Privacy-Preserving Local Language Models for Longitudinal Data Retrieval in Chronic Dermatologic Disease: Implementation in Pemphigus Patients
Pith reviewed 2026-06-30 11:25 UTC · model grok-4.3
The pith
A locally deployed small language model extracts 56 clinical features from pemphigus patient records at 82 percent accuracy and generates summaries that dermatologists prefer in over half of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
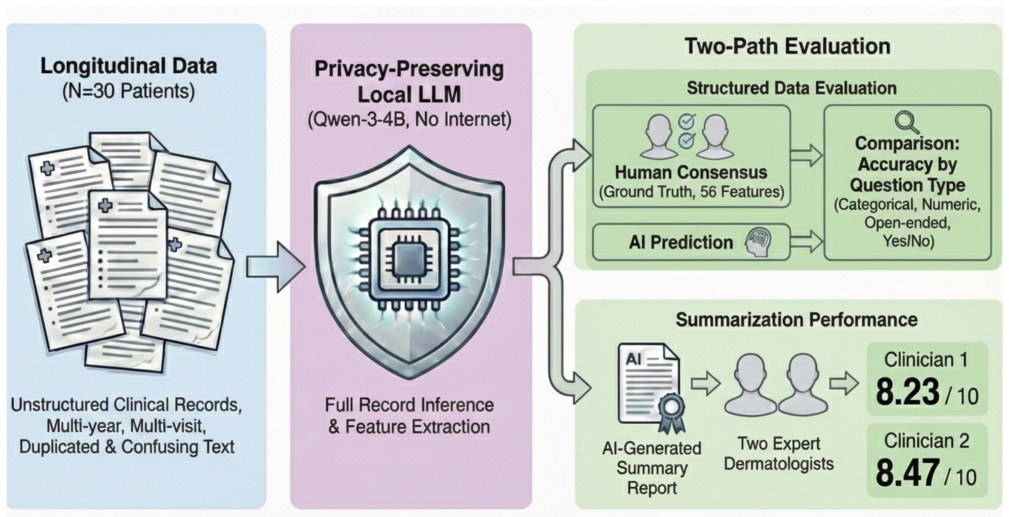
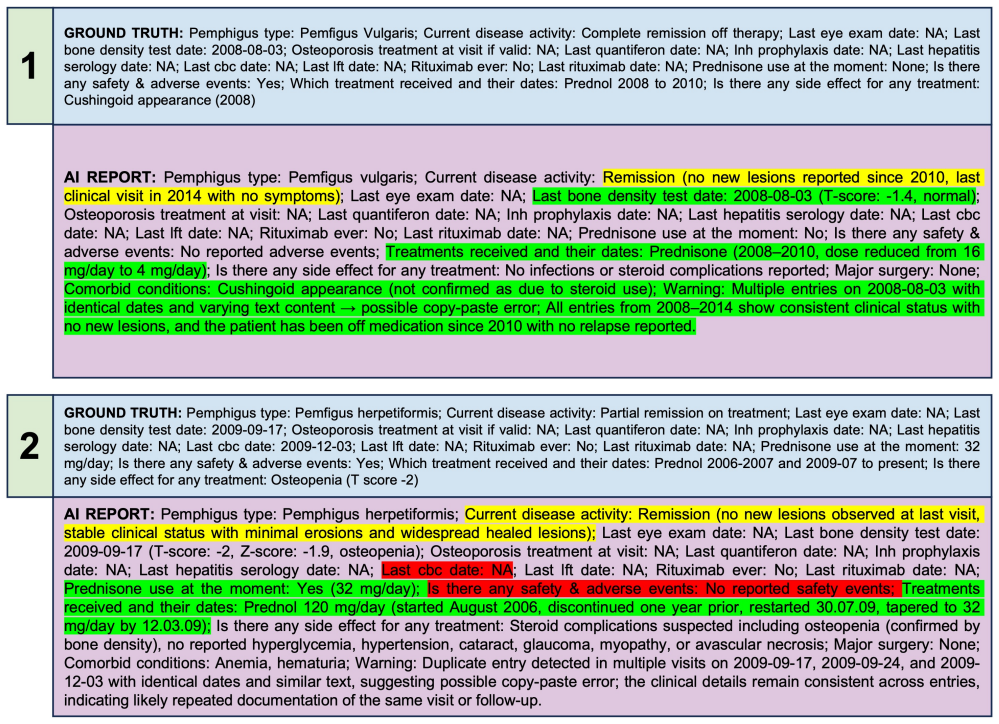
The authors aggregated 541 visit notes from thirty pemphigus patients into full longitudinal records and had two expert dermatologists annotate 56 clinically relevant features. They then prompted the locally deployed Qwen3 4B Thinking 2507 model with each complete record to retrieve the features and generate final report summaries. The model achieved 82.25 percent mean accuracy on the 1680 feature tasks. Dermatologist ratings of the generated summaries averaged 8.23-8.50 across quality, clinical accuracy, and usefulness scales with no significant difference between evaluators, and the AI summaries were preferred in 53.3 percent of evaluations. The authors conclude that privacy-preserving loc
What carries the argument
The locally deployed Qwen3 4B Thinking 2507 small language model prompted with each patient's complete longitudinal record to retrieve 56 annotated features and produce one final summary.
