Selective Test-Time Compute Scaling for Click-Through Rate Prediction via Uncertainty-Triggered Feature Path Exploration
Pith reviewed 2026-06-30 12:40 UTC · model grok-4.3
The pith
A training-free framework scales test-time compute only for uncertain CTR predictions to improve accuracy at low average cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
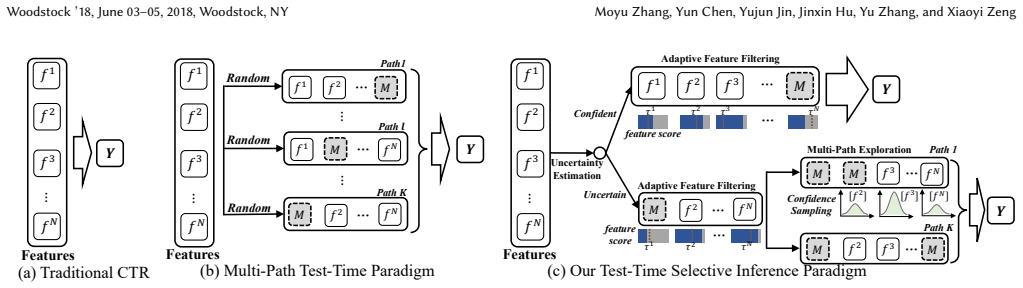
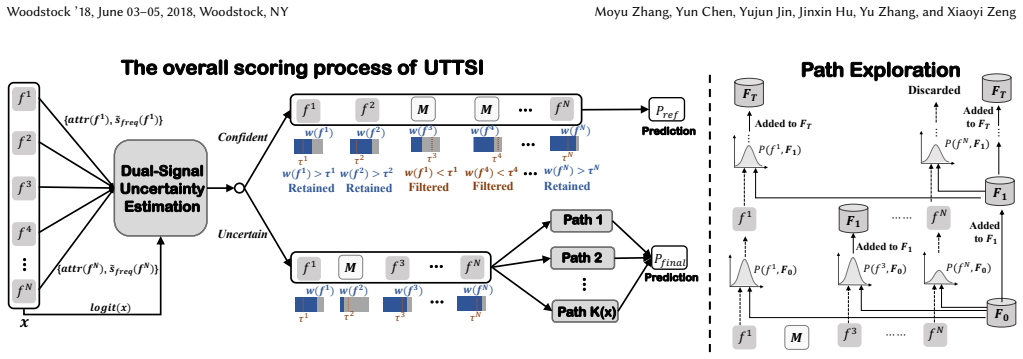
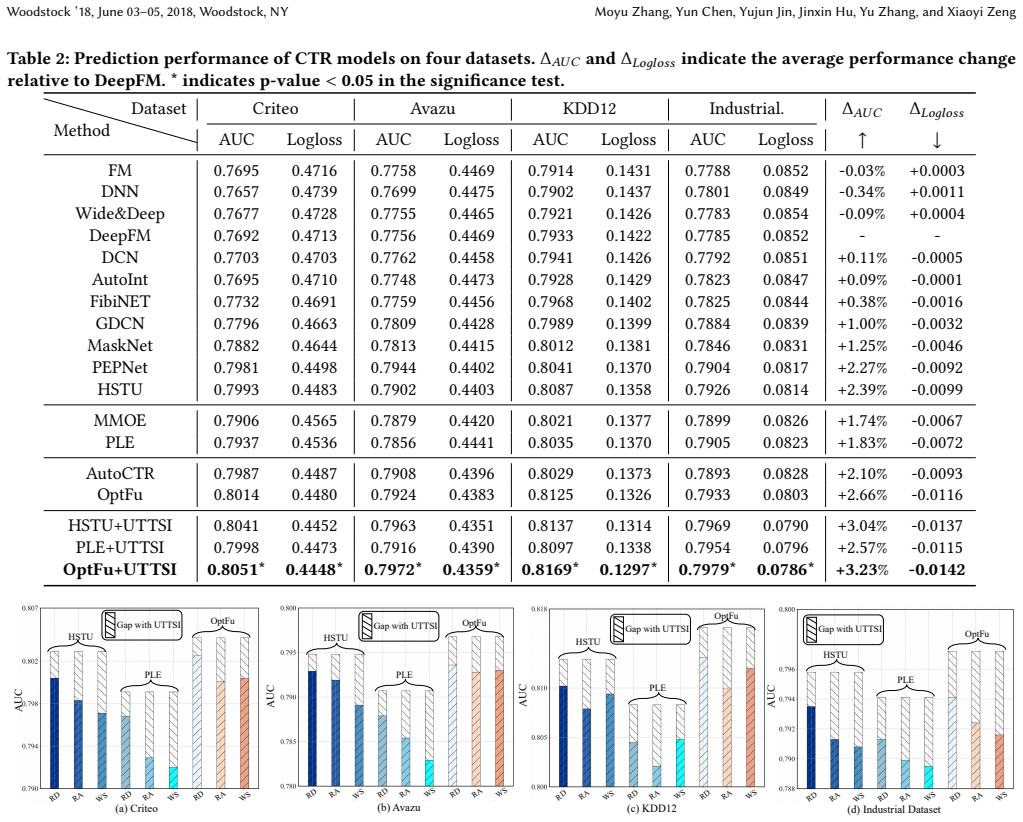
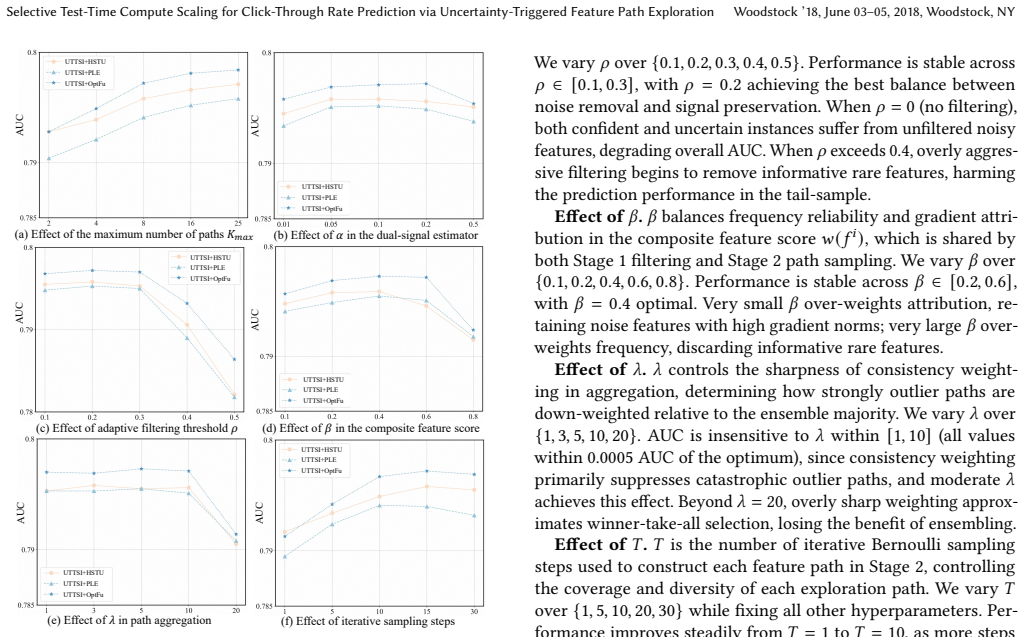
UTTSI distinguishes epistemic uncertainty from aleatoric ambiguity via model logit confidence combined with a data-level frequency prior. Every instance receives adaptive feature filtering to drop unreliable embeddings; high-uncertainty instances additionally undergo stochastic feature-path explorations whose outputs are aggregated by consistency-weighted ensembling. Confident instances bypass exploration, resulting in average overhead of approximately 2.8 times base model cost with worst-case latency unchanged. Experiments across four datasets and three backbones show statistically significant gains over training-phase baselines, and a seven-day online A/B test records a 5.3 percent relativ
What carries the argument
The dual-signal uncertainty estimator (model logit confidence plus data-level frequency prior) that triggers selective feature filtering and stochastic feature-path exploration with consistency-weighted ensembling.
