Factorize to Generalize: Retrieval-Guided Invariant-Dynamic Decomposition for Time Series Forecasting
Pith reviewed 2026-06-30 12:12 UTC · model grok-4.3
The pith
Retrieval sequences guide decomposition of time series into invariant and dynamic components for better zero-shot robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
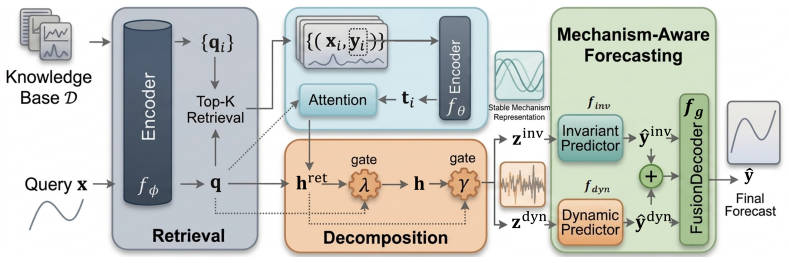
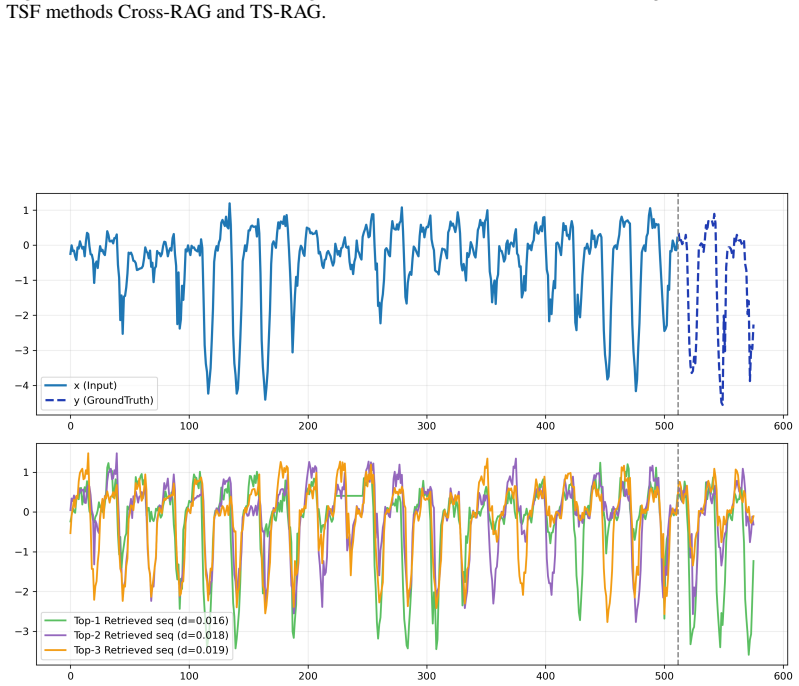
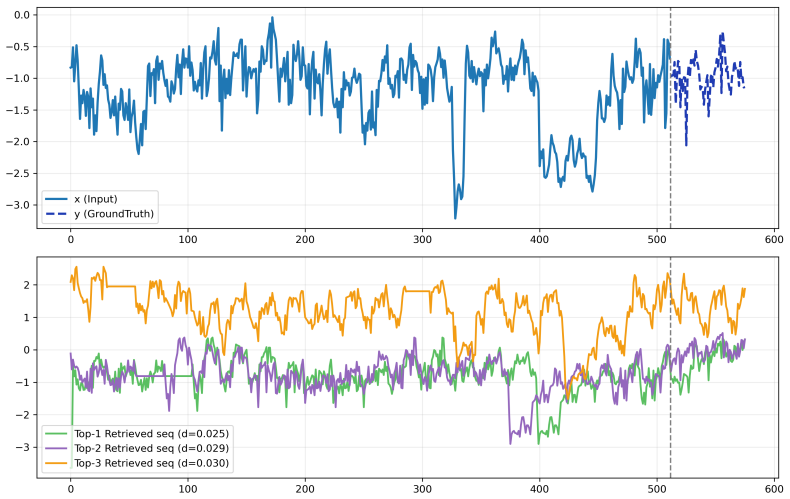
The central claim is that rather than using retrieval as auxiliary predictive context, retrieved sequences serve as implicit environment samples to construct a retrieval-aware representation via attention-based aggregation. A retrieval-guided routing mechanism then decomposes this into an invariant component capturing stable shared structure and a dynamic component modeling context-dependent variations. These are forecasted separately and fused, supported by objectives that encourage invariant learning and disentanglement, plus theoretical insight that retrieval aggregation reduces variance and approximates invariant representation learning without explicit supervision. This yields improved
What carries the argument
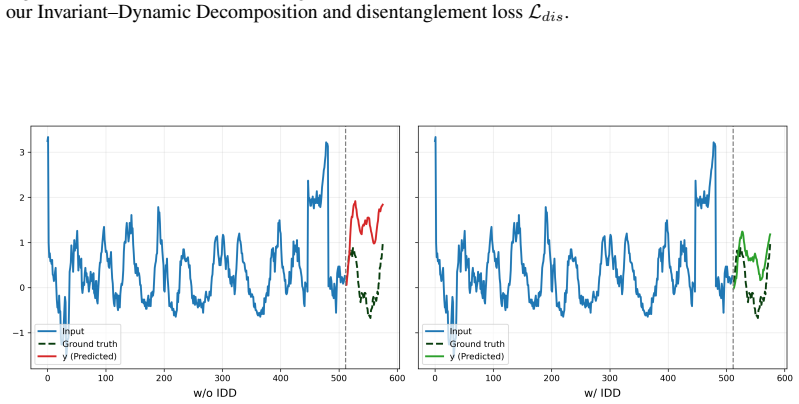
The retrieval-guided routing mechanism that decomposes a retrieval-aware representation into an invariant component for stable shared structure and a dynamic component for context-dependent variations.
