Learning from Semantic Dictionaries: Discriminative Codebook Contrastive Learning for Unified Visual Representation and Generation
Pith reviewed 2026-06-30 12:25 UTC · model grok-4.3
The pith
LEASE unifies visual representation and generation by training a single encoder on semantic codebooks in a precomputed discrete token space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
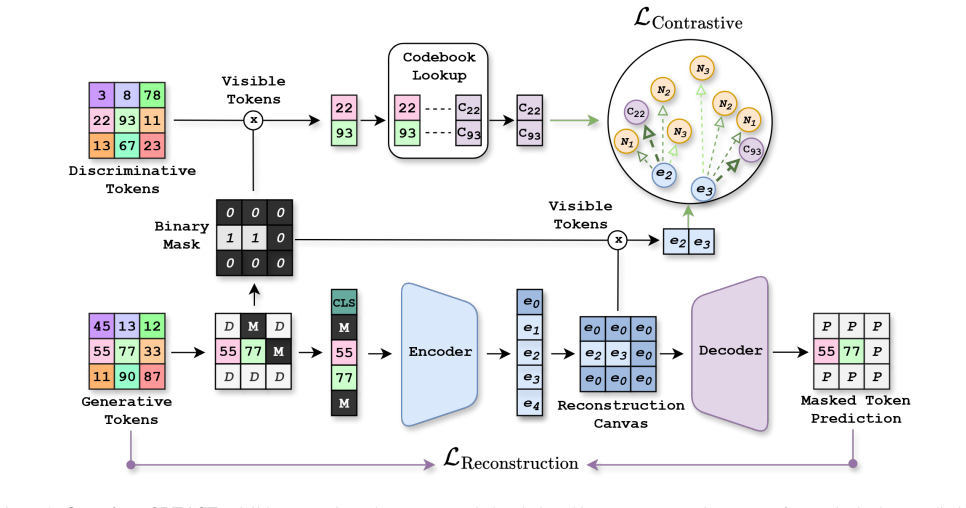
LEASE shows that a one-time precomputed paired codebook plus the combination of masked reconstruction loss and adaptive codebook contrast loss yields a single latent space that supports both unconditional generation and representation learning at state-of-the-art unified performance levels on ImageNet-1K.
What carries the argument
Paired generative-discriminative codebook with masked token reconstruction and codebook contrast losses operating in a fixed discrete token space.
If this is right
- Linear probing accuracy improves by up to 1.7 percent over prior VQGAN-based unified models.
- Unconditional generation reaches lower FID and higher IS than MAGE.
- Few-shot and transfer performance rise by roughly 0.5 to 0.75 percent on average.
- Robustness benchmarks improve by 4-6 percent on average over the same baselines.
- The same unsupervised encoder can be extended to conditional generation while remaining competitive with specialized models.
Where Pith is reading between the lines
- The fixed codebook may allow training on smaller compute budgets than methods that require online tokenization or heavy augmentations.
- Because the token space is precomputed once, the approach could be applied to new domains by swapping only the codebook construction step.
- The separation of generative and discriminative codebooks suggests a route to test whether further specialization of the two dictionaries would increase the performance gap.
- Success on ImageNet raises the question of whether the same dual-objective recipe scales to video or 3-D data without architectural changes.
Load-bearing premise
A single precomputed discrete token space plus the two losses is sufficient to produce a latent representation that is simultaneously good for generation and discrimination without further supervision.
What would settle it
A replication on ImageNet-1K in which the LEASE model fails to exceed MAGE or Sorcen on both linear-probing accuracy and unconditional FID simultaneously.
