STREAM: A Data-Centric Framework for Mining High-Value Task-Oriented Dialogues from Streaming Media
Pith reviewed 2026-06-30 11:42 UTC · model grok-4.3
The pith
Public streaming media can be mined to synthesize large-scale task-oriented dialogues that improve dialogue state tracking across model backbones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
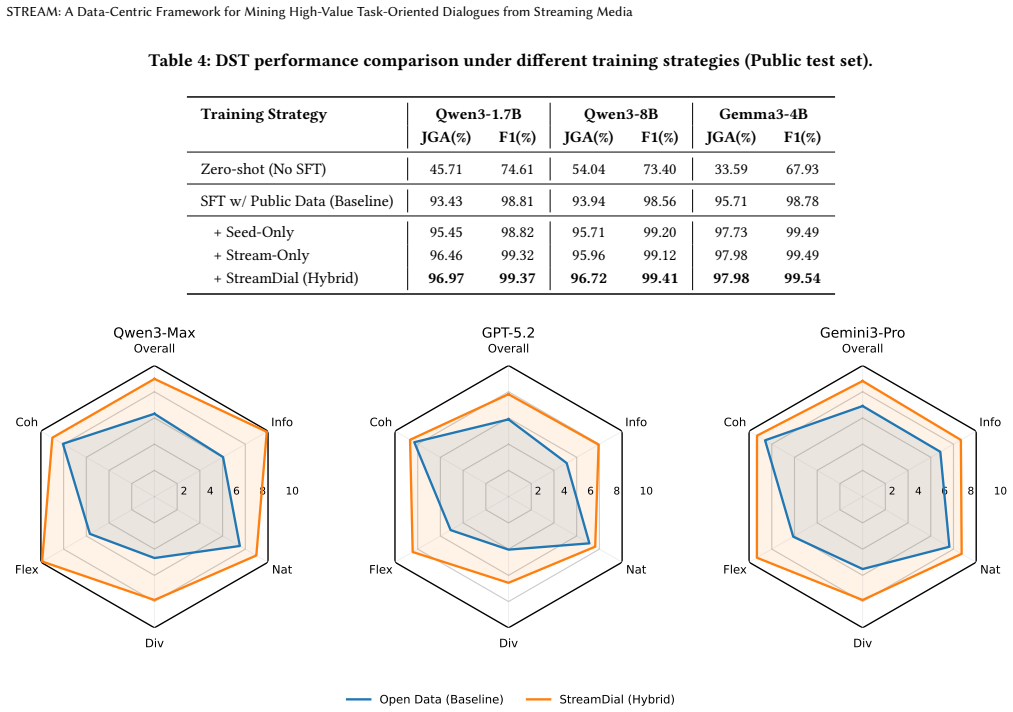
Stream mines authentic interaction signals from noisy streams and synthesizes conversations by integrating role-grounded persona construction with Conversational Blueprint construction; it further adopts retrieval-augmented generation to support knowledge-aware responses. Based on Stream, StreamDial is released with 87,498 dialogue sessions and 1,497,320 turns covering Automotive, Restaurant, and Hotel, each organized as a structured quadruplet that captures realistic service behaviors. Models trained with StreamDial improve intrinsic dialogue quality over strong baselines and improve Dialogue State Tracking across backbones, with reported multilingual transfer results under controlled budge
What carries the argument
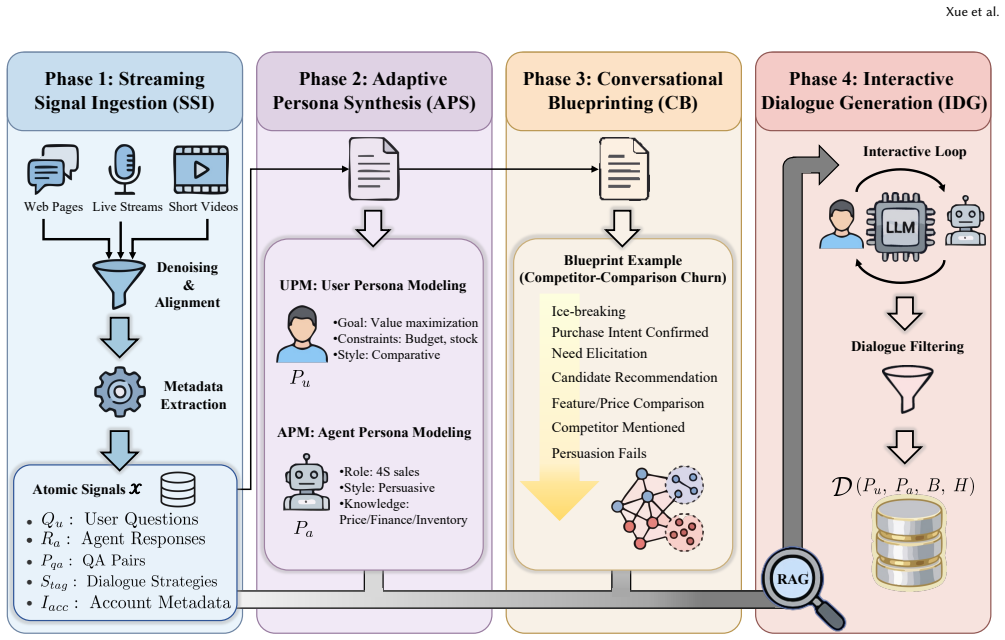
The Stream framework, which mines authentic interaction signals from noisy streaming media and synthesizes conversations via role-grounded persona construction, Conversational Blueprint construction, and retrieval-augmented generation.
