Scale When Needed: Adaptive Neuron-level Mixed Precision Quantization Aware Training
Pith reviewed 2026-06-30 12:21 UTC · model grok-4.3
The pith
Each neuron learns its own bit precision during QAT to improve compression-accuracy trade-offs over layer-level methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NMP-QAT lets each neuron learn its own discrete precision independently during training. Bit width starts low and expands only when training signals require it, implemented through differentiable surrogates paired with straight-through estimators. The method applies to both weights and activations, preserves a fully discrete inference graph, and is shown on telecom and non-telecom datasets using MLP and tabular foundation models to deliver superior compression-accuracy results compared with existing mixed-precision QAT baselines.
What carries the argument
Per-neuron adaptive precision learning via differentiable surrogates and straight-through estimators that expand bit width on demand while keeping inference discrete.
Load-bearing premise
Differentiable surrogates combined with straight-through estimators can produce stable, generalizable discrete per-neuron precisions that translate directly into better inference performance without instability or overfitting.
What would settle it
A controlled comparison on a standard benchmark dataset where NMP-QAT at a given average bit rate yields lower accuracy than a strong layer-level mixed-precision QAT baseline.
Figures
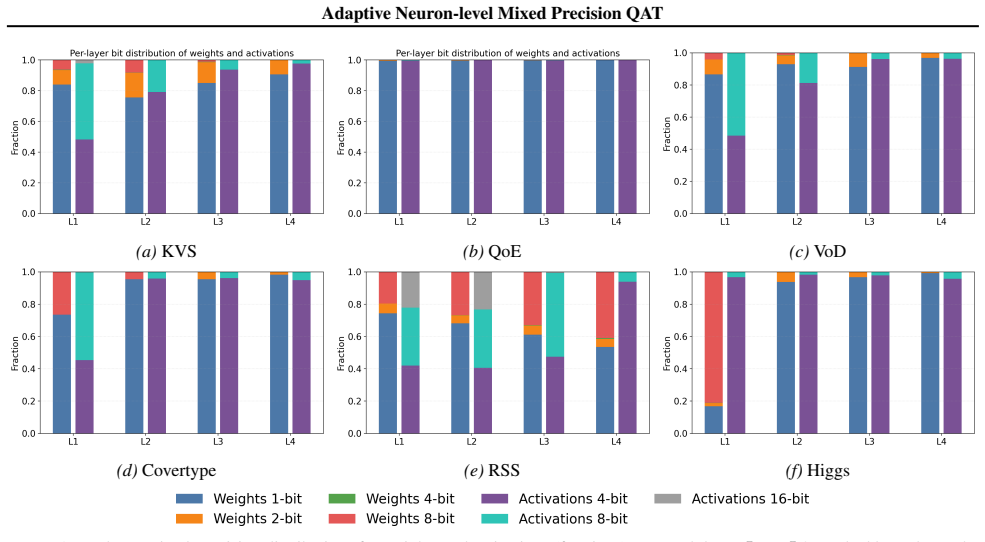
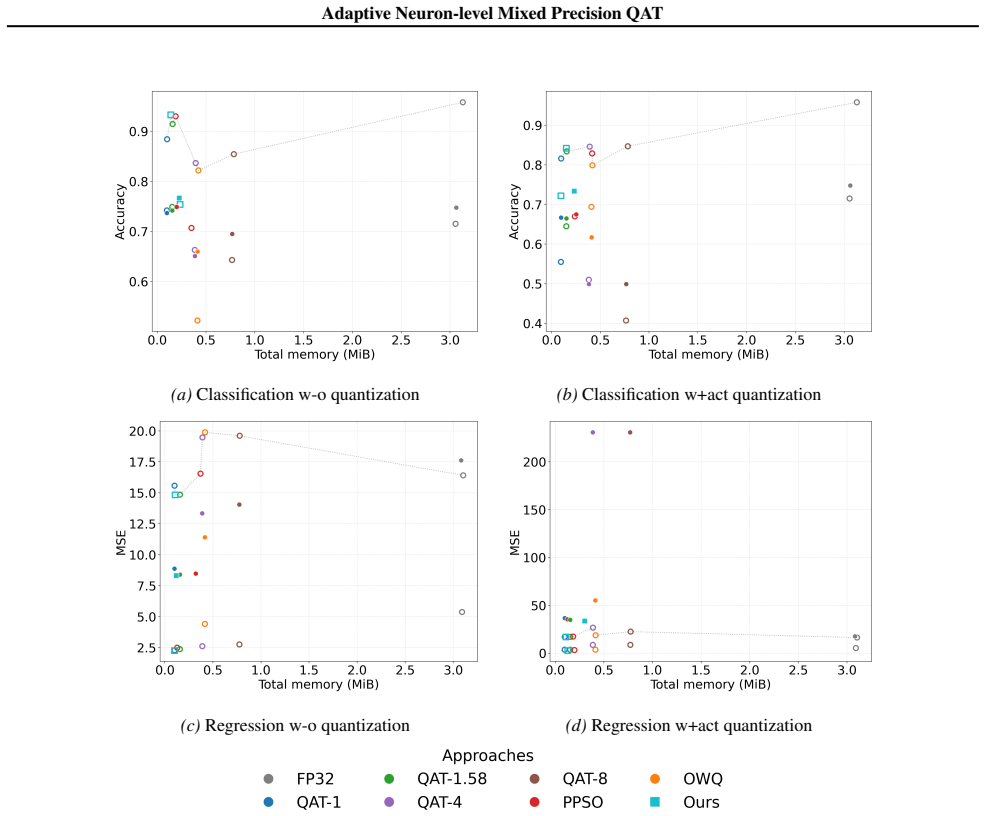
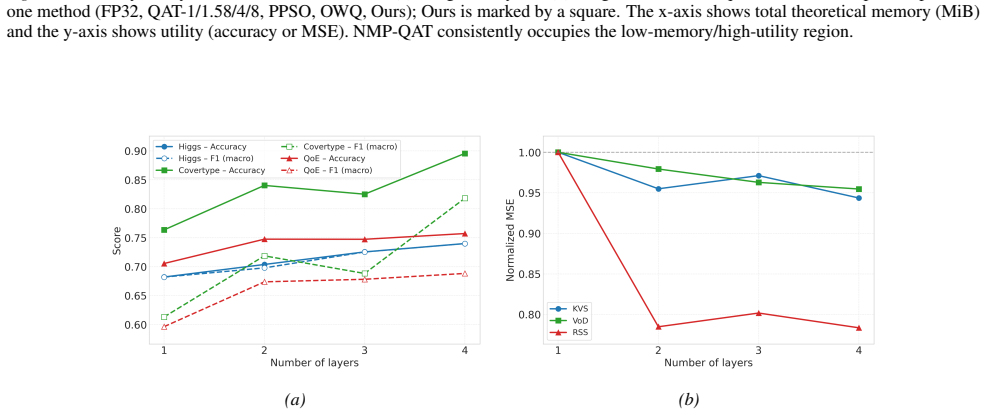
read the original abstract
