Estimating Mixture Distributions via Stochastic Mirror Descent
Pith reviewed 2026-06-29 23:54 UTC · model grok-4.3
The pith
Stochastic mirror descent on mixture models yields estimators with near-optimal convergence rates in KL divergence and L2 norm that scale to many components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By casting mixture estimation as stochastic convex optimization over the simplex of M-component weights and applying stochastic mirror descent with a chosen Bregman divergence, the resulting φ-SMD estimators converge at near-optimal rates in KL divergence and ℓ2 norm, remain computationally cheap even when the pool of basis distributions is large, and require no strict lower bound on probabilities for discrete outcomes.
What carries the argument
Stochastic mirror descent updates on the probability simplex of mixture weights, driven by Bregman divergences that define the estimator family.
If this is right
- A practitioner can enlarge the pool of candidate components to obtain richer approximations without a proportional rise in computation.
- Classical estimators such as maximum-likelihood mixtures emerge as special cases of the same framework by suitable choice of Bregman divergence.
- Estimation on discrete data proceeds without needing the precise support of the target distribution in advance.
- The same optimization view supplies convergence guarantees in both information divergence and Euclidean distance simultaneously.
Where Pith is reading between the lines
- The same mirror-descent construction could be applied to other convex losses beyond cross-entropy, such as those arising in robust estimation.
- Because the method decouples the cost of adding components from the cost of the optimization step, it may be useful for over-complete dictionaries in high-dimensional settings where EM-style methods become intractable.
- The framework invites direct comparison experiments that measure wall-clock time versus statistical error on data sets whose support size is only partially known.
Load-bearing premise
The selected family of basis distributions is rich enough that the best mixture in that family is close to the unknown target.
What would settle it
A concrete counter-example mixture family and target distribution where the observed KL or L2 error of the φ-SMD estimator fails to improve at the claimed near-optimal rate as the sample size grows.
Figures
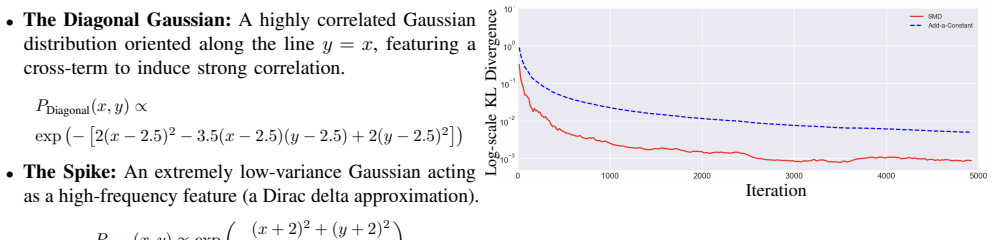