Figures

read the original abstract
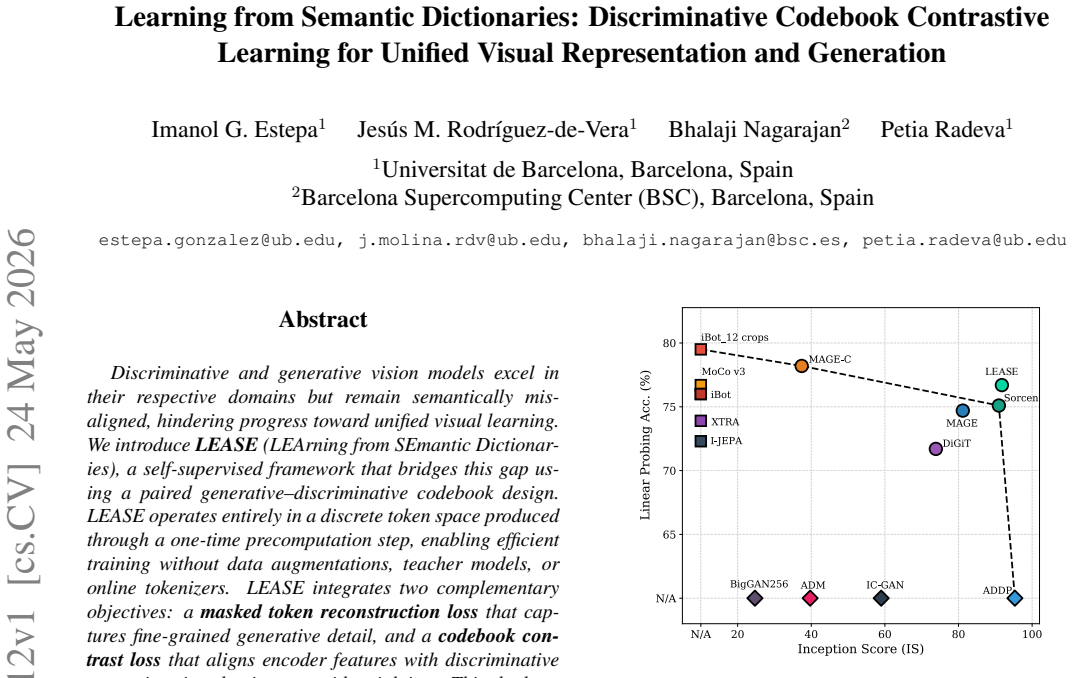
Discriminative and generative vision models excel in their respective domains but remain semantically misaligned, hindering progress toward unified visual learning. We introduce LEASE (LEArning from SEmantic Dictionaries), a self-supervised framework that bridges this gap using a paired generative-discriminative codebook design. LEASE operates entirely in a discrete token space produced through a one-time precomputation step, enabling efficient training without data augmentations, teacher models, or online tokenizers. LEASE integrates two complementary objectives: a masked token reconstruction loss that captures fine-grained generative detail, and a codebook contrast loss that aligns encoder features with discriminative semantics via adaptive centroid weighting. This dual supervision yields a unified latent space that supports both high-quality generation and strong representation learning. On ImageNet-1K, LEASE achieves state-of-the-art unified performance, outperforming prior VQGAN-based methods such as MAGE and Sorcen across linear probing (up to +1.7%), unconditional generation (-1.26 FID and +10.19 IS w.r.t MAGE), few-shot learning (+0.56% on average against Sorcen), transfer (+0.75% average improvement against MAGE and Sorcen), and robustness benchmarks (+5.86% and +4.25% average improvement against MAGE and Sorcen, respectively). It also competes favorably with domain-specialized contrastive and generative models while surpassing previous MIM methods. The unsupervised LEASE model can also be extended to conditional generation by building upon its learned representations, proving competitive with specialized baselines. Overall, LEASE provides an efficient and effective step toward general-purpose vision models that jointly understand and generate visual content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEASE, a self-supervised framework for unified visual representation and generation. It relies on a one-time precomputed discrete token space from a VQGAN-style codebook, trained with two objectives: masked token reconstruction for generative detail and codebook contrast loss with adaptive centroid weighting for discriminative alignment. The central claim is that this produces a single latent space supporting both high-quality generation and strong representation learning without data augmentations or teacher models. On ImageNet-1K, it reports SOTA unified results outperforming VQGAN-based baselines (MAGE, Sorcen) on linear probing (+1.7%), unconditional generation (-1.26 FID, +10.19 IS vs MAGE), few-shot (+0.56% avg vs Sorcen), transfer (+0.75% avg), and robustness (+5.86% and +4.25% avg), while competing with specialized models and extending to conditional generation.