If this is right
- The same selective mechanism delivers gains on multiple public datasets and in live production traffic without altering model training.
- Worst-case latency remains identical to the base model because only uncertain instances incur extra compute.
- The approach works across different backbone architectures and complements rather than replaces existing training-phase techniques.
- Average inference cost stays modest because the majority of instances are routed through the cheap base path.
Where Pith is reading between the lines
- The selective scaling pattern could be tested on other sparse tabular or recommendation tasks that exhibit similar training-data imbalance.
- Replacing the frequency prior with learned uncertainty estimates might further tighten the trigger condition.
- The consistency-weighted ensembling step could be reused as a lightweight way to combine multiple inference paths in other domains.
Load-bearing premise
The dual-signal estimator reliably separates cases where extra feature exploration improves the prediction from cases where it does not.
What would settle it
A controlled test that applies feature-path exploration to low-uncertainty instances and measures whether accuracy rises, or withholds exploration from high-uncertainty instances and measures whether accuracy falls, would falsify the central claim.
Figures
read the original abstract
Scaling test-time compute has proven highly effective for language models, yet this opportunity remains largely unexplored for industrial Click-Through Rate (CTR) prediction. CTR models suffer from a fundamental asymmetry: feature combinations well-represented in training yield confident predictions, while sparsely observed ones produce unreliable outputs. Existing training-phase solutions such as adaptive gating learn a fixed selection function subject to the same sparsity, offering no per-instance recourse at deployment.We propose UTTSI (Uncertainty-Triggered Test-Time Selective Inference), a training-free model-agnostic framework that scales inference depth proportionally to per-instance uncertainty. A dual-signal estimator combining model logit confidence with a data-level frequency prior distinguishes epistemic uncertainty from aleatoric ambiguity. Every instance undergoes adaptive feature filtering to remove unreliable embeddings; uncertain instances additionally receive stochastic feature-path explorations whose predictions are aggregated via consistency-weighted ensembling. Confident instances bypass exploration entirely, keeping average overhead at approximately $2.8\times$ base model cost with worst-case latency unchanged.Experiments on four datasets with three backbone architectures demonstrate consistent, statistically significant gains over all training-phase baselines. A seven-day online A/B test further confirms a 5.3% relative CTR gain ($p < 0.01$), establishing selective test-time compute allocation as a practical complement to training-phase advances for CTR prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UTTSI, a training-free and model-agnostic framework for selective test-time compute scaling in CTR prediction. It uses a dual-signal estimator (model logit confidence combined with a data-level frequency prior) to distinguish epistemic uncertainty from aleatoric ambiguity, applies adaptive feature filtering to all instances, and triggers stochastic feature-path exploration plus consistency-weighted ensembling only for uncertain instances. Experiments on four datasets with three backbone architectures report consistent statistically significant gains over training-phase baselines, and a seven-day online A/B test shows a 5.3% relative CTR lift (p < 0.01) at approximately 2.8× average overhead with unchanged worst-case latency.
Significance. If the selective triggering mechanism proves reliable, the work would establish a practical complement to training-phase advances for industrial CTR systems by allocating extra inference compute only where it is beneficial, without requiring retraining or model changes.
major comments (3)
- [Abstract] Abstract: The central claim that selective uncertainty-triggered exploration produces the reported gains depends on the dual-signal estimator correctly separating cases where exploration is beneficial. No ablations are described that isolate this component (e.g., uncertainty trigger versus random selection at matched exploration budget, or versus single-signal variants), so it remains possible that any additional compute on a subset of instances would yield similar improvements.
- [Abstract] Abstract: The manuscript states that predictions are aggregated via consistency-weighted ensembling and that average overhead is kept at ~2.8× base cost, yet provides no implementation details, pseudocode, or validation of the weighting scheme or overhead calculation. This information is required to assess reproducibility and whether the claimed latency properties hold.