If this is right
- Clinicians could review extensive longitudinal histories more quickly during routine visits.
- The approach reduces the chance of overlooking critical past information in chronic disease management.
- Local deployment keeps all patient data inside the clinic and avoids external transmission.
- The same workflow could be applied to other chronic dermatologic conditions that generate long follow-up records.
- Integration into clinical systems could support decision-making when used with human oversight.
Where Pith is reading between the lines
- The same local-model approach might be tested on records from other chronic conditions such as psoriasis or atopic dermatitis to check generalizability.
- Prospective trials could measure whether access to these summaries changes actual treatment decisions or patient outcomes.
- Fine-tuning the model on dermatology-specific notes could raise feature accuracy above the current 82 percent level.
- Pairing the model with electronic health record interfaces could allow on-the-fly summary generation during visits.
Load-bearing premise
The two dermatologists' annotations of the 56 features count as reliable ground truth, and their quality ratings and preference counts show the model outperforms experts.
What would settle it
A larger study in which additional independent dermatologists re-annotate the same records and rate new model summaries, resulting in accuracy below 70 percent or preference for human notes in most cases, would falsify the central claim.
Figures
read the original abstract
Chronic dermatologic diseases such as pemphigus require long-term follow-up, generating extensive longitudinal clinical documentation that is difficult to review comprehensively during routine visits and increasing clinician workload as well as the risk of missing critical historical information. We evaluated whether a locally deployed, privacy-preserving small language model (SLM) could retrieve structured clinical features and generate longitudinal summaries from long-term dermatology follow-up records. In this retrospective case series, thirty pemphigus patients contributed 541 visit notes that were aggregated into full longitudinal records (89,336 words); 56 clinically relevant features were annotated by two expert dermatologists. The locally deployed SLM (Qwen3 4B Thinking 2507) was queried with each complete record to retrieve 56 features and generate one final report summaries. Across 1,680 feature retrieval tasks, mean accuracy was 82.25%. Dermatologists' ratings of AI-generated summaries were high for overall quality (8.23-8.47), clinical accuracy (7.93-8.20), and usefulness (8.47-8.50), with no significant inter-evaluator differences and an overall preference for AI summaries in 53.3% of evaluations. These findings suggest that privacy-preserving, locally deployed SLMs can outperform medical experts and reliably generate clinically meaningful longitudinal summaries. SLMs may support clinical decision-making when integrated with appropriate oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates a locally deployed small language model (Qwen3 4B Thinking) on 541 visit notes from 30 pemphigus patients (aggregated to 89,336 words) for retrieving 56 expert-annotated clinical features and generating longitudinal summaries. It reports 82.25% mean accuracy across 1,680 retrieval tasks, high dermatologist Likert ratings (overall quality 8.23-8.47, clinical accuracy 7.93-8.20, usefulness 8.47-8.50), and 53.3% overall preference for the AI summaries, concluding that privacy-preserving local SLMs can outperform medical experts and support clinical decision-making.
