Unbiased Diffusion Variational Inversion via Principled Posterior Matching
Pith reviewed 2026-06-30 12:10 UTC · model grok-4.3
The pith
Integrating Fisher divergence yields an exact, tractable gradient for KL optimization in diffusion variational inversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Principled Posterior Matching (PPM) returns to the fundamentals of variational inference by formulating the exact optimization of the KL divergence via the integration of Fisher divergence. The paper derives a tractable, equivalent gradient form of this integral that enables precise optimization without the biases of prior approximations. The analysis shows that mode collapse in earlier methods follows directly from the approximation gap, and the new formulation unifies mass-covering variational inference with amortized single-step reconstruction while generalizing to a broader family of divergences.
What carries the argument
The integral of the Fisher divergence, which supplies a tractable and unbiased gradient equivalent to exact KL minimization between the inversion distribution and the Bayesian posterior.
If this is right
- Mass-covering divergences improve inversion diversity and uncertainty quantification compared with mode-seeking approximations.
- The same formulation supports training an efficient reconstruction network for single-step inference.
- The integral construction extends directly to other divergence families without changing the overall optimization structure.
- Reconstruction fidelity, multimodal posterior recovery, and calibrated uncertainty all improve on inpainting, fluorescent microscopy, and black-hole imaging tasks.
Where Pith is reading between the lines
- The same Fisher-integral trick could be applied to other generative models that currently rely on approximate score matching for inverse problems.
- If the gradient equivalence holds under distribution shift, PPM could reduce the need for task-specific fine-tuning in scientific imaging pipelines.
- The framework makes uncertainty quantification in diffusion inversion comparable to traditional Bayesian methods, which would allow direct use of the recovered posteriors in downstream scientific inference.
Load-bearing premise
The integration of Fisher divergence produces a gradient that is exactly equivalent to KL optimization and can be implemented without introducing new approximations.
What would settle it
An experiment that measures the KL divergence achieved by PPM versus prior score-based methods on a known multimodal posterior and shows that PPM does not reduce the gap to the true minimum.
Figures
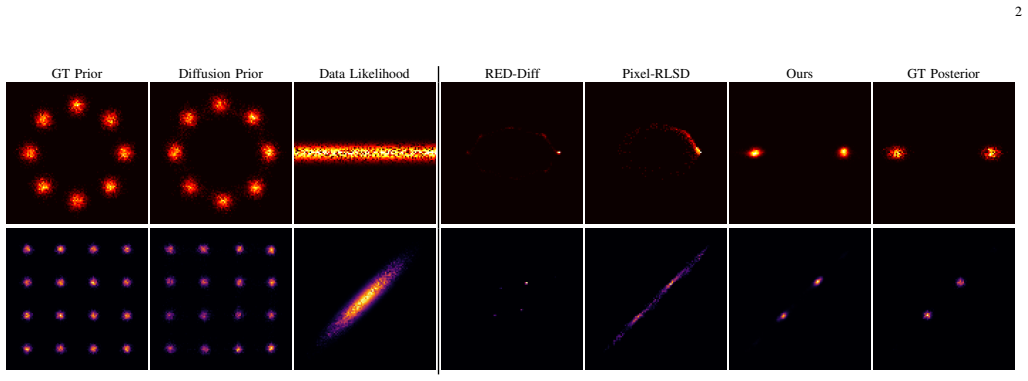
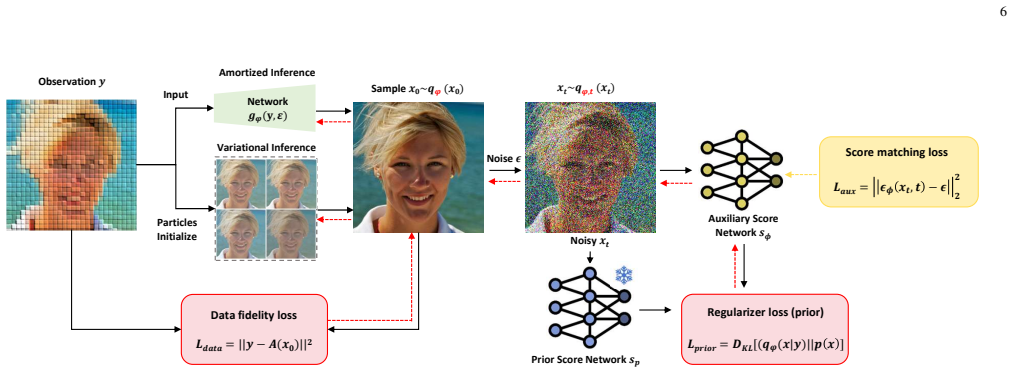



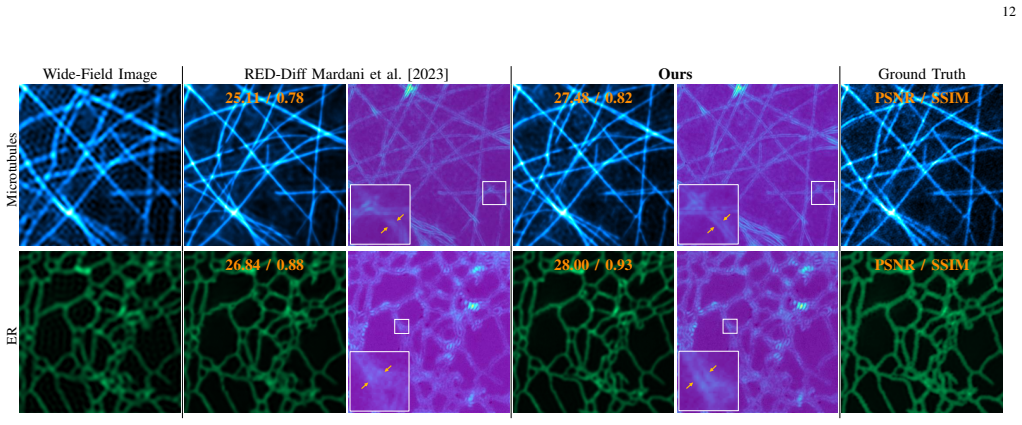

read the original abstract