Significance. If verified, the result would be significant for efficient unification of generative and discriminative vision models. The approach's avoidance of augmentations, teachers, and online tokenizers, combined with multi-task evaluation on standard ImageNet-1K benchmarks (probing, generation metrics, few-shot, transfer, robustness), provides a concrete step toward general-purpose models. The extension to conditional generation from the learned representations is a noted strength.
major comments (2)
- [Method and Experiments] The central claim that the dual objectives produce a unified latent space (abstract) rests on the necessity of the codebook contrast loss; however, no ablation isolates its contribution by removing the contrast term while retaining masked reconstruction on the fixed precomputed codebook. This is load-bearing for the reported margins (+1.7% linear probing, robustness gains) because the precomputation step alone may already encode sufficient semantics, leaving open whether the contrast objective is required or marginal.
- [Experiments] §4 (Experiments): the SOTA claims vs MAGE and Sorcen are presented without error bars, multiple runs, or statistical significance tests on the key metrics (FID, IS, linear probing accuracy); this weakens the ability to confirm the unification benefit is robust rather than run-specific.
minor comments (1)
- [Abstract/Method] The abstract and method description could more explicitly define the adaptive centroid weighting mechanism and its relation to the codebook contrast loss equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that the dual objectives produce a unified latent space (abstract) rests on the necessity of the codebook contrast loss; however, no ablation isolates its contribution by removing the contrast term while retaining masked reconstruction on the fixed precomputed codebook. This is load-bearing for the reported margins (+1.7% linear probing, robustness gains) because the precomputation step alone may already encode sufficient semantics, leaving open whether the contrast objective is required or marginal.
Authors: We agree that an explicit ablation isolating the codebook contrast loss (while retaining masked reconstruction on the fixed precomputed codebook) is required to substantiate its contribution to the unified latent space and the reported gains. In the revised manuscript we will add this ablation, training the contrast-ablated variant and reporting its linear probing accuracy, robustness metrics, and generation performance relative to the full LEASE model. revision: yes
-
Referee: [Experiments] §4 (Experiments): the SOTA claims vs MAGE and Sorcen are presented without error bars, multiple runs, or statistical significance tests on the key metrics (FID, IS, linear probing accuracy); this weakens the ability to confirm the unification benefit is robust rather than run-specific.
Authors: We concur that variability measures would strengthen confidence in the SOTA margins. In the revision we will rerun the primary evaluation protocols (linear probing, unconditional generation FID/IS) over multiple random seeds, report means with standard deviations, and include statistical significance tests against the MAGE and Sorcen baselines. revision: yes
Circularity Check
No circularity; derivation self-contained against external benchmarks
full rationale
The paper's central claims rest on a one-time precomputed VQGAN-style codebook plus dual masked-reconstruction and codebook-contrast objectives, with all reported gains (linear probing, FID/IS, few-shot, transfer, robustness) measured against external baselines such as MAGE and Sorcen on ImageNet-1K. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes are present in the supplied text that would reduce any result to its own inputs by construction. The method description treats the codebook as an independent preprocessing step and evaluates unification via standard external metrics, satisfying the criteria for a non-circular, self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sample- and Parameter-Efficient Auto-Regressive Image Models, 2024
Elad Amrani, Leonid Karlinsky, and Alex Bronstein. Sample- and Parameter-Efficient Auto-Regressive Image Models, 2024. arXiv:2411.15648 [cs]. 3
-