If this is right
- StreamDial improves intrinsic dialogue quality over strong baselines according to automatic judges.
- Models trained with StreamDial improve Dialogue State Tracking performance across different backbones.
- The dataset supports encouraging multilingual transfer results on models such as Qwen3-8B under a controlled training budget.
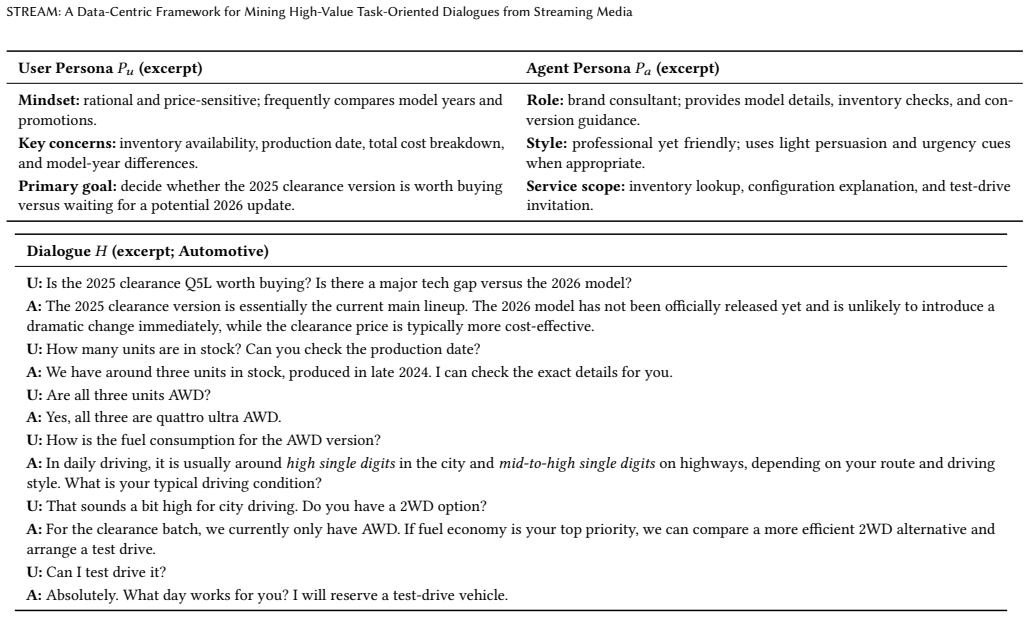
- Each session in the dataset is released as a structured quadruplet that explicitly pairs history with user and agent personas plus a Conversational Blueprint.
Where Pith is reading between the lines
- The same mining approach could be applied to additional vertical domains beyond the three evaluated, provided the streams contain comparable service interactions.
- The explicit blueprint and persona structure may enable finer-grained analysis of which dialogue behaviors most contribute to downstream gains.
- If the synthesized data generalizes, training budgets for domain-specific dialogue systems could shift away from expert annotation toward public media sources.
Load-bearing premise
Publicly available streaming media contains sufficient authentic task-oriented interaction signals that can be mined and synthesized via personas and blueprints to produce dialogues improving downstream performance.
What would settle it
A controlled experiment in which models trained on StreamDial show no gain or a loss in Dialogue State Tracking accuracy relative to models trained on prior static corpora or on data without the blueprint and persona structure.
