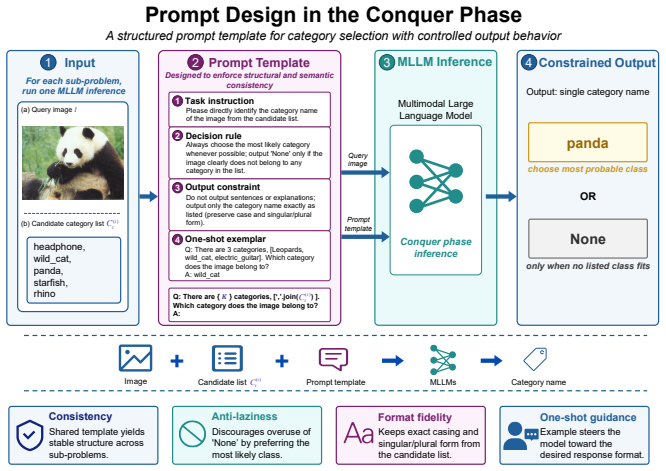
Divide-and-Conquer Inference (DCI): a test-time strategy that recursively decomposes the classification task and applies dynamic pruning to shrink the candidate set at each step.
If this is right
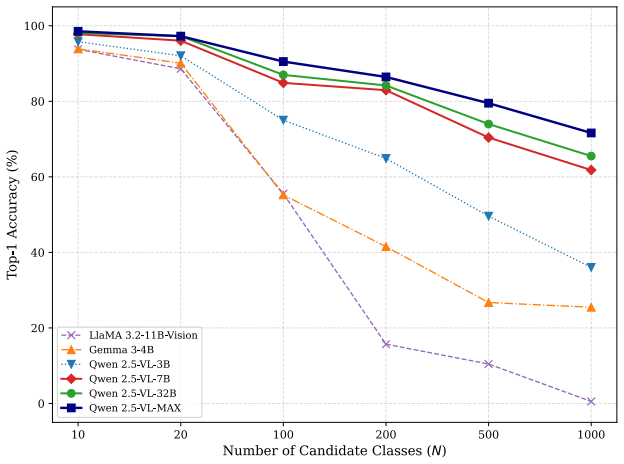
- Lightweight open-source MLLMs reach or surpass closed frontier models on ImageNet-21K classification.
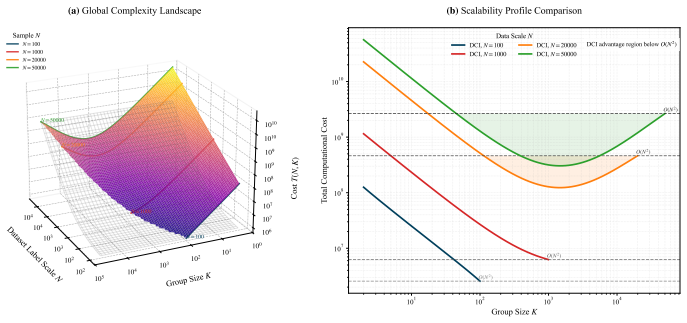
- Inference time for large-scale recognition scales better than the quadratic cost of full self-attention.
- The same plug-and-play procedure works across different MLLM backbones without modification.
Where Pith is reading between the lines
- The same recursive pruning pattern could be applied to other long-context tasks such as dense captioning or visual question answering over many objects.
- Dynamic pruning might be combined with existing retrieval methods to further reduce the initial candidate pool before decomposition begins.
- If the entropy-attention account holds, similar collapse should appear in pure language models on tasks with very large output vocabularies.
Load-bearing premise
The accuracy drop is caused by an entropy-attention conflict that recursive decomposition can fix without discarding the information needed to discriminate among classes.
What would settle it
Run DCI on a model and dataset where the label space exceeds 100k classes and measure whether accuracy still rises relative to direct inference; if it does not, the decomposition no longer preserves discriminative signal.
Figures
read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a wide range of vision language tasks. However, when applied to large scale image classification, their performance degrades significantly as the label space expands a phenomenon we define as Performance Collapse in Long Sequence Recognition. Through an information theoretic analysis, we reveal that this collapse stems from a fundamental conflict between the escalating information entropy and the prominent attention dilution and decay within attention mechanisms, which impairs the model's ability to maintain a sufficient signal-to-noise ratio when processing extremely long prompts. To mitigate this, we propose Divide-and-Conquer Inference (DCI), a novel test-time scaling strategy for visual recognition with MLLMs. DCI recursively decomposes complex global classification tasks into multiple simpler, localized subproblems and employs a dynamic pruning mechanism to compress the search space. This method effectively improves the local signal to noise ratio and model accuracy by mitigating the inherent weight dilution issues in long-sequence inference. Moreover, while traditional self-attention incurs a prohibitive quadratic computational complexity, DCI achieves more favorable scaling behavior and substantially accelerates inference in large scale classification scenarios. Extensive experiments on benchmarks such as ImageNet-1K and ImageNet-21K demonstrate that DCI consistently improves classification accuracy. This enables lightweight open-source models to rival or even surpass frontier closed-source giants without any additional training or fine-tuning. As a model-agnostic, plug-and-play paradigm, DCI offers an efficient approach for scaling the inferential precision of MLLMs in large-scale scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs suffer from 'Performance Collapse in Long Sequence Recognition' on large-scale image classification due to a conflict between escalating information entropy and attention dilution/decay that reduces SNR in long prompts. It proposes Divide-and-Conquer Inference (DCI) as a test-time, model-agnostic strategy that recursively decomposes global classification into localized subproblems and applies dynamic pruning to compress the label space, thereby raising local SNR, improving accuracy, and achieving better-than-quadratic scaling. Experiments on ImageNet-1K and ImageNet-21K are asserted to show consistent gains that allow lightweight open-source MLLMs to rival or surpass closed-source frontier models without any training or fine-tuning.