Existing score-based methods for inverse problems often resort to approximate minimization of the KL divergence between the inversion distribution and the Bayesian posterior. Such an approximation leads to severe mode collapse and unreliable uncertainty quantification. In this paper, we propose Principled Posterior Matching (PPM), a framework that returns to the fundamentals of variational inference, rather than using tricky approximations. Instead of relying on heuristic approximations, we rigorously formulate the exact optimization of the KL divergence via the integration of Fisher divergence. We derive a tractable, equivalent gradient form of this integral, enabling precise optimization without the biases introduced by prior approximations. Our analysis clearly reveals that the mode collapse in previous methods stems directly from this approximation gap. Supported by our theoretical solution, PPM unifies two complementary paradigms: (1) In variational inference, PPM adopts mass-covering divergences that significantly improve the inversion diversity and uncertainty quantification; (2) In amortized inference, it enables the training of an efficient reconstruction network for rapid, single-step reconstruction. Furthermore, our formulation naturally extends to a broader family of divergence measures by generalizing the integral of the Fisher divergence. We validate PPM across challenging computational imaging tasks, including inpainting, super-resolution fluorescent microscopy, and radio interferometric black-hole imaging. In all experiments, PPM achieves superior reconstruction fidelity, faithful multimodal posterior recovery, and well-calibrated uncertainty estimates, establishing a robust framework for scientific imaging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Principled Posterior Matching (PPM) for diffusion-based variational inversion of inverse problems. It claims that prior score-based methods rely on approximate KL minimization, which causes mode collapse and poor uncertainty quantification. PPM instead formulates exact KL optimization between the inversion distribution and Bayesian posterior by integrating the Fisher divergence, derives a tractable equivalent gradient form for this integral, and shows this eliminates approximation biases. The approach unifies mass-covering divergences in variational inference with amortized inference for single-step reconstruction, generalizes to other divergences, and is validated on inpainting, super-resolution fluorescent microscopy, and radio interferometric black-hole imaging tasks, reporting improved fidelity, multimodal posterior recovery, and calibrated uncertainties.
Significance. If the claimed derivation of a tractable, unbiased gradient equivalent to exact KL optimization holds without new approximations, this would constitute a meaningful advance for score-based methods in computational imaging. The explicit link between the approximation gap and mode collapse, combined with the unification of variational and amortized paradigms and the generalization of the Fisher integral, provides a principled alternative to heuristic approaches. The experimental validation across challenging scientific imaging tasks further supports potential utility where faithful uncertainty and diversity are required.
minor comments (2)
- The abstract refers to 'rigorously formulate the exact optimization' and 'derive a tractable, equivalent gradient form'; the full manuscript should ensure these steps are presented with explicit integral definitions and gradient derivations to allow direct verification of equivalence.
