H²MT: Semantic Hierarchy-Aware Hierarchical Memory Transformer
Pith reviewed 2026-06-30 12:24 UTC · model grok-4.3
The pith
H²MT builds an offline semantic hierarchy of a long document so that queries can route coarse-to-fine and discard irrelevant branches before full processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
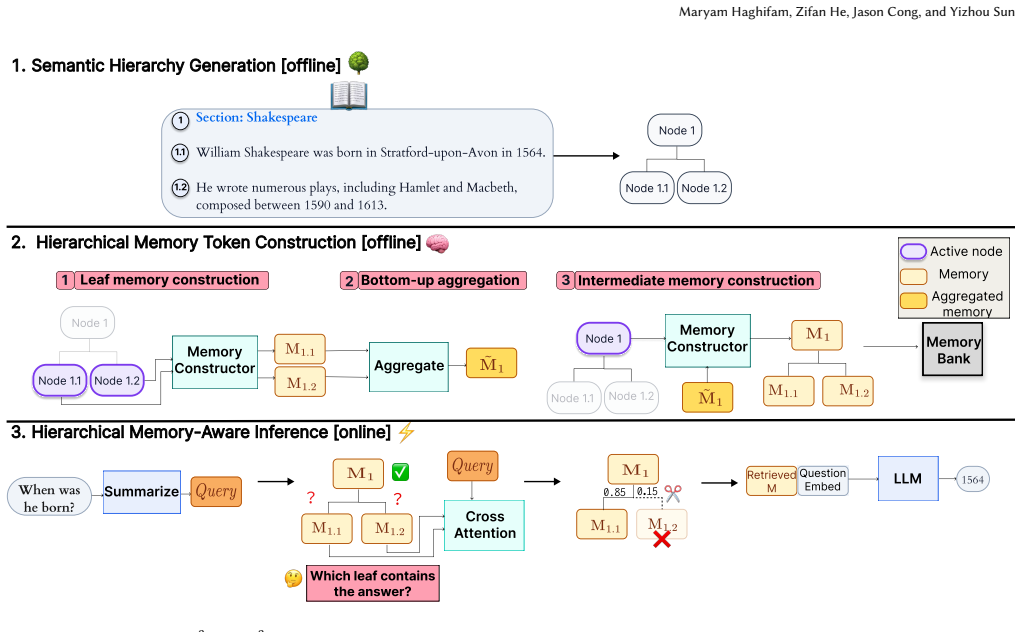
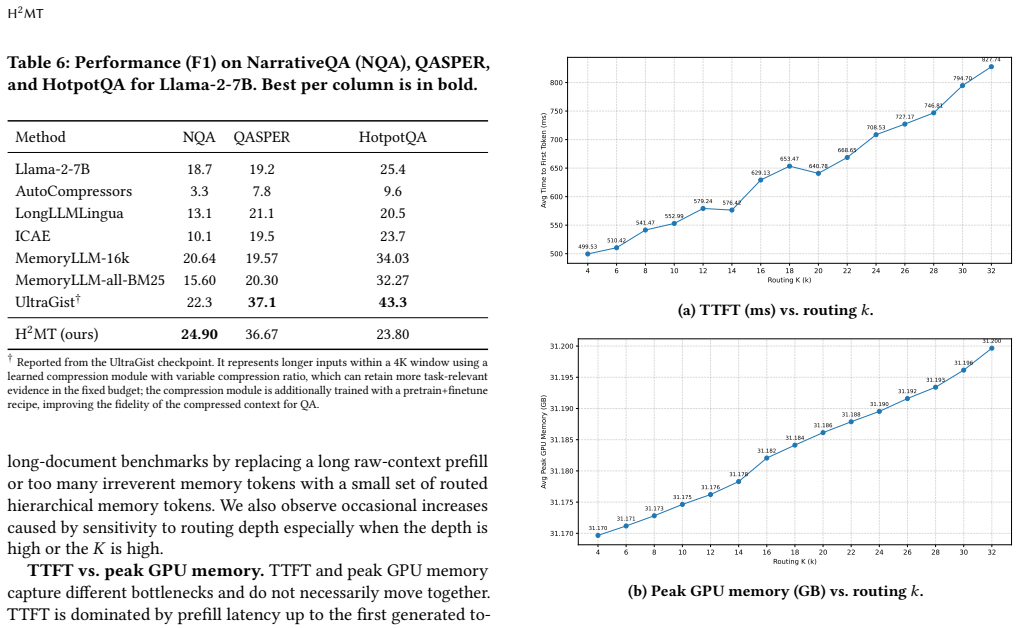
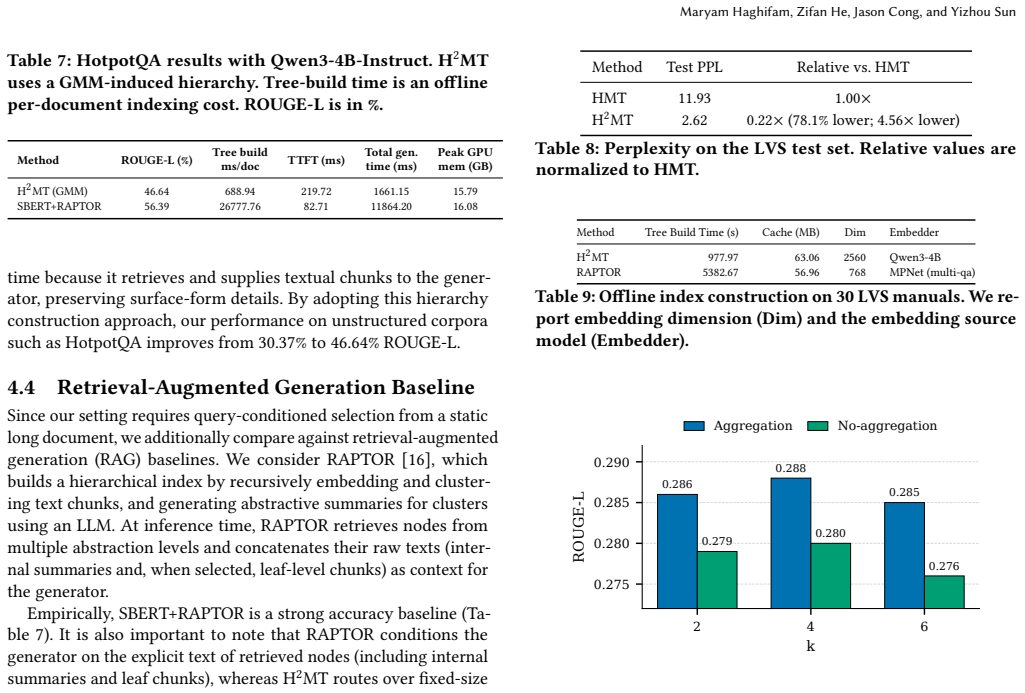
H²MT makes long-context inference structure-aware: it builds a semantic hierarchy offline, computes a memory embedding for each node via bottom-up post-order aggregation, and routes queries coarse-to-fine at inference to prune irrelevant branches early, delivering competitive ROUGE-L and F1 scores with lower peak GPU memory and time-to-first-token than prompt compression, memory-token methods, and retrieval-augmented generation baselines on LongBench QA and structured technical-document settings.
What carries the argument
The semantic hierarchy whose nodes each hold a memory embedding aggregated bottom-up in post-order; coarse-to-fine routing then uses these embeddings to decide which branches to prune.
If this is right
- Peak GPU memory during inference stays below that of full-prompt and retrieval baselines.
- Time-to-first-token decreases because large irrelevant subtrees are never loaded or attended to.
- No external vector index or additional storage is required beyond the built hierarchy.
- Quality remains within a few points of uncompressed baselines on NarrativeQA, HotpotQA, and QASPER.
Where Pith is reading between the lines
- If the hierarchy can be updated incrementally, the same routing logic might extend to streaming or continually growing documents.
- The same coarse-to-fine pruning principle could be applied inside attention layers rather than only at the document level.
- Documents whose natural sections already form clean hierarchies would see the largest efficiency gains.
Load-bearing premise
The offline semantic hierarchy accurately reflects the portions of the document that will matter for later queries.
What would settle it
Run the same LongBench QA suites after deliberately building hierarchies from documents whose section structure misleads about query relevance; if F1 or ROUGE-L then falls materially below the flat baselines, the pruning step is discarding necessary information.
