Universal Boosts, Specific Suppressors: Sparse Autoencoder Steering of Medical Vision-Language Models
Pith reviewed 2026-06-30 12:33 UTC · model grok-4.3
The pith
Sparse autoencoder steering at inference time improves chest X-ray report quality on multiple vision-language models without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the MIMIC-CXR test split, the inference-only SAE steering method improves the quality of generated reports for RadVLM, LLaVA-Rad, and CheXOne, with relative improvements of +5.4%, +7.2%, and +17.0% in the clinical composite metric and statistically significant GREEN gains on all backbones. Cross-model alignment shows quality-promoting directions overlap strongly while hallucination-linked directions are model-specific, so transferable steering requires backbone-specific suppression. The same features transfer zero-shot to IU-Xray with GREEN gains of +7.7% relative.
What carries the argument
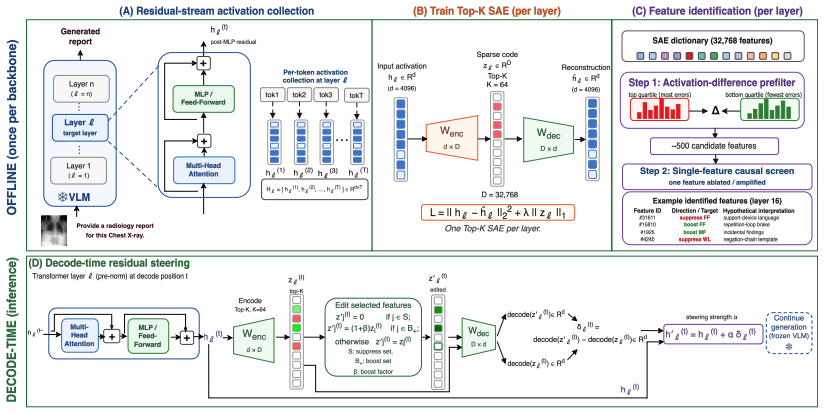
Top-K sparse autoencoders on late layers combined with causal residual steering that applies suppress and boost interventions at inference time.
If this is right
- Boost directions for report quality can be reused across different VLM architectures.
- Hallucination suppression must be handled separately for each model backbone.
- The steering features identified are properties of the model rather than the specific training data.
- The approach requires no weight updates and works at decoding time only.
Where Pith is reading between the lines
- Universal boost directions may exist more broadly for medical vision-language tasks beyond radiology.
- Model-specific suppressors suggest that hallucination patterns differ in how they manifest in different architectures.
- Similar SAE-based interventions could potentially address other error types like incorrect localization in reports.
- Releasing the feature sets allows others to test steering on additional VLMs or datasets.
Load-bearing premise
The top-K selected SAE features on late layers are the causal drivers of the observed clinical errors and can be steered at inference without creating new problems.
What would settle it
A controlled test where the identified boost and suppress vectors are applied to a new set of inputs and the clinical composite or GREEN scores show no improvement or decline compared to the unsteered baseline.
Figures


read the original abstract
Medical vision-language models (VLMs) often hallucinate findings when generating chest X-ray reports: they fabricate findings that are not present in the image, miss important ones, or locate them incorrectly. We mitigate this without weight updates by decoding-time residual steering on a per-token sparse autoencoder (SAE) basis: Top-$K$ SAEs on late layers, causal steering against clinical errors, then combined suppress/boost intervention at inference time. On the MIMIC-CXR test split, our inference-only method improves the quality of generated reports for three radiology VLMs (RadVLM, LLaVA-Rad, and CheXOne), with relative improvements of +5.4%, +7.2%, and +17.0% in the clinical composite metric, and statistically significant GREEN gains on all backbones. A cross-model feature alignment shows that the quality-promoting (boost) directions overlap strongly across architectures, whereas hallucination-linked (suppress) directions are model-specific. Therefore, transferable steering must treat suppression per-backbone, rather than sharing a universal suppress list. The same recipe transfers zero-shot to IU-Xray (Green $+7.7\%$ rel.) without retraining, confirming that the identified features are properties of the model, not of the training corpus. We release causal feature sets and an interactive feature dashboard: https://cxr-sparse-feature-dashboard.netlify.app/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sparse autoencoders (SAEs) applied to late layers of radiology VLMs enable inference-only residual steering: top-K features linked to clinical errors are suppressed while quality-promoting features are boosted, yielding relative gains of +5.4%, +7.2%, and +17.0% in a clinical composite metric on the MIMIC-CXR test split for RadVLM, LLaVA-Rad, and CheXOne, plus statistically significant GREEN improvements. Cross-model alignment shows overlapping boost directions but model-specific suppress directions; the approach transfers zero-shot to IU-Xray (+7.7% GREEN rel.) without retraining, and the authors release feature sets and a dashboard.