- The extension to a 'broader family of divergence measures by generalizing the integral of the Fisher divergence' is mentioned; including the generalized integral form and any conditions for tractability would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for their thorough and positive review, accurate summary of our contributions, and recommendation to accept. The referee correctly identifies the core advance in deriving a tractable gradient for exact KL optimization in diffusion variational inversion.
Circularity Check
No significant circularity
full rationale
The abstract presents the core contribution as a rigorous derivation of an exact, tractable gradient for KL optimization obtained by integrating Fisher divergence, explicitly positioned as free of prior heuristic approximations. No equations, self-citations, or derivation steps are visible that reduce this claimed equivalence to a fitted parameter, a self-referential definition, or an imported uniqueness result. The central claim is therefore treated as self-contained mathematical work rather than a renaming or re-labeling of inputs. This is the default honest outcome when no load-bearing reduction can be exhibited by direct quote.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Integration of Fisher divergence provides a tractable equivalent gradient for exact KL divergence optimization in diffusion models.
Reference graph
Works this paper leans on
-
[1]
Asad Aali, Marius Arvinte, Sidharth Kumar, and Jonathan I Tamir. Solving inverse problems with score-based gen- erative priors learned from noisy data.arXiv preprint arXiv:2305.01166,
-
[2]
Weimin Bai, Yubo Li, Wenzheng Chen, Weijian Luo, and He Sun. Dive3d: Diverse distillation-based text-to-3d generation via score implicit matching.arXiv preprint arXiv:2506.13594, 2025a. Weimin Bai, Yubo Li, Weijian Luo, Wenzheng Chen, and He Sun. Vision-language models as differentiable semantic and spatial rewards for text-to-3d generation.arXiv preprint...
-
[3]
Generative plug and play: Posterior sampling for inverse problems.arXiv preprint arXiv:2306.07233,
Charles A Bouman and Gregery T Buzzard. Generative plug and play: Posterior sampling for inverse problems.arXiv preprint arXiv:2306.07233,
-
[4]
Hanyu Cai, Binqi Shen, Lier Jin, Lan Hu, and Xiaojing Fan. Does tone change the answer? evaluating prompt politeness effects on modern llms: Gpt, gemini, llama.arXiv preprint arXiv:2512.12812,
-
[5]
doi: 10.48550/arXiv.2512.12812. URL https://arxiv.org/abs/2512.12812. Emmanuel Candes and Justin Romberg. Sparsity and inco- herence in compressive sampling.Inverse problems, 23(3): 969,
-
[6]
Monte carlo guided diffusion for bayesian linear inverse problems.arXiv preprint arXiv:2308.07983,
Gabriel Cardoso, Yazid Janati El Idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided diffusion for bayesian linear inverse problems.arXiv preprint arXiv:2308.07983,
-
[7]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sam- pling for general noisy inverse problems.arXiv preprint arXiv:2209.14687,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Variational schr\” odinger diffusion models.arXiv preprint arXiv:2405.04795,
Wei Deng, Weijian Luo, Yixin Tan, Marin Bilo ˇs, Yu Chen, Yuriy Nevmyvaka, and Ricky TQ Chen. Variational schr\” odinger diffusion models.arXiv preprint arXiv:2405.04795,
-
[9]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp.arXiv preprint arXiv:1605.08803,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Efficient bayesian computational imaging with a surrogate score-based prior
Berthy T Feng and Katherine L Bouman. Efficient bayesian computational imaging with a surrogate score-based prior. arXiv preprint arXiv:2309.01949,
-
[11]
Berthy T Feng, Jamie Smith, Michael Rubinstein, Huiwen Chang, Katherine L Bouman, and William T Freeman. Score-based diffusion models as principled priors for inverse imaging.arXiv preprint arXiv:2304.11751,
-
[12]
doi: 10.20944/preprints202603.1152.v1. URL https://doi.org/10. 20944/preprints202603.1152.v1. Marco A Iglesias, Kody JH Law, and Andrew M Stuart. 14 Ensemble kalman methods for inverse problems.Inverse Problems, 29(4):045001,
-
[13]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior syn- thesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2403.06054 (2024)
Xiang Li, Soo Min Kwon, Ismail R Alkhouri, Saiprasad Ravishankar, and Qing Qu. Decoupled data consistency with diffusion purification for image restoration.arXiv preprint arXiv:2403.06054,
-
[15]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.arXiv preprint arXiv:2206.00927,
-
[16]
Weijian Luo. A comprehensive survey on knowledge distilla- tion of diffusion models.arXiv preprint arXiv:2304.04262,
-
[17]
Weijian Luo. Diff-instruct++: Training one-step text-to-image generator model to align with human preferences.arXiv preprint arXiv:2410.18881,
-
[18]
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems, 37:115377–115408, 2024a. Weijian Luo, Colin Zhang, Debing Zhang, and Zhengyang Geng. Diff-instruct*: Towards human-preferred one- step text-to-image generative models.ar...
