Transformer Field Theory: A Response-Theoretic Approach to Mechanistic Interpretability
Pith reviewed 2026-06-30 11:56 UTC · model grok-4.3
The pith
Treating the residual stream as a Transformer field turns activation patching into localized source insertion whose first-order responses are predicted by sensitivities and Green functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the residual stream of a fixed forward pass as a Transformer field over layer depth and token position, patching is formulated as localized source insertion; first-order sensitivity fields then predict patch effects, Green functions describe downstream propagation, and the framework yields practical objects for organizing experiments and reduced response descriptions.
What carries the argument
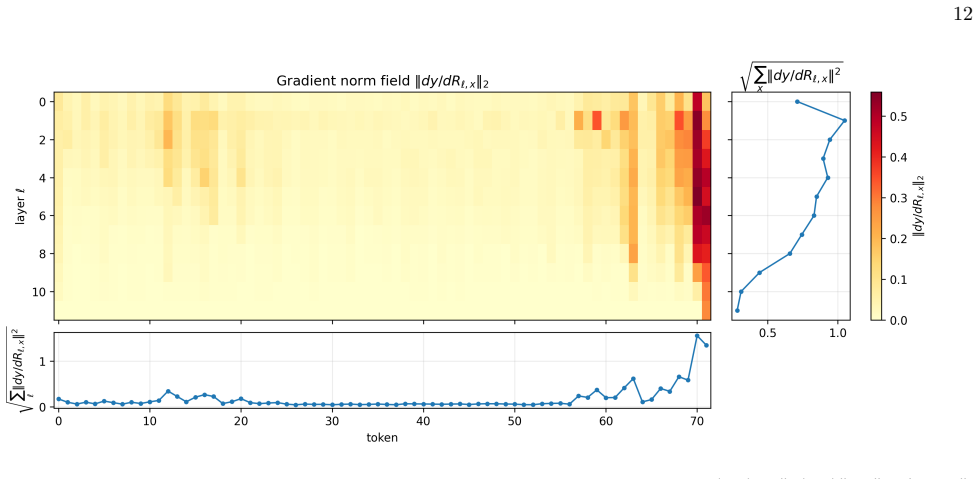
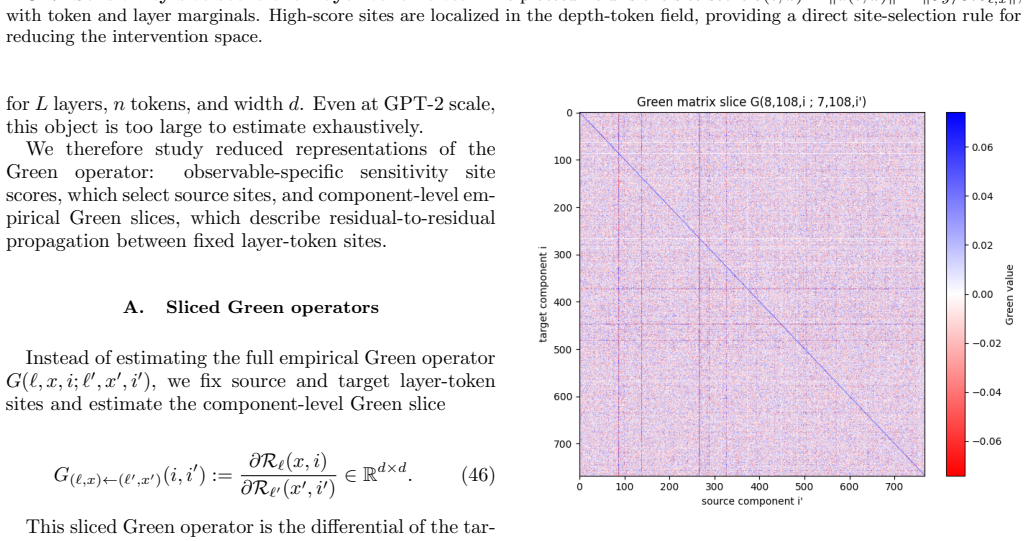
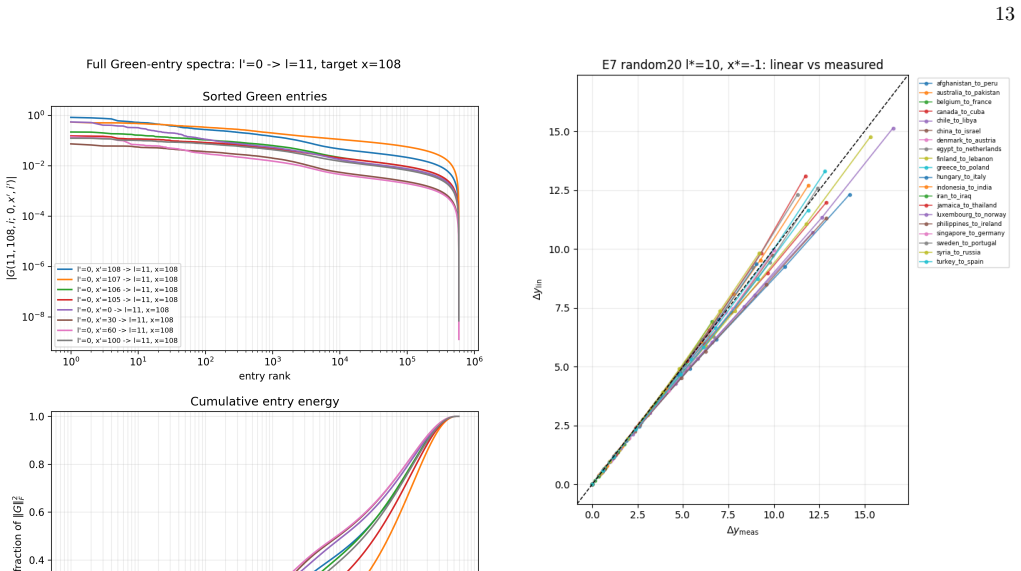
The Transformer field, defined as the residual stream over layer depth and token position, with patching treated as localized source insertion and first-order response theory applied to compute sensitivities and Green functions.
If this is right
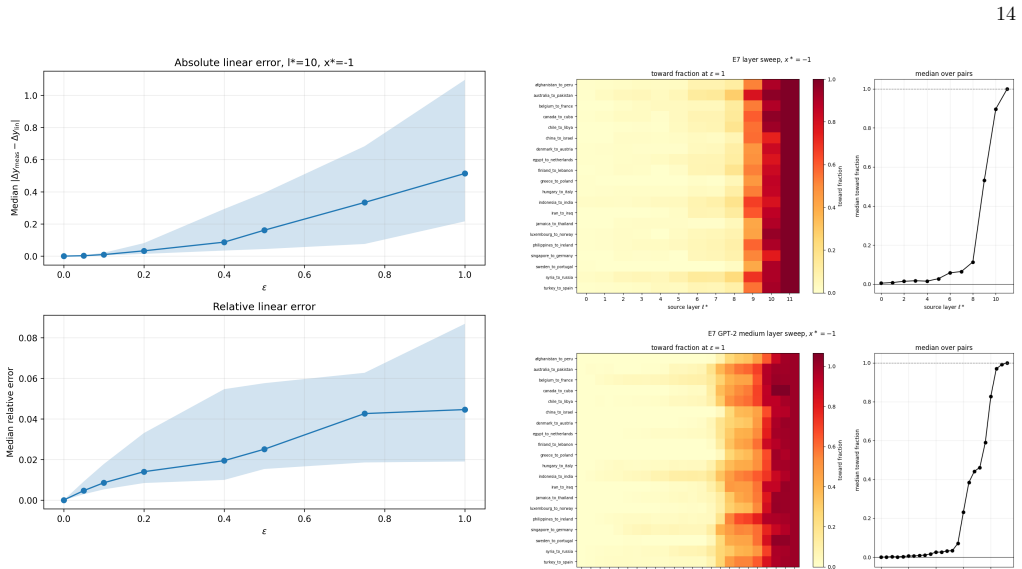
- Localized Transformer-field interventions exhibit a bounded local linear regime.
- First-order sensitivities predict patch effects across layer-token sites.
