SEP-Attack: A Simple and Effective Paradigm for Transfer-Based Textual Adversarial Attack
Pith reviewed 2026-06-30 12:17 UTC · model grok-4.3
The pith
SEP-Attack uses DPP to assign diverse weights to surrogate models for better transferable textual attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
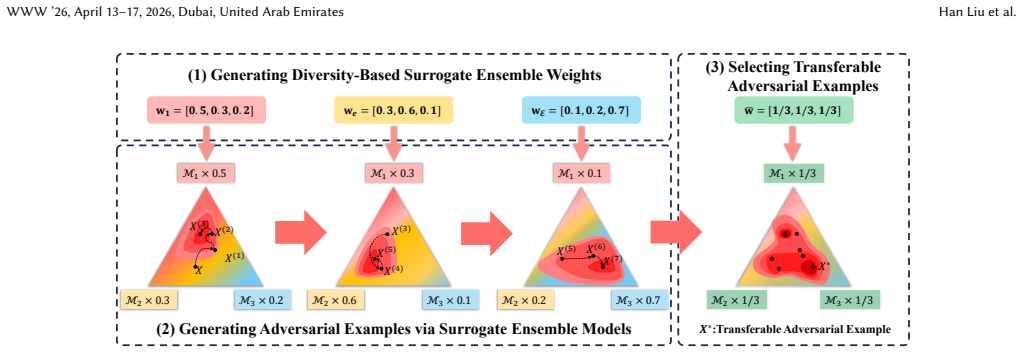
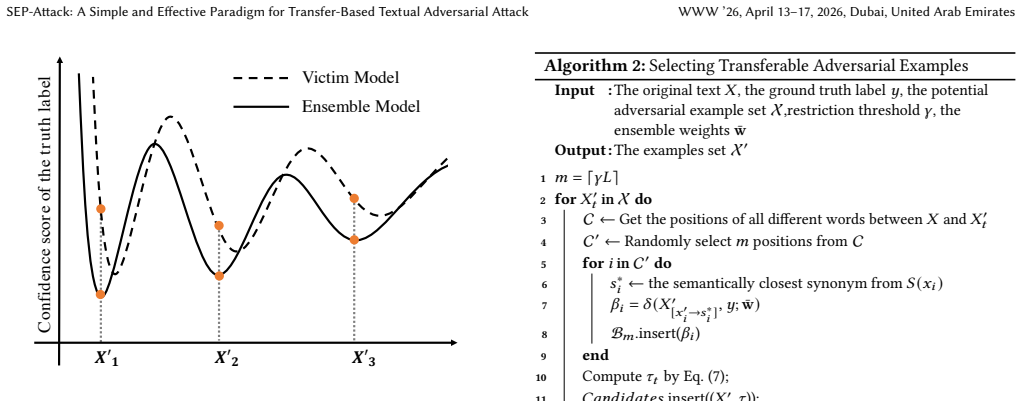
SEP-Attack employs the Determinantal Point Process to generate diverse surrogate ensemble weights that represent the transferability of submodels. Using these weights, a new metric evaluates prediction confidence scores, which are used to calculate word importance scores and generate adversarial candidates. A quantified transferability score is then applied to each candidate to select the final transferable adversarial examples.
What carries the argument
Determinantal Point Process (DPP) for generating diverse surrogate ensemble weights that represent submodel transferability and improve word importance scoring plus candidate selection.
If this is right
- Word importance scores become more accurate when derived from transferability-weighted confidence values.
- Adversarial candidates selected via the new metric achieve higher attack success on black-box targets.
- Quantified transferability scoring enables explicit ranking of candidates before deployment against real APIs.
- The overall pipeline scales to multiple datasets without requiring victim model gradients or architecture details.
Where Pith is reading between the lines
- The same DPP weighting idea could be tested on vision models to check whether diversity in surrogates generalizes beyond text.
- Replacing DPP with other diversity mechanisms might yield different transfer gains and could be compared directly.
- Success on real APIs suggests the method could be evaluated on larger language models where API access is the only option.
