Growing a Neural Network in Breadth, Depth, and Time
Pith reviewed 2026-06-29 23:20 UTC · model grok-4.3
The pith
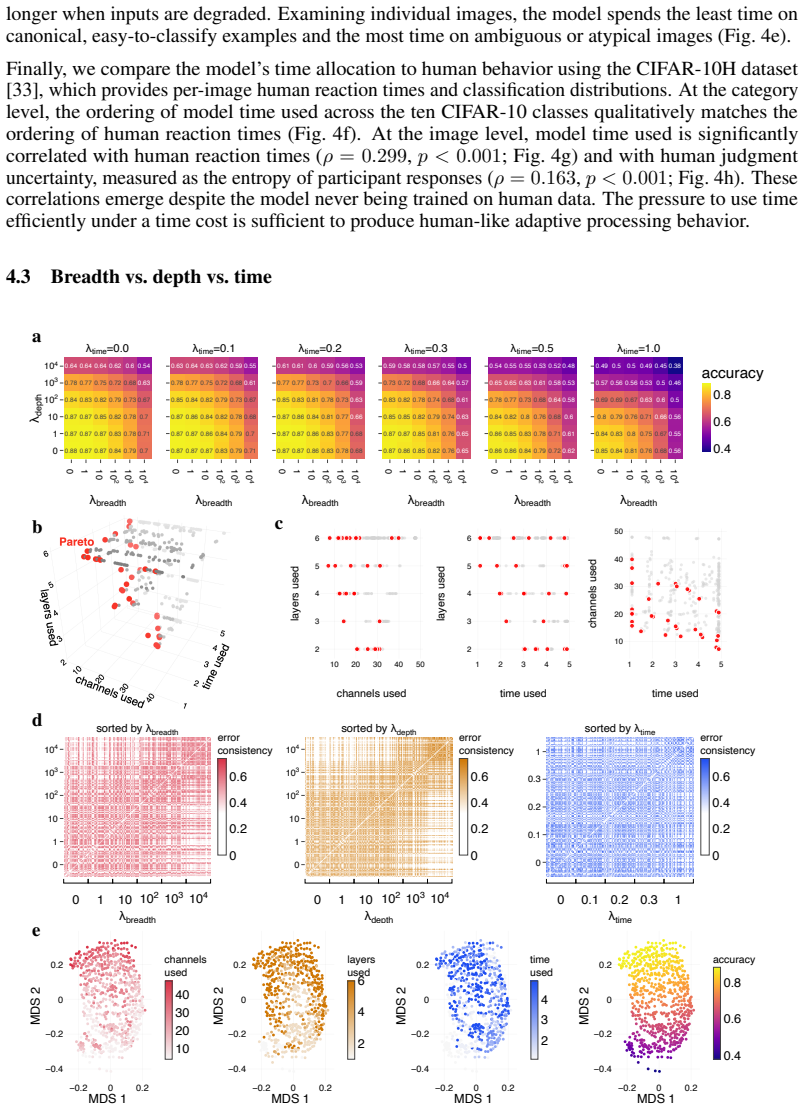
Recurrent convolutional networks learn to trade off breadth, depth, and time when these resources are penalized with differentiable costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
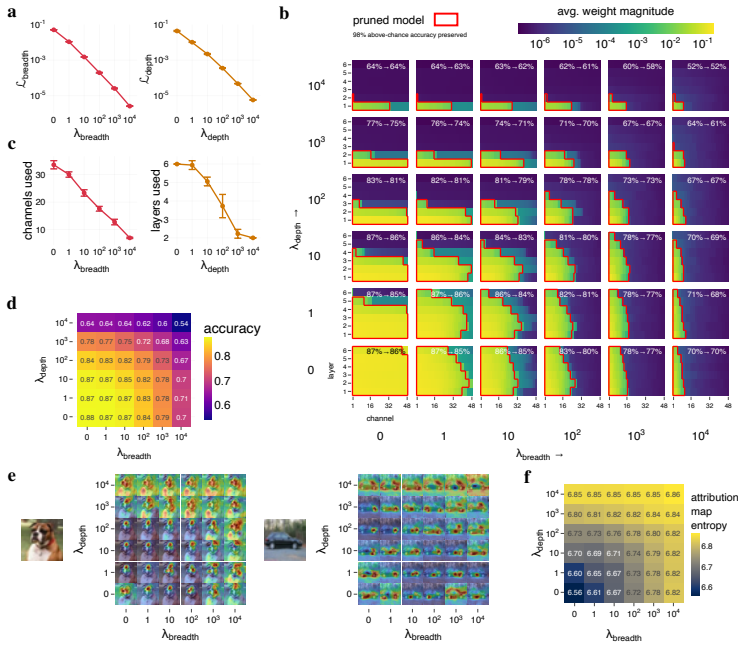
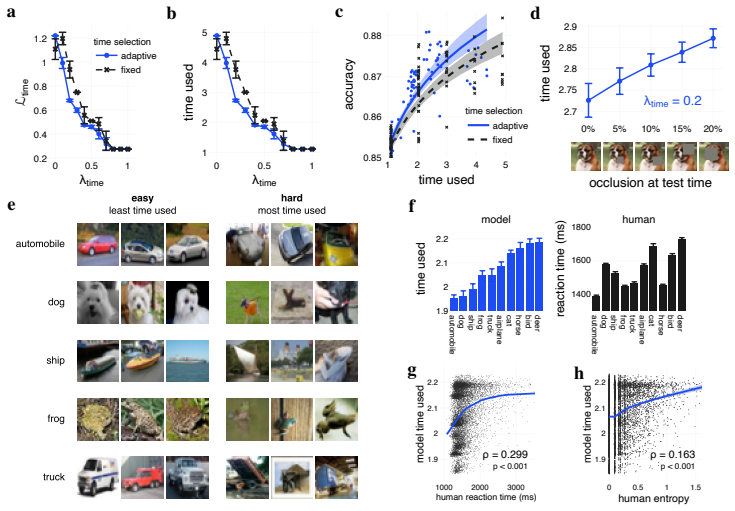
Jointly optimizing task error with costs on breadth, depth, and time causes diverse computational graphs