Significance. If the causal status of the selected SAE directions is confirmed, the result would be significant for providing a training-free, interpretable intervention to reduce hallucinations in medical VLMs, with the cross-model analysis offering guidance on transferable vs. backbone-specific steering and the public artifacts enabling further work.
major comments (2)
- [Method (SAE feature selection and steering procedure)] The central claim requires that the top-K SAE features selected on error-linked tokens are causally responsible for the reported gains. The manuscript provides no ablation controls that isolate these directions from non-specific effects such as generic activation scaling or steering any high-magnitude late-layer features; without such tests the +5.4–17% clinical composite improvements and GREEN gains cannot be attributed specifically to the chosen suppress/boost directions.
- [Experiments and Results] Statistical methods, exact baseline comparisons, and validation that steering does not introduce new errors or degrade other aspects of report quality are not described with sufficient detail to assess robustness of the cross-model and transfer results.
minor comments (2)
- [Method] Notation for the residual steering operation and the precise definition of the clinical composite metric should be clarified with equations.
- [Abstract and Results] The abstract states 'statistically significant GREEN gains' but does not specify the test or correction used; this detail belongs in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the causal attribution and experimental details.
read point-by-point responses
-
Referee: [Method (SAE feature selection and steering procedure)] The central claim requires that the top-K SAE features selected on error-linked tokens are causally responsible for the reported gains. The manuscript provides no ablation controls that isolate these directions from non-specific effects such as generic activation scaling or steering any high-magnitude late-layer features; without such tests the +5.4–17% clinical composite improvements and GREEN gains cannot be attributed specifically to the chosen suppress/boost directions.
Authors: We agree that additional controls are needed to strengthen the causal claim. In the revised manuscript we will add ablations comparing the error-linked top-K steering against (i) random selection of high-magnitude features from the same late layers and (ii) uniform scaling of activations without feature selection. These will be reported on the same MIMIC-CXR split and metrics to isolate the contribution of the selected directions. revision: yes
-
Referee: [Experiments and Results] Statistical methods, exact baseline comparisons, and validation that steering does not introduce new errors or degrade other aspects of report quality are not described with sufficient detail to assess robustness of the cross-model and transfer results.
Authors: We will expand the Experiments section with precise descriptions of the statistical tests (including exact p-values and confidence intervals), full baseline tables, and additional metrics (e.g., fluency, completeness, and error-type breakdowns) to confirm that steering does not introduce new errors or degrade non-clinical aspects of report quality. These details will cover both the cross-model and zero-shot transfer experiments. revision: yes
Circularity Check
No significant circularity; empirical results on held-out splits are self-contained
full rationale
The paper reports measured improvements (+5.4% to +17.0% clinical composite, GREEN gains) from applying top-K SAE residual steering at inference on three VLMs, evaluated on the MIMIC-CXR test split with zero-shot transfer to IU-Xray. These are direct empirical outcomes from the intervention recipe, not quantities derived by construction from the feature-selection step or from any self-citation chain. No load-bearing premise reduces to a fitted parameter renamed as prediction, a self-definitional loop, or an ansatz imported via the authors' prior work. The cross-model alignment observations are likewise downstream measurements rather than tautological. The derivation chain therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10241–10259, Suzhou, China
SAEs are good for steering – if you select the right features. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10241–10259, Suzhou, China. Association for Computational Linguistics. Shruthi Bannur, Kenza Bouzid, Daniel Coelho de Cas- tro, Anton Schwaighofer, Sam Bond-Taylor, Maxi- milian Ilse, Fernando Pérez...
2025
-
[2]
Technical Report MSR-TR- 2024-18, Microsoft
Maira-2: Grounded radiol- ogy report generation. Technical Report MSR-TR- 2024-18, Microsoft. Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, and 1 others
2024
-
[3]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He
Radiology-aware model-based 9 evaluation metric for report generation.arXiv preprint arXiv:2311.16764. Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He
-
[4]
InInternational Conference on Learning Representations, volume 2024, pages 54158–54183
Dola: Decoding by contrasting layers improves factuality in large language models. InInternational Conference on Learning Representations, volume 2024, pages 54158–54183. Dina Demner-Fushman and 1 others
2024
-
[5]
Preparing a collection of radiology examinations for distribu- tion and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310. Nicolas Deperrois, Hidetoshi Matsuo, Samuel Ruiperez- Campillo, Moritz Vandenhirtz, Sonia Laguna, Alain Ryser, Koji Fujimoto, Mizuho Nishio, Thomas Sut- ter, Julia V ogt, Jonas Kluckert, Thomas Frauenfel...
