TinyFormer: Preserving Tiny Objects in YOLO-DETR Hybrid Real-time Detectors
Pith reviewed 2026-06-30 12:07 UTC · model grok-4.3
The pith
TinyFormer hybrid fuses YOLO pyramids with DETR set prediction to retain tiny objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
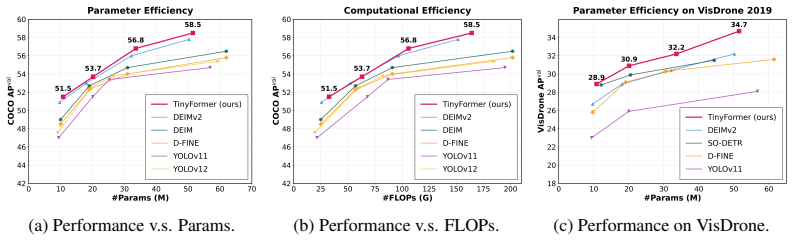
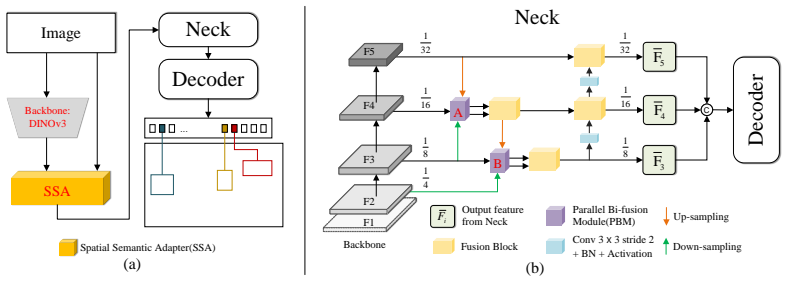
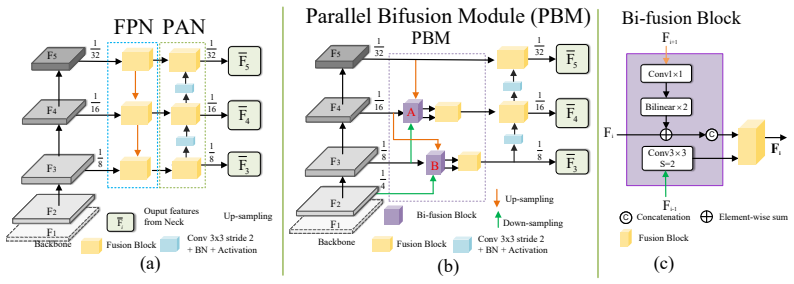
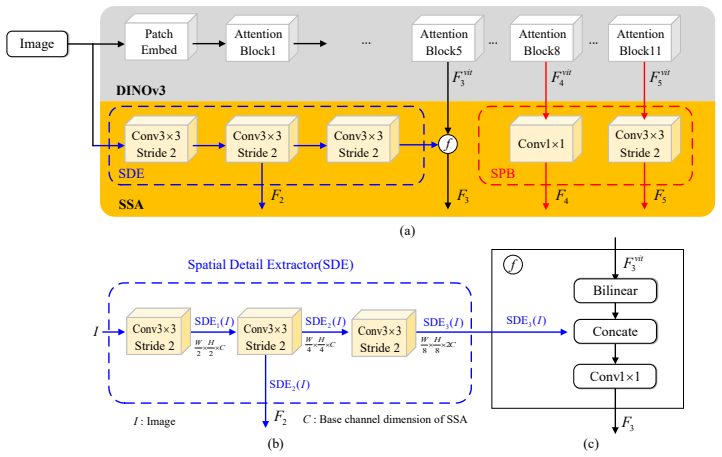
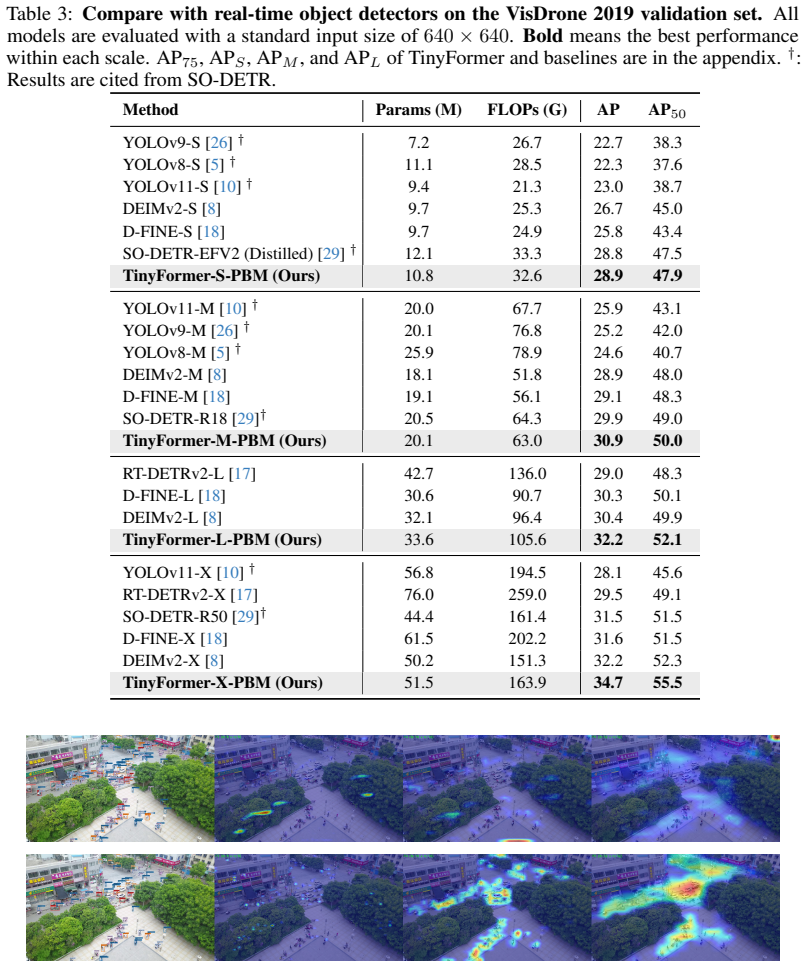
TinyFormer unifies dense YOLO-style feature fusion and DETR-style set prediction through a Parallel Bi-fusion Module that builds high-resolution shortcuts from shallow stages and a Spatial Semantic Adapter that injects early high-resolution cues into transformer embeddings, yielding 58.5 percent AP overall and a 1.6 percent AP gain on small objects.
What carries the argument
Parallel Bi-fusion Module (PBM) that creates high-resolution shortcuts from shallow stages to the feature pyramid, together with Spatial Semantic Adapter (SSA) that extracts and injects early-stage spatial cues into transformer token embeddings.
If this is right
- Real-time detectors can reach higher small-object accuracy by combining dense pyramid fusion with set prediction.
- Adding PBM alone raises small-object AP by 1.6 percent while overall AP increases slightly.
- Objects365 pre-training lifts the same model to 60.2 percent AP with lower parameter count than competing pretrained detectors.
- The hybrid architecture offers a concrete accuracy-efficiency trade-off for applications that must run at video rates.
Where Pith is reading between the lines
- The same shortcut and adapter pattern may transfer to other transformer detectors that currently under-perform on fine-scale features.
- Testing the modules on datasets with even smaller average object size could reveal whether the gains scale with object size.
- Replacing the ViT backbone with a lighter CNN might isolate how much of the improvement comes from the fusion modules versus the transformer itself.
Load-bearing premise
The measured gains on small objects are produced by the PBM and SSA modules rather than by any differences in training schedule, data augmentation, or hyper-parameters relative to the YOLO and DEIMv2 baselines.
What would settle it
An experiment that retrains the DEIMv2 or YOLO baselines with exactly the same schedule, augmentation, and hyper-parameters used for TinyFormer and obtains equal or larger AP gains on small objects would show the modules are not responsible.
Figures
read the original abstract