Figures

read the original abstract
Transformer-based LLMs achieve strong results on many language tasks; however, long inputs remain challenging because context windows are finite, and prefill latency and memory grow rapidly with prompt length. Flat token-stream processing and chunk-based retrieval can therefore spend substantial computation and context budget on text unrelated to the query. Offline-indexed RAG additionally introduces external storage and index management overhead, and typically appends retrieved evidence as raw text, increasing prefill cost and latency. H^{2}MT makes long-context inference structure-aware: it builds a semantic hierarchy offline, computes a memory embedding for each node via bottom-up post-order aggregation, and routes queries coarse-to-fine at inference to prune irrelevant branches early. On LongBench QA (NarrativeQA, HotpotQA, QASPER) and two structured technical-document settings, H MT achieves favorable quality efficiency trade-offs, delivering competitive ROUGE-L and F1 (where applicable) with lower peak GPU memory and time-to-first-token (TTFT) than prompt compression, memory-token methods, and retrieval-augmented generation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces H²MT, a hierarchical memory transformer that builds a semantic hierarchy offline from long documents, computes node memory embeddings via bottom-up post-order aggregation, and performs coarse-to-fine query routing at inference time to prune irrelevant branches early. It claims competitive ROUGE-L and F1 scores (where applicable) alongside lower peak GPU memory and TTFT than prompt-compression, memory-token, and RAG baselines on LongBench QA tasks (NarrativeQA, HotpotQA, QASPER) plus two structured technical-document settings.
Significance. If the offline hierarchy reliably encodes query-relevant structure, the coarse-to-fine pruning mechanism could deliver a practical quality-efficiency improvement for long-context inference without external index overhead or raw-text retrieval costs.
major comments (2)
- [§3 (Hierarchy Construction and Routing)] The central quality-efficiency claim rests on the assumption that offline bottom-up aggregation produces nodes whose pruning discards only irrelevant content; however, no ablation, oracle-hierarchy comparison, or hierarchy-fidelity metric is provided to test whether the fixed hierarchy aligns with query needs on NarrativeQA or HotpotQA.
- [§4.2 (Experimental Results)] Table 2 (LongBench QA results): reported ROUGE-L/F1 values are presented as competitive, yet without isolating the effect of pruning (e.g., via an unpruned hierarchical baseline or relevance-recall analysis), it is impossible to confirm that efficiency gains do not trade off against quality on the reported tasks.
minor comments (3)
- [Abstract] Abstract contains the typo 'H MT' instead of 'H²MT'.
- [Abstract and §4.1] The two structured technical-document settings are mentioned but never named or described.
- [§3.1] Notation for memory-embedding aggregation (bottom-up post-order) is introduced without an explicit equation or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the hierarchy construction and experimental validation. We address each major comment below and will make revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 (Hierarchy Construction and Routing)] The central quality-efficiency claim rests on the assumption that offline bottom-up aggregation produces nodes whose pruning discards only irrelevant content; however, no ablation, oracle-hierarchy comparison, or hierarchy-fidelity metric is provided to test whether the fixed hierarchy aligns with query needs on NarrativeQA or HotpotQA.
Authors: We agree that direct validation of hierarchy-query alignment would provide stronger support for the pruning mechanism. While the competitive ROUGE-L and F1 scores on NarrativeQA and HotpotQA (tasks requiring precise relevance judgments) offer indirect evidence that the offline hierarchy enables effective pruning, we will add a hierarchy-fidelity analysis (e.g., recall of query-relevant nodes post-pruning) and an oracle-hierarchy comparison in the revised §3 and experiments. revision: yes
-
Referee: [§4.2 (Experimental Results)] Table 2 (LongBench QA results): reported ROUGE-L/F1 values are presented as competitive, yet without isolating the effect of pruning (e.g., via an unpruned hierarchical baseline or relevance-recall analysis), it is impossible to confirm that efficiency gains do not trade off against quality on the reported tasks.