Load-bearing premise
That DPP-generated weights accurately capture how well each submodel's behavior transfers to the victim model.
What would settle it
An experiment that replaces DPP weighting with uniform weights on the same surrogate set and finds no gain in transfer success rate on held-out victims would refute the core benefit.
Figures
read the original abstract
Despite the strong performance of deep neural networks in modern Web and language applications, they remain vulnerable to adversarial attacks, especially transferable attacks that generate adversarial examples using surrogate models without accessing the victim model. Transferable attacks in the text domain are still under-explored, with only a few studies addressing this challenging issue, often with suboptimal results due to equal treatment of submodels or inaccurate estimation of importance scores. To address these challenges, we propose a simple yet effective paradigm for transfer-based textual adversarial attack, named SEP-Attack. Specifically, we employ the Determinantal Point Process (DPP) to generate diverse surrogate ensemble weights, representing the transferability of submodels. Using these weights, we introduce a new metric to evaluate prediction confidence scores, which in turn are used to calculate word importance scores and generate adversarial candidates. Finally, we quantify the transferability score for each candidate and select the top ones as the final transferable adversarial examples. Experiments conducted on four datasets and two real-world APIs validate the efficacy of SEP-Attack, significantly outperforming state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEP-Attack, a paradigm for transfer-based textual adversarial attacks. It employs the Determinantal Point Process (DPP) to produce diverse weights for an ensemble of surrogate models that represent submodel transferability. These weights define a new metric for prediction confidence scores, which are then used to compute word importance scores and select adversarial candidates. The final step quantifies transferability of each candidate and retains the top ones. Experiments on four datasets and two real-world APIs are reported to show significant outperformance over state-of-the-art baselines.
Significance. If the empirical results hold under scrutiny, the work provides a simple, DPP-based mechanism for improving ensemble diversity and transferability estimation in textual attacks. This directly addresses the documented limitations of equal submodel weighting and inaccurate importance scoring, potentially strengthening robustness evaluations for deployed language models and APIs.
major comments (2)
- [§3.2] §3.2, the DPP weight generation procedure: the claim that the resulting weights 'represent the transferability of submodels' requires an explicit validation step (e.g., correlation with actual cross-model attack success rates) that is not shown; without it the downstream word-importance and candidate-selection steps rest on an unverified proxy.
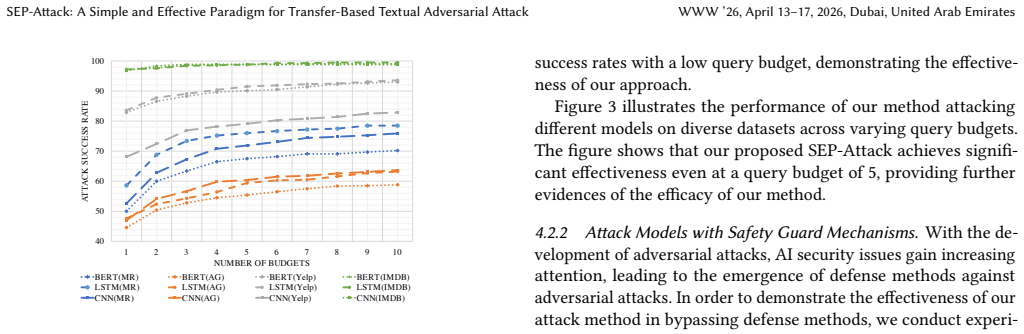
- [§4.2, Table 3] §4.2 and Table 3: the reported attack success rates on the two real-world APIs are given as single-point estimates without standard deviations across random seeds or multiple query budgets; this makes it impossible to determine whether the claimed superiority over baselines is statistically reliable.
minor comments (3)
- [Eq. (5)] The notation for the new confidence metric (Eq. 5) uses the same symbol C for both the per-submodel and the weighted ensemble versions; a distinct symbol would improve readability.