[2]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-Supervised Learning from Im- ages with a Joint-Embedding Predictive Architecture, 2023. arXiv:2301.08243 [cs]. 3
-
[3]
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, and Boris Katz. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2019. 7
2019
-
[4]
Large Scale GAN Training for High Fidelity Natural Image Syn- thesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Syn- thesis. 2018. 1, 3
2018
-
[5]
Deep Clustering for Unsupervised Learn- ing of Visual Features
Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep Clustering for Unsupervised Learn- ing of Visual Features. pages 132–149, 2018. 2
2018
-
[6]
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing Properties in Self-Supervised Vision Transformers, 2021. arXiv:2104.14294 [cs]. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Instance- conditioned gan.Advances in Neural Information Process- ing Systems, 34:27517–27529, 2021
Arantxa Casanova, Marlene Careil, Jakob Verbeek, Michal Drozdzal, and Adriana Romero Soriano. Instance- conditioned gan.Advances in Neural Information Process- ing Systems, 34:27517–27529, 2021. 3
2021
-
[8]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. MaskGIT: Masked Generative Image Transformer. pages 11315–11325, 2022. 3, 5, i
2022
-
[9]
A Simple Framework for Contrastive Learn- ing of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A Simple Framework for Contrastive Learn- ing of Visual Representations. InProceedings of the 37th In- ternational Conference on Machine Learning, pages 1597–
-
[10]
ISSN: 2640-3498
PMLR, 2020. ISSN: 2640-3498. 2
2020
-
[11]
An Empiri- cal Study of Training Self-Supervised Vision Transformers
Xinlei Chen, Saining Xie, and Kaiming He. An Empiri- cal Study of Training Self-Supervised Vision Transformers. pages 9640–9649, 2021. 3
2021
-
[12]
Context Autoencoder for Self- supervised Representation Learning.International Journal of Computer Vision, 132(1):208–223, 2024
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context Autoencoder for Self- supervised Representation Learning.International Journal of Computer Vision, 132(1):208–223, 2024. 3
2024
-
[13]
Deconstructing Denoising Diffusion Models for Self- Supervised Learning.CoRR, 2024
Xinlei Chen, Zhuang Liu, Saining Xie, and Kaiming He. Deconstructing Denoising Diffusion Models for Self- Supervised Learning.CoRR, 2024. 1, 3
2024
-
[14]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. 6
2014
-
[15]
FlashAttention-2: Faster Attention with Better Par- allelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster Attention with Better Par- allelism and Work Partitioning. 2023. 7
2023
-
[16]
ImageNet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical im- age database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. ISSN: 1063-
2009
-
[17]
Large Scale Adversarial Representation Learning
Jeff Donahue and Karen Simonyan. Large Scale Adversarial Representation Learning. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2019. 3
2019
-
[18]
With a Little Help From My Friends: Nearest-Neighbor Contrastive Learning of Vi- sual Representations
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. With a Little Help From My Friends: Nearest-Neighbor Contrastive Learning of Vi- sual Representations. pages 9588–9597, 2021. 3
2021
-
[19]
Taming Transformers for High-Resolution Image Synthesis, 2021
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Taming Transformers for High-Resolution Image Synthesis, 2021. arXiv:2012.09841 [cs]. 1, 2, 3, 5, 6
-
[20]
Estepa, Ignacio Sarasua, Bhalaji Nagarajan, and Petia Radeva
Imanol G. Estepa, Ignacio Sarasua, Bhalaji Nagarajan, and Petia Radeva. All4One: Symbiotic Neighbour Contrastive Learning via Self-Attention and Redundancy Reduction. pages 16243–16253, 2023. 3, i
2023
-
[21]
Imanol G. Estepa, Jes ´us M. Rodr ´ıguez-de Vera, Ignacio Saras´ua, Bhalaji Nagarajan, and Petia Radeva. Conjur- ing Positive Pairs for Efficient Unification of Representation Learning and Image Synthesis, 2025. arXiv:2503.15060 [cs]. 2, 3, 4, 6, 7, i, iii, iv
-
[22]
Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories. Computer Vision and Image Understanding, 106(1):59–70,
-
[23]
Bootstrap Your Own Latent - A New Ap- proach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap Your Own Latent - A New Ap- proach to Self-Supervised Learning. InAdvances in Neural Information Proce...