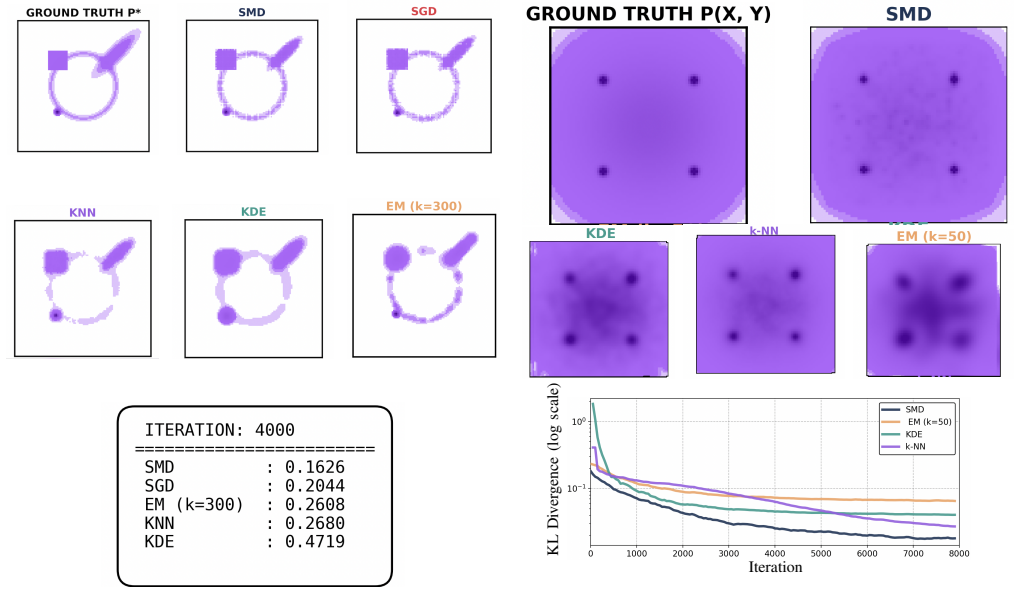

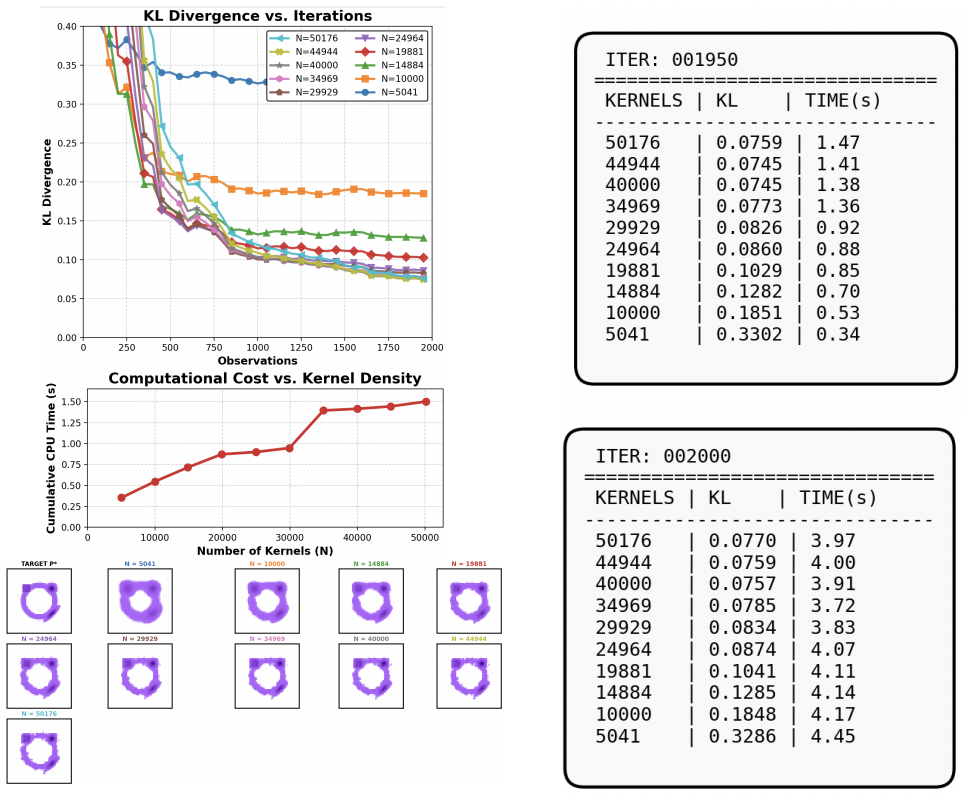
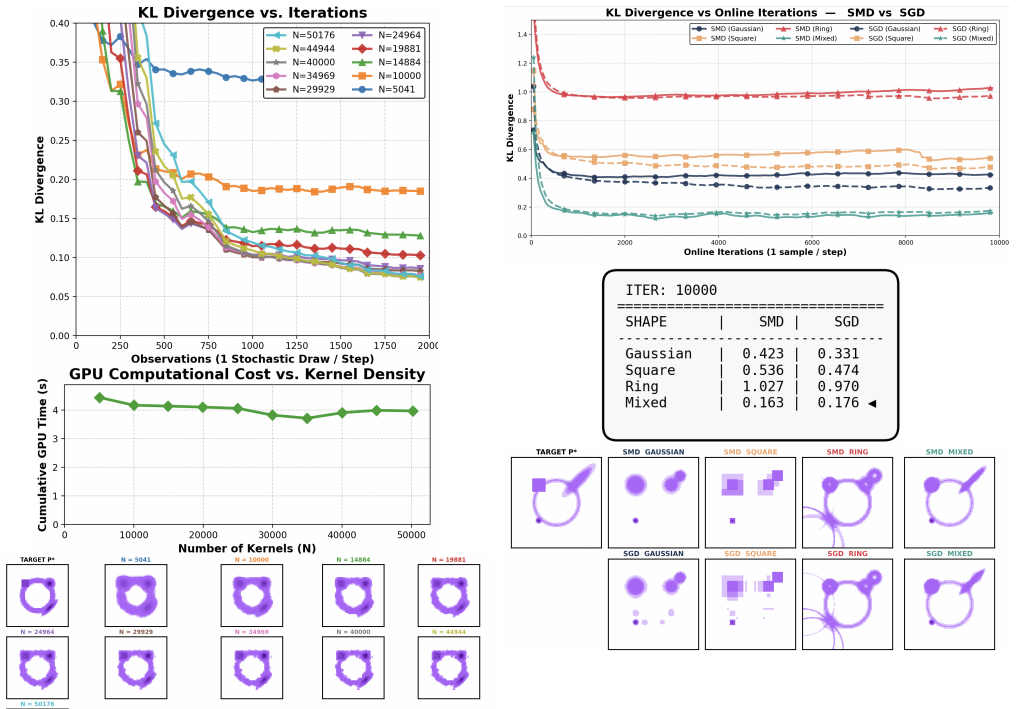
read the original abstract
We revisit the classical problem of estimating an unknown distribution from its samples by fitting a mixture model that minimizes cross-entropy loss. Framing the task as a stochastic convex optimization problem over the space of $ M $-component mixture distributions, we propose a family of estimators derived from the stochastic mirror descent (SMD) algorithm. This optimization-based approach provides a principled and flexible framework that generalizes traditional estimators and proposes a variety of novel estimators through the choice of Bregman divergences. A key advantage of our method is that it scales efficiently with the number of candidate components $ f_i $; that is, one can employ a large set of basis distributions in the mixture model without incurring significant computational overhead. This enables richer approximations and improved estimation accuracy. Moreover, in the case of categorical distribution (discrete outcomes) our estimators do not require a strict lower bound, in other words our framework does not require the precise knowledge of the support of the distribution. We demonstrate that, under mild conditions, the proposed $ \varphi $-SMD estimators achieve near-optimal convergence rates in both Kullback-Leibler (KL) divergence and $ \ell_2 $-norm and offer practical benefits when computation is expensive. Our numerical analysis highlights improved performance guaranties over classical estimators, particularly in terms of sample efficiency and scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript frames distribution estimation from samples as stochastic convex optimization over the simplex of weights for an M-component mixture model, minimizing cross-entropy loss. It introduces a family of φ-SMD estimators obtained by applying stochastic mirror descent with general Bregman divergences, asserts that the method scales to large numbers of basis distributions without significant overhead, requires no strict support lower bound for categorical distributions, and proves that the estimators attain near-optimal rates in KL divergence and ℓ₂ norm under mild conditions. Numerical experiments are reported to demonstrate gains in sample efficiency and scalability relative to classical estimators.