YOLO-series and DETR-based detectors struggle with tiny-object detection. YOLO-style models benefit from efficient dense prediction, but their large-stride backbones may suppress tiny instances in deep feature maps and make grid assignment ambiguous. DETR-based models remove hand-crafted post-processing through set prediction, yet they reason over coarse token grids, where tiny objects occupy only a few weak tokens and are easily overlooked during matching. To address these limitations, we propose TinyFormer, a unified YOLO--DETR hybrid real-time detector that combines ViT representations, NMS-free set prediction, and a YOLO-style pyramid neck for accurate small-object detection. TinyFormer introduces a Parallel Bi-fusion Module (PBM), which builds high-resolution shortcuts from shallow stages to the feature pyramid, preserving fine spatial details during multi-scale fusion. We further design a Spatial Semantic Adapter (SSA) to compensate for the spatial loss caused by coarse tokenization. SSA extracts high-resolution cues from early stages and injects them into transformer token embeddings, improving tiny-object localization without sacrificing the global modeling ability of DETR. Experiments on MS COCO show that TinyFormer consistently outperforms recent YOLO-series detectors and the strong DEIMv2 baseline. TinyFormer-X achieves 58.4% AP even without PBM, while adding PBM improves the overall AP to 58.5% and brings a 1.6% AP gain on small objects. With Objects365 pre-training, TinyFormer-X-PBM reaches 60.2% AP, surpassing RF-DETR and other Objects365-pretrained detectors with fewer parameters and lower computation. These results demonstrate that TinyFormer bridges dense YOLO-style feature fusion and DETR-style set prediction, providing a strong accuracy-efficiency trade-off for real-time tiny-object detection. Code is available at https://github.com/mmpmmpmmpjosh/TinyFormer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TinyFormer, a YOLO-DETR hybrid real-time object detector that integrates ViT backbones, NMS-free set prediction, and a YOLO-style pyramid neck. It introduces the Parallel Bi-fusion Module (PBM) to create high-resolution shortcuts from shallow stages to the feature pyramid and the Spatial Semantic Adapter (SSA) to inject high-resolution cues from early stages into transformer token embeddings. On MS COCO, TinyFormer-X reaches 58.5% AP (58.4% without PBM) with a 1.6% AP gain on small objects; with Objects365 pre-training it reaches 60.2% AP while using fewer parameters than RF-DETR. Code is released.