Significance. If the evaluation methodology is strengthened to directly test superiority, the work would provide useful evidence on the viability of on-device SLMs for longitudinal record summarization in chronic disease management, with the local deployment approach addressing privacy constraints that limit cloud-based medical AI. The retrospective design with real expert annotations on a focused disease cohort is a positive aspect of the empirical setup.
major comments (2)
- [Abstract] Abstract: the central claim that the findings 'suggest that privacy-preserving, locally deployed SLMs can outperform medical experts' is not supported by the reported results. Feature retrieval accuracy (82.25%) quantifies agreement with the two dermatologists' annotations of the 56 features rather than any direct comparison of model performance against expert-generated outputs. The 53.3% preference rate for AI summaries is presented without a described comparator arm (e.g., no blinded evaluation against summaries written by the same experts) or statistical testing, so the data support approximation and favorable ratings but not outperformance.
- [Results (summary evaluation)] Summary evaluation section: the preference testing reports an overall 53.3% rate favoring AI summaries with high Likert scores but provides no details on how the comparator summaries were generated, who produced them, or whether the preference task was blinded and balanced. Without this, the preference metric cannot substantiate superiority over expert performance.
minor comments (2)
- [Abstract] Abstract: 'one final report summaries' appears to be a grammatical error and should be clarified.
- [Methods] The manuscript does not report inter-rater agreement statistics between the two expert dermatologists on the 56-feature annotations, which would strengthen the reliability of the ground-truth labels used for the 82.25% accuracy calculation.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the careful reading and the identification of areas where our claims and reporting require strengthening. We will make revisions to moderate the language regarding outperformance and to provide additional methodological details on the summary evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the findings 'suggest that privacy-preserving, locally deployed SLMs can outperform medical experts' is not supported by the reported results. Feature retrieval accuracy (82.25%) quantifies agreement with the two dermatologists' annotations of the 56 features rather than any direct comparison of model performance against expert-generated outputs. The 53.3% preference rate for AI summaries is presented without a described comparator arm (e.g., no blinded evaluation against summaries written by the same experts) or statistical testing, so the data support approximation and favorable ratings but not outperformance.
Authors: We concur that the central claim in the abstract regarding outperformance is not substantiated by the results as presented. The accuracy metric reflects agreement with expert annotations, and the preference rate does not include a direct comparison to summaries generated by the annotating experts or statistical analysis. We will revise the abstract to remove this claim and instead emphasize the high agreement and positive ratings received by the AI-generated summaries. revision: yes
-
Referee: [Results (summary evaluation)] Summary evaluation section: the preference testing reports an overall 53.3% rate favoring AI summaries with high Likert scores but provides no details on how the comparator summaries were generated, who produced them, or whether the preference task was blinded and balanced. Without this, the preference metric cannot substantiate superiority over expert performance.
Authors: We acknowledge that the summary evaluation section lacks sufficient detail on the comparator summaries. In the revised manuscript, we will expand this section to fully describe the generation of comparator summaries, the blinding and balancing of the preference task, and report statistical testing for the preference rates to allow proper interpretation of the results. revision: yes
Circularity Check
No circularity; purely empirical evaluation with no derivations or self-referential constructions
full rationale
The manuscript is a retrospective case series reporting empirical metrics (feature retrieval accuracy of 82.25% across 1,680 tasks, Likert-scale quality ratings, and 53.3% preference rate) from direct comparison of SLM outputs against two dermatologists' annotations of 56 features in 541 notes. No equations, parameter fitting, predictive derivations, or self-citations appear in the provided text or abstract. The central claim rests on these external benchmarks rather than any reduction to the study's own inputs by construction. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schmidt, E., Kasperkiewicz, M. & Joly, P. Pemphigus.The Lancet394, 882–894, DOI: 10.1016/S0140-6736(19)31778-7 (2019)
-
[2]
Medicine30, 1134–1142, DOI: 10.1038/s41591-024-02855-5 (2024)
Van Veen, D.et al.Adapted large language models can outperform medical experts in clinical text summarization.Nat. Medicine30, 1134–1142, DOI: 10.1038/s41591-024-02855-5 (2024)
-
[3]
Medicine5, 186, DOI: 10.1038/s41746-022-00730-6 (2022)
Wu, H.et al.A survey on clinical natural language processing in the United Kingdom from 2007 to 2022.npj Digit. Medicine5, 186, DOI: 10.1038/s41746-022-00730-6 (2022)
-
[4]
A Primer on Neural Network Models for Natural Language Processing.J
Goldberg, Y . A Primer on Neural Network Models for Natural Language Processing.J. Artif. Intell. Res.57, 345–420, DOI: 10.1613/jair.4992 (2016)
-
[5]
Paganelli, A.et al.Natural language processing in dermatology: A systematic literature review and state of the art.J. Eur. Acad. Dermatol. V enereol.38, 2225–2234, DOI: 10.1111/jdv.20286 (2024). _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/jdv.20286. 7.Azarfar, G.et al.Responsible adoption of multimodal artificial intelligence in health care: ...
