K-U-KAN: Koopman-Enhanced U-KAN for 3D Dental Reconstruction from a Single Panoramic X-ray Radiograph
Pith reviewed 2026-06-30 11:42 UTC · model grok-4.3
The pith
K-U-KAN reconstructs 3D dental volumes from a single panoramic X-ray by lifting features with KANs then evolving them linearly via Koopman dynamics before focal-trough placement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
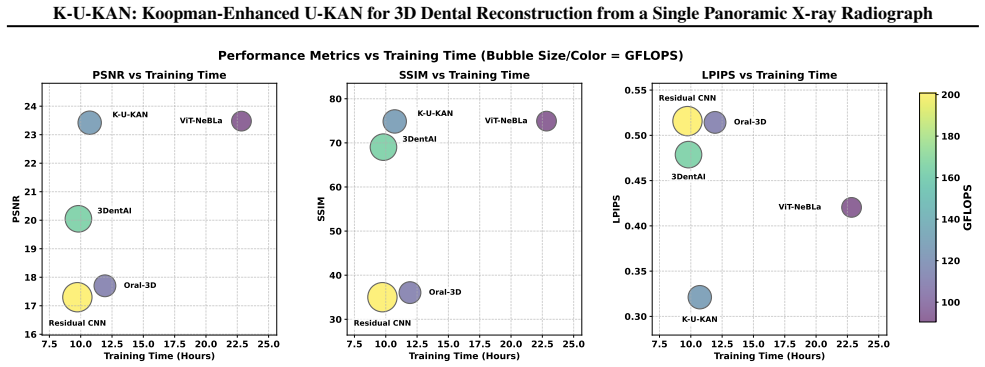