Deploying deep neural networks on resource-constrained 6G edge devices demands aggressive compression with minimal accuracy loss. Quantization-Aware Training (QAT) has emerged as a leading compression approach; however, existing mixed-precision methods typically operate at coarse layer- or channel-level granularity. These methods often rely on heuristic or search-based bit-allocation strategies, which may overlook fine-grained variability at the neuron level. We propose Neuron-Level Mixed-Precision QAT (NMP-QAT), where each neuron independently learns its own discrete precision during training. Starting from low-bit precision, NMP-QAT expands bit-width only when training signals demand it, via differentiable surrogates and straight-through estimators, while preserving a fully discrete inference graph. This adaptability extends to both weights and activations, reducing memory movement. Evaluated on telecom and non-telecom datasets across MLP and tabular foundation model architectures, NMP-QAT achieves superior compression-accuracy trade-offs over mixed-precision QAT baselines, making it well-suited for Green AI deployments at the network edge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Neuron-Level Mixed-Precision QAT (NMP-QAT), a quantization-aware training approach in which each neuron independently learns its own discrete bit-width for weights and activations. The method begins at low precision and adaptively increases bit-width only when training signals require it, using differentiable surrogates combined with straight-through estimators while maintaining a fully discrete inference graph. Experiments are described on telecom and non-telecom datasets using MLP and tabular foundation model architectures, with the central claim that NMP-QAT yields superior compression-accuracy trade-offs relative to existing mixed-precision QAT baselines.