Authors: The reported results already compare against flat, memory-token, and RAG baselines that lack hierarchical pruning, showing maintained quality with reduced memory and TTFT. To directly isolate the pruning contribution, we will add an unpruned hierarchical baseline and a relevance-recall analysis of pruned content to the revised Table 2 and §4.2. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical architecture (offline hierarchy construction via bottom-up aggregation, coarse-to-fine routing at inference) whose quality-efficiency claims rest on measured ROUGE-L/F1, peak memory, and TTFT numbers across LongBench tasks. No equations, fitted parameters, or self-citations are presented that would make any reported gain equivalent to the method definition by construction. The performance numbers are externally falsifiable on the cited benchmarks and do not reduce to tautological inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long- Document Transformer.arXiv preprint arXiv:2004.05150(2020). https://arxiv. org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [3]
-
[4]
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. 2023. Adapt- ing Language Models to Compress Contexts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computa- tional Linguistics, Singapore, 3829–3846. doi:10.18653/v1/2023.emnlp-main.232
-
[5]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating Long Sequences with Sparse Transformers.arXiv preprint arXiv:1904.10509(2019). https://arxiv.org/abs/1904.10509
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, An- dreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. 2021. Rethinking At- tention with Performers. InInternational Conference on Learning Representations. https://arxiv.org/abs/2009.14794
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Le, and Ruslan Salakhutdinov
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. 2019. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. https://aclanthology.org/P19-1285/
2019
-
[8]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025). https: //arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Tao Ge, Hu Jing, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. 2024. In-context Autoencoder for Context Compression in a Large Language Model. InThe Twelfth International Conference on Learning Representations. https: //openreview.net/forum?id=uREj4ZuGJE
2024
-
[10]
Anthony Grattafiori et al . 2024. The Llama 3 Herd of Models. (2024). arXiv:2407.21783 [cs.LG] https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Haoyu He, Markus Flicke, Jan Buchmann, Iryna Gurevych, and Andreas Geiger
-
[12]
InProceedings of the Conference on Language Modeling (COLM)
HDT: Hierarchical Document Transformer. InProceedings of the Conference on Language Modeling (COLM). https://openreview.net/pdf?id=dkpeWQRmlc Published as a conference paper at COLM 2024
2024
-
[13]
Zifan He, Yingqi Cao, Zongyue Qin, Neha Prakriya, Yizhou Sun, and Jason Cong. 2025. HMT: Hierarchical Memory Transformer for Efficient Long Context Language Processing. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Associati...
-
[14]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, B...
2024
-
[15]
doi:10.18653/v1/2024.acl-long.91
-
[16]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
- [17]
-
[18]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7–11, 2024. OpenReview.net. https://openreview.net/forum?id=GN921JHCRw
2024
-
[19]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30. 5998–
2017
-
[20]
https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Lin- former: Self-Attention with Linear Complexity.arXiv preprint arXiv:2006.04768 (2020). https://arxiv.org/abs/2006.04768
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[22]
Xiaoqiang Wang, Suyuchen Wang, Yun Zhu, and Bang Liu. 2025. R 3Mem: Bridging Memory Retention and Retrieval via Reversible Compression. In Findings of the Association for Computational Linguistics: ACL 2025, Wanxi- ang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 454...
-
[23]
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian Mcauley. 2024. MEMORYLLM: Towards Self-Updatable Large Language Models. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov...
2024
-
[24]
Rabe, DeLesley Hutchins, and Christian Szegedy
Yuhuai Wu, Markus N. Rabe, DeLesley Hutchins, and Christian Szegedy. 2022. Memorizing Transformers.arXiv preprint arXiv:2203.08913(2022). https://arxiv. org/abs/2203.08913
-
[25]
An Yang et al. 2024. Qwen2 Technical Report. (2024). arXiv:2407.10671 [cs.CL] https://arxiv.org/abs/2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Manzil Zaheer, Guru Guruganesh, Joshua Ainslie, Chris Alberti, Santiago On- tanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for Longer Sequences. InAdvances in Neural Information Processing Systems. https://arxiv.org/abs/2007.14062
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [27]
-
[28]
Warning/Note/Caution
Lin Zheng, Chong Wang, and Lingpeng Kong. 2022. Linear Complexity Random- ized Self-attention Mechanism. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Ka- malika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (Eds.). PMLR, 27011–27041. https:...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.