-
[6]
InICML 2025 Workshop on Reliable and Responsible Founda- tion Models
Steering language model refusal with sparse autoencoders. InICML 2025 Workshop on Reliable and Responsible Founda- tion Models. Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Edward Michalson, Michael Moseley, Curtis Langlotz, Akshay S Chaudhari, and Jean-Benoit Del- brouck
2025
-
[7]
InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 374–390, Miami, Florida, USA
GREEN: Generative radiology report evaluation and error notation. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 374–390, Miami, Florida, USA. Association for Computational Linguistics. Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata
2024
-
[8]
In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1500–1519, Online
Com- bining automatic labelers and expert annotations for accurate radiology report labeling using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1500–1519, Online. Association for Computa- tional Linguistics. Tim Tanida, Philip Müller, Georgios Kaissis, and Daniel Rueckert
2020
-
[9]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 546–557, Suzhou, China
RadEval: A framework for radiology text evaluation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 546–557, Suzhou, China. As- sociation for Computational Linguistics. Feiyang Yu, Mark Endo, Rayan Krishnan, Ian Pan, Andy Tsai, Eduardo Pontes Reis, Eduardo Kaiser Ururahy Nunes Fonseca,...
2025
-
[10]
InInternational Conference on Learning Representations
Bertscore: Eval- uating text generation with bert. InInternational Conference on Learning Representations. Yabin Zhang, Chong Wang, Yunhe Gao, Jiaming Liu, Maya Varma, Justin Xu, Sophie Ostmeier, Jin Long, Sergios Gatidis, Seena Dehkharghani, Arne Michal- son, Eun Kyoung Hong, Christian Bluethgen, Hai- wei Henry Guo, Alexander Victor Ortiz, Stephan Altmay...
-
[11]
Representation engineering: A top-down approach to ai transparency.Preprint, arXiv:2310.01405. 11 Appendix A Layer selection We train SAEs at ten evenly-spaced depths {0,4,8,12,16,20,24,28,32,35} of RadVLM’s 36-layer Qwen3-VL backbone but hook only a sub- set L={8,16,20,24} for steering. Table 5 reports SAE reconstruction quality at each depth, revealing ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
top-activating contexts
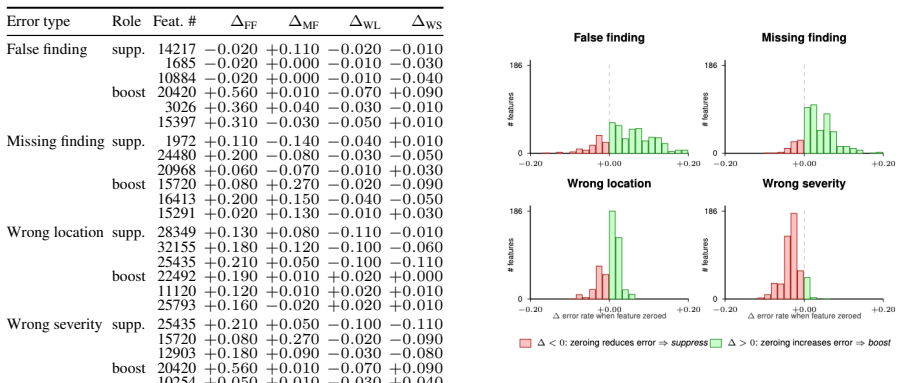
A short synthesis paragraph at the end relates these obser- vations to the cross-model boost-suppress finding in § 5.5. 13 Error Type Role Feat.∆ FF ∆ MF ∆ WL ∆ WS False finding supp. 31611−0.160 +0.040−0.030−0.040 23239−0.130−0.030−0.030−0.030 8320−0.130 +0.100−0.070−0.050 boost 15810+0.300 +0.080 +0.000−0.020 5872+0.280 +0.080 +0.000−0.100 16965+0.270 +...
1925
-
[13]
There is no evidence of pneumothorax. There is no evidence of pul- monary edema
Each feature has a causal sign that tells us what it does. Aboostfeature has ∆t>0: turning it off makes error type t worse, so it was helping the model when it was activated. Asuppressfeature has ∆t<0: turning it off makes the error t better, so it was driving that error when it activated. The text snippets in Table 11 therefore have a simple interpretati...
1925
-
[14]
Good Reporting
For each reported feature, Ta- ble 12 shows how many studies it activates on, how strongly it activates on average, and at which point in the report it activates most (early, middle, or late). By analyzing this, we observed three patterns as follows: • Features related to the repetition-loop are rare and late.Feature #15810 as FF-boost activates on only 4...
1925
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.