to emerge, with all three resources trading off against each other, networks growing in every dimension as tasks become harder, increased recurrence under occlusion, and model time correlating with human reaction times.
What carries the argument
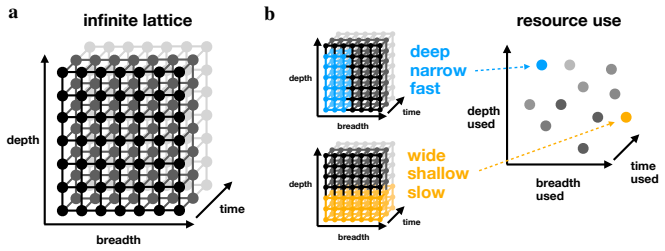
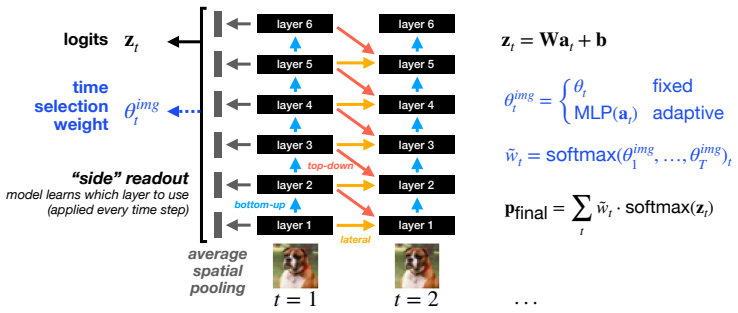
Differentiable cost terms for breadth, depth, and time, optimized jointly with task errors via backpropagation within a recurrent convolutional network conceived as a finite subset of an infinite lattice.