Figures

read the original abstract
Large language models for vertical domains are bottlenecked by the scarcity of complex, domain-specific task-oriented dialogues. Existing data acquisition pipelines face a persistent trilemma: expert annotation is expensive, real-world service conversations are constrained by privacy and commercial restrictions, and static corpora quickly become temporally stale. We propose Stream, a data-centric framework that leverages publicly available streaming media (live streams and short videos) to synthesize high-value service dialogues at scale. Stream mines authentic interaction signals from noisy streams and synthesizes conversations by integrating role-grounded persona construction with Conversational Blueprint construction; it further adopts retrieval-augmented generation (RAG) to support knowledge-aware responses. Based on Stream, we release StreamDial, a large-scale multi-domain dataset covering Automotive, Restaurant, and Hotel. StreamDial contains 87,498 dialogue sessions and 1,497,320 turns in total, with an average of 17.11 turns per session and a comparable scale across domains. Each session is organized as a structured quadruplet $\langle P_u, P_a, B, H \rangle$ that pairs dialogue history with explicit user/agent personas and a Conversational Blueprint, capturing realistic service behaviors such as requirement mining, constraint conflicts, negotiation, and recovery. Evaluations with automatic judges and downstream tasks show that StreamDial improves intrinsic dialogue quality over strong baselines, and models trained with StreamDial improve Dialogue State Tracking across backbones; we further report a completed human-evaluation set and encouraging multilingual transfer on Qwen3-8B under a controlled training budget. The data is released in https://github.com/hitxueliang/DialogDataSetBySTREAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the STREAM framework, which mines authentic interaction signals from publicly available streaming media (live streams and short videos) to synthesize high-value task-oriented service dialogues via role-grounded personas and Conversational Blueprints, augmented by RAG for knowledge-aware responses. It releases the StreamDial dataset (87,498 sessions, 1.5M turns across Automotive/Restaurant/Hotel domains) structured as quadruplets ⟨P_u, P_a, B, H⟩ and claims that StreamDial improves intrinsic dialogue quality over baselines and boosts DST performance across model backbones, with additional human evaluation and multilingual transfer results.
Significance. If the core mining premise holds and the synthesized dialogues demonstrably capture realistic service behaviors (requirement mining, negotiation, recovery), the work would offer a scalable, privacy-preserving alternative to expert annotation or restricted real-world corpora, directly addressing data scarcity for vertical-domain LLMs. The release of a large, structured, multi-domain dataset with explicit blueprints is a concrete contribution that could enable reproducible downstream research.
major comments (2)
- [Abstract] Abstract: the central claim that Stream 'mines authentic interaction signals from noisy streams' to produce quadruplet-structured dialogues containing requirement mining, constraint conflicts, and negotiation is load-bearing for all downstream claims, yet the abstract provides no examples, statistics, or evidence that such multi-turn agent-user task-oriented interactions exist in the source streaming media (as opposed to monologues, reviews, or entertainment content). Without this substantiation, the premise that publicly available streams contain sufficient authentic signals for the target domains cannot be evaluated.
- [Abstract] Abstract: the statements that 'evaluations with automatic judges and downstream tasks show that StreamDial improves intrinsic dialogue quality over strong baselines' and 'models trained with StreamDial improve Dialogue State Tracking across backbones' are presented without any metrics, baselines, or evaluation protocols. This absence prevents assessment of whether the claimed improvements are statistically meaningful or merely artifacts of the synthesis process.
minor comments (2)
- [Abstract] The abstract mentions a 'completed human-evaluation set' and 'encouraging multilingual transfer on Qwen3-8B' but gives no details on scale, inter-annotator agreement, or controlled conditions; these should be expanded in the main text with specific numbers and protocols.
- [Abstract] The GitHub link for data release is provided, but the manuscript should include a brief description of the release format, licensing, and any filtering steps applied to the quadruplets to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify areas where the abstract could be strengthened to better support its claims. We address each point below and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Stream 'mines authentic interaction signals from noisy streams' to produce quadruplet-structured dialogues containing requirement mining, constraint conflicts, and negotiation is load-bearing for all downstream claims, yet the abstract provides no examples, statistics, or evidence that such multi-turn agent-user task-oriented interactions exist in the source streaming media (as opposed to monologues, reviews, or entertainment content). Without this substantiation, the premise that publicly available streams contain sufficient authentic signals for the target domains cannot be evaluated.
Authors: We agree that the abstract would benefit from more direct substantiation of the core premise. The full manuscript provides this evidence in Sections 3.1–3.3 (source media analysis, persona and blueprint construction) and Table 2 (statistics on interaction types such as negotiation and recovery across the 87k sessions). However, we acknowledge the abstract should be more self-contained. We will revise it to include a concise illustrative example of a mined multi-turn interaction and key statistics on the prevalence of task-oriented behaviors in the streaming sources. revision: yes
-
Referee: [Abstract] Abstract: the statements that 'evaluations with automatic judges and downstream tasks show that StreamDial improves intrinsic dialogue quality over strong baselines' and 'models trained with StreamDial improve Dialogue State Tracking across backbones' are presented without any metrics, baselines, or evaluation protocols. This absence prevents assessment of whether the claimed improvements are statistically meaningful or merely artifacts of the synthesis process.