Significance. If the stated convergence rates hold and the optimization framing is correctly instantiated, the work supplies a flexible, computationally attractive route to mixture-based estimators that generalizes several classical procedures through the choice of Bregman divergence and removes a common support restriction in the discrete case. The emphasis on scalability with the number of candidate components is a practical strength for richer approximations.
minor comments (3)
- Abstract: the phrase 'improved performance guaranties' contains a typographical error and should read 'improved performance guarantees'.
- Abstract: the notation 'φ-SMD' is used before any definition of the underlying Bregman divergence or the precise update rule; a one-sentence clarification would improve readability for readers outside the immediate subfield.
- Abstract: the phrase 'under mild conditions' is repeated without even a high-level indication of what those conditions are (e.g., boundedness of the basis densities, convexity parameters); while the full text presumably supplies them, the abstract would benefit from a parenthetical hint.
Simulated Author's Rebuttal
We thank the referee for the careful reading and positive recommendation of minor revision. The report provides a concise summary of the contribution but lists no specific major comments requiring response.
Circularity Check
No significant circularity; derivation is self-contained in standard SMD theory
full rationale
The paper frames the mixture estimation task as stochastic convex optimization over M-component weights and derives φ-SMD estimators via Bregman divergences. The near-optimal KL and ℓ2 rates are obtained from established SMD convergence results under mild conditions on the convex problem, without any equation that reduces a reported rate to a fitted parameter from the same data, without self-definitional loops, and without load-bearing self-citations that substitute for independent verification. The framework generalizes classical estimators through flexible choice of divergence but does not rename known empirical patterns or import uniqueness via prior author work. The central claim therefore rests on external convex-optimization theory rather than on quantities defined by the paper's own fitting procedure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The cross-entropy loss over mixture weights is convex in the weights.
- standard math Stochastic gradients have bounded variance or satisfy standard concentration conditions.