If this is right
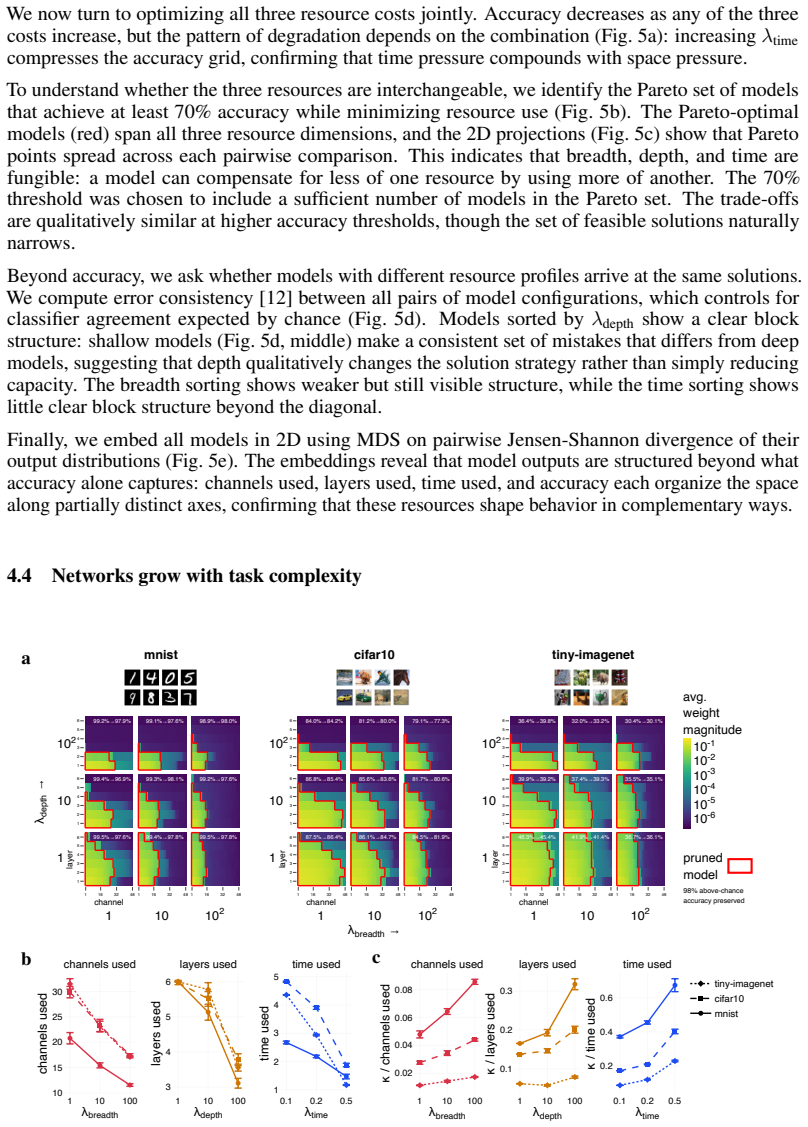
- Networks grow in breadth, depth, and time as task complexity increases.
- All three resources can be traded off to achieve a target accuracy.
- More recurrent steps are taken spontaneously when inputs are occluded.
- Time used by the model correlates with human reaction times in object recognition.
- Diverse computational graphs emerge under varying pressures on the three resources.
Where Pith is reading between the lines
- Similar mechanisms might explain variations in brain size and recurrence across different species or cognitive demands.
- The approach could be used to design artificial networks that balance efficiency across multiple resource dimensions.
- Applying the method to other sensory modalities or tasks might test whether the human reaction time correlation generalizes.
- The infinite lattice conception allows for continuous rather than discrete network scaling in theory.
Load-bearing premise
The specific differentiable costs chosen for breadth, depth, and time, along with the recurrent convolutional architecture as a finite subset of an infinite lattice, faithfully capture the resource constraints that shape neural computation.
What would settle it
A failure to observe resource trade-offs, lack of growth in all three dimensions with task complexity, or absence of correlation between model time and human reaction times on the object recognition task would falsify the central claims.
Figures

read the original abstract
Spatial and temporal resource constraints are critical for both biological and artificial intelligent systems. Here we define differentiable cost terms for breadth, depth, and time within a recurrent convolutional neural network conceived as a finite subset of an infinite lattice. We optimize these costs jointly with task errors via backpropagation. We set different pressures on breadth, depth, and time, which leads to diverse computational graphs emerging organically through training. We find that all three resources can be traded off against each other to achieve a given level of accuracy. Networks grow in all three dimensions with task complexity and spontaneously take more recurrent steps when inputs are occluded. Surprisingly, time used by the model correlates with human reaction times in an object recognition task. Our framework provides a normative account of how resource constraints shape neural architectures, connecting to questions about brain design in neuroscience, and may help illuminate the diversity of neural solutions found in nature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines differentiable cost terms for breadth, depth, and time within a recurrent convolutional network treated as a finite subset of an infinite lattice. These costs are optimized jointly with task loss via backpropagation under varying resource pressures, producing emergent computational graphs. Key findings include trade-offs among the three resources for fixed accuracy, growth in all dimensions with task complexity, increased recurrent steps under occlusion, and a correlation between model time usage and human reaction times in object recognition.