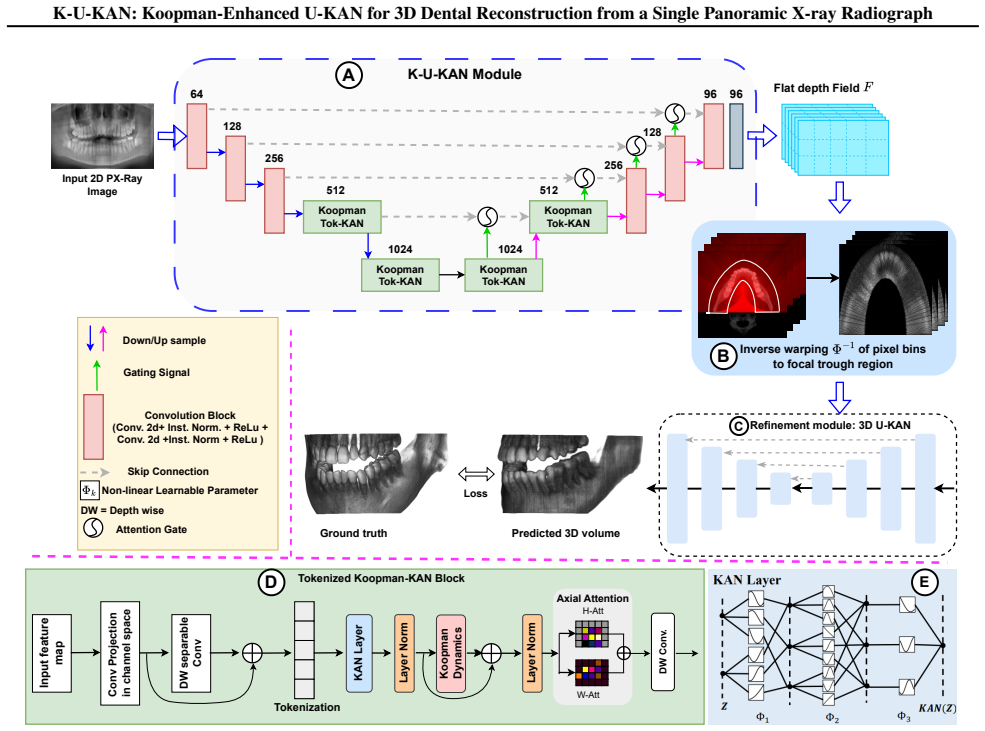
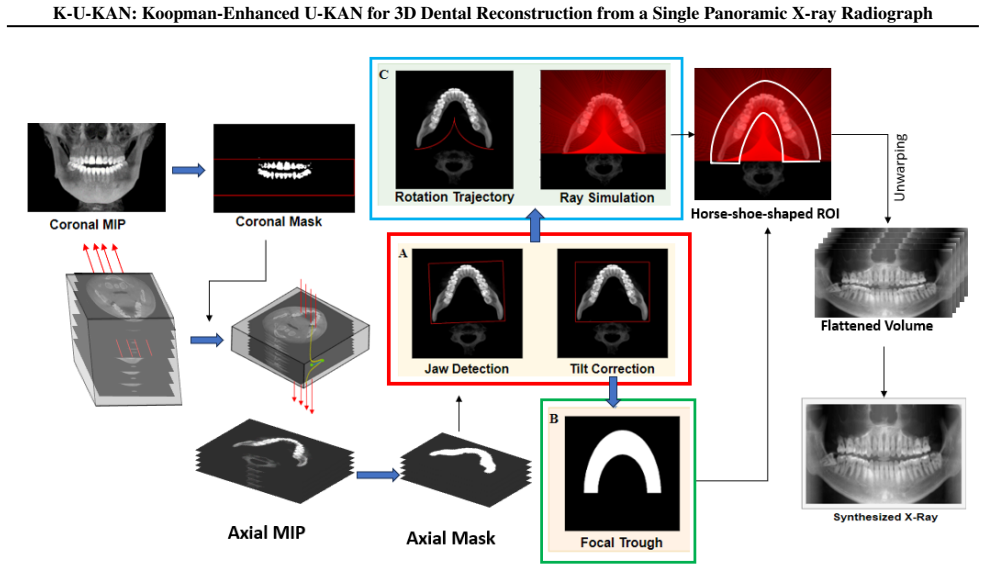
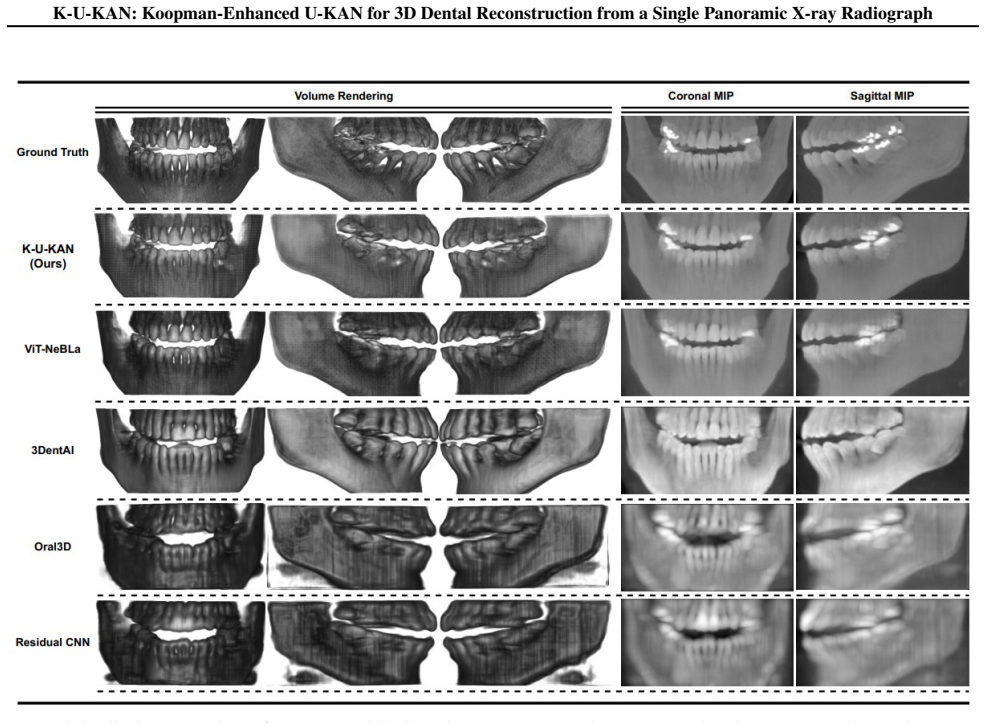
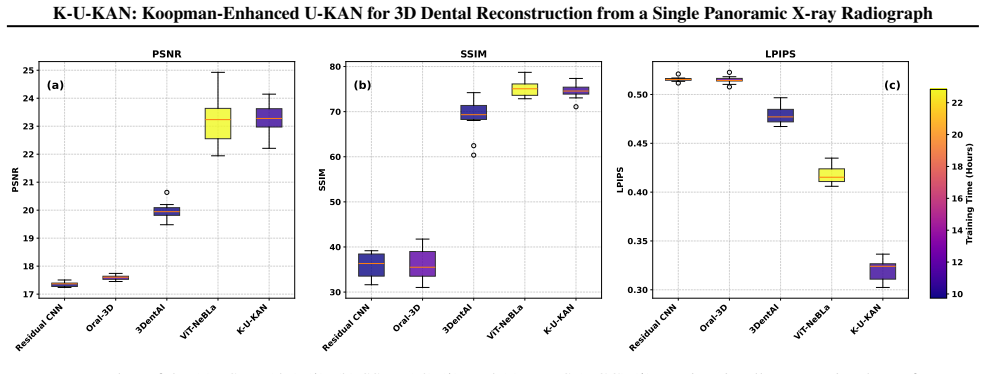
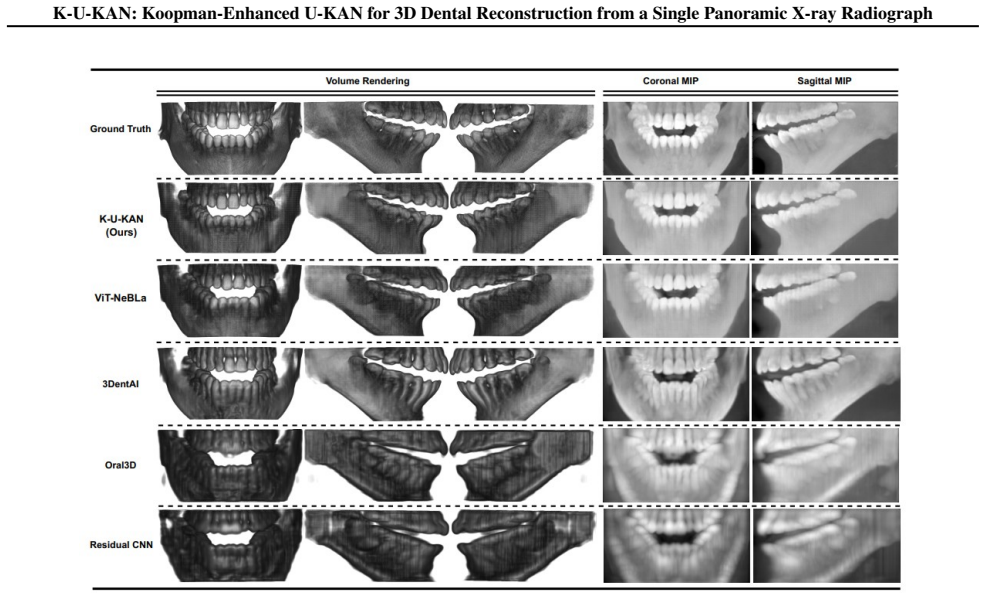
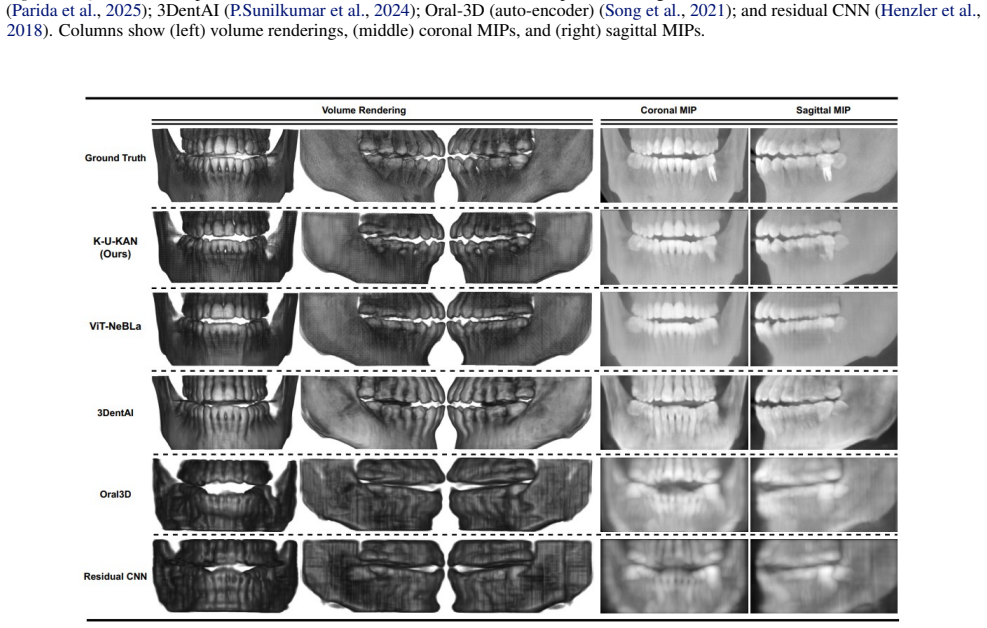
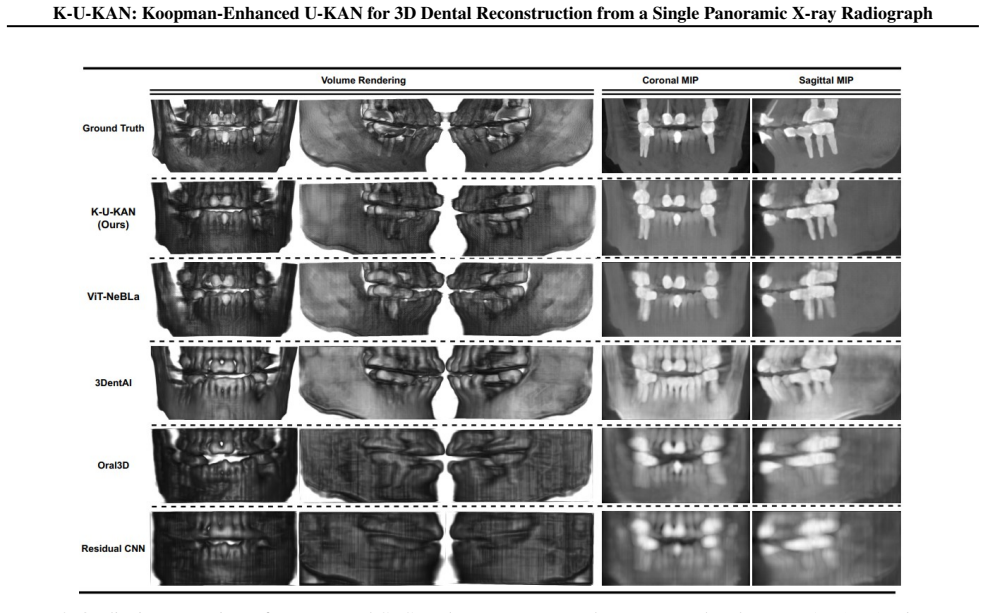
K-U-KAN is a three-stage pipeline that (i) lifts 2D features into depth-aware observables with Kolmogorov-Arnold Networks, (ii) advances these observables by a stable, phase-aware linear evolution via a Koopman token block, and (iii) places the predicted depth bins onto focal-trough rays before a lightweight 3D attention U-KAN refines the volume. This marriage of physics (Beer-Lambert image formation), geometry (horseshoe focal trough), and learned linear dynamics yields sharp anatomy, fewer artifacts, and robust behavior on native radiographic intensities with batch size one. On held-out data, K-U-KAN matches transformer/implicit baselines on signal and structure metrics, clearly improves p
What carries the argument
Three-stage pipeline of KAN-based lifting to depth-aware observables, Koopman token block for stable phase-aware linear evolution, and projection onto horseshoe focal-trough rays before 3D attention U-KAN refinement.