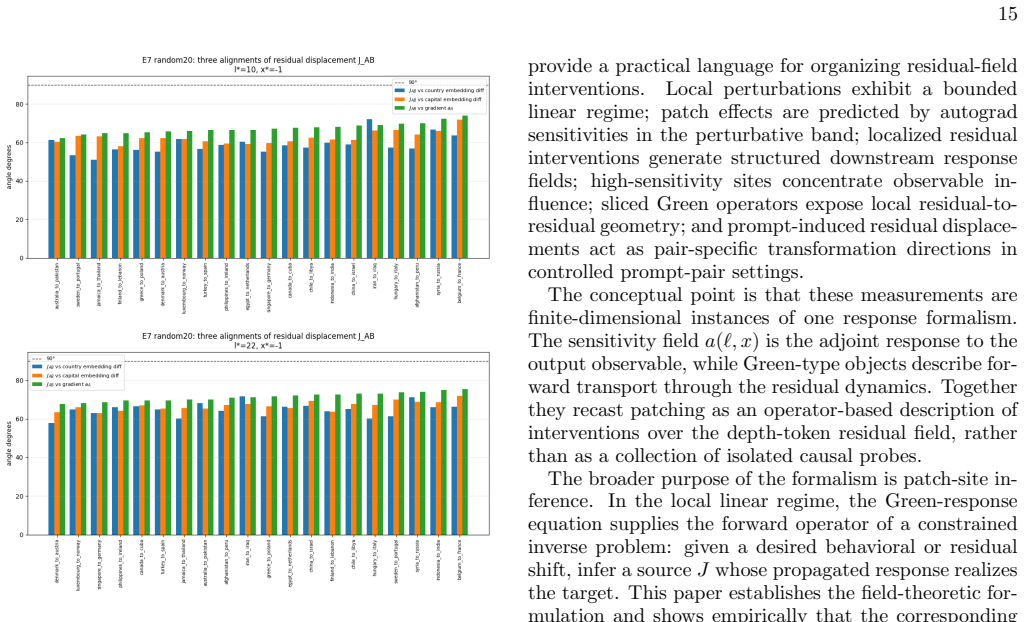
- Localized sources generate structured anisotropic Transformer-field propagation.
- High-sensitivity sites and sliced Green operators provide reduced response descriptions.
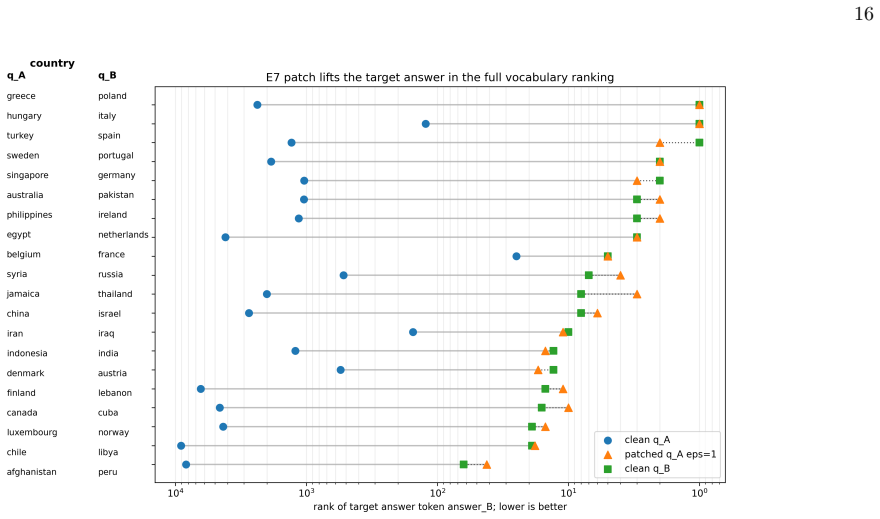
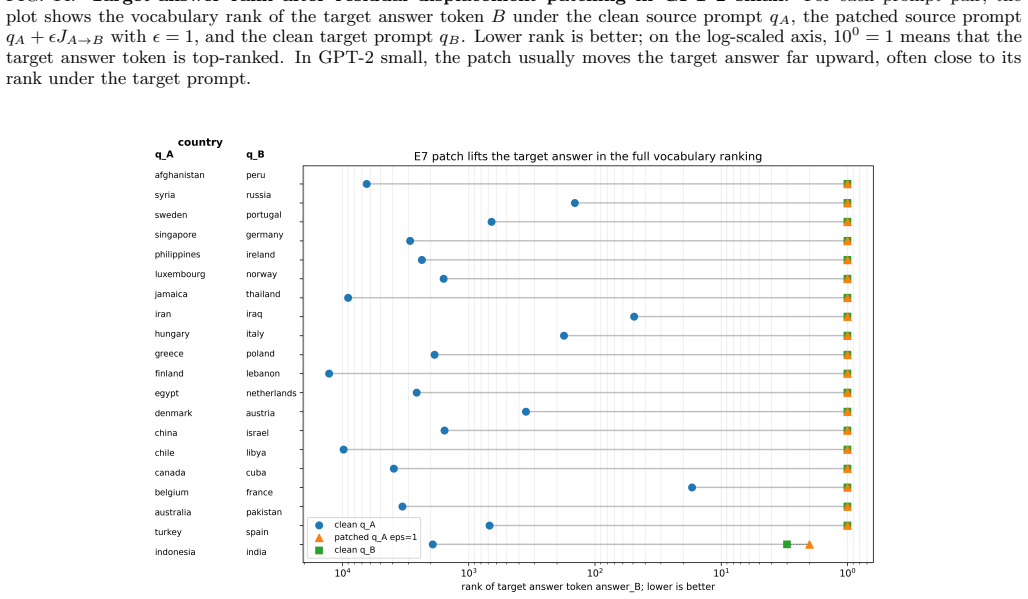
- Prompt-induced Transformer-field displacements partially transfer answer behavior.