Significance. If the results hold under scrutiny of the cost functions and controls, the work supplies a normative model linking resource constraints to architectural diversity, with direct relevance to questions of brain design in neuroscience. The joint optimization and spontaneous emergence of dynamics (e.g., extra recurrent steps) are notable strengths when the cost terms can be independently justified.
major comments (2)
- [Abstract] Abstract: the assertion that the framework supplies a 'normative account of how resource constraints shape neural architectures' is load-bearing for the central claim, yet the differentiable cost terms for breadth, depth, and time are selected for differentiability rather than derived from measured biological quantities (e.g., wiring length or metabolic rate); alternative exponents or normalizations could eliminate the reported trade-offs and spontaneous dynamics.
- [Abstract] The resource pressure coefficients (lambdas) are free parameters; without an independent justification or sensitivity analysis showing that the growth patterns and human-RT correlation survive changes in functional form, the normative interpretation risks circularity.
minor comments (1)
- [Abstract] Abstract: the reported correlation between model time and human reaction times lacks any mention of statistical test, effect size, number of participants, or controls for task difficulty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our normative framing. We address the two major points below and will revise the manuscript accordingly to strengthen the presentation of our cost functions and their justification.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the framework supplies a 'normative account of how resource constraints shape neural architectures' is load-bearing for the central claim, yet the differentiable cost terms for breadth, depth, and time are selected for differentiability rather than derived from measured biological quantities (e.g., wiring length or metabolic rate); alternative exponents or normalizations could eliminate the reported trade-offs and spontaneous dynamics.
Authors: We agree that the cost terms (linear penalties on breadth and depth, and a step-count penalty on time) were selected to be differentiable so that resource usage can be optimized jointly with task loss via backpropagation. The normative claim refers to the principle that explicit, optimizable resource constraints can produce emergent architectural diversity and dynamics, rather than to the claim that our exact functional forms match measured biological quantities. We will revise the abstract to qualify the normative language and add a dedicated paragraph in the discussion that (i) states the rationale for the chosen forms as tractable approximations and (ii) reports new sensitivity analyses on exponents and normalizations. These analyses will test whether the reported trade-offs, growth patterns, and spontaneous recurrence survive changes in functional form. revision: yes
-
Referee: [Abstract] The resource pressure coefficients (lambdas) are free parameters; without an independent justification or sensitivity analysis showing that the growth patterns and human-RT correlation survive changes in functional form, the normative interpretation risks circularity.
Authors: The lambdas are hyperparameters that set the relative strength of each resource cost. Their specific values were selected so that networks reach high accuracy while still exhibiting measurable resource usage. We acknowledge that independent biological justification for particular lambda values is not provided. We will add a sensitivity section that sweeps lambda values over an order-of-magnitude range and tests alternative cost functional forms; we will show that the core phenomena—resource trade-offs for fixed accuracy, growth in all three dimensions with task complexity, increased recurrence under occlusion, and the model-time/human-RT correlation—remain qualitatively intact. This analysis will be reported in the revised manuscript to reduce the risk of circularity. revision: yes
Circularity Check
No significant circularity; costs explicitly defined and results emerge from joint optimization with external validation
full rationale
The paper defines differentiable cost terms for breadth, depth, and time, then optimizes them jointly with task loss via backpropagation on a recurrent conv net treated as a lattice subset. Emergent behaviors (resource trade-offs, growth with complexity, extra recurrent steps under occlusion, human RT correlation) are simulation outcomes rather than inputs by construction. No equations or self-citations reduce any central claim to a fitted parameter renamed as prediction or to a self-referential definition. The human RT correlation supplies an independent external benchmark. This is a standard normative modeling setup with chosen but transparent functional forms; no load-bearing step collapses to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- resource pressure coefficients (lambdas for breadth, depth, time)
axioms (2)
- standard math Backpropagation can jointly optimize task loss and differentiable resource costs
- domain assumption The recurrent convolutional network can be treated as a finite subset of an infinite lattice without loss of generality for the resource trade-offs
invented entities (1)
-
differentiable cost terms for breadth, depth, and time
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jascha Achterberg, Danyal Akarca, D. J. Strouse, John Duncan, and Duncan E. Astle. Spatially embedded recurrent neural networks reveal widespread links between structural and functional neuroscience findings. Nature Machine Intelligence, 5(12):1369–1381, November 2023. ISSN 2522-5839. doi: 10.1038/ s42256-023-00748-9. URLhttps://www.nature.com/articles/s4...