If this is right
- Matches transformer and implicit baselines on signal and structure metrics.
- Improves perceptual quality over those baselines.
- Trains in roughly half the time of competing methods.
- Operates effectively with batch size one on native radiographic intensities.
- Yields volumes with sharp anatomy and fewer artifacts through explicit physics and geometry constraints.
Where Pith is reading between the lines
- The reported efficiency gains could allow deployment on standard clinical hardware without specialized accelerators.
- The explicit use of focal-trough geometry may make the reconstructions more consistent with the curved shape of real dental arches than purely learned approaches.
- The linear evolution step could support incremental updates when new 2D views become available.
- Similar combinations of KAN lifting and Koopman evolution might apply to other single-projection medical reconstruction tasks with known imaging geometry.
Load-bearing premise
The assumption that lifting 2D features into depth-aware observables with KANs, followed by stable phase-aware linear evolution via the Koopman token block and placement onto focal-trough rays, supplies sufficient information for the lightweight 3D attention U-KAN to produce accurate volumes.
What would settle it
An ablation experiment on held-out data showing that removing the Koopman token block or the focal-trough ray placement causes clear drops in perceptual quality or increases in artifacts would falsify the claim that these steps drive the reported gains.
Figures
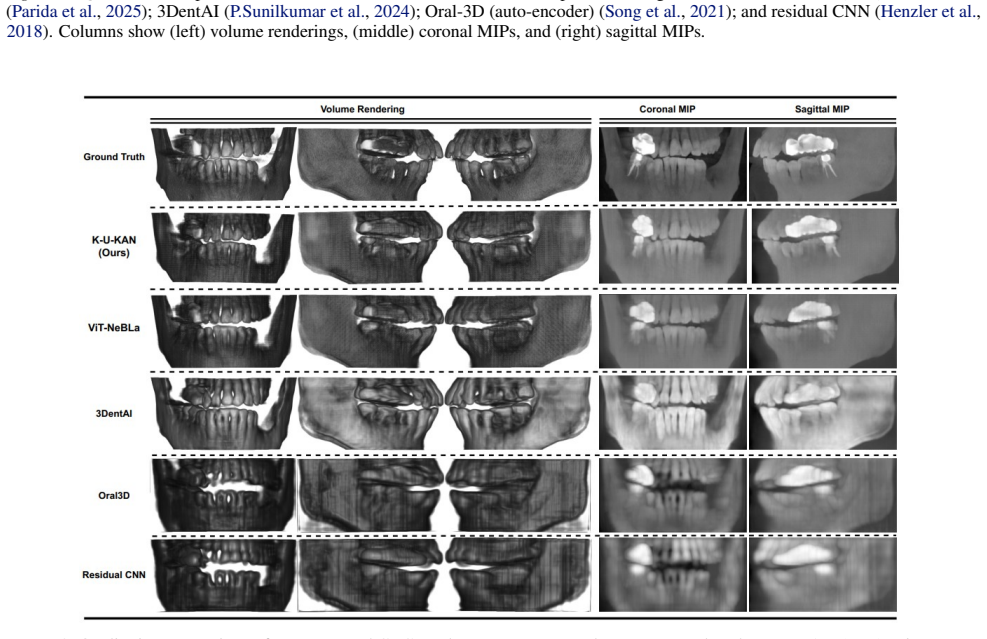
read the original abstract
A panoramic X-ray compresses a 3D jaw into a 2D strip; we aim to recover the missing depth cleanly and fast. Existing implicit neural representations render realistic volumes but are slow to train, sensitive to sampling and positional encodings, and costly in practice. Pure CNN baselines are efficient yet struggle with the dental arch's long-range geometry, blur fine enamel-dentin boundaries, and offer little interpretability. We present K-U-KAN, a three-stage pipeline that (i) lifts 2D features into depth-aware observables with Kolmogorov-Arnold Networks, (ii) advances these observables by a stable, phase-aware linear evolution via a Koopman token block, and (iii) places the predicted depth bins onto focal-trough rays before a lightweight 3D attention U-KAN refines the volume. This marriage of physics (Beer-Lambert image formation), geometry (horseshoe focal trough), and learned linear dynamics yields sharp anatomy, fewer artifacts, and robust behavior on native radiographic intensities with batch size one. On held-out data, K-U-KAN matches transformer/implicit baselines on signal and structure metrics, clearly improves perceptual quality, and trains in roughly half the time-making single-view PX $\to$ CBCT reconstruction more practical for clinical pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents K-U-KAN, a three-stage pipeline for 3D dental volume reconstruction from a single panoramic X-ray. Stage (i) lifts 2D features to depth-aware observables via Kolmogorov-Arnold Networks; stage (ii) evolves them with a stable phase-aware linear Koopman token block; stage (iii) places the depth bins onto horseshoe focal-trough rays before refinement by a lightweight 3D attention U-KAN. The approach integrates Beer-Lambert image formation and focal-trough geometry priors. The authors claim the method produces sharp anatomy with fewer artifacts, matches transformer/implicit baselines on signal and structure metrics, improves perceptual quality, and trains in roughly half the time on native intensities with batch size one.
