Trajectory-Consistent Calibration for Cache-Accelerated Diffusion Models
Pith reviewed 2026-06-30 12:09 UTC · model grok-4.3
The pith
Cache acceleration for diffusion transformers matches full-computation quality when calibration priors are computed iteratively to match shifted trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
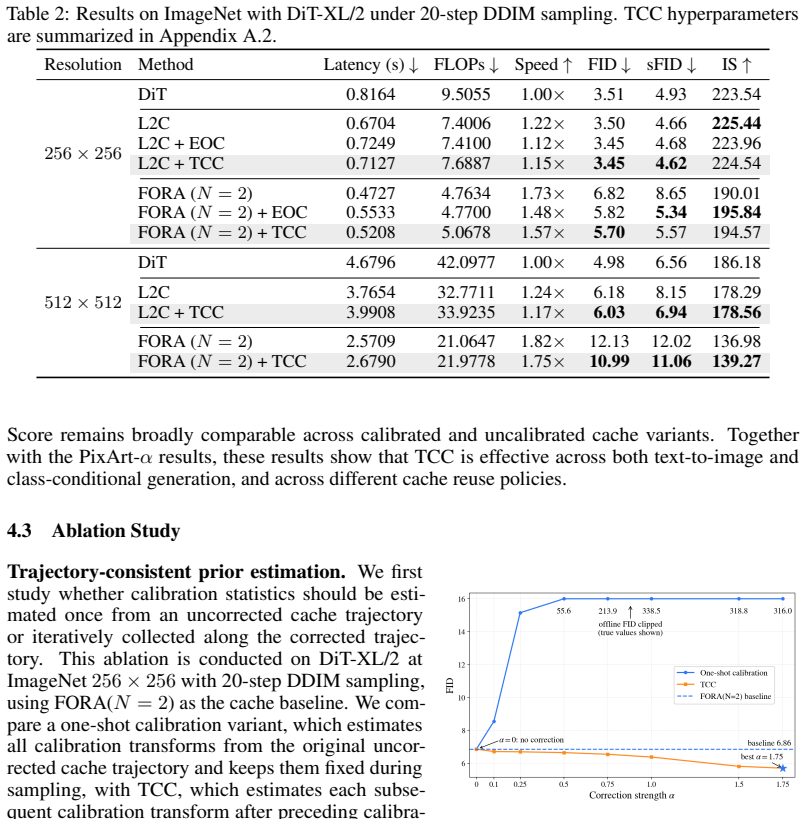
Diffusion Transformers incur high inference cost from repeated denoiser calls. Cache acceleration reuses intermediate representations across steps but introduces deviations. Effective calibration must address both the direct mismatch from reuse and the trajectory shift induced by earlier corrections. Trajectory-Consistent Calibration uses an offline iterative procedure to compute each calibration prior after accounting for the shifts caused by preceding calibrations. On a PixArt-alpha setting with FORA caching, this reduces FID from 29.83 to 27.35, slightly surpassing the full-computation baseline while preserving the original reuse policy.
What carries the argument
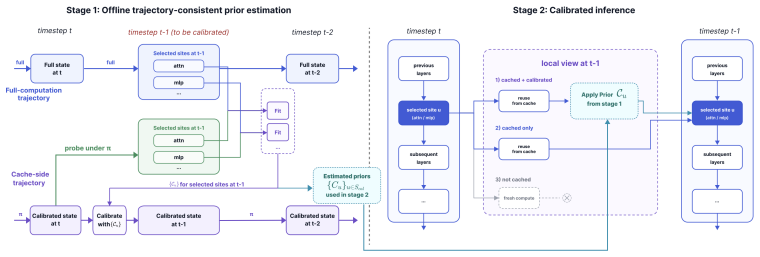
Trajectory-Consistent Calibration (TCC): an offline iterative procedure that estimates each calibration prior after simulating the trajectory shifts induced by all preceding calibrations.
If this is right
- TCC applies to multiple cache-based acceleration methods without changing their reuse policies.