- [Abstract] Abstract: Statistically significant gains are reported on four datasets, but the text supplies no information on error bars, number of runs, variance across random seeds, or the precise statistical test and multiple-comparison correction used for the offline and online results.
minor comments (1)
- [Abstract] The abstract refers to 'adaptive feature filtering' and 'stochastic feature-path explorations' without defining the precise filtering criterion or the distribution from which paths are sampled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the abstract and relevant sections to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that selective uncertainty-triggered exploration produces the reported gains depends on the dual-signal estimator correctly separating cases where exploration is beneficial. No ablations are described that isolate this component (e.g., uncertainty trigger versus random selection at matched exploration budget, or versus single-signal variants), so it remains possible that any additional compute on a subset of instances would yield similar improvements.
Authors: We agree that isolating the contribution of the dual-signal estimator is important for validating the central claim. The full manuscript includes comparisons against training-phase baselines, but does not contain the exact ablations requested (random triggering at matched budget and single-signal variants). We will add these ablations in a new subsection of the experiments and update the abstract to reference the results, which show that the dual-signal approach outperforms both alternatives. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that predictions are aggregated via consistency-weighted ensembling and that average overhead is kept at ~2.8× base cost, yet provides no implementation details, pseudocode, or validation of the weighting scheme or overhead calculation. This information is required to assess reproducibility and whether the claimed latency properties hold.
Authors: The full manuscript provides pseudocode for the ensembling procedure in Algorithm 1 (Section 3.3) and details the overhead calculation in Section 4.2, including per-component latency measurements. However, the abstract itself contains no such details. We will expand the abstract with a concise description of the weighting scheme and overhead validation, and ensure all implementation details remain clearly referenced. revision: yes
-
Referee: [Abstract] Abstract: Statistically significant gains are reported on four datasets, but the text supplies no information on error bars, number of runs, variance across random seeds, or the precise statistical test and multiple-comparison correction used for the offline and online results.
Authors: We acknowledge that the abstract omits these statistical details. The full manuscript reports results with standard deviations across 5 random seeds in Table 2 and uses paired t-tests with Bonferroni correction for the offline experiments (Section 4.1); the online A/B test uses a two-proportion z-test. We will add a brief statement on the number of runs, variance, and tests to the abstract, along with a pointer to the full statistical methodology. revision: yes
Circularity Check
No circularity; training-free empirical framework with independent experimental validation
full rationale
The paper introduces UTTSI as a training-free, model-agnostic method using a dual-signal estimator (logit confidence + frequency prior) for selective feature-path exploration. No equations, fitted parameters, or self-citations are shown that would make the reported gains or the estimator's triggering behavior reduce to the inputs by construction. Experiments on four datasets, three backbones, and a seven-day online A/B test are presented as separate empirical evidence rather than derived predictions. The derivation chain does not match any of the enumerated circularity patterns and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al
-
[2]
In12th USENIX symposium on operating systems design and implementation (OSDI 16)
Tensorflow: A system for large-scale machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16)
-
[3]
Surat Teerapittayanon, Bradley McDanel, and H. T. Kung. 2016. BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks. InProceedings of the 23rd International Conference on Pattern Recognition (ICPR). 2464–2469
2016
-
[4]
Bo Chen, Yichao Wang, Zhirong Liu, Ruiming Tang, Wei Guo, Hongkun Zheng, Weiwei Yao, Muyu Zhang, Xiuqiang He. 2021. Enhancing Explicit and Implicit Feature Interactions via Information Sharing for Parallel Deep CTR Models. InProceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM). (Nov. 2021), 3757-3766
2021
-
[5]
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. 2024. AlphaMath Almost Zero: Process Supervision without Process. InProceedings of the Advances in Neu- ral Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NIPS). (Dec. 2024)
2024
-
[6]