Significance. If the central claims hold with supporting quantitative evidence, the work would be significant for clinical dental pipelines by offering a faster, physics-informed alternative to implicit representations or standard CNNs for single-view PX-to-CBCT reconstruction. The explicit use of geometric and dynamic priors could improve interpretability and robustness on long-range dental arch geometry.
major comments (3)
- [Abstract] Abstract: performance claims (matching baselines on signal/structure metrics, halved training time, improved perceptual quality) are stated without any numerical values, tables, figures, error bars, or ablation results, rendering the central claim of practical superiority impossible to evaluate from the supplied information.
- [Method (Koopman token block)] Method description of Koopman token block (stage ii): no derivation of the Koopman operator, no eigenvalue-magnitude analysis for stability, and no verification that the resulting observables remain invertible to accurate depth bins consistent with the Beer-Lambert and focal-trough model; this is load-bearing because the lightweight 3D U-KAN may simply learn a generic mapping rather than benefiting from the claimed priors.
- [Experiments] Experiments / results section: the assumption that KAN lifting + Koopman evolution + focal-trough ray placement supplies sufficient depth information is presented without explicit checks on operator stability, ray-placement consistency, or depth-bin accuracy on held-out data, leaving the robustness claims untested.
minor comments (1)
- [Abstract] Abstract: the final sentence contains a missing space ('time-making').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance claims (matching baselines on signal/structure metrics, halved training time, improved perceptual quality) are stated without any numerical values, tables, figures, error bars, or ablation results, rendering the central claim of practical superiority impossible to evaluate from the supplied information.
Authors: We agree that the abstract would be strengthened by explicit numerical support for the claims. In the revised version we have incorporated key quantitative results drawn from the experiments (e.g., matching SSIM/PSNR within reported margins, perceptual metric gains, and training-time reduction) together with pointers to the relevant tables and figures. revision: yes
-
Referee: [Method (Koopman token block)] Method description of Koopman token block (stage ii): no derivation of the Koopman operator, no eigenvalue-magnitude analysis for stability, and no verification that the resulting observables remain invertible to accurate depth bins consistent with the Beer-Lambert and focal-trough model; this is load-bearing because the lightweight 3D U-KAN may simply learn a generic mapping rather than benefiting from the claimed priors.
Authors: We accept this observation. The revised method section now contains an explicit derivation of the phase-aware Koopman operator, an eigenvalue-magnitude analysis confirming stability, and verification that the observables invert to depth bins consistent with the physical models. These additions clarify that the block contributes structured dynamics beyond a generic mapping. revision: yes
-
Referee: [Experiments] Experiments / results section: the assumption that KAN lifting + Koopman evolution + focal-trough ray placement supplies sufficient depth information is presented without explicit checks on operator stability, ray-placement consistency, or depth-bin accuracy on held-out data, leaving the robustness claims untested.