If this is right
- The model improves robustness under distribution shifts compared to prior methods.
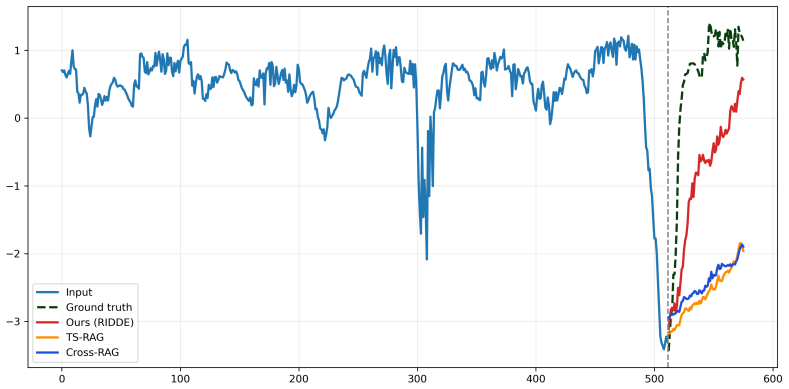
- It outperforms existing time series foundation models and retrieval baselines in zero-shot forecasting.
- Separate forecasting of invariant and dynamic components preserves transferable patterns while adapting to evolving dynamics.
- Training objectives promote invariant learning and disentanglement of the two components.
Where Pith is reading between the lines
- The same retrieval-guided decomposition could apply to other sequential prediction tasks facing distribution shifts, such as in sensor data or financial series.
- Retrieval may serve as a practical substitute for explicit environment labels in invariant representation methods across domains.
- Performance could vary if retrieval sources differ substantially from the target distribution, suggesting a need to test retrieval quality thresholds.
Load-bearing premise
Retrieved sequences can be treated as implicit samples from related environments that enable decomposition into invariant and dynamic components without explicit environment labels or supervision.
What would settle it
An experiment on distribution-shifted time series data where the full decomposition method shows no gain or a loss in zero-shot accuracy compared to plain retrieval would falsify the central claim.