Significance. If the empirical results hold under rigorous evaluation, the work could contribute to more efficient inference on resource-constrained edge devices by introducing neuron-level granularity to mixed-precision quantization. This finer control may reduce memory movement beyond what layer- or channel-level methods achieve and aligns with Green AI goals for 6G and similar deployments.
major comments (1)
- [Abstract] Abstract: the central claim that NMP-QAT achieves superior compression-accuracy trade-offs is asserted without any quantitative results, baselines, error bars, or dataset details. This absence is load-bearing because it prevents verification of whether the data actually support the claim of improved trade-offs.
Simulated Author's Rebuttal
We thank the referee for their review. The single major comment concerns the abstract's lack of quantitative support for the central claim. We address this below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that NMP-QAT achieves superior compression-accuracy trade-offs is asserted without any quantitative results, baselines, error bars, or dataset details. This absence is load-bearing because it prevents verification of whether the data actually support the claim of improved trade-offs.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. The full manuscript reports specific metrics (accuracy, compression ratios, and comparisons) on the telecom and tabular datasets for both MLP and foundation-model backbones, including error bars from multiple runs. In the revision we will condense the key results (e.g., average accuracy retention at given bit budgets versus layer- and channel-level mixed-precision QAT baselines) into the abstract while remaining within length limits. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes a standard QAT extension using differentiable surrogates and straight-through estimators to learn per-neuron bit-widths starting from low precision. No load-bearing step reduces by construction to its own inputs, no fitted parameter is renamed as a prediction, and no self-citation chain is invoked to justify uniqueness or an ansatz. The central claim rests on empirical evaluation across datasets and architectures rather than any self-referential derivation. This is the normal case of an independent method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Channel-Wise Mixed-Precision Quantization for Large Language Models
Chen, Z., Xie, B., Li, J., and Shen, C. Channel-wise mixed- precision quantization for large language models.arXiv preprint arXiv:2410.13056,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
T., Pilligundla, P., Mireshghallah, F., Yazdan- bakhsh, A., and Esmaeilzadeh, H
Elthakeb, A. T., Pilligundla, P., Mireshghallah, F., Yazdan- bakhsh, A., and Esmaeilzadeh, H. Releq: A reinforce- ment learning approach for deep quantization of neural networks.arXiv preprint arXiv:1811.01704,
-
[3]
Tabular transformers for modeling multivariate time series
Padhi, I., Schiff, Y ., Melnyk, I., Rigotti, M., Mroueh, Y ., Dognin, P., Ross, J., Nair, R., and Altman, E. Tabular transformers for modeling multivariate time series. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3565–3569. IEEE,
2021
-
[4]
Impact Statement This paper presents NMP-QAT, a neuron-level mixed- precision quantization-aware training framework aimed at advancing efficient machine learning for resource- constrained deployments. The primary motivation is to enable accurate, low-footprint inference on edge devices, with particular relevance to 6G network intelligence, where energy ef...
2024
-
[5]
However, it targetsuniformlow-bit quantization (2-8 bits) through multi-stage freezing procedures, making extension to mixed-precision settings non-trivial
progressively quantizes neurons via freezing masks and straight-through estimators, outperforming layer- and channel-wise schemes in low-bit regimes. However, it targetsuniformlow-bit quantization (2-8 bits) through multi-stage freezing procedures, making extension to mixed-precision settings non-trivial. Neuron-levelmixed- precision methods, particularly...
2021
-
[6]
8 Adaptive Neuron-level Mixed Precision QAT This proves theO(T −1/2)convergence rate for stationarity of the surrogate objective
Choosingη= 1/ √ Tand assumingT≥L 2 so thatη≤1/L, we obtain 1 T T−1X t=0 E∥∇eL(θt)∥2 ≤ 2 eL(θ0)− eL∗ +Lσ 2 √ T . 8 Adaptive Neuron-level Mixed Precision QAT This proves theO(T −1/2)convergence rate for stationarity of the surrogate objective. It remains to relate surrogate stationarity to stationarity of the hard-quantized objective. By Assumption B.2, ∇WL...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.