-
[19]
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models.arXiv preprint arXiv:2305.04391,
-
[20]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to-image diffusion mod- els with deep language understanding.arXiv preprint arXiv:2205.11487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Bowen Song, Soo Min Kwon, Zecheng Zhang, Xinyu Hu, Qing Qu, and Liyue Shen. Solving inverse problems with latent diffusion models via hard data consistency.arXiv preprint arXiv:2307.08123,
-
[23]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[24]
Provable probabilistic imaging using score- based generative priors.arXiv preprint arXiv:2310.10835,
Yu Sun, Zihui Wu, Yifan Chen, Berthy T Feng, and Kather- ine L Bouman. Provable probabilistic imaging using score- based generative priors.arXiv preprint arXiv:2310.10835,
-
[25]
Brian L Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi Jaakkola. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem.arXiv preprint arXiv:2206.04119,
-
[26]
Yifei Wang, Weimin Bai, Weijian Luo, Wenzheng Chen, and He Sun. Integrating amortized inference with diffusion mod- els for learning clean distribution from corrupted images. arXiv preprint arXiv:2407.11162,
-
[27]
Yifei Wang, Weimin Bai, Colin Zhang, Debing Zhang, Weijian Luo, and He Sun. Uni-instruct: One-step diffusion model through unified diffusion divergence instruction.arXiv preprint arXiv:2505.20755,
-
[28]
Xingyu Xu and Yuejie Chi. Provably robust score-based diffusion posterior sampling for plug-and-play image recon- struction.arXiv preprint arXiv:2403.17042,
-
[29]
Zilyu Ye, Zhiyang Chen, Tiancheng Li, Zemin Huang, Weijian Luo, and Guo-Jun Qi. Schedule on the fly: Diffusion time prediction for faster and better image generation.arXiv preprint arXiv:2412.01243,
-
[30]
Improving diffusion inverse problem solving with decoupled noise annealing
Bingliang Zhang, Wenda Chu, Julius Berner, Chenlin Meng, Anima Anandkumar, and Yang Song. Improving diffusion inverse problem solving with decoupled noise annealing. arXiv preprint arXiv:2407.01521,
-
[31]
Hongkai Zheng, Wenda Chu, Bingliang Zhang, Zihui Wu, Austin Wang, Berthy T Feng, Caifeng Zou, Yu Sun, Nikola Kovachki, Zachary E Ross, et al. Inversebench: Benchmark- ing plug-and-play diffusion priors for inverse problems in physical sciences.arXiv preprint arXiv:2503.11043,
-
[32]
Mingyuan Zhou, Huangjie Zheng, Yi Gu, Zhendong Wang, and Hai Huang. Adversarial score identity distillation: Rapidly surpassing the teacher in one step.arXiv preprint arXiv:2410.14919, 2024a. Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion mode...
-
[33]
Repulsive latent score distillation for solving inverse prob- lems.arXiv preprint arXiv:2406.16683,
Nicolas Zilberstein, Morteza Mardani, and Santiago Segarra. Repulsive latent score distillation for solving inverse prob- lems.arXiv preprint arXiv:2406.16683,
-
[34]
His current research in- terests include representation learning and generative modeling
He is currently working toward the doctoral degree with Rice University. His current research in- terests include representation learning and generative modeling. Weijian Luois a RedStar Senior Research Sci- entist at the Humane Intelligence (hi) Lab, Xiao- hongshu Inc. He received his B.S. degree from the University of Science and Technology of China and...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.