Where Pith is reading between the lines
- This framework could enable systematic selection of patch sites by solving the adjoint inverse problem instead of exhaustive search.
- The partial transfer of prompt-induced displacements points toward possible uses in targeted model editing across related prompts.
- Anisotropic propagation implies that intervention effects concentrate along specific layer-token paths rather than spreading uniformly.
- The linear regime bound may shift in larger models, offering a testable way to locate where higher-order response terms become necessary.
Load-bearing premise
The residual stream of a fixed forward pass can be treated as a Transformer field over layer depth and token position such that patching corresponds to localized source insertion and first-order response theory applies.
What would settle it
A direct comparison showing that measured patch effects deviate substantially from predictions based on first-order sensitivity fields in the tested GPT-2 models would falsify the core response-theoretic predictions.
Figures

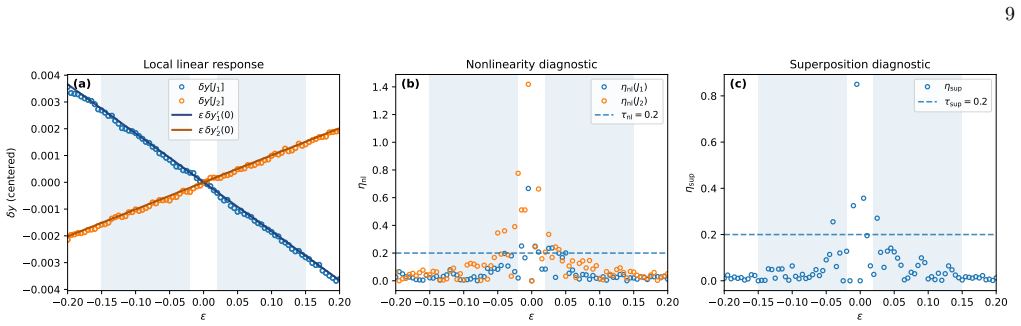
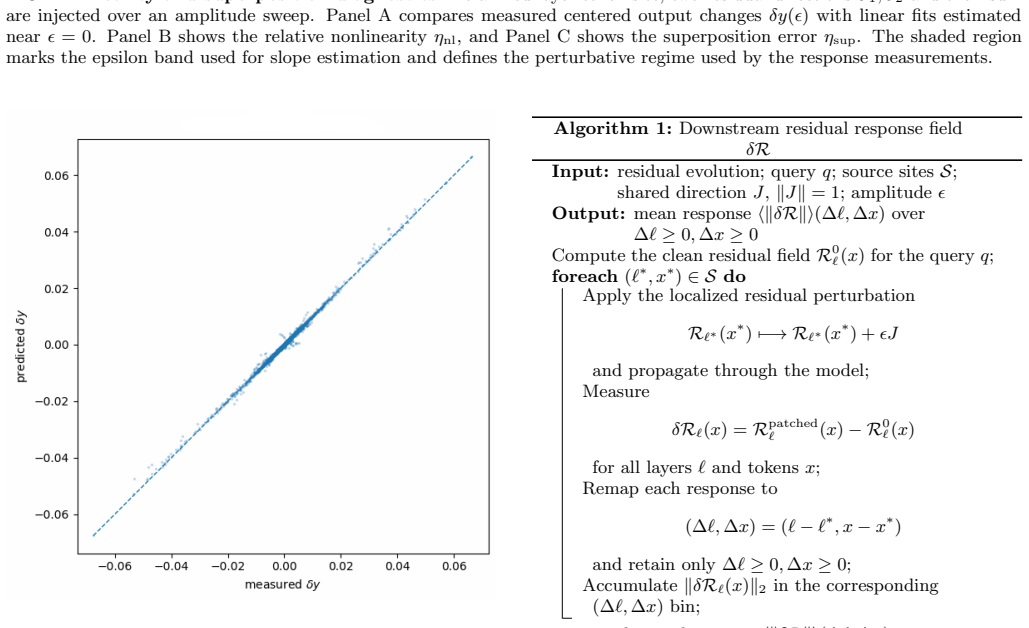
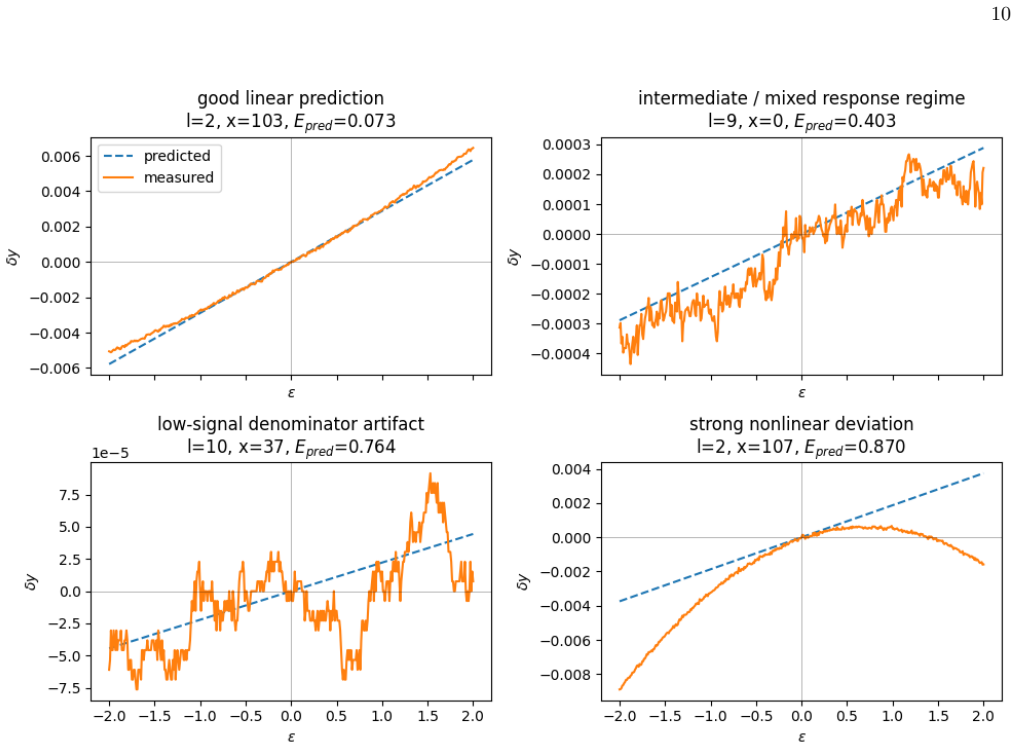
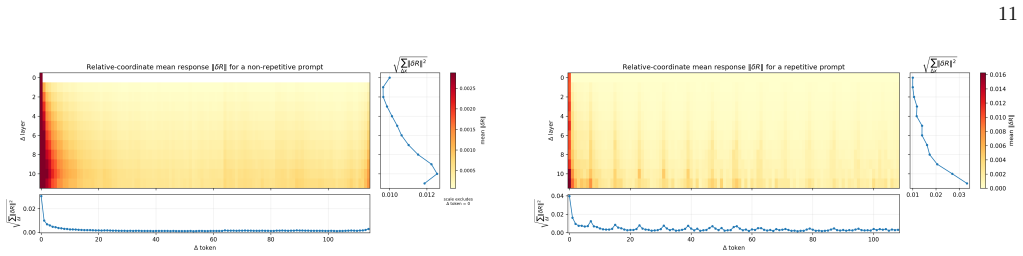
read the original abstract
Mechanistic interpretability often studies Transformer behavior by intervening on internal activations through activation patching, causal tracing, path patching, and steering directions. This paper develops Transformer Field Theory: a response-theoretic framework in which the residual stream of a fixed forward pass is treated as a Transformer field over layer depth and token position. In this formulation, patching becomes a localized source