Significance. If the small-object gains are robustly attributable to PBM and SSA, the work provides a concrete accuracy-efficiency trade-off for real-time tiny-object detection by bridging dense YOLO-style fusion with DETR-style matching. The public code release and use of the standard MS COCO benchmark are positive for reproducibility and comparability.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental comparisons): the claim that TinyFormer outperforms DEIMv2 and YOLO-series detectors does not include an explicit statement that all baselines were trained with identical epoch counts, learning-rate schedules, data-augmentation policies, and optimizer settings. Without this, the 1.6% AP_s improvement cannot be confidently credited to PBM and SSA rather than uncontrolled training differences.
- [§4.1] §4.1 (ablation on PBM): while the abstract reports a 0.1% overall AP increase and 1.6% AP_s increase when adding PBM to TinyFormer-X, the corresponding table or text does not report the AP_s value for the 58.4% configuration, preventing direct verification that the small-object gain is isolated to PBM.
minor comments (1)
- [§3] Notation for PBM and SSA is introduced in the abstract and §3 but the precise tensor shapes and injection points into the DETR decoder are not restated in a single equation or diagram caption, making the modules harder to re-implement from text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental clarity and ablation reporting. We address each major comment below and will make the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental comparisons): the claim that TinyFormer outperforms DEIMv2 and YOLO-series detectors does not include an explicit statement that all baselines were trained with identical epoch counts, learning-rate schedules, data-augmentation policies, and optimizer settings. Without this, the 1.6% AP_s improvement cannot be confidently credited to PBM and SSA rather than uncontrolled training differences.
Authors: We agree that an explicit statement on training parity is needed for full confidence in attributing gains to PBM and SSA. While we followed the official training recipes and hyperparameters reported in each baseline paper (standard practice for such comparisons), the manuscript does not document this explicitly. We will revise §4 to include a dedicated paragraph detailing that all models were trained for the same number of epochs using identical data-augmentation pipelines, learning-rate schedules, and optimizers (with minor adjustments only for convergence stability as noted in the original works). This addition will directly address the concern and allow readers to verify the attribution. revision: yes
-
Referee: [§4.1] §4.1 (ablation on PBM): while the abstract reports a 0.1% overall AP increase and 1.6% AP_s increase when adding PBM to TinyFormer-X, the corresponding table or text does not report the AP_s value for the 58.4% configuration, preventing direct verification that the small-object gain is isolated to PBM.
Authors: We acknowledge the omission in the ablation table. The text states that adding PBM yields a 1.6% AP_s gain, but the table in §4.1 does not list the corresponding AP_s for the 58.4% AP (no-PBM) variant. We will update the ablation table to explicitly report AP, AP_s, AP_m, and AP_l for both configurations, enabling direct verification that the small-object improvement is attributable to PBM. revision: yes
Circularity Check
No circularity: purely empirical architecture paper with externally verifiable results
full rationale
The paper presents a new YOLO-DETR hybrid detector and reports direct AP metrics on the fixed public MS COCO test set (e.g., 58.4% AP without PBM, 58.5% with PBM, 1.6% AP_s gain). No derivation chain, equations, or fitted parameters exist that could reduce a claimed prediction to its own inputs by construction. Self-citations, if present for baselines, are not load-bearing for the central accuracy claims, which remain falsifiable outside the paper. This matches the default non-circular outcome for empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- fusion and injection hyperparameters inside PBM and SSA
axioms (1)
- domain assumption High-resolution shortcuts from shallow stages preserve usable spatial detail for tiny objects
invented entities (2)
-
Parallel Bi-fusion Module (PBM)
no independent evidence
-
Spatial Semantic Adapter (SSA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yolov4: Optimal speed and accuracy of object detection.arXiv, 2020
Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection.arXiv, 2020
2020
-
[2]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
2020
-
[3]
Ping-Yang Chen, Ming-Ching Chang, Jun-Wei Hsieh, and Yong-Sheng Chen. Parallel residual bi-fusion feature pyramid network for accurate single-shot object detection.IEEE Transactions on Image Processing, 30:9099–9111, 2021. doi: 10.1109/TIP.2021.3118953
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Yolov8.https: // docs