Significance. If the information-theoretic motivation, pruning invariance, and empirical gains are rigorously established, the work would offer a practical plug-and-play inference-time method for scaling MLLM classification to very large vocabularies. The emphasis on no retraining and improved computational scaling could be useful for deploying open models in real-world settings.
major comments (3)
- [Abstract] Abstract: The information-theoretic analysis is stated to reveal the entropy-attention conflict as the cause of performance collapse, yet no equations, derivations, or quantitative measures (e.g., entropy growth, attention decay rates, or SNR thresholds) are supplied, leaving the explanatory foundation for DCI unverified and load-bearing.
- [Abstract] Abstract: Dynamic pruning is claimed to compress the search space while preserving critical discriminative information at every recursive stage, but no analysis of pruning recall, error-propagation bounds, or the decision criterion that guarantees the ground-truth label is retained more reliably than the baseline misclassification rate is provided; this invariance is load-bearing for the accuracy-improvement claim.
- [Abstract] Abstract: 'Extensive experiments on ImageNet-1K and ImageNet-21K demonstrate that DCI consistently improves classification accuracy' is asserted, yet the abstract contains no quantitative results, tables, baseline comparisons, ablations, or error analysis, preventing evaluation of effect sizes or controls.
minor comments (1)
- [Abstract] Abstract: The phrase 'a phenomenon we define as Performance Collapse in Long Sequence Recognition' introduces a new term without a formal definition or citation to related long-context degradation literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the abstract accordingly to better reflect the analyses and results in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: The information-theoretic analysis is stated to reveal the entropy-attention conflict as the cause of performance collapse, yet no equations, derivations, or quantitative measures (e.g., entropy growth, attention decay rates, or SNR thresholds) are supplied, leaving the explanatory foundation for DCI unverified and load-bearing.
Authors: The complete information-theoretic analysis, including equations for entropy growth, attention decay rates, and SNR thresholds, appears in Section 3. The abstract summarizes this foundation at a high level. We will revise the abstract to include a concise reference to these quantitative measures and their role in motivating DCI. revision: yes
-
Referee: [Abstract] Abstract: Dynamic pruning is claimed to compress the search space while preserving critical discriminative information at every recursive stage, but no analysis of pruning recall, error-propagation bounds, or the decision criterion that guarantees the ground-truth label is retained more reliably than the baseline misclassification rate is provided; this invariance is load-bearing for the accuracy-improvement claim.
Authors: Section 4 derives the pruning recall, error-propagation bounds, and decision criteria that ensure reliable retention of the ground-truth label. We will update the abstract to briefly note these invariance properties established in the analysis. revision: yes
-
Referee: [Abstract] Abstract: 'Extensive experiments on ImageNet-1K and ImageNet-21K demonstrate that DCI consistently improves classification accuracy' is asserted, yet the abstract contains no quantitative results, tables, baseline comparisons, ablations, or error analysis, preventing evaluation of effect sizes or controls.
Authors: We agree the abstract would be strengthened by quantitative results. The revised abstract will report key accuracy gains on ImageNet-1K and ImageNet-21K, along with baseline comparisons drawn from the experimental section. revision: yes
Circularity Check
No circularity: test-time procedure with independent experimental validation
full rationale
The paper's information-theoretic analysis of performance collapse is presented as motivation rather than a derivation that forces the DCI method. DCI is introduced as a novel test-time scaling strategy relying on recursive decomposition and dynamic pruning, with claimed gains supported by experiments on ImageNet benchmarks rather than any fitted parameters, self-definitional equations, or load-bearing self-citations that reduce the result to its inputs. No steps match the enumerated circularity patterns; the central claim remains externally falsifiable via accuracy measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, Y
D. Zhang, Y . Yu, J. Dong, C. Li, D. Su, C. Chu, D. Yu, Mm-llms: Recent advances in multimodal large language models, Findings of the Association for Computa- tional Linguistics: ACL 2024 (2024) 12401–12430
2024
-
[2]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, D. Amodei, Scaling laws for neural language models, arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., Gpt-4 technical report, arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al., Qwen3 technical report, arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
H. Lu, W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, et al., Deepseek-vl: towards real-world vision-language understanding, arXiv preprint arXiv:2403.05525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
N. Fei, Z. Lu, Y . Gao, G. Yang, Y . Huo, J. Wen, H. Lu, R. Song, X. Gao, T. Xiang, et al., Towards artificial general intelligence via a multimodal foundation model, Nature Communications 13 (1) (2022) 3094
2022
-
[7]
A. Wu, Y . Yang, X. Luo, Y . Yang, C. Wang, L. Hu, X. Dai, D. Chen, C. Luo, L. Qiu, et al., Llm2clip: Powerful language model unlock richer visual repre- sentation, in: NeurIPS 2024 Workshop: Self-Supervised Learning-Theory and Practice, 2024
2024
-
[8]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever, Learning transferable visual models from natural language supervision, in: M. Meila, T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, V ol. 139 of Proceedings of Machine Learning Rese...