insertion into the Transformer field, first-order sensitivity fields predict patch effects, Green functions describe downstream propagation, and patch selection is posed as an adjoint inverse problem. Empirically, we test the theory's forward response objects in GPT-2-style autoregressive Transformers. Localized Transformer-field interventions exhibit a bounded local linear regime; first-order sensitivities predict patch effects across layer-token sites; localized sources generate structured anisotropic Transformer-field propagation; high-sensitivity sites and sliced Green operators provide reduced response descriptions; and prompt-induced Transformer-field displacements partially transfer answer behavior. These results establish sensitivities, Transformer-field responses, and sliced Green operators as practical objects for organizing patching experiments, while providing the forward mathematical basis for patch-site inference and cross-scale response transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Transformer Field Theory, a response-theoretic framework for mechanistic interpretability of Transformers. It treats the residual stream of a fixed forward pass as a field over layer depth and token position. Interventions such as activation patching are modeled as localized source insertions, with first-order sensitivity fields predicting patch effects and Green functions describing downstream propagation. Patch selection is formulated as an adjoint inverse problem. Empirical tests on GPT-2-style autoregressive models report a bounded local linear regime, predictive accuracy of first-order sensitivities across layer-token sites, structured anisotropic propagation from localized sources, utility of high-sensitivity sites and sliced Green operators for reduced descriptions, and partial transfer of answer behavior via prompt-induced field displacements.