- [Figure 2] Figure 2 caption does not state the number of DPP samples drawn or the kernel matrix construction details, which are needed to reproduce the diversity results.
- [§2] Related-work section omits recent DPP applications in NLP ensemble methods (e.g., 2023–2024 papers on DPP for model selection); adding 2–3 citations would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive recommendation. We address each major point below.
read point-by-point responses
-
Referee: [§3.2] §3.2, the DPP weight generation procedure: the claim that the resulting weights 'represent the transferability of submodels' requires an explicit validation step (e.g., correlation with actual cross-model attack success rates) that is not shown; without it the downstream word-importance and candidate-selection steps rest on an unverified proxy.
Authors: We agree that an explicit validation step would strengthen the claim. In the revised manuscript we will add a correlation analysis (in §3.2 or an appendix) between the DPP-derived weights and measured attack success rates on held-out surrogate-victim pairs. revision: yes
-
Referee: [§4.2, Table 3] §4.2 and Table 3: the reported attack success rates on the two real-world APIs are given as single-point estimates without standard deviations across random seeds or multiple query budgets; this makes it impossible to determine whether the claimed superiority over baselines is statistically reliable.
Authors: We acknowledge that single-point estimates limit statistical assessment. We will rerun the API experiments across multiple random seeds, report means and standard deviations, and update Table 3 accordingly (noting that query budgets on real APIs constrain the number of runs). revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents SEP-Attack as a procedural method using DPP for ensemble weights, a new confidence metric for word importance, and transferability scoring for candidate selection. The abstract and description contain no equations, derivations, or claims that reduce by construction to fitted inputs or self-citations. The central claim is empirical (outperformance on datasets/APIs), with no load-bearing self-referential steps visible. This matches the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pir Noman Ahmad, Adnan Muhammad Shah, KangYoon Lee, and Wazir Muham- mad. 2026. Misinformation detection on online social networks using pretrained language models.Information Processing and Management63, 1 (2026), 104342
2026
-
[2]
AI@Meta. 2024. Llama 3 Model Card. (2024). https://github.com/meta-llama/ llama3/blob/main/MODEL_CARD.md
2024
-
[3]
Cong Chen, Wei Qu, Si Su, Yukun Feng, and Tao Li. 2025. A comprehensive review of LLM-based content moderation: advancements, challenges, and future directions.Knowledge-Based Systems330 (2025), 114689
2025
-
[4]
Huanran Chen, Yichi Zhang, Yinpeng Dong, and Jun Zhu. 2024. Rethinking Model Ensemble in Transfer-based Adversarial Attacks. InInternational Conference on Learning Representations (ICLR)
2024
-
[5]
Laming Chen, Guoxin Zhang, and Eric Zhou. 2018. Fast Greedy MAP Infer- ence for Determinantal Point Process to Improve Recommendation Diversity. In Conference on Neural Information Processing Systems (NeurIPS). 5627–5638
2018
-
[6]
Yangyi Chen, Hongcheng Gao, Ganqu Cui, Fanchao Qi, Longtao Huang, Zhiyuan Liu, and Maosong Sun. 2022. Why Should Adversarial Perturbations be Imper- ceptible? Rethink the Research Paradigm in Adversarial NLP. InConference on Empirical Methods in Natural Language Processing (EMNLP). 11222–11237
2022
-
[7]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In North American Chapter of the Association for Computational Linguistics (NAACL). 4171–4186
2019
-
[8]
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting Adversarial Attacks With Momentum. InComputer Vision and Pattern Recognition (CVPR). 9185–9193
2018
-
[9]