2023
-
[2]
Predictive coding is a consequence of energy efficiency in recurrent neural networks.Patterns, 3(12), 2022
Abdullahi Ali, Nasir Ahmad, Elgar de Groot, Marcel Antonius Johannes van Gerven, and Tim Christian Kietzmann. Predictive coding is a consequence of energy efficiency in recurrent neural networks.Patterns, 3(12), 2022
2022
-
[3]
Adaptive computation as a new mechanism of dynamic human attention.Psychological Review, 133(3):534, 2026
Mario Belledonne, Eivinas Butkus, Brian J Scholl, and Ilker Yildirim. Adaptive computation as a new mechanism of dynamic human attention.Psychological Review, 133(3):534, 2026
2026
-
[4]
Nicholas M Blauch, Marlene Behrmann, and David C Plaut. A connectivity-constrained computational account of topographic organization in primate high-level visual cortex.Proceedings of the National Academy of Sciences, 119(3):e2112566119, 2022
2022
-
[5]
How attention saves energy in vision.bioRxiv,
Eivinas Butkus, Zhuofan Ying, and Nikolaus Kriegeskorte. How attention saves energy in vision.bioRxiv,
-
[6]
doi: 10.64898/2026.03.18.710397
-
[7]
Beth L. Chen, David H. Hall, and Dmitri B. Chklovskii. Wiring optimization can relate neuronal structure and function.Proceedings of the National Academy of Sciences of the United States of America, 103(12): 4723–4728, March 2006. ISSN 0027-8424. doi: 10.1073/pnas.0506806103
-
[8]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural Ordinary Differential Equations, December 2019. URLhttp://arxiv.org/abs/1806.07366. arXiv:1806.07366 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Wiring optimization in cortical circuits
Dmitri B Chklovskii, Thomas Schikorski, and Charles F Stevens. Wiring optimization in cortical circuits. Neuron, 34(3):341–347, 2002
2002
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255,
-
[11]
doi: 10.1109/CVPR.2009.5206848
-
[12]
A. Aldo Faisal, Luc P. J. Selen, and Daniel M. Wolpert. Noise in the nervous system.Nature Reviews Neuroscience, 9(4):292–303, April 2008. ISSN 1471-003X, 1471-0048. doi: 10.1038/nrn2258. URL https://www.nature.com/articles/nrn2258
-
[13]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. InInternational Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=rJl-b3RcF7
2019
-
[14]
Wichmann
Robert Geirhos, Kristof Meding, and Felix A. Wichmann. Beyond accuracy: quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency.Advances in Neural Information Pro- cessing Systems, 33:13890–13902, 2020. URL https://proceedings.neurips.cc/paper_files/ paper/2020/hash/9f6992966d4c363ea0162a056cb45fe5-Abstract.html
2020
-
[15]
Computational rationality: A converging paradigm for intelligence in brains, minds, and machines.Science, 349(6245):273–278, 2015
Samuel J Gershman, Eric J Horvitz, and Joshua B Tenenbaum. Computational rationality: A converging paradigm for intelligence in brains, minds, and machines.Science, 349(6245):273–278, 2015
2015
-
[16]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Learning both weights and connections for efficient neural network
Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Gar- nett, editors,Advances in Neural Information Processing Systems, volume 28. Curran Asso- ciates, Inc., 2015. URL https://proceedings.neurips.cc/paper_files/paper/2015/file/ ae0eb...
2015
-
[18]
Song Han, Huizi Mao, and William J. Dally. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding, February 2016. URL http://arxiv.org/ abs/1510.00149. arXiv:1510.00149 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 11
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Ho, David Abel, Carlos G
Mark K. Ho, David Abel, Carlos G. Correa, Michael L. Littman, Jonathan D. Cohen, and Thomas L. Griffiths. People construct simplified mental representations to plan.Nature, 606(7912):129–136, June
-
[21]
doi: 10.1038/s41586-022-04743-9
ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-022-04743-9. URL https://www.nature. com/articles/s41586-022-04743-9
-
[22]
Tim C. Kietzmann, Courtney J. Spoerer, Lynn K. A. Sörensen, Radoslaw M. Cichy, Olaf Hauk, and Nikolaus Kriegeskorte. Recurrence is required to capture the representational dynamics of the human visual system.Proceedings of the National Academy of Sciences, 116(43):21854–21863, October 2019. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.1905544116. URL http...