Jianxin Chang, Chenbin Zhang, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). (Aug. 2023), 3795-3804
2023
-
[7]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[8]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys)
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys). (Sep. 2016), 7-10
2016
-
[10]
Yizhou Dang, Yuting Liu, Enneng Yang, Minhan Huang, Guibing Guo, Jianzhe Zhao, and Xingwei Wang. 2025. Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). (Jul. 2025), 1466-1475
2025
-
[11]
Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. 2024. AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training. InProceedings of the 41st International Conference on Machine Learning (ICML). (Jul. 2024)
2024
-
[12]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. Deepfm: a factorization-machine based neural network for ctr prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). Melbourne, Australia., 2782–2788
2017
-
[13]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[14]
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
-
[15]
InProceedings of the 41st International Conference on Machine Learning (ICML)
On the Embedding Collapse when Scaling up Recommendation Models. InProceedings of the 41st International Conference on Machine Learning (ICML). 2024
2024
-
[16]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics. 249–256
2010
-
[17]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, Yueming Han, Menglei Zhou, Lei Yu, Chuan Liu, and Wei Lin. 2025. MTGR: Industrial-Scale Generative Recom- mendation Framework in Meituan.arXiv preprint arXiv:2502.18965(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining fea- ture importance and bilinear feature interaction for click-through rate prediction. InProceedings of ACM Conference on Recommender Systems (RecSys). 169–177
2019
-
[19]
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. 2023. How to index item ids for recommendation foundation models. InProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 195–204
2023
-
[20]
Pengyue Jia, Yejing Wang, Zhaocheng Du, Xiangyu Zhao, Yichao Wang, Bo Chen, Wanyu Wang, Huifeng Guo, and Ruiming Tang. 2024. ERASE: Benchmarking Feature Selection Methods for Deep Recommender Systems. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). (Aug. 2024), 5194-5205
2024
-
[21]
Muthukrishnan
Graham Cormode and S. Muthukrishnan. 2005. An Improved Data Stream Sum- mary: The Count-Min Sketch and its Applications.Journal of Algorithms. 55, 1 (2005), 58–75
2005
-
[22]
Kaggle. 2014. Criteo Display Advertising Challenge. https://www.kaggle.com/c/criteo-display-ad-challenge
2014
-
[23]
Kaggle. 2015. Avazu Click-Through Rate Prediction. https://www.kaggle.com/c/avazu-ctr-prediction
2015
- [24]
-
[25]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. In ICLR
2015
-
[26]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra
-
[27]
InPro- ceedings of the Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems (NIPS)
Solving Quantitative Reasoning Problems with Language Models. InPro- ceedings of the Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems (NIPS). (Nov. 2022)
2022
-
[28]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let’s Verify Step by Step. InProceedings of the 12th International Conference on Learning Representations (ICLR). (May. 2024)
2024
-
[29]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature In- teractions for Recommender Systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). (Aug. 2018), 1754-1763
2018
-
[30]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). London, UK, 1930–1939
2018
-
[31]
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, and Jie Jiang. 2024. Ads Recommendation in a Collapsed and Entangled World. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). (Aug. 2024), 5566-5577
2024
-
[32]
Steffen Rendle. 2010. Factorization Machines. InProceedings of the 10th IEEE International Conference on Data Mining (ICDM). (Dec. 2020), 995-1000
2010
-
[33]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[34]
InAdvances in Neural Information Processing Systems 36 (2023), 10299–10315
Recommender systems with generative retrieval. InAdvances in Neural Information Processing Systems 36 (2023), 10299–10315
2023
-
[35]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri...
2024
-
[36]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. InProceedings of the 10th international conference on World Wide Web. 285–295
2001
-
[37]
Qingquan Song, Dehua Cheng, Hanning Zhou, Jiyan Yang, Yuandong Tian, and Xia Hu. 2020. Towards Automated Neural Interaction Discovery for Click- Through Rate Prediction. InProceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (KDD). 945–955
2020
-
[38]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. AutoInt: Automatic Feature Interaction Learning via SelfAt- tentive Neural Networks. InProceedings of the 28th ACM International Conference Woodstock ’18, June 03–05, 2018, Woodstock, NY Moyu Zhang, Yun Chen, Yujun Jin, Jinxin Hu, Yu Zhang, and Xiaoyi Zeng on ...