Authors: We agree that the abstract would be stronger with explicit metrics and protocol references. The manuscript details the evaluation setup, baselines, and results (including automatic judges, human evaluation, and DST experiments across backbones) in Sections 5 and 6. We will revise the abstract to incorporate representative quantitative results and a brief mention of the evaluation protocols to allow readers to assess the improvements directly. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes an external data-mining and synthesis pipeline (Stream) that ingests publicly available streaming media, applies role-grounded persona construction plus Conversational Blueprint construction, and augments with RAG to produce the StreamDial quadruplets. Downstream evaluations (automatic judges, DST task improvements) compare the resulting dataset against independent baselines rather than re-deriving any quantity from the synthesis parameters themselves. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description that would collapse the claimed improvements back to the input construction by definition. The framework therefore remains an independent synthesis method whose outputs are tested externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public streaming media contains extractable authentic task-oriented interaction signals suitable for high-value dialogue synthesis
invented entities (1)
-
Conversational Blueprint
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shya- mal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Bal- tescu, Haim ing Bao, Mo Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, ...
2023
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, R...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[4]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection.ArXivabs/2310.11511 (2023). https://api.semanticscholar.org/ CorpusID:264288947
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gasic. 2018. MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. InConference on Empirical Methods in Natural Language Processing. https: //api.semanticscholar.org/CorpusID:52897360
2018
-
[6]
Daoyuan Chen, Yilun Huang, Xuchen Pan, Nana Jiang, Haibin Wang, Ce Ge, Yushuo Chen, Wenhao Zhang, Zhijian Ma, Yilei Zhang, Jun Huang, Wei Lin, Yaliang Li, Bolin Ding, and Jingren Zhou. 2025. Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models.ArXivabs/2501.14755 (2025). https://api.semanticscholar.org/CorpusID:279154431
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mish...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Seamless Communication, Loïc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady ElSahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, ...
-
[9]
https://api.semanticscholar.org/CorpusID: 267200805
SeamlessM4T-Massively Multilingual & Multimodal Machine Transla- tion.ArXivabs/2308.11596 (2023). https://api.semanticscholar.org/CorpusID: 267200805
-
[10]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. 2024. A Survey on LLM-as-a-Judge.ArXivabs/2411.15594 (2024). https://api.semanticscholar.org/CorpusID:274234014
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane A. Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2022. Few-shot Learning with Retrieval Augmented Language Models.J. Mach. Learn. Res.24 (2022), 251:1–251:43. https://api.semanticscholar.org/CorpusID:251371732
2022
-
[12]
Gemma Team Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram’e, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-Bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gael Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.ArXivabs/2005.11401 (2020). https://api.semanticscholar.org/CorpusID:218869575
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
M. Moradshahi, Tianhao Shen, Kalika Bali, Monojit Choudhury, Gaël de Chalen- dar, Anmol Goel, Sungkyun Kim, Prashant Kodali, Ponnurangam Kumaraguru, Nasredine Semmar, Sina J. Semnani, Jiwon Seo, Vivek Seshadri, Manish Shri- vastava, Michael Sun, Aditya Yadavalli, Chaobin You, Deyi Xiong, and Mon- ica S. Lam. 2023. X-RiSAWOZ: High-Quality End-to-End Multil...