2020
-
[24]
Masked Autoencoders Are Scal- able Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked Autoencoders Are Scal- able Vision Learners. pages 16000–16009, 2022. 1, 3, 5, i
2022
-
[25]
Benchmarking Neu- ral Network Robustness to Common Corruptions and Pertur- bations
Dan Hendrycks and Thomas Dietterich. Benchmarking Neu- ral Network Robustness to Common Corruptions and Pertur- bations. 2018. 7
2018
-
[26]
The Many Faces of Robustness: A Crit- ical Analysis of Out-of-Distribution Generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kada- vath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, and Justin Gilmer. The Many Faces of Robustness: A Crit- ical Analysis of Out-of-Distribution Generalization. pages 8340–8349, 2021
2021
-
[27]
Natural Adversarial Examples, 2021
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Stein- hardt, and Dawn Song. Natural Adversarial Examples, 2021. arXiv:1907.07174 [cs]. 7
-
[28]
Contrastive Masked Autoencoders are Stronger Vi- sion Learners.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2506–2517, 2024
Zhicheng Huang, Xiaojie Jin, Chengze Lu, Qibin Hou, Ming-Ming Cheng, Dongmei Fu, Xiaohui Shen, and Jiashi Feng. Contrastive Masked Autoencoders are Stronger Vi- sion Learners.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2506–2517, 2024. Conference Name: IEEE Transactions on Pattern Analysis and Machine Intelligence. 3, i
2024
-
[29]
Mean Shift for Self-Supervised Learn- ing
Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. Mean Shift for Self-Supervised Learn- ing. pages 10326–10335, 2021. 3, i
2021
-
[30]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. 6
2009
-
[31]
SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vi- sion Experts and Token Folding
Hao Li, Changyao Tian, Jie Shao, Xizhou Zhu, Zhaokai Wang, Jinguo Zhu, Wenhan Dou, Xiaogang Wang, Hong- sheng Li, Lewei Lu, and Jifeng Dai. SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vi- sion Experts and Token Folding. 4
-
[32]
Siyuan Li, Di Wu, Fang Wu, Zelin Zang, and Stan Z. Li. Architecture-Agnostic Masked Image Modeling – From ViT back to CNN. InProceedings of the 40th International Con- ference on Machine Learning, pages 20149–20167. PMLR,
-
[33]
Siyuan Li, Luyuan Zhang, Zedong Wang, Juanxi Tian, Cheng Tan, Zicheng Liu, Chang Yu, Qingsong Xie, Hao- nan Lu, Haoqian Wang, and Zhen Lei. MergeVQ: A Uni- fied Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization, 2025. arXiv:2504.00999 [cs]. 1, 2, 4, 7
-
[34]
MAGE: MAsked Gener- ative Encoder To Unify Representation Learning and Image Synthesis
Tianhong Li, Huiwen Chang, Shlok Mishra, Han Zhang, Dina Katabi, and Dilip Krishnan. MAGE: MAsked Gener- ative Encoder To Unify Representation Learning and Image Synthesis. pages 2142–2152, 2023. 1, 2, 3, 4, 5, 6, 7, i, iii, iv
2023
-
[35]
Hao Liu, Xinghua Jiang, Xin Li, Antai Guo, Yiqing Hu, De- qiang Jiang, and Bo Ren. The Devil Is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-training.Proceedings of the AAAI Conference on Artifi- cial Intelligence, 37(2):1649–1656, 2023. 3
2023
-
[36]
UniTok: A Unified Tokenizer for Visual Generation and Understanding,
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. UniTok: A Unified Tokenizer for Visual Generation and Understanding,
- [37]
-
[38]
Do text-free diffusion models learn discriminative visual repre- sentations?, 2023
Soumik Mukhopadhyay, Matthew Gwilliam, Yosuke Yam- aguchi, Vatsal Agarwal, Namitha Padmanabhan, Archana Swaminathan, Tianyi Zhou, and Abhinav Shrivastava. Do text-free diffusion models learn discriminative visual repre- sentations?, 2023. arXiv:2311.17921 [cs]. 1, 3
-
[39]
Asano, Nanne van Noord, Marcel Worring, and Cees G
Ivona Najdenkoska, Mohammad Mahdi Derakhshani, Yuki M. Asano, Nanne van Noord, Marcel Worring, and Cees G. M. Snoek. TULIP: Token-length Upgraded CLIP,
- [40]
-
[41]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Represen- tation Learning with Contrastive Predictive Coding, 2019. arXiv:1807.03748 [cs]. 3
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable Diffusion Models with Transformers. pages 4195–4205, 2023. 3
2023
-
[44]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021....