Reference graph
Works this paper leans on
-
[1]
Robust Stochastic Approximation Approach to Stochastic Programming
Nemirovski, Arkadi and Juditsky, Anatoli and Lan, Guanghui and Shapiro, Alexander. Robust Stochastic Approximation Approach to Stochastic Programming. SIAM Journal on Optimization, 19(4):1574– 1609, 2009
2009
-
[2]
Braess, J
D. Braess, J. Forster, T. Sauer, and H. U. Simon. How to Achieve Minimax Expected Kullback-Leibler Distance from an Unknown Finite Distribution. In Algorithmic Learning Theory: Proceedings of the 13th International Conference (ALT), pages 380–394. Springer, 2002
2002
-
[3]
Barron and Thomas M
Andrew R. Barron and Thomas M. Cover. Minimum complexity density estimation. IEEE Transactions on Information Theory, 37(4):1034–1054, 1991
1991
-
[4]
On centralized and distributed mirror descent: Convergence analysis using quadratic constraints
Youbang Sun, Mahyar Fazlyab, and Shahin Shahrampour. On centralized and distributed mirror descent: Convergence analysis using quadratic constraints. IEEE Transactions on Automatic Control, 68(5):3139–3146, 2022
2022
-
[5]
Peer-to-peer Federated Learning on Graphs
Anusha Lalitha, Osman Cihan Kilinc, Tara Javidi, and Farinaz Koushanfar. Peer-to-peer federated learning on graphs. arXiv preprint arXiv:1901.11173, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[6]
Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging Fig
Ohad Shamir and Tong Zhang. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging Fig. 5: Comparison of GPU time consumption (top) for different kernel sizes with CPU time consumption (bottom). schemes. In International conference on machine learning, pages 71–79, 2013
2013
-
[7]
Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. Stochastic gradient descent with differentially private updates. In 2013 IEEE Global Conference on Signal and Information Processing, pages 245–
2013
-
[8]
Painless stochastic gradient: Interpolation, line-search, and convergence rates
Sharan Vaswani, Aaron Mishkin, Issam Laradji, Mark Schmidt, Gau- thier Gidel, and Simon Lacoste-Julien. Painless stochastic gradient: Interpolation, line-search, and convergence rates. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[9]
On learning distributions from their samples
Sudeep Kamath, Alon Orlitsky, Dheeraj Pichapati, and Ananda Theertha Suresh. On learning distributions from their samples. In Conference on Learning Theory, pages 1066–1100. PMLR, 2015
2015
-
[10]
Parallel Gaussian Process Optimization with Upper Confidence Bound and Pure Exploration
Emile Contal, David Buffoni, Alexandre Robicquet, and Nicolas Vayatis. Parallel Gaussian Process Optimization with Upper Confidence Bound and Pure Exploration. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 225–240. Springer, 2013
2013
-
[11]
Scattered data approximation
Holger Wendland. Scattered data approximation. Cambridge University Press, 2004
2004
-
[12]
Gaussian Fig
Christopher KI Williams and Carl Edward Rasmussen. Gaussian Fig. 6: Comparison of GPU time consumption for different kernel sizes. processes for machine learning. MIT Press, 2006
2006
-
[13]
Adams, and Nando De Freitas
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando De Freitas. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1):148–175, 2015
2015
-
[14]
Posterior Variance Analysis of Gaussian Processes with Application to Average Learning Curves
Armin Lederer, Jonas Umlauft, and Sandra Hirche. Posterior Variance Analysis of Gaussian Processes with Application to Average Learning Curves. arXiv preprint arXiv:1906.01404, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[15]
H. Jiang. Uniform convergence rates for kernel density estimation. InProceedings of the International Conference on Machine Learning (ICML), pages 1694–1703, 2017
2017
-
[16]
M. J. Fryer. A review of some non-parametric methods of density estimation.IMA Journal of Applied Mathematics, 20(3):335–354, 1977
1977
-
[17]
E. J. Wegman. Nonparametric probability density estimation: I. A summary of available methods.Technometrics, 14(3):533–546, 1972
1972
-
[18]
Zhao and L
P. Zhao and L. Lai. Analysis of kNN density estimation.IEEE Transactions on Information Theory, 68(12):7971–7995, 2022
2022
-
[19]
C. F. J. Wu. On the convergence properties of the EM algorithm.The Annals of Statistics, pages 95–103, 1983
1983
-
[20]
An online classification EM algorithm based on the mixture model,
A. Sam ´e, C. Ambroise, and G. Govaert, “An online classification EM algorithm based on the mixture model,”Statistics and Computing, vol. 17, no. 3, pp. 209–218, 2007. Fig. 7: Comparison of SMD and SGD over different kernel shapes and sizes. VII. APPENDIX We begin with proof of the lemma II.3 Proof. We establish convexity by directly computing the Hessian...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.