2019
-
[39]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Gemini 1.5: 2024
Gemini Team. Gemini 1.5: 2024. Unlocking Multimodal Understanding Across Millions of Tokens of Context
2024
-
[41]
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. InFourteenth ACM Conference on Recommender Systems. 269– 278
2020
-
[42]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. 2024. Idgenrec: Llm-recsys alignment with textual id learning. InProceed- ings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 355–364
2024
-
[43]
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, and Dong Yu. 2024. Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing. InProceedings of the Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NIPS). (Dec. 2024)
2024
-
[44]
Fangye Wang, Hansu Gu, Dongsheng Li, Tun Lu, Peng Zhang, and Ning Gu. 2023. Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM). (Oct. 2023), 2523-2533
2023
-
[45]
Fangye Wang, Yingxu Wang, Dongsheng Li, Hansu Gu, Tun Lu, Peng Zhang, and Ning Gu. 2022. Enhancing CTR Prediction with Context-Aware Feature Representation Learning. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). (Jul. 2022), 343-352
2022
-
[46]
Hong Wen, Jing Zhang, Fuyu Lv, Wentian Bao, Tianyi Wang, and Zulong Chen
-
[47]
InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
Hierarchically Modeling Micro and Macro Behaviors via Multi-Task Learn- ing for Conversion Rate Prediction. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
-
[48]
Hong Wen, Jing Zhang, Yuan Wang, Fuyu Lv, Wentian Bao, Quan Lin, and Keping Yang. 2020. Entire space multi-task modeling via post-click behavior decom- position for conversion rate prediction. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 2377–2386
2020
-
[49]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. (Aug. 2017), 12:1-12:7
2017
-
[50]
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H. Chi. 2021. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. InProceedings of the 30th Web Conference (WWW). (Apr. 2021), 1785-1797
2021
-
[51]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, SeeKiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for genera- tive recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM). 2400–2409
2024
-
[52]
Zhiqiang Wang, Qingyun She, Junlin Zhang. 2021. MaskNet: Introducing Feature- Wise Multiplication to CTR Ranking Models by Instance-Guided Mask. InPro- ceedings of DLP-KDD
2021
-
[53]
Mingjia Yin, Junwei Pan, Hao Wang, Ximei Wang, Shangyu Zhang, Jie Jiang, Defu Lian, and Enhong Chen. 2025. From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models. InProceedings of the 42nd International Conference on Machine Learning (ICML). (Jul. 2025)
2025
-
[54]
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. 2023. Scaling Relationship on Learning Math- ematical Reasoning with Large Language Models.arxiv preprint arXiv:2308.01825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
-
[56]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. 2022. STaR: Boot- strapping Reasoning With Reasoning. InAdvances in Neural Information Pro- cessing Systems 35: Annual Conference on Neural Information Processing Systems (NIPS). (Nov. 2022)
2022
-
[57]
Jing Zhang and Dacheng Tao. 2021. Empowering Things With Intelligence: A Survey of the Progress, Challenges, and Opportunities in Artificial Intelligence of Things.IEEE Internet of Things Journal. 8(10), 7789–7817
2021
-
[58]
Moyu Zhang, Yongxiang Tang, Jinxin Hu, and Yu Zhang. 2024. Scenario-Adaptive Fine-Grained Personalization Network: Tailoring User Behavior Representation to the Scenario Context. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). (Jul. 2024), 1557-1566
2024
-
[59]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InProceedings of the 41st International Conference on Machine Learning (ICML). (Jul. 2024)
2024
-
[60]
Kexin Zhang, Fuyuan Lyu, Xing Tang, Dugang Liu, Chen Ma, Kaize Ding, Xi- uqiang He, and Xue Liu. 2025. Fusion Matters: Learning Fusion in Deep Click- through Rate Prediction Models. InProceedings of the Eighteenth ACM Interna- tional Conference on Web Search and Data Mining (WSDM). (Mar. 2025), 744-753
2025
-
[61]
Weinan Zhang, Jiarui Qin, Wei Guo, Ruiming Tang, and Xiuqiang He. 2021. Deep Learning for Click-Through Rate Estimation. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI). (Aug. 2021), 4695- 4703
2021
-
[62]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). 1059–1068
2018
-
[63]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, Huizhi Yang, Zheng Chai, Zhe Chen, Yuchao Zheng, Qiwei Chen, Feng Zhang, Xun Zhou, Peng Xu, Xiao Yang, Di Wu, Zuotao Liu. 2025. RankMixer: Scaling Up Ranking Models in Industrial Recommenders.arXiv preprint arXiv:2507.15551(2025)
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.