- The method yields consistent FID gains on both PixArt-alpha and DiT-XL/2.
- Calibration occurs entirely offline, adding no runtime overhead to the accelerated sampler.
- In representative settings the calibrated cache model can achieve lower FID than the uncached full-computation baseline.
Where Pith is reading between the lines
- The same iterative accounting for cumulative shifts could be tested on other diffusion accelerations such as step-skipping or mixed-precision computation.
- Approximating the offline iteration with a cheap online update might allow adaptive calibration during a single generation run.
- The result suggests that trajectory-level consistency, rather than per-step fidelity alone, is the relevant objective when designing any form of approximate sampling.
Load-bearing premise
The offline iterative procedure produces calibration priors that accurately reflect the trajectory shifts that would occur during actual online sampling without introducing new deviations.
What would settle it
Running the TCC-calibrated cache model on a held-out prompt set or with a substantially different number of denoising steps and checking whether the reported FID reduction and outperformance of the full baseline still hold.
Figures




read the original abstract
Diffusion Transformers require repeated denoiser evaluations during iterative sampling, making inference computationally expensive. Cache-based acceleration reduces this cost by reusing intermediate representations across denoising steps, but can introduce representation deviations and degrade generation quality. In this paper, we analyze these deviations and show that effective calibration should consider both the direct mismatch caused by reuse and the subsequent trajectory shift induced by earlier corrections. To address this challenge, we propose Trajectory-Consistent Calibration (TCC), a training-free method that calibrates cached representations toward their full-computation counterparts. Specifically, rather than estimating all calibration priors from a single uncorrected cache trajectory, TCC uses an offline iterative procedure so that each prior accounts for the trajectory shift induced by preceding calibrations. Experiments on PixArt-alpha and DiT-XL/2 show that TCC consistently improves FID across representative cache-based acceleration methods while preserving their underlying reuse policies. Notably, in a representative PixArt-alpha cache-acceleration setting based on FORA, TCC reduces FID from 29.83 to 27.35, slightly surpassing the full-computation baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trajectory-Consistent Calibration (TCC), a training-free method to calibrate cached representations in diffusion transformers. It analyzes representation deviations from cache reuse and introduces an offline iterative procedure (Section 3.2, Algorithm 1) so that each calibration prior accounts for trajectory shifts from preceding corrections. Experiments on PixArt-alpha and DiT-XL/2 report consistent FID improvements across cache methods, including a reduction from 29.83 to 27.35 on a FORA-based PixArt-alpha setting that slightly exceeds the full-computation baseline.
Significance. If the offline procedure produces priors that match online trajectory shifts, TCC would provide a practical way to improve quality of cache-accelerated diffusion sampling without retraining or altering reuse policies. The reported FID gains on two models are concrete, but the absence of direct verification of the offline-online match and of error bars limits the strength of the evidence for the central claim.
major comments (2)
- [Section 3.2, Algorithm 1] Section 3.2 and Algorithm 1: the offline iterative procedure is presented as producing priors that reflect trajectory shifts induced by preceding calibrations, yet the manuscript contains no direct comparison (e.g., per-step representation distances, trajectory divergence metrics, or ablation of the iterative loop) between the offline-computed priors and the actual online state evolution under the same cache policy. This verification is load-bearing for the claim that TCC accounts for induced shifts rather than introducing new deviations.
- [Experiments section] Experiments (FID tables): the reported FID values (e.g., 29.83 → 27.35) lack error bars, details on the number of samples or data exclusion criteria, and any statistical test; without these it is impossible to determine whether the improvement over the full-computation baseline is robust or within noise.