2021
-
[45]
Do ImageNet Classifiers Generalize to ImageNet? 2021
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do ImageNet Classifiers Generalize to ImageNet? 2021. 7
2021
-
[46]
High-Resolution Image Synthesis With Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-Resolution Image Synthesis With Latent Diffusion Models. pages 10684– 10695, 2022. 1
2022
-
[47]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301,
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Ji- wen Lu. Latent Diffusion Model without Variational Au- toencoder, 2025. arXiv:2510.15301 [cs]. 4, 7
-
[48]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Fed- erico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khali- dov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamon- jisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Co...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Ucf101: A dataset of 101 human actions classes from videos in the wild, 2012
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild, 2012. 6
2012
-
[50]
Changyao Tian, Chenxin Tao, Jifeng Dai, Hao Li, Ziheng Li, Lewei Lu, Xiaogang Wang, Hongsheng Li, Gao Huang, and Xizhou Zhu. ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denois- ing Diffusion Process, 2024. arXiv:2306.05423 [cs]. 1, 3, 6, iv
-
[51]
Attention is All you Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. InAdvances in Neu- ral Information Processing Systems. Curran Associates, Inc.,
-
[52]
Shashanka Venkataramanan, Valentinos Pariza, Moham- madreza Salehi, Lukas Knobel, Spyros Gidaris, Elias Ramzi, Andrei Bursuc, and Yuki M. Asano. Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning, 2025. arXiv:2507.14137 [cs]. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Learning Robust Global Representations by Penal- izing Local Predictive Power
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning Robust Global Representations by Penal- izing Local Predictive Power. InAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2019. 7
2019
-
[54]
Denoising Diffusion Autoencoders are Unified Self- supervised Learners, 2023
Weilai Xiang, Hongyu Yang, Di Huang, and Yunhong Wang. Denoising Diffusion Autoencoders are Unified Self- supervised Learners, 2023. arXiv:2303.09769 [cs]. 1
-
[55]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE Computer So- ciety Conference on Computer Vision and Pattern Recogni- tion, pages 3485–3492, 2010. 6
2010
-
[56]
SimMIM: a Simple Framework for Masked Image Modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. SimMIM: a Simple Framework for Masked Image Modeling. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9643–9653, New Orleans, LA, USA, 2022. IEEE. 1, 3
2022
-
[57]
Vector-quantized Image Modeling with Improved VQGAN
Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized Image Modeling with Improved VQGAN. 2021. 1
2021
-
[58]
Rep- resentation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Rep- resentation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. 2024. 2, 4, 7
2024
-
[59]
How Mask Mat- ters: Towards Theoretical Understandings of Masked Au- toencoders.Advances in Neural Information Processing Sys- tems, 35:27127–27139, 2022
Qi Zhang, Yifei Wang, and Yisen Wang. How Mask Mat- ters: Towards Theoretical Understandings of Masked Au- toencoders.Advances in Neural Information Processing Sys- tems, 35:27127–27139, 2022. 3
2022
-
[60]
Improved Transformer for High-Resolution GANs
Long Zhao, Zizhao Zhang, Ting Chen, Dimitris Metaxas, and Han Zhang. Improved Transformer for High-Resolution GANs. InAdvances in Neural Information Processing Sys- tems, pages 18367–18380. Curran Associates, Inc., 2021. 3
2021
-
[61]
Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation, 2025
Anlin Zheng, Xin Wen, Xuanyang Zhang, Chuofan Ma, Tiancai Wang, Gang Yu, Xiangyu Zhang, and Xiaojuan Qi. Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation, 2025. arXiv:2507.08441 [cs]. 2, 4, 7
-
[62]
Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 40(6):1452–1464, 2018
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 40(6):1452–1464, 2018. 6
2018
-
[63]
iBOT: Image BERT Pre-Training with Online Tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: Image BERT Pre- Training with Online Tokenizer, 2022. arXiv:2111.07832 [cs]. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Stabilize the Latent Space for Image Autore- gressive Modeling: A Unified Perspective, 2024
Yongxin Zhu, Bocheng Li, Hang Zhang, Xin Li, Linli Xu, and Li Bing. Stabilize the Latent Space for Image Autore- gressive Modeling: A Unified Perspective, 2024. 2, 3, 5, 7, iii Learning from Semantic Dictionaries: Discriminative Codebook Contrastive Learning for Unified Visual Representation and Generation Supplementary Material The supplementary material...
-
[65]
As shown in Table E.10, all methods achieve comparable performance on MSCOCO, with Sorcen and LEASE slightly improving over MAGE
caused by the quantized input tokens. As shown in Table E.10, all methods achieve comparable performance on MSCOCO, with Sorcen and LEASE slightly improving over MAGE. On FoodSeg, a more specific dataset, Sorcen stands as the best while LEASE matches the performance obtained by MAGE. MSCOCO FoodSeg MAGE 15.80 15.88 Sorcen 15.90 16.82 LEASE 15.92 15.85 Tab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.