Figures
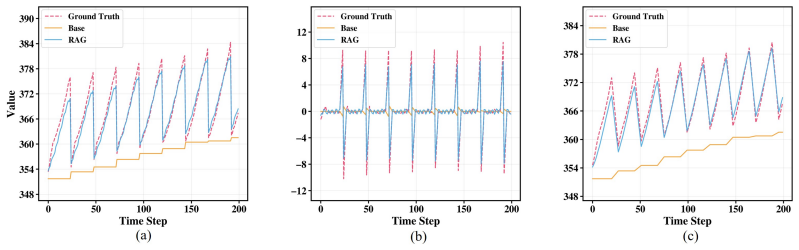
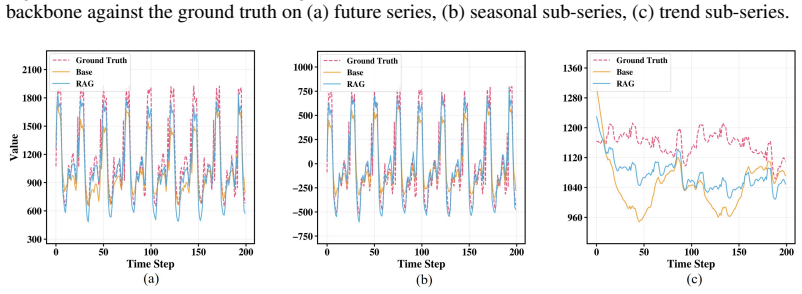
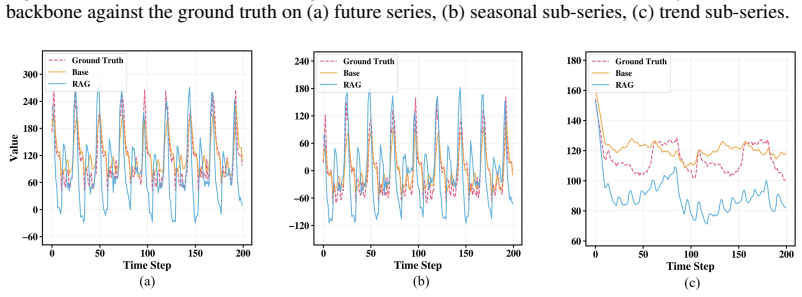
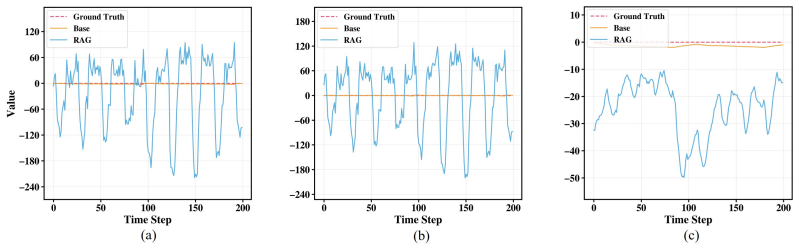
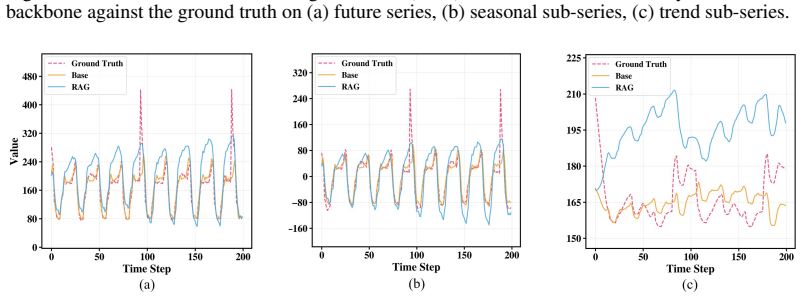
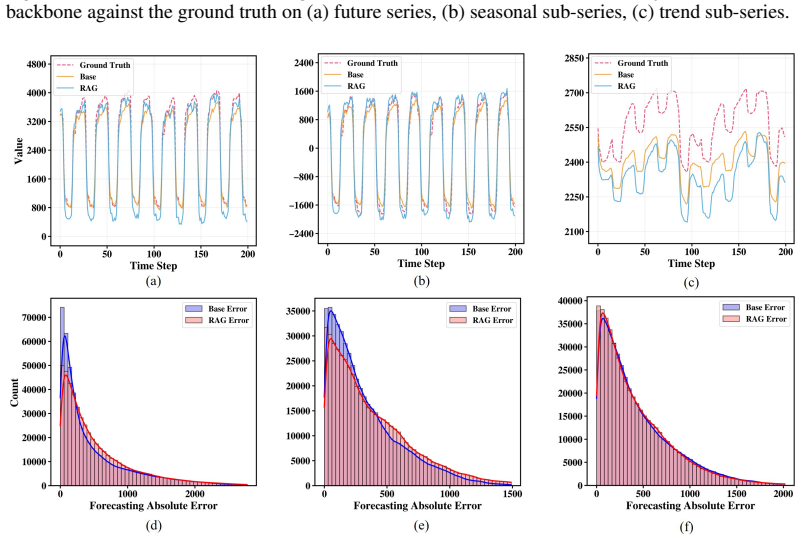
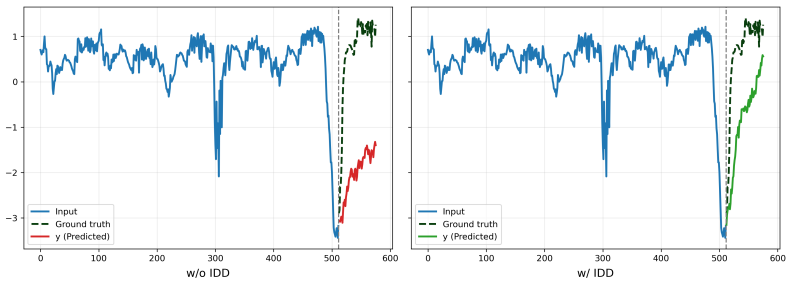
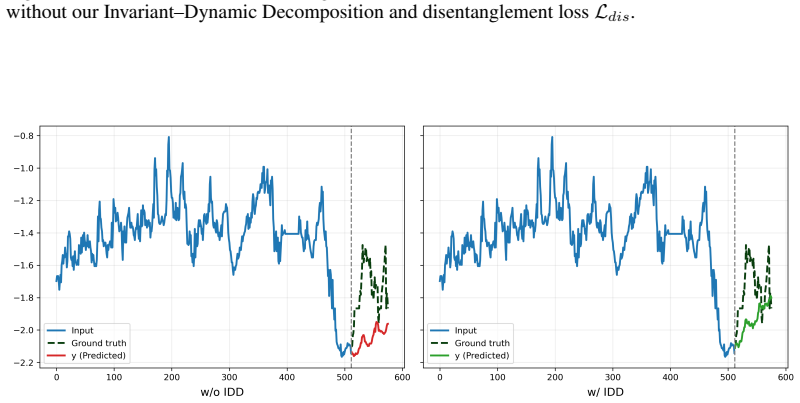
read the original abstract
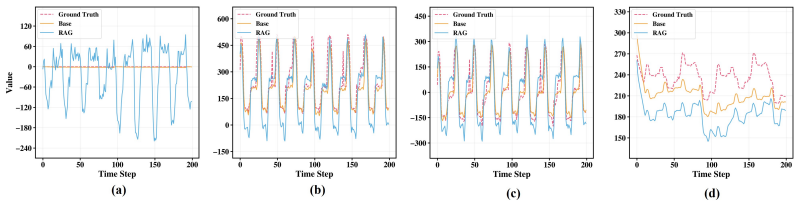
Time series foundation models (TSFMs) have recently achieved strong zero-shot forecasting performance through large-scale pretraining and retrieval-augmented prediction. However, our empirical analysis reveals a non-trivial limitation of retrieval-based forecasting: retrieval tends to induce more oscillatory predictions, improving performance on highly fluctuating series while degrading accuracy on smoother, trend-dominated ones. This suggests that retrieved information may be fused into prediction without explicitly distinguishing stable temporal structure from instance-specific variations, which can reduce robustness under distribution shifts. We propose a Retrieval-guided Invariant-Dynamic DEcomposition framework for time series forecasting. Rather than using retrieval as auxiliary predictive context, we leverage retrieved sequences as implicit samples from related environments to guide representation decomposition. Specifically, we first construct a retrieval-aware representation via attention-based aggregation, and then introduce a retrieval-guided routing mechanism to decompose it into an invariant component capturing stable shared structure and a dynamic component modeling context-dependent variations. These two components are forecast separately and fused for final prediction, enabling the model to preserve transferable patterns while remaining adaptive to evolving dynamics. We further design training objectives that encourage invariant learning and disentanglement, and provide theoretical insight showing that retrieval aggregation reduces variance and approximates invariant representation learning without explicit environment supervision. Extensive experiments demonstrate that our method consistently improves robustness under distribution shifts and outperforms existing TSFMs and retrieval-based baselines in zero-shot forecasting settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the RIDDE framework for time series forecasting. It first empirically observes that retrieval-augmented TSFMs produce oscillatory predictions that help fluctuating series but degrade smoother ones. The method treats retrieved sequences as implicit environment samples, constructs a retrieval-aware representation via attention aggregation, and applies a retrieval-guided routing mechanism to decompose the representation into an invariant component (stable shared structure) and a dynamic component (context-dependent variations). These are forecasted separately, fused for the final prediction, and trained with objectives that encourage invariant learning and disentanglement. A theoretical insight is offered that retrieval aggregation reduces variance and approximates invariant representation learning without explicit environment labels. Extensive experiments are claimed to show improved robustness under distribution shifts and superior zero-shot performance over TSFMs and retrieval baselines.