-
[23]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, Ontario, 2009
2009
-
[24]
Communication in neuronal networks.Science, 301(5641): 1870–1874, 2003
Simon B Laughlin and Terrence J Sejnowski. Communication in neuronal networks.Science, 301(5641): 1870–1874, 2003
2003
-
[25]
On the value of model diversity in neuroscience.Nature Reviews Neuroscience, 21(8): 395–396, 2020
Gilles Laurent. On the value of model diversity in neuroscience.Nature Reviews Neuroscience, 21(8): 395–396, 2020
2020
-
[26]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
2015
-
[27]
Optimal brain damage.Advances in neural information processing systems, 2, 1989
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage.Advances in neural information processing systems, 2, 1989
1989
-
[28]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[29]
Pruning Filters for Efficient ConvNets
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning Filters for Efficient ConvNets, March 2017. URLhttp://arxiv.org/abs/1608.08710. arXiv:1608.08710 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.Behavioral and Brain Sciences, 43:e1, 2020
Falk Lieder and Thomas L Griffiths. Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.Behavioral and Brain Sciences, 43:e1, 2020
2020
-
[31]
Jack Lindsey, Samuel A Ocko, Surya Ganguli, and Stephane Deny. A unified theory of early visual represen- tations from retina to cortex through anatomically constrained deep cnns.arXiv preprint arXiv:1901.00945, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[32]
Progressive neural architecture search
Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. InProceedings of the European conference on computer vision (ECCV), pages 19–34, 2018
2018
-
[33]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=S1eYHoC5FX
2019
-
[34]
Learning efficient convolutional networks through network slimming
Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming. InProceedings of the IEEE international conference on computer vision, pages 2736–2744, 2017
2017
-
[35]
DiCarlo, Kalanit Grill-Spector, and Daniel L.K
Eshed Margalit, Hyodong Lee, Dawn Finzi, James J. DiCarlo, Kalanit Grill-Spector, and Daniel L.K. Yamins. A unifying framework for functional organization in early and higher ventral visual cortex. Neuron, 112(14):2435–2451.e7, July 2024. ISSN 08966273. doi: 10.1016/j.neuron.2024.04.018. URL https://linkinghub.elsevier.com/retrieve/pii/S0896627324002794
-
[36]
Human uncertainty makes classification more robust
Joshua C Peterson, Ruairidh M Battleday, Thomas L Griffiths, and Olga Russakovsky. Human uncertainty makes classification more robust. InProceedings of the IEEE/CVF international conference on computer vision, pages 9617–9626, 2019
2019
-
[37]
A behavioral model of rational choice.The quarterly journal of economics, pages 99–118, 1955
Herbert A Simon. A behavioral model of rational choice.The quarterly journal of economics, pages 99–118, 1955
1955
-
[38]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Spoerer, Patrick McClure, and Nikolaus Kriegeskorte
Courtney J. Spoerer, Patrick McClure, and Nikolaus Kriegeskorte. Recurrent Convolutional Neural Networks: A Better Model of Biological Object Recognition.Frontiers in Psychology, 8:1551, September
-
[40]
ISSN 1664-1078. doi: 10.3389/fpsyg.2017.01551. URL https://www.frontiersin.org/ article/10.3389/fpsyg.2017.01551/full. 12
-
[41]
Re- current neural networks can explain flexible trading of speed and accuracy in biological vision.PLOS Computational Biology, 16(10):e1008215, 2020
Courtney J Spoerer, Tim C Kietzmann, Johannes Mehrer, Ian Charest, and Nikolaus Kriegeskorte. Re- current neural networks can explain flexible trading of speed and accuracy in biological vision.PLOS Computational Biology, 16(10):e1008215, 2020
2020
-
[42]
MIT Press, 2015
Peter Sterling and Simon Laughlin.Principles of neural design. MIT Press, 2015
2015
-
[43]
Speed of processing in the human visual system.Nature, 381(6582):520–522, 1996
Simon Thorpe, Denis Fize, and Catherine Marlot. Speed of processing in the human visual system.Nature, 381(6582):520–522, 1996
1996
-
[44]
One and done? Optimal decisions from very few samples.Cognitive science, 38(4):599–637, 2014
Edward Vul, Noah Goodman, Thomas L Griffiths, and Joshua B Tenenbaum. One and done? Optimal decisions from very few samples.Cognitive science, 38(4):599–637, 2014
2014
-
[45]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. InEuropean conference on computer vision, pages 818–833. Springer, 2014. 13 A Compute Each model was trained on a single GPU for approximately 2.5 hours, requiring roughly 3.3 GB of GPU memory at batch size 128. Training was conducted on a university cluster with a mix ...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.