Authors: We agree that explicit validation is required. The updated experiments section adds analyses of operator stability (eigenvalue spectra), ray-placement consistency, and depth-bin accuracy on held-out data; these results are reported in a new subsection and the supplementary material. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's three-stage pipeline combines external physical priors (Beer-Lambert image formation) and geometric constraints (horseshoe focal trough) with KAN lifting, Koopman evolution, and U-KAN refinement. These elements are presented as an integration of independent known models rather than any quantity being defined in terms of itself or a fitted parameter being relabeled as a prediction. No self-citations, uniqueness theorems from the authors, or ansatzes smuggled via prior work appear in the provided abstract or method description, and the claims are evaluated against held-out data using standard metrics. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Koopman operators can provide stable, phase-aware linear evolution of depth-aware observables extracted from 2D radiographic features
- domain assumption Horseshoe-shaped focal trough rays accurately represent the geometry for placing predicted depth bins
invented entities (1)
-
Koopman token block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https: //arxiv.org/abs/2405.12832
doi: 10.48550/arXiv.2405.12832. URL https: //arxiv.org/abs/2405.12832. Brunton, S. L., Budiˇsi´c, M., Kaiser, E., and Kutz, J. N. Mod- ern koopman theory for dynamical systems.SIAM Re- view, 64(2):229–340, 2022. doi: 10.1137/21M1401243. Diaz, R., De La Vega Martin, C., and Sandler, M. To- wards efficient modelling of string dynamics: A com- parison of sta...
-
[2]
ISSN 0167-7055, 1467-8659. doi: 10.1111/cgf. 13369. URL https://onlinelibrary.wiley. com/doi/10.1111/cgf.13369. Jacobs, R., Salmon, B., Codari, M., Hassan, B., and Born- stein, M. M. Cone beam computed tomography in implant dentistry: recommendations for clinical use. BMC Oral Health, 18(1):88, May 2018. ISSN 1472-
work page doi:10.1111/cgf 2018
-
[3]
URL https: //doi.org/10.1186/s12903-018-0523-5
doi: 10.1186/s12903-018-0523-5. URL https: //doi.org/10.1186/s12903-018-0523-5. 17 K-U-KAN: Koopman-Enhanced U-KAN for 3D Dental Reconstruction from a Single Panoramic X-ray Radiograph Jader, G., Fontineli, J., Ruiz, M., Abdalla, K., Pithon, M., and Oliveira, L. Deep Instance Segmentation of Teeth in Panoramic X-Ray Images. In2018 31st SIB- GRAPI Conferen...
-
[4]
URL https: //doi.org/10.1016/j.amc.2021.126877
doi: 10.1016/j.amc.2021.126877. URL https: //doi.org/10.1016/j.amc.2021.126877. Ketcham, R. A. and Hanna, R. D. Beam hard- ening correction for x-ray computed tomography of heterogeneous natural materials.Computers & Geosciences, 67:49–61, 2014. ISSN 0098-
-
[5]
doi: https://doi.org/10.1016/j.cageo.2014.03
-
[6]
Khan, S., Naseer, M., Hayat, M., Zamir, S
URL https://www.sciencedirect.com/ science/article/pii/S0098300414000533. Khan, S., Naseer, M., Hayat, M., Zamir, S. W., Khan, F. S., and Shah, M. Transformers in Vision: A Sur- vey.ACM Computing Surveys, 54(10s):1–41, January
-
[7]
ISSN 0360-0300, 1557-7341. doi: 10.1145/ 3505244. URL https://dl.acm.org/doi/10. 1145/3505244. Koopman, B. O. Hamiltonian systems and transformations in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931. doi: 10.1073/pnas.17.5. 315. Lee, J.-H., Kim, D.-h., Jeong, S.-N., and Choi, S.- H. Diagnosis and prediction of periodon...
-
[8]
Li, C., Liu, X., Li, W., Wang, C., Liu, H., Liu, Y ., Chen, Z., and Yuan, Y
URL https://jpis.org/DOIx.php?id= 10.5051/jpis.2018.48.2.114. Li, C., Liu, X., Li, W., Wang, C., Liu, H., Liu, Y ., Chen, Z., and Yuan, Y . U-kan makes strong backbone for medical image segmentation and generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39,
-
[9]
URL https: //doi.org/10.1609/aaai.v39i5.32491
doi: 10.1609/aaai.v39i5.32491. URL https: //doi.org/10.1609/aaai.v39i5.32491. Li, X., Meng, M., Huang, Z., Bi, L., Delamare, E., Feng, D., Sheng, B., and Kim, J. 3DPX: Progressive 2D-to-3D Oral Image Reconstruction with Hybrid MLP-CNN Networks. In Linguraru, M. G., Dou, Q., Feragen, A., Giannarou, S., Glocker, B., Lekadir, K., and Schnabel, J. A. (eds.),M...