minor comments (1)
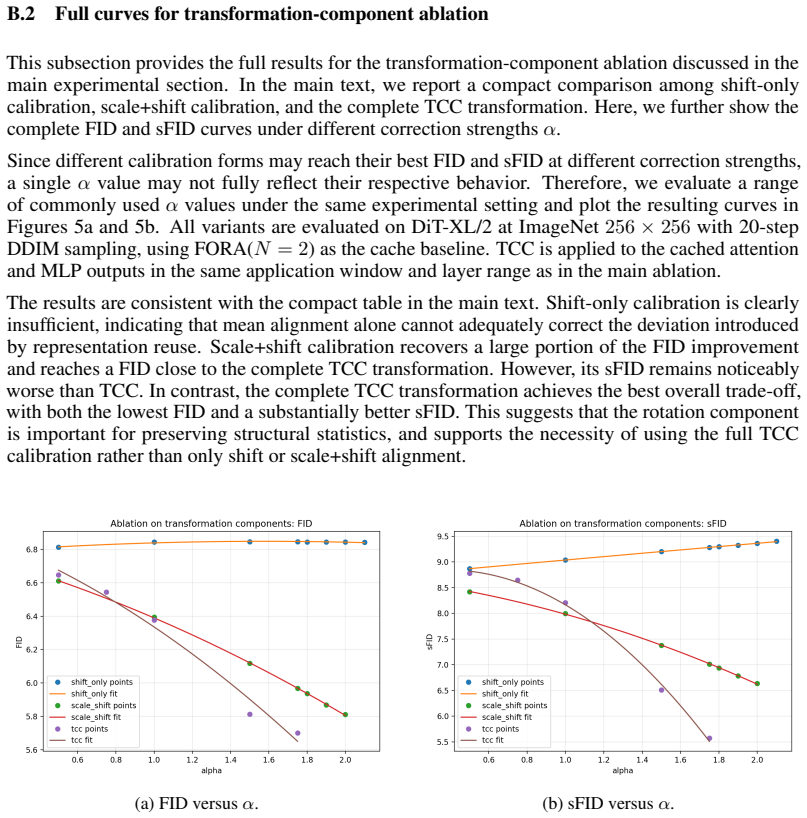
- [Section 3] Notation for the calibration prior and the trajectory-shift term is introduced without an explicit equation reference in the main text; adding a numbered equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below, agreeing where the manuscript is missing supporting analysis and outlining planned revisions.
read point-by-point responses
-
Referee: [Section 3.2, Algorithm 1] Section 3.2 and Algorithm 1: the offline iterative procedure is presented as producing priors that reflect trajectory shifts induced by preceding calibrations, yet the manuscript contains no direct comparison (e.g., per-step representation distances, trajectory divergence metrics, or ablation of the iterative loop) between the offline-computed priors and the actual online state evolution under the same cache policy. This verification is load-bearing for the claim that TCC accounts for induced shifts rather than introducing new deviations.
Authors: We agree that the manuscript lacks direct verification of the offline-online match and that this is a substantive gap for the central claim. The current evidence consists of the procedure design in Algorithm 1 together with downstream FID gains; these do not substitute for explicit trajectory-level comparisons. In revision we will add per-step representation distance plots and an ablation that disables the iterative loop, reporting both representation-level and generation-level metrics under the same cache policies. revision: yes
-
Referee: [Experiments section] Experiments (FID tables): the reported FID values (e.g., 29.83 → 27.35) lack error bars, details on the number of samples or data exclusion criteria, and any statistical test; without these it is impossible to determine whether the improvement over the full-computation baseline is robust or within noise.