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. 2018. HotFlip: White- Box Adversarial Examples for Text Classification. InAnnual Meeting of the Asso- ciation for Computational Linguistics (ACL). 31–36
2018
-
[10]
Ji Gao, Jack Lanchantin, Mary Lou Soffa, and Yanjun Qi. 2018. Black-Box Gener- ation of Adversarial Text Sequences to Evade Deep Learning Classifiers. InIEEE Symposium on Security and Privacy (S&P). 50–56
2018
-
[11]
Zhijin Ge, Xiaosen Wang, Hongying Liu, Fanhua Shang, and Yuanyuan Liu
-
[12]
In Conference on Neural Information Processing Systems (NeurIPS)
Boosting Adversarial Transferability by Achieving Flat Local Maxima. In Conference on Neural Information Processing Systems (NeurIPS)
-
[13]
Adrián Girón, Javier Huertas-Tato, and David Camacho. 2025. LLM synthetic generation to enhance online content moderation generalization in hate speech scenarios.Computing107, 7 (2025), 164
2025
-
[14]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. InInternational Conference on Learning Representations (ICLR)
2015
-
[15]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Computation(1997), 1735–1780
1997
-
[16]
Tao Huang. 2025. Content moderation by LLM: from accuracy to legitimacy. Artificial Intelligence Review58, 10 (2025), 320
2025
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. InAAAI Conference on Artificial Intelligence (AAAI). 8018–8025
2020
-
[19]
Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification. InConference on Empirical Methods in Natural Language Processing (EMNLP). 1746–1751
2014
-
[20]
Hyun Kwon and Sanghyun Lee. 2023. Ensemble transfer attack targeting text classification systems.Computers & Security124 (2023), 102944
2023
-
[21]
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. InInternational Conference on Learning Representations (ICLR)
2020
-
[22]
Thai Le, Noseong Park, and Dongwon Lee. 2022. SHIELD: Defending Textual Neural Networks against Multiple Black-Box Adversarial Attacks with Stochastic Multi-Expert Patcher. InAnnual Meeting of the Association for Computational Linguistics (ACL). 6661–6674
2022
-
[23]
Deokjae Lee, Seungyong Moon, Junhyeok Lee, and Hyun Oh Song. 2022. Query- Efficient and Scalable Black-Box Adversarial Attacks on Discrete Sequential Data via Bayesian Optimization. InInternational Conference on Machine Learning (ICML). 12478–12497
2022
-
[24]
Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, and Ting Wang. 2019. TextBugger: Generating Adversarial Text Against Real-world Applications. InNetwork and Distributed System Security Symposium (NDSS)
2019
-
[25]
Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. 2020. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. InConference on Empirical Methods in Natural Language Processing (EMNLP). 6193–6202
2020
-
[26]
Han Liu, Zhi Xu, Xiaotong Zhang, Feng Zhang, Fenglong Ma, Hongyang Chen, Hong Yu, and Xianchao Zhang. 2023. HQA-Attack: Toward High Quality Black- Box Hard-Label Adversarial Attack on Text. InConference on Neural Information Processing Systems (NeurIPS)
2023
-
[27]
Xiaodong Liu, Xiao Lin, Yiming Ding, Changcheng Li, Peng Jiang, and Weiran Shen. 2025. Optimizing Revenue through User Coupon Recommendations in Truthful Online Ad Auctions. InThe Web Conference (WWW). ACM, 1380–1388
2025
-
[28]
Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. 2017. Delving into Trans- ferable Adversarial Examples and Black-box Attacks. InInternational Conference on Learning Representations (ICLR)
2017
-
[29]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv preprint arXiv:1907.11692 abs/1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
Zhiwei Liu, Keyi Wang, Zhuo Bao, Xin Zhang, Jiping Dong, Kailai Yang, Mohsinul Kabir, Polydoros Giannouris, Rui Xing, Seongchan Park, Jaehong Kim, Dong Li, Qianqian Xie, and Sophia Ananiadou. 2025. FinNLP-FNP-LLMFinLegal-2025 Shared Task: Financial Misinformation Detection Challenge Task. InInternational Conference on Computational Linguistics (COLING). 271–276