-
[10]
ISSN 0250-832X, 1476-542X. doi: 10.1259/dmfr. 20140197. URL https://academic.oup.com/ dmfr/article/7263895. Lusch, B., Kutz, J. N., and Brunton, S. L. Deep learning for universal linear embeddings of nonlinear dynamics. Nature Communications, 9(1):4950, 2018. doi: 10.1038/ s41467-018-07210-0. URL https://doi.org/10. 1038/s41467-018-07210-0. Ma, W., Wu, H....
-
[11]
Attention U-Net: Learning Where to Look for the Pancreas
doi: 10.1007/s00247-017-4012-9. URL https: //doi.org/10.1007/s00247-017-4012-9. Oktay, O., Schlemper, J., Folgoc, L. L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N. Y ., Kainz, B., Glocker, B., and Rueckert, D. Attention u-net: Learning where to look for the pancreas, 2018. URLhttps://arxiv.org/abs/1804.03999. Parida, B. K., Su...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s00247-017-4012-9 2018
-
[13]
URL https: //arxiv.org/abs/2509.18483
doi: 10.48550/arXiv.2509.18483. URL https: //arxiv.org/abs/2509.18483. Shah, N. Recent advances in imaging technologies in dentistry.World Journal of Radiology, 6(10): 794, 2014. ISSN 1949-8470. doi: 10.4329/ wjr.v6.i10.794. URL http://www.wjgnet.com/ 1949-8470/full/v6/i10/794.htm. Somvanshi, S., Javed, S. A., Islam, M. M., Pandit, D., and Das, S. A surve...
-
[14]
doi: 10.1609/ aaai.v35i1.16135
ISSN 2374-3468, 2159-5399. doi: 10.1609/ aaai.v35i1.16135. URL https://ojs.aaai.org/ index.php/AAAI/article/view/16135. Song, W., Zheng, H., Tu, D., Liang, C., and He, L. Oral- 3dv2: 3d oral reconstruction from panoramic x-ray imag- ing with implicit neural representation, 2023. URL https://arxiv.org/abs/2303.12123. Stramotas, S. Accuracy of linear and an...
-
[15]
URL https:// academic.oup.com/ejo/article-lookup/ doi/10.1093/ejo/24.1.43
doi: 10.1093/ejo/24.1.43. URL https:// academic.oup.com/ejo/article-lookup/ doi/10.1093/ejo/24.1.43. Sun, J., Huang, Y ., Yu, W., Garcia-Ortiz, A., et al. Re- cursive regulator: A deep-learning and real-time model adaptation strategy for nonlinear systems.Commu- nications Engineering, 4:140, 2025. doi: 10.1038/ s44172-025-00477-4. Sunilkumar, A. P., Parid...
-
[16]
A comprehensive review on generative AI for education
ISSN 2169-3536. doi: 10.1109/ACCESS. 2025.3573744. URL https://ieeexplore.ieee. org/document/11015780/. Tirunagari, S., Poh, N., Wells, K., Bober, M., and Win- dridge, D. Movement correction in dce-mri through windowed and reconstruction dynamic mode decomposi- tion.Machine Vision and Applications, 28(3-4):393–407,
-
[17]
URL https: //doi.org/10.1007/s00138-017-0835-5
doi: 10.1007/s00138-017-0835-5. URL https: //doi.org/10.1007/s00138-017-0835-5. Vandenberghe, B., Jacobs, R., and Bosmans, H. Modern dental imaging: a review of the current technology and clinical applications in dental practice.European Radi- ology, 20(11):2637–2655, November 2010. ISSN 0938- 7994, 1432-1084. doi: 10.1007/s00330-010-1836-1. URL http://li...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.