Significance. If the routing mechanism produces a genuine, validated decomposition into invariant and dynamic factors (rather than an arbitrary split) and the theoretical approximation is non-circular, the work would provide a concrete mechanism for improving robustness in retrieval-augmented forecasting without requiring environment labels. The zero-shot gains would be noteworthy if shown to arise specifically from the disentanglement rather than richer context alone.
major comments (3)
- [Abstract] Abstract (theoretical insight paragraph): the claim that 'retrieval aggregation reduces variance and approximates invariant representation learning without explicit environment supervision' is stated without any derivation, equations, variance-reduction proof, or comparison to standard invariant-risk minimization; this is load-bearing for the central claim that the method enables label-free invariant learning.
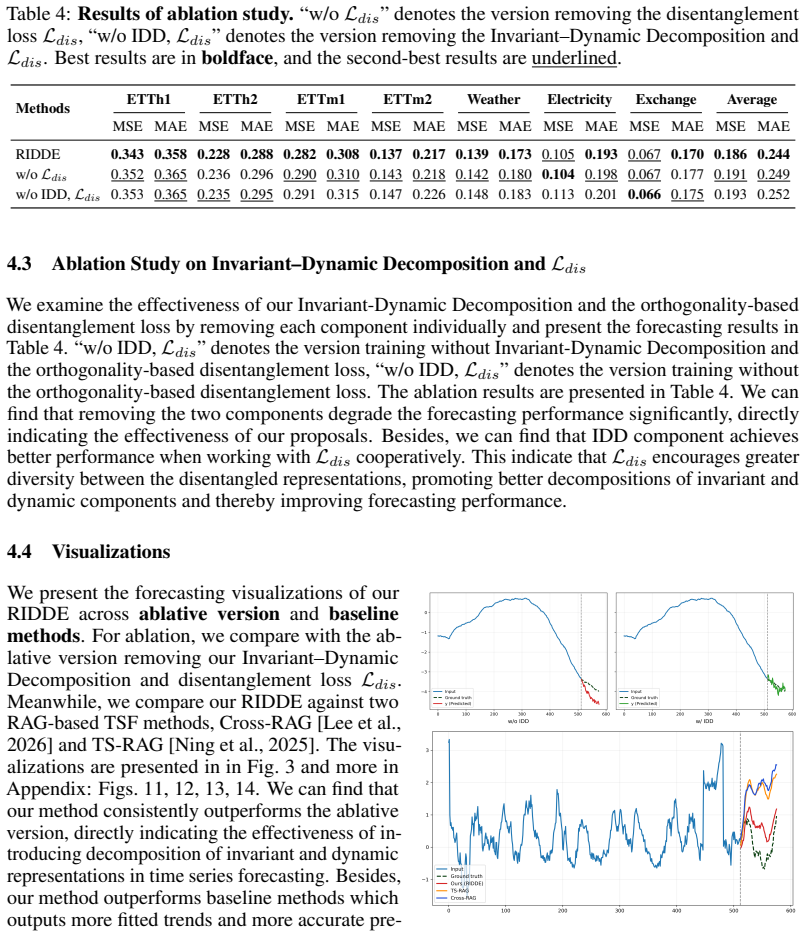
- [Abstract] Abstract and experiments description: no invariance metric (e.g., prediction stability across shifts), mutual-information measure between components, or ablation removing the routing mechanism is mentioned; without such evidence the robustness gains cannot be attributed to the claimed decomposition rather than simply richer retrieval context.
- [Abstract] Abstract (weakest-assumption paragraph): the assumption that retrieved sequences can be treated as implicit samples from related environments enabling unsupervised decomposition is presented without any supporting diagnostic (e.g., environment-similarity statistics or routing visualization); this directly underpins the entire retrieval-guided routing design.
minor comments (2)
- [Abstract] The abstract introduces the acronym RIDDE only implicitly; spelling out the full name on first use would improve readability.
- [Abstract] The empirical observation about oscillatory vs. smooth series is described qualitatively; a brief quantitative summary (e.g., performance delta on trend-dominated vs. fluctuating subsets) would strengthen the motivation.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the emphasis on strengthening the theoretical presentation and empirical attribution of gains. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (theoretical insight paragraph): the claim that 'retrieval aggregation reduces variance and approximates invariant representation learning without explicit environment supervision' is stated without any derivation, equations, variance-reduction proof, or comparison to standard invariant-risk minimization; this is load-bearing for the central claim that the method enables label-free invariant learning.