2025
-
[31]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. In Annual Meeting of the Association for Computational Linguistics (ACL). 142–150
2011
-
[32]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. InInternational Conference on Learning Representations (ICLR). OpenRe- view.net
2018
-
[33]
Rishabh Maheshwary, Saket Maheshwary, and Vikram Pudi. 2021. Generating Natural Language Attacks in a Hard Label Black Box Setting. InAAAI Conference on Artificial Intelligence (AAAI). 13525–13533
2021
-
[34]
Zhao Meng and Roger Wattenhofer. 2020. A Geometry-Inspired Attack for Generating Natural Language Adversarial Examples. InCOLING. 6679–6689
2020
-
[35]
Bo Pang and Lillian Lee. 2005. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. InAnnual Meeting of the Association for Computational Linguistics (ACL). 115–124
2005
-
[36]
Zeyu Qin, Yanbo Fan, Yi Liu, Li Shen, Yong Zhang, Jue Wang, and Baoyuan Wu. 2022. Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation. InConference on Neural Information Processing Systems (NeurIPS)
2022
-
[37]
Haoran Tang, Shiqing Wu, Zhihong Cui, Yicong Li, Guandong Xu, and Qing Li. 2025. Model-Agnostic Dual-Side Online Fairness Learning for Dynamic Recommendation.IEEE Transactions on Knowledge and Data Engineering37, 5 (2025), 2727–2742
2025
-
[38]
Xiaosen Wang and Kun He. 2021. Enhancing the Transferability of Adversarial Attacks Through Variance Tuning. InComputer Vision and Pattern Recognition (CVPR). 1924–1933
2021
-
[39]
Likang Wu, Zhaopeng Qiu, Zhi Zheng, Hengshu Zhu, and Enhong Chen. [n. d.]. Exploring Large Language Model for Graph Data Understanding in Online Job Recommendations. InAAAI Conference on Artificial Intelligence (AAAI), Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan (Eds.). 9178–9186
-
[40]
Qingzheng Xu, Heming Du, Szymon Lukasik, Tianqing Zhu, Sen Wang, and Xin Yu. 2025. MDAM3: A Misinformation Detection and Analysis Framework for Multitype Multimodal Media. InThe Web Conference (WWW). ACM, 5285–5296
2025
-
[41]
Muchao Ye, Jinghui Chen, Chenglin Miao, Han Liu, Ting Wang, and Fenglong Ma
-
[42]
InACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
PAT: Geometry-Aware Hard-Label Black-Box Adversarial Attacks on Text. InACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 3093–3104
-
[43]
Muchao Ye, Jinghui Chen, Chenglin Miao, Ting Wang, and Fenglong Ma. 2022. LeapAttack: Hard-Label Adversarial Attack on Text via Gradient-Based Opti- mization. InACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2307–2315
2022
-
[44]
Muchao Ye, Chenglin Miao, Ting Wang, and Fenglong Ma. 2022. TextHoaxer: Bud- geted Hard-Label Adversarial Attacks on Text. InAAAI Conference on Artificial Intelligence (AAAI). 3877–3884
2022
-
[45]
Kan Yuan, Di Tang, Xiaojing Liao, XiaoFeng Wang, Xuan Feng, Yi Chen, Menghan Sun, Haoran Lu, and Kehuan Zhang. 2019. Stealthy Porn: Understanding Real- World Adversarial Images for Illicit Online Promotion. InIEEE Symposium on Security and Privacy (S&P). 952–966
2019
-
[46]
Liping Yuan, Xiaoqing Zheng, Yi Zhou, Cho-Jui Hsieh, and Kai-Wei Chang. 2021. On the Transferability of Adversarial Attacks against Neural Text Classifier. InConference on Empirical Methods in Natural Language Processing (EMNLP). 1612–1625
2021
-
[47]
Zhiyuan Zeng and Deyi Xiong. 2021. An Empirical Study on Adversarial Attack on NMT: Languages and Positions Matter. InAnnual Meeting of the Association for Computational Linguistics (ACL). 454–460
2021
-
[48]
wonderful
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015. Character-level Convo- lutional Networks for Text Classification. InConference on Neural Information Processing Systems (NeurIPS). 649–657. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Han Liu et al. A Dataset Description The detailed dataset information is as follows: • MR[ 34] is a short mov...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.