Significance. If the central claims hold, the work supplies a forward mathematical basis that could systematize patching experiments through sensitivities, response fields, and Green operators, while enabling reduced descriptions and inverse problems for site selection. The empirical results on GPT-2 models, including demonstration of a linear regime and predictive sensitivities, constitute a concrete contribution. The framework introduces new objects (Transformer field, sliced Green operators) rather than re-deriving fitted quantities, which is a strength when the linear approximation is shown to be practically relevant.
major comments (1)
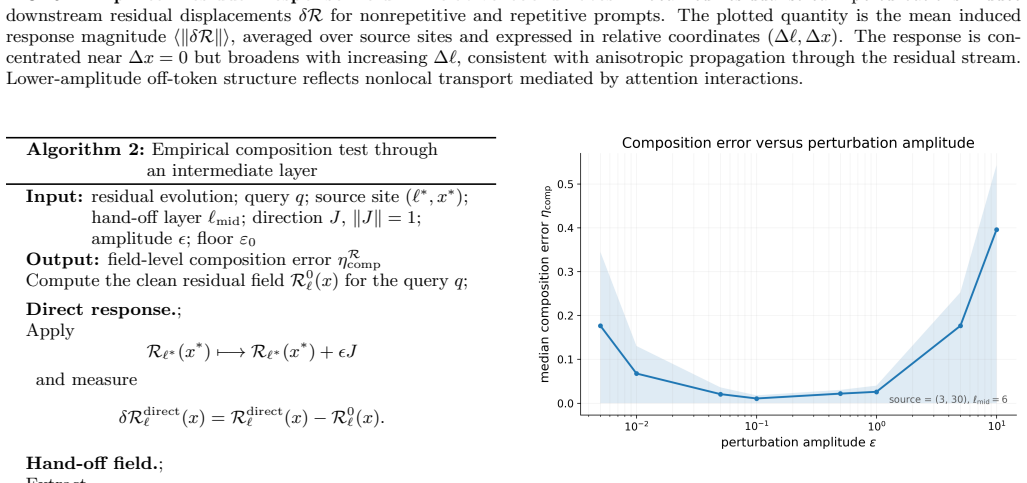
- [Abstract] Abstract (empirical claims paragraph): The central assertion that 'localized Transformer-field interventions exhibit a bounded local linear regime' and that 'first-order sensitivities predict patch effects' is load-bearing for the framework's utility. No quantitative characterization is given of the regime boundaries (e.g., perturbation magnitude relative to activation norms or to the scale of standard activation-patching substitutions), leaving open whether the regime is wide enough for the claimed predictive objects to apply to typical experimental interventions.
minor comments (2)
- [Introduction / Modeling] The distinction between the newly introduced 'Transformer field' and the standard residual-stream representation should be made explicit in the modeling section to clarify what additional structure is being imposed.