Authors: The abstract summarizes the insight concisely due to length limits. The full manuscript contains a dedicated theoretical section deriving the variance-reduction property of retrieval aggregation and relating it to invariant-risk minimization without environment labels. We will revise the abstract to include a brief parenthetical reference to this analysis for improved clarity. revision: partial
-
Referee: [Abstract] Abstract and experiments description: no invariance metric (e.g., prediction stability across shifts), mutual-information measure between components, or ablation removing the routing mechanism is mentioned; without such evidence the robustness gains cannot be attributed to the claimed decomposition rather than simply richer retrieval context.
Authors: We agree this evidence would strengthen attribution. The current experiments emphasize forecasting accuracy under shifts but omit explicit invariance or disentanglement metrics. In revision we will add an ablation removing the routing mechanism, plus metrics for prediction stability across shifts and mutual information between the invariant and dynamic components. revision: yes
-
Referee: [Abstract] Abstract (weakest-assumption paragraph): the assumption that retrieved sequences can be treated as implicit samples from related environments enabling unsupervised decomposition is presented without any supporting diagnostic (e.g., environment-similarity statistics or routing visualization); this directly underpins the entire retrieval-guided routing design.
Authors: We concur that diagnostics would better support the modeling assumption. The revised version will incorporate environment-similarity statistics between retrieved and query sequences together with routing visualizations demonstrating separation of invariant and dynamic factors. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and excerpts describe a retrieval-guided decomposition framework with a claimed theoretical insight that retrieval aggregation reduces variance and approximates invariant learning. No equations, derivations, or self-citations are exhibited that reduce any prediction or result to its inputs by construction, nor do any load-bearing steps rely on fitted parameters renamed as predictions or uniqueness theorems imported from the same authors. The central claims rest on the proposed architecture, training objectives, and empirical validation, which remain independent of the inputs in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Foundation models for time series: A survey.arXiv preprint arXiv:2504.04011,
Siva Rama Krishna Kottapalli, Karthik Hubli, Sandeep Chandrashekhara, Garima Jain, Sunayana Hubli, Gayathri Botla, and Ramesh Doddaiah. Foundation models for time series: A survey.arXiv preprint arXiv:2504.04011,
-
[2]
Seunghan Lee, Jaehoon Lee, Jun Seo, Sungdong Yoo, Minjae Kim, Tae Yoon Lim, Dongwan Kang, Hwanil Choi, SoonYoung Lee, and Wonbin Ahn. Cross-rag: Zero-shot retrieval-augmented time series forecasting via cross-attention.arXiv preprint arXiv:2603.14709,
-
[3]
Timer-S1: A Billion-Scale Time Series Foundation Model with Serial Scaling
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models. In International Conference on Machine Learning, pages 39295–39317, 2025b. Yong Liu, Xingjian Su, Shiyu Wang, Haoran Zhang, Haixuan Liu, Yuxuan Wang, Zhou Ye, Yang Xiang, Jianmin Wang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Deep learning for energy time-series analysis and forecasting.arXiv preprint arXiv:2306.09129,
Maria Tzelepi, Charalampos Symeonidis, Paraskevi Nousi, Efstratios Kakaletsis, Theodoros Manousis, Pavlos Tosidis, Nikos Nikolaidis, and Anastasios Tefas. Deep learning for energy time-series analysis and forecasting.arXiv preprint arXiv:2306.09129,
-
[5]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Chen Wang, Mingsheng Long, and Jianmin Wang. Deep time series models: A comprehensive survey and benchmark.arXiv preprint arXiv:2407.13278,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. InInternational Conference on Learning Representations. 11 Shangyu Wu, Ying Xiong, Yufei Cui, Haolun Wu, Can Chen, Ye Yuan, Lianming Huang, Xue Liu, Tei-Wei Kuo, Nan Guan, et al. Retrieval-augmented generat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
More robust forecasting under distribution shifts could support better decision-making when target-domain supervision is limited
12 A Broader Impacts This work aims to improve robust zero-shot time series forecasting, which may benefit applications such as weather forecasting, energy management, healthcare, and finance. More robust forecasting under distribution shifts could support better decision-making when target-domain supervision is limited. Potential risks remain, however. F...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.