2021
-
[9]
L. Fan, D. Krishnan, P. Isola, D. Katabi, Y . Tian, Improving clip training with language rewrites, Advances in Neural Information Processing Systems 36 (2023) 35544–35575
2023
-
[10]
Z. Ye, F. Jiang, Q. Wang, K. Huang, J. Huang, Idea: Image description enhanced clip-adapter for image classification, Pattern Recognition (2025) 112224
2025
-
[11]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, et al., Llava-onevision: Easy visual task transfer, arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al., Qwen2. 5 technical report, arXiv e-prints (2024) arXiv–2412
2024
-
[13]
Zhang, A
Y . Zhang, A. Unell, X. Wang, D. Ghosh, Y . Su, L. Schmidt, S. Yeung-Levy, Why are visually-grounded language models bad at image classification?, Advances in Neural Information Processing Systems 37 (2024) 51727–51753
2024
-
[14]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Let- man, A. Mathur, A. Schelten, A. Vaughan, et al., The llama 3 herd of models, arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al., Gemma: Open models based on gemini research and technology, arXiv preprint arXiv:2403.08295 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: A large-scale hierarchical image database, in: 2009 IEEE conference on computer vision and pattern recognition, IEEE, 2009, pp. 248–255
2009
-
[17]
Krizhevsky, G
A. Krizhevsky, G. Hinton, et al., Learning multiple layers of features from tiny images (2009)
2009
-
[18]
Welinder, S
P. Welinder, S. Branson, T. Mita, C. Wah, F. Schroff, S. Belongie, P. Perona, Caltech-ucsd birds 200 (2010). 33
2010
-
[19]
Bossard, M
L. Bossard, M. Guillaumin, L. Van Gool, Food-101–mining discriminative com- ponents with random forests, in: European conference on computer vision, Springer, 2014, pp. 446–461
2014
-
[20]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al., Deepseek-r1 incentivizes reasoning in llms through reinforcement learning, Nature 645 (8081) (2025) 633–638
2025
-
[21]
Muennighoff, Z
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettle- moyer, P. Liang, E. Candès, T. B. Hashimoto, s1: Simple test-time scaling, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 20286–20332
2025
-
[22]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdh- ery, D. Zhou, Self-consistency improves chain of thought reasoning in language models, in: The Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al., Chain-of-thought prompting elicits reasoning in large language models, Advances in neural information processing systems 35 (2022) 24824–24837
2022
-
[24]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, K. Narasimhan, Tree of thoughts: Deliberate problem solving with large language models, Advances in neural information processing systems 36 (2023) 11809–11822
2023
-
[25]
Besta, N
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al., Graph of thoughts: Solving elaborate problems with large language models, in: Proceedings of the AAAI conference on artificial intelligence, V ol. 38, 2024, pp. 17682–17690
2024
-
[26]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al., Openai o1 system card, arXiv preprint arXiv:2412.16720 (2024). 34
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Z. Hu, W. Liu, X. Qu, X. Yue, C. Chen, Z. Wang, Y . Cheng, Divide and con- quer: grounding llms as efficient decision-making agents via offline hierarchical reinforcement learning, in: Proceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[28]
W. Cui, Z. Li, D. Lopez, K. Das, B. A. Malin, S. Kumar, J. Zhang, Divide- conquer-reasoning for consistency evaluation and automatic improvement of large language models, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 334–361
2024
-
[29]
J. W. Cooley, J. W. Tukey, An algorithm for the machine calculation of complex fourier series, Mathematics of computation 19 (90) (1965) 297–301
1965
-
[30]
C. E. Shannon, A mathematical theory of communication, The Bell System Tech- nical Journal 27 (3) (1948) 379–423
1948
-
[31]
R. M. Fano, D. Hawkins, Transmission of information: A statistical theory of communications, American Journal of Physics 29 (11) (1961) 793–794
1961
-
[32]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al., Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Anthropic, Introducing claude opus 4.5,https://www.anthropic.com/news/ claude-opus-4-5(2025)
2025
-
[34]
K. Team, A. Du, B. Yin, B. Xing, B. Qu, B. Wang, C. Chen, C. Zhang, C. Du, C. Wei, et al., Kimi-vl technical report, arXiv preprint arXiv:2504.07491 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Liang, X
Y . Liang, X. Lyu, W. Chen, M. Ding, J. Zhang, X. He, S. Wu, X. Xing, S. Yang, X. Wang, et al., Wsi-llava: A multimodal large language model for whole slide image, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22718–22727. 35
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.