- [Theoretical Framework] Notation for the Green operators and adjoint inverse problem should include a brief reminder of the underlying linear operator to aid readers unfamiliar with response theory.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that quantitative bounds on the linear regime are important for assessing applicability and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract (empirical claims paragraph): The central assertion that 'localized Transformer-field interventions exhibit a bounded local linear regime' and that 'first-order sensitivities predict patch effects' is load-bearing for the framework's utility. No quantitative characterization is given of the regime boundaries (e.g., perturbation magnitude relative to activation norms or to the scale of standard activation-patching substitutions), leaving open whether the regime is wide enough for the claimed predictive objects to apply to typical experimental interventions.
Authors: We agree that the abstract would benefit from explicit quantitative characterization of the regime boundaries to support the load-bearing claims. The main text reports empirical evidence for a bounded linear regime in GPT-2 models (Section 4), including tests of first-order sensitivity predictions, but does not supply the requested metrics (e.g., perturbation size relative to activation norms) in the abstract itself. In revision we will update the abstract to include a concise quantitative statement drawn from the experiments, such as the range of source magnitudes (relative to activation scale) over which first-order predictions remain accurate within a stated error tolerance. This will directly address applicability to standard patching interventions. revision: yes
Circularity Check
No significant circularity; framework introduces independent response objects
full rationale
The paper defines the residual stream as a Transformer field and introduces first-order sensitivity fields and Green operators as derived quantities from the model's forward pass. These are then used to predict patch effects, with empirical tests on GPT-2 models. No step reduces a claimed prediction to a fitted parameter from the same data by construction, nor relies on load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results. The central modeling assumptions (bounded linear regime, field treatment of activations) are stated explicitly and tested against external patching interventions rather than being tautological. The derivation chain remains self-contained with independent mathematical content.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Transformer field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,” inAdvances in Neural Information Processing Systems (NeurIPS)30(2017), arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, et al
C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter, “Zoom In: An Introduction to Circuits,” Distill 5, e00024.001 (2020). 10.23915/distill.00024.001
-
[3]
A Mathematical Framework for Transformer Circuits,
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerlyet al., “A Mathematical Framework for Transformer Circuits,” Transformer Circuits Thread (2021)
2021
-
[4]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
K. R. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt, “Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2 Small,” inInternational Conference on Learning Representations (ICLR)(2023), arXiv:2211.00593. 10.48550/arXiv.2211.00593
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.00593 2023
-
[5]
Localizing Model Behavior with Path Patching
N. Goldowsky-Dill, C. MacLeod, L. Sato, and A. Arora, “Localizing Model Behavior with Path Patching,” arXiv:2304.05969 (2023). 10.48550/arXiv.2304.05969
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.05969 2023
-
[6]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
F. Zhang and N. Nanda, “Towards Best Practices of Activation Patching in Language Models: Metrics and Methods,” arXiv:2309.16042 (2023). 10.48550/arXiv.2309.16042
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16042 2023
-
[7]
Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses,
L. Chan, A. Garriga-Alonso, N. Goldowsky-Dill, R. Greenblatt, J. Nitishinskaya, A. Radhakrishnan, B. Shlegeris, and N. Thomas, “Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses,” AI Alignment Forum (2022)
2022
-
[8]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016), arXiv:1512.03385. 10.1109/CVPR.2016.90
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr.2016.90 2016
-
[9]
Neural Ordinary Differential Equations
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud, “Neural Ordinary Differential Equations,” inAdvances in Neural Information Processing Systems (NeurIPS)31, pp. 6571–6583 (2018), arXiv:1806.07366. 10.48550/arXiv.1806.07366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.07366 2018
-
[10]