-
[16]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior.Proceedings of the 36th Annual ACM Symposium on User Inter- face Software and Technology(2023). https://api.semanticscholar.org/CorpusID: 258040990
2023
-
[17]
Baolin Peng, Chunyuan Li, Jinchao Li, Shahin Shayandeh, Lars Lidén, and Jian- feng Gao. 2021. Soloist: Building Task Bots at Scale with Transfer Learning and Machine Teaching.Transactions of the Association for Computational Linguistics 9 (2021), 807–824. https://api.semanticscholar.org/CorpusID:236937204
2021
-
[18]
Lanzendörfer, Florian Yan, and Roger Wattenhofer
Samuel Pfisterer, Florian Grötschla, Luca A. Lanzendörfer, Florian Yan, and Roger Wattenhofer. 2025. EuroSpeech: A Multilingual Speech Corpus.ArXiv abs/2510.00514 (2025). https://api.semanticscholar.org/CorpusID:281705709
-
[19]
Jun Quan, Shian Zhang, Qian Cao, Zi pu Li, and Deyi Xiong. 2020. RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annota- tions for Task-Oriented Dialogue Modeling. InConference on Empirical Meth- ods in Natural Language Processing. https://api.semanticscholar.org/CorpusID: 224706438
2020
-
[20]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning. https://api.semanticscholar.org/CorpusID:231591445
2021
-
[21]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. InInternational Conference on Machine Learning. https://api. semanticscholar.org/CorpusID:252923993
2022
-
[22]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-Context Retrieval-Augmented Lan- guage Models.Transactions of the Association for Computational Linguistics11 (2023), 1316–1331. https://api.semanticscholar.org/CorpusID:256459451
2023
-
[23]
Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2019. Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset. InAAAI Conference on Artificial Intelligence. https://api.semanticscholar.org/CorpusID:202565722
2019
-
[24]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embed- dings using Siamese BERT-Networks.ArXivabs/1908.10084 (2019). https: //api.semanticscholar.org/CorpusID:201646309
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Young, and David Vandyke
Lina Maria Rojas-Barahona, Milica Gasic, Nikola Mrksic, Pei hao Su, Stefan Ultes, Tsung-Hsien Wen, Steve J. Young, and David Vandyke. 2016. A Network- based End-to-End Trainable Task-oriented Dialogue System. InConference of the European Chapter of the Association for Computational Linguistics. https: //api.semanticscholar.org/CorpusID:10565222
2016
-
[26]
Paul Voigt and Axel von dem Bussche. 2024. The EU General Data Protection Regulation (GDPR): A Practical Guide.The EU General Data Protection Regulation (GDPR)(2024). https://api.semanticscholar.org/CorpusID:273725799
2024
-
[27]
Lei Wang, Chengbang Ma, Xueyang Feng, Zeyu Zhang, Hao ran Yang, Jingsen Zhang, Zhi-Yang Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji rong Wen. 2023. A survey on large language model based autonomous agents.Frontiers of Computer Science18 (2023). https: //api.semanticscholar.org/CorpusID:261064713
2023
-
[28]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-Instruct: Aligning Language Models with Self-Generated Instructions. InAnnual Meeting of the Association for Computational Linguistics. https://api.semanticscholar.org/CorpusID:254877310
2022
-
[29]
Williams, Kavosh Asadi, and Geoffrey Zweig
J. Williams, Kavosh Asadi, and Geoffrey Zweig. 2017. Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforce- ment learning. InAnnual Meeting of the Association for Computational Linguistics. https://api.semanticscholar.org/CorpusID:13214003
2017
-
[30]
Chien-Sheng Wu, Steven C. H. Hoi, Richard Socher, and Caiming Xiong. 2020. TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue. InConference on Empirical Methods in Natural Language Processing. https://api.semanticscholar.org/CorpusID:215768835
2020
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Jingren Zhou, Junyan Lin, Kai Dang, Keqin Bao, Ke-Pei Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models.ArXivabs/2305.10601 (2023). https: //api.semanticscholar.org/CorpusID:258762525
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. ReAct: Synergizing Reasoning and Acting in Language Models.ArXivabs/2210.03629 (2022). https://api.semanticscholar.org/CorpusID: 252762395
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Young, Milica Gasic, Blaise Thomson, and J
Steve J. Young, Milica Gasic, Blaise Thomson, and J. Williams. 2013. POMDP- Based Statistical Spoken Dialog Systems: A Review.Proc. IEEE101 (2013), 1160–
2013
-
[35]
https://api.semanticscholar.org/CorpusID:2364633
-
[36]
Ming Zhang, Caishuang Huang, Yilong Wu, Shichun Liu, Huiyuan Zheng, Yurui Dong, Yujiong Shen, Shihan Dou, Jun Zhao, Junjie Ye, Qi Zhang, Tao Gui, and Xuanjing Huang. 2024. TransferTOD: A Generalizable Chinese Multi-Domain Task-Oriented Dialogue System with Transfer Capabilities. InConference on Empirical Methods in Natural Language Processing. https://api...
2024
-
[37]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Haotong Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena.ArXivabs/2306.05685 (2023). https://api.semanticscholar. org/CorpusID:259129398
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Qi Zhu, Kaili Huang, Zheng Zhang, Xiaoyan Zhu, and Minlie Huang. 2020. Cross- WOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset. Transactions of the Association for Computational Linguistics8 (2020), 281–295. https://api.semanticscholar.org/CorpusID:211532256 STREAM: A Data-Centric Framework for Mining High-Value Task-Oriented Dialogu...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.