-
[6]
Yilmaz, A.et al.Resource-efficient medical vision language model for dermatology via a synthetic data generation framework, DOI: 10.1101/2025.05.17.25327785 (2025). ISSN: 3067-2007 Pages: 2025.05.17.25327785
-
[7]
Dis.9, ofac471, DOI: 10.1093/ofid/ofac471 (2022)
Goodman-Meza, D.et al.Natural Language Processing and Machine Learning to Identify People Who Inject Drugs in Electronic Health Records.Open F orum Infect. Dis.9, ofac471, DOI: 10.1093/ofid/ofac471 (2022)
-
[8]
Bootsma-Robroeks, C. M. H. H. T.et al.AI-generated draft replies to patient messages: exploring effects of implementation. Front. Digit. Heal.7, DOI: 10.3389/fdgth.2025.1588143 (2025)
-
[9]
S., Yuan, W., Poddar, M., Elsamadisi, P
Marwaha, J. S., Yuan, W., Poddar, M., Elsamadisi, P. & Brat, G. A. The algorithmic consultant: a new era of clinical AI calls for a new workforce of physician-algorithm specialists.npj Digit. Medicine8, 552, DOI: 10.1038/s41746-025-01960-0 (2025)
-
[10]
Wang, J.et al.Systematic Evaluation of Research Progress on Natural Language Processing in Medicine Over the Past 20 Years: Bibliometric Study on PubMed.J. Med. Internet Res.22, e16816, DOI: 10.2196/16816 (2020). Company: Journal of Medical Internet Research Distributor: Journal of Medical Internet Research Institution: Journal of Medical Internet Researc...
-
[11]
Bear Don’t Walk, O. J., Reyes Nieva, H., Lee, S. S.-J. & Elhadad, N. A scoping review of ethics considerations in clinical natural language processing.JAMIA Open5, ooac039, DOI: 10.1093/jamiaopen/ooac039 (2022)
-
[12]
Obika, D.et al.Safety principles for medical summarization using generative AI.Nat. Medicine30, 3417–3419, DOI: 10.1038/s41591-024-03313-y (2024). 15.Yang, A.et al.Qwen3 Technical Report, DOI: 10.48550/arXiv.2505.09388 (2025). ArXiv:2505.09388 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41591-024-03313-y 2024
-
[13]
Dymek, C.et al.Building the evidence-base to reduce electronic health record–related clinician burden.J. Am. Med. Informatics Assoc.28, 1057–1061, DOI: 10.1093/jamia/ocaa238 (2021)
-
[14]
Gandhi, T. K.et al.How can artificial intelligence decrease cognitive and work burden for front line practitioners?JAMIA Open6, ooad079, DOI: 10.1093/jamiaopen/ooad079 (2023)
-
[15]
Center for AI Safetyet al.A benchmark of expert-level academic questions to assess AI capabilities.Nature649, 1139–1146, DOI: 10.1038/s41586-025-09962-4 (2026). 19.Sellergren, A.et al.MedGemma Technical Report, DOI: 10.48550/arXiv.2507.05201 (2025). ArXiv:2507.05201 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09962-4 2026
-
[16]
Shah, S. V . Accuracy, Consistency, and Hallucination of Large Language Models When Analyzing Unstructured Clinical Notes in Electronic Medical Records.JAMA Netw. Open7, e2425953, DOI: 10.1001/jamanetworkopen.2024.25953 (2024)
-
[17]
Du, X.et al.Testing and Evaluation of Generative Large Language Models in Electronic Health Record Applications: A Systematic Review, DOI: 10.1101/2024.08.11.24311828 (2024)
-
[18]
Kim, Y .et al.Medical Hallucinations in Foundation Models and Their Impact on Healthcare, DOI: 10.48550/arXiv.2503. 05777 (2025). ArXiv:2503.05777 [cs]. 9/12 Appendix The main prompt and clinical features with their input type and notes. Each clinical feature were prompted separately. Main Prompt:You are an expert dermatologist tasked with summarizing lon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.