R. Kubo, “Statistical-Mechanical Theory of Irreversible Processes. I. General Theory and Simple Applications to Magnetic and Conduction Problems,” Journal of the Physical Society of Japan12, 570–586 (1957). 10.1143/JPSJ.12.570
-
[11]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
H. Cunningham, A. Ewart, L. Riggs Smith, R. Huben, and L. Sharkey, “Sparse Autoencoders Find Highly Interpretable Features in Language Models,” arXiv:2309.08600 (2023). 10.48550/arXiv.2309.08600
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600 2023
-
[12]
Scaling and evaluating sparse autoencoders
L. Gao, T. Dupr´ e la Tour, H. Tillman, G. Goh, R. Troll, A. Radford, I. Sutskever, J. Leike, and J. Wu, “Scaling and Evaluating Sparse Autoencoders,” arXiv:2406.04093 (2024). 10.48550/arXiv.2406.04093
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.04093 2024
-
[13]
Attribution Patching: Activation Patching at Industrial Scale,
N. Nanda, “Attribution Patching: Activation Patching at Industrial Scale,” neelnanda.io (2023)
2023
-
[14]
Attribution Patching Outperforms Automated Circuit Discovery,
A. Syed, C. Rager, and A. Conmy, “Attribution Patching Outperforms Automated Circuit Discovery,” inProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp. 407–416 (2024), arXiv:2310.10348. 10.18653/v1/2024.blackboxnlp-1.25
-
[15]
J. Kram´ ar, T. Lieberum, R. Shah, and N. Nanda, “AtP*: An Efficient and Scalable Method for Localizing LLM Behaviour to Components,” arXiv:2403.00745 (2024). 10.48550/arXiv.2403.00745
-
[16]
Statistical Dynamics of Classical Systems,
P. C. Martin, E. D. Siggia, and H. A. Rose, “Statistical Dynamics of Classical Systems,” Physical Review A8, 423–437 (1973). 10.1103/PhysRevA.8.423
-
[17]
H. K. Janssen, “On a Lagrangean for Classical Field Dynamics and Renormalization Group Calculations of Dynamical Critical Properties,” Zeitschrift f¨ ur Physik B23, 377–380 (1976). 10.1007/BF01316547
-
[18]
Techniques de renormalisation de la th´ eorie des champs et dynamique des ph´ enom` enes critiques,
C. De Dominicis, “Techniques de renormalisation de la th´ eorie des champs et dynamique des ph´ enom` enes critiques,” Journal de Physique Colloques37, C1-247–C1-253 (1976). 10.1051/jphyscol:1976138
-
[19]
L. S. Pontryagin, V. G. Boltyanskii, R. V. Gamkrelidze, and E. F. Mishchenko,The Mathematical Theory of Optimal Processes(Interscience, New York, 1962)
1962
-
[20]
In-Context Learning Creates Task Vectors,
R. Hendel, M. Geva, and A. Globerson, “In-Context Learning Creates Task Vectors,” inFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 9318–9333 (2023), arXiv:2310.15916. 10.18653/v1/2023.findings-emnlp.624
-
[21]
Function Vectors in Large Language Models,
E. Todd, M. L. Li, A. S. Sharma, A. Mueller, B. C. Wallace, and D. Bau, “Function Vectors in Large Language Models,” inInternational Conference on Learning Representations (ICLR)(2024), arXiv:2310.15213. 10.48550/arXiv.2310.15213
-
[22]
Steering Language Models With Activation Engineering
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid, “Steering Language Models With Activation Engineering,” arXiv:2308.10248 (2023). 10.48550/arXiv.2308.10248
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248 2023
-
[23]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowskiet al., “Repre- sentation Engineering: A Top-Down Approach to AI Transparency,” arXiv:2310.01405 (2023). 10.48550/arXiv.2310.01405
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405 2023
-
[24]
The Platonic Representation Hypothesis
M. Huh, B. Cheung, T. Wang, and P. Isola, “Position: The Platonic Representation Hypothesis,” inProceedings of the 41st International Conference on Machine Learning (ICML), PMLR235, 20617–20642 (2024), arXiv:2405.07987. 10.48550/arXiv.2405.07987
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.07987 2024
-
[25]
Understanding image representations by measuring their equivariance and equivalence
K. Lenc and A. Vedaldi, “Understanding Image Representations by Measuring Their Equivariance and Equivalence,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 991–999 (2015), arXiv:1411.5908. 10.48550/arXiv.1411.5908
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1411.5908 2015
-
[26]
Revisiting Model Stitching to Compare Neural Representations,
Y. Bansal, P. Nakkiran, and B. Barak, “Revisiting Model Stitching to Compare Neural Representations,” inAdvances in Neural Information Processing Systems (NeurIPS)34(2021), arXiv:2106.07682. 10.48550/arXiv.2106.07682
-
[27]
Gromov–Wasserstein Distances and the Metric Approach to Object Matching,
F. M´ emoli, “Gromov–Wasserstein Distances and the Metric Approach to Object Matching,” Foundations of Computational Mathematics11, 417–487 (2011). 10.1007/s10208-011-9093-5
-
[28]
Gromov–Wasserstein Averaging of Kernel and Distance Matrices,
G. Peyr´ e, M. Cuturi, and J. Solomon, “Gromov–Wasserstein Averaging of Kernel and Distance Matrices,” inProceedings of the 33rd International Conference on Machine Learning (ICML), PMLR48, 2664–2672 (2016)
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.