Jocher Glenn. Yolov8.https: // docs. ultralytics. com/ models/ yolov8/, 2023
2023
-
[6]
Yolo11.https: // docs
Jocher Glenn. Yolo11.https: // docs. ultralytics. com/ models/ yolo11/, 2024
2024
-
[7]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, 2016
2016
-
[8]
Real-time object detection meets dinov3.arXiv, 2025
Shihua Huang, Yongjie Hou, Longfei Liu, Xuanlong Yu, and Xi Shen. Real-time object detection meets dinov3.arXiv, 2025
2025
-
[9]
Deim: Detr with improved matching for fast convergence
Shihua Huang, Zhichao Lu, Xiaodong Cun, Yongjun Yu, Xiao Zhou, and Xi Shen. Deim: Detr with improved matching for fast convergence. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15162–15171, 2025
2025
-
[10]
yolov11.https://github.com/ultralytics, 2024
Glenn Jocher. yolov11.https://github.com/ultralytics, 2024
2024
-
[11]
Glenn Jocher, K Nishimura, T Mineeva, and RJAM Vilariño. yolov5. https://github.com/ultralytics/yolov5/tree, 2, 2020
2020
-
[12]
Mengqi Lei, Siqi Li, Yihong Wu, and et al. Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception.arXiv preprint arXiv:2506.17733, 2025
-
[13]
A deep learning-based hybrid framework for object detection and recognition in autonomous driving.IEEE Access, 8:194228–194239, 2020
Yanfen Li, Hanxiang Wang, L Minh Dang, Tan N Nguyen, Dongil Han, Ahyun Lee, Insung Jang, and Hyeonjoon Moon. A deep learning-based hybrid framework for object detection and recognition in autonomous driving.IEEE Access, 8:194228–194239, 2020
2020
-
[14]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[15]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InCVPR, 2017
2017
-
[16]
Path aggregation network for instance seg- mentation
Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance seg- mentation. InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 10
2018
-
[17]
Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer, 2024
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer, 2024. URL https://arxiv.org/abs/ 2407.17140
-
[18]
D-fine: Redefine regression task in detrs as fine-grained distribution refinement.arXiv, 2024
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-fine: Redefine regression task in detrs as fine-grained distribution refinement.arXiv, 2024
2024
-
[19]
Rf-detr: Neural architecture search for real-time detection transformers, 2025
Isaac Robinson, Peter Robicheaux, Matvei Popov, Deva Ramanan, and Neehar Peri. Rf-detr: Neural architecture search for real-time detection transformers, 2025. URL https://arxiv.org/abs/2511. 09554
2025
-
[20]
Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, and Manoj Karkee. Yolo26: key architec- tural enhancements and performance benchmarking for real-time object detection.arXiv preprint arXiv:2509.25164, 2025
-
[21]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[22]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
YOLOv12: Attention-Centric Real-Time Object Detectors
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors. arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Yolov10: Real-time end-to-end object detection.arXiv preprint arXiv:2405.14458, 2024
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yolov10: Real-time end-to-end object detection.arXiv preprint arXiv:2405.14458, 2024
-
[25]
Cspnet: A new backbone that can enhance learning capability of cnn
Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. Cspnet: A new backbone that can enhance learning capability of cnn. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 390–391, 2020
2020
-
[26]
Yolov9: Learning what you want to learn using programmable gradient information.arXiv, 2024
Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. Yolov9: Learning what you want to learn using programmable gradient information.arXiv, 2024
2024
-
[27]
Surveiledge: Real-time video query based on collaborative cloud-edge deep learning
Shibo Wang, Shusen Yang, and Cong Zhao. Surveiledge: Real-time video query based on collaborative cloud-edge deep learning. InIEEE INFOCOM 2020-IEEE Conference on Computer Communications, pages 2519–2528. IEEE, 2020
2020
-
[28]
mixup: Beyond empirical risk minimization
Hongyi Zhang. mixup: Beyond empirical risk minimization. InICLR, 2017
2017
-
[29]
So-detr: leveraging dual-domain features and knowledge distillation for small object detection
Huaxiang Zhang, Hao Zhang, Aoran Mei, Zhongxue Gan, and Guo-Niu Zhu. So-detr: leveraging dual-domain features and knowledge distillation for small object detection. In2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
2025
-
[30]
Detrs beat yolos on real-time object detection, 2023
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection, 2023
2023
-
[31]
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Heng Fan, Qinghua Hu, and Haibin Ling. Detection and tracking meet drones challenge.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (11):7380–7399, 2021. 11 Appendix A Implementation Details We implement TinyFormer in PyTorch 2.5.1 with CUDA 12.2, building upon the DEIMv2 [8]. To ensure a s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.