Authors: We concur that the reported FID numbers require statistical context to assess robustness. The revised experiments section will report mean and standard deviation over at least three independent runs, state that FID is computed on the standard 10 000-image protocol with no exclusions, and include a paired statistical test (e.g., Wilcoxon) comparing TCC against the uncorrected cache baseline and the full-computation reference. revision: yes
Circularity Check
No circularity; derivation is self-contained training-free procedure
full rationale
The paper describes TCC as a training-free offline iterative procedure that computes calibration priors sequentially to account for trajectory shifts, with no equations, fitted parameters, or self-citations shown that reduce the claimed FID improvement (29.83 to 27.35) to the inputs by construction. The offline loop is presented as an independent computational approximation of online dynamics rather than a definitional equivalence or renamed empirical pattern. No load-bearing self-citation chains or ansatzes are invoked. This is the most common honest finding for a method whose central claim rests on an explicit algorithmic procedure rather than a mathematical reduction to its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2506.15682. Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,
-
[2]
Huanpeng Chu, Wei Wu, Guanyu Fen, and Yutao Zhang
URL https://arxiv.org/abs/2505.05829. Huanpeng Chu, Wei Wu, Guanyu Fen, and Yutao Zhang. Omnicache: A trajectory-oriented global perspective on training-free cache reuse for diffusion transformer models,
-
[3]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei
URL https: //arxiv.org/abs/2508.16212. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hier- archical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255,
-
[4]
Imagenet: A large- scale hierarchical image database
doi: 10.1109/CVPR.2009.5206848. Yasaman Haghighi and Alexandre Alahi. Sencache: Accelerating diffusion model inference via sensitivity-aware caching.arXiv preprint arXiv:2602.24208,
-
[5]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
URL https://arxiv.org/abs/1706.08500. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S
URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf. Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S. Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffusion transformers. arXiv preprint arXiv:2411.02397,
-
[7]
Microsoft COCO: Common Objects in Context
URLhttps://arxiv.org/abs/1405.0312. Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. arXiv preprint arXiv:2411.19108,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ziming Liu, Yifan Yang, Chengruidong Zhang, Yiqi Zhang, Lili Qiu, Yang You, and Yuqing Yang
URL https: //openreview.net/forum?id=PlKWVd2yBkY. Ziming Liu, Yifan Yang, Chengruidong Zhang, Yiqi Zhang, Lili Qiu, Yang You, and Yuqing Yang. Region-adaptive sampling for diffusion transformers, 2025b. URL https://arxiv.org/abs/ 2502.10389. Jinming Lou, Wenyang Luo, Yufan Liu, Bing Li, Xinmiao Ding, Weiming Hu, Yuming Li, and Chenguang Ma. Token caching ...
-
[9]
11 Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu
URL https: //arxiv.org/abs/2409.18523. 11 Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.arXiv preprint arXiv:2206.00927,
-
[10]
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang
doi: 10.1007/s11633-025-1562-4. Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching, 2024a. Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15762–157...
-
[11]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers ’25)
doi: 10.1109/ ICCV51070.2023.00387. Junxiang Qiu, Lin Liu, Shuo Wang, Jinda Lu, Kezhou Chen, and Yanbin Hao. Accelerating diffu- sion transformer via gradient-optimized cache. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17608–17617, 2025a. Junxiang Qiu, Shuo Wang, Jinda Lu, Lin Liu, Houcheng Jiang, Xingyu Zhu, a...
-
[12]
Learning Transferable Visual Models From Natural Language Supervision
URL https: //arxiv.org/abs/2103.00020. Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your steps: Optimizing sampling schedules in diffusion models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps://arxiv.org/abs/1606.03498. Peter H. Schönemann. A generalized solution of the orthogonal procrustes problem.Psychometrika, 31(1):1–10,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang
doi: 10.1007/BF02289451. Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast-forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425,
-
[15]
URL https: //openreview.net/forum?id=pt4iKnAm0M. Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInter- national Conference on Learning Representations, 2021a. URL https://openreview.net/ forum?id=St1giarCHLP. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-base...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Maskplan: Masked generative layout planning from partial input
doi: 10.1109/CVPR52733.2024.00594. Shuchen Xue, Zhaoqiang Liu, Fei Chen, Shifeng Zhang, Tianyang Hu, Enze Xie, and Zhenguo Li. Accelerating diffusion sampling with optimized time steps. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8292–8301,
-
[17]
Maskplan: Masked generative layout planning from partial input
doi: 10.1109/ CVPR52733.2024.00792. Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor- corrector framework for fast sampling of diffusion models.NeurIPS,
-
[18]
Maskplan: Masked generative layout planning from partial input
doi: 10.1109/CVPR52733.2024.00743. Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Linfeng Zhang. Accelerating diffusion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317,
-
[19]
1.1929 11.9085 1.71×2.65 4.71238.040.80 0.59 FORA(N=
1929
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.