Inference Time Optimization with Confidence Dynamics
Pith reviewed 2026-06-30 11:09 UTC · model grok-4.3
The pith
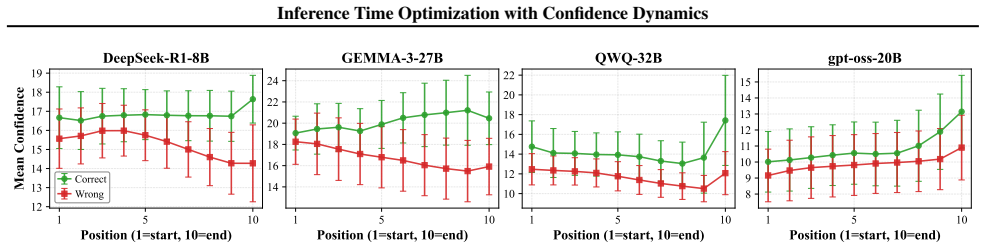
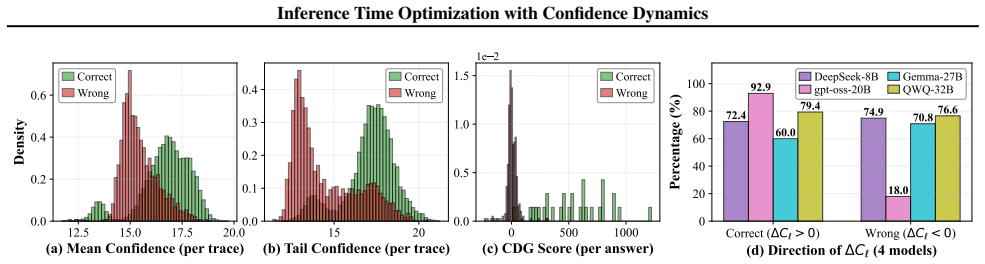
LLM reasoning traces that reach correct answers tend to gain confidence over steps while wrong traces lose it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
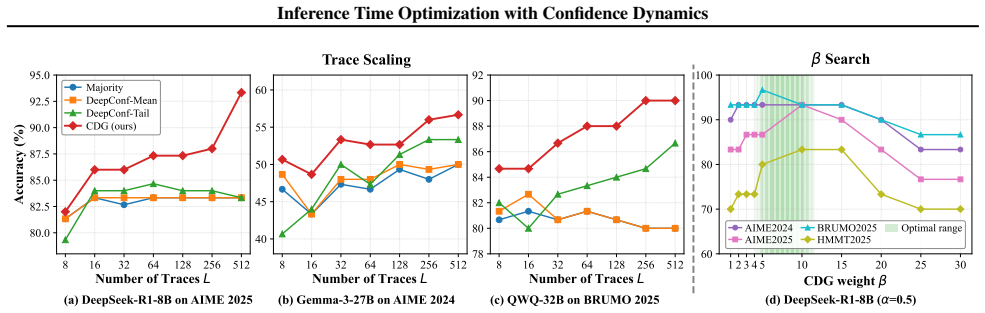
Correct answer traces tend to exhibit confidence improvement over time (positive confidence gain), while incorrect traces show attenuated or declining confidence as reasoning proceeds. The authors introduce Confidence Dynamic Gain (CDG) based voting that incorporates the full trajectory of confidence evolution along the reasoning chain and report substantial gains over baselines on AIME24/25, HMMT25, and BRUMO25 across four model families, supported by theoretical analysis of the observed pattern.
What carries the argument
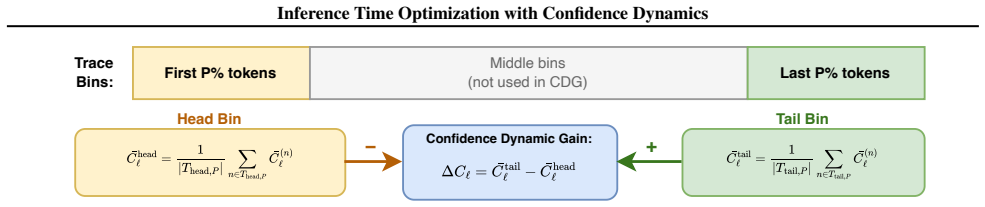
Confidence Dynamic Gain (CDG) voting, which scores each sampled reasoning trace by the net change in model confidence across its steps and uses that score for final answer selection.
If this is right
- CDG voting improves answer selection accuracy when multiple reasoning traces are sampled at inference time.
- The same confidence-trajectory signal works across different open-source model families on mathematical reasoning tasks.
- Using the direction of confidence change supplies a stronger discriminative signal than endpoint confidence alone.
- The method requires no model retraining and can be added to existing sampling pipelines.
Where Pith is reading between the lines
- If the pattern generalizes, prompts could be designed to make confidence trajectories even steeper for easier filtering.
- The same dynamic might appear in non-mathematical domains such as code or scientific reasoning and could be tested directly.
- CDG could be combined with existing techniques like majority voting to produce hybrid selection rules.
Load-bearing premise
The model's reported confidence scores give a reliable, roughly monotonic signal of whether the current reasoning path is heading toward a correct answer.
What would settle it
A large set of examples in which many correct final answers come from trajectories whose confidence decreases or many incorrect answers come from trajectories whose confidence increases would falsify the reported pattern.
Figures
read the original abstract
Inference time optimization techniques, such as repeated sampling, have significantly advanced the reasoning capabilities of Large Language Models (LLMs). However, the critical role of model uncertainty remains largely underexplored in these optimization strategies. In this paper, we investigate the dynamics of confidence along reasoning trajectories and for first time reveal a surprising and unique pattern: correct answer traces tend to exhibit confidence improvement over time (positive confidence gain), while incorrect traces show attenuated or declining confidence as reasoning proceeds. Based on this observation, we propose Confidence Dynamic Gain (CDG) based voting, which incorporates how the confidence trajectory of the response evolves along the reasoning chain. Experiments across four open-source architectures (DeepSeek-R1, gpt-oss, Gemma-3, Qwen-QwQ) on the AIME24/25, HMMT25, and BRUMO25 benchmarks demonstrate that CDG yields a significant performance boost over baselines. These results demonstrate that our method provides a robust discriminative signal for improving answer selection in LLM reasoning. We also provide theoretical insights for this phenomenon. Code will be released at https://github.com/Accenture/CDG.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that correct LLM reasoning traces exhibit positive confidence gain over time while incorrect traces show attenuated or declining confidence; based on this pattern it introduces Confidence Dynamic Gain (CDG) voting that incorporates the evolution of confidence along the reasoning chain, reports significant gains over baselines on AIME24/25, HMMT25 and BRUMO25 across four models (DeepSeek-R1, gpt-oss, Gemma-3, Qwen-QwQ), and supplies theoretical insights.
Significance. If the claimed pattern is robust and the CDG method generalizes beyond the reported benchmarks, the work would supply a lightweight, training-free inference-time signal for answer selection that exploits internal model uncertainty rather than external verification. The planned code release would strengthen reproducibility.
major comments (2)
- [Abstract] Abstract: the central empirical claim (positive vs. declining confidence trajectories) and the performance gains of CDG voting cannot be evaluated because the manuscript provides no description of how token- or sequence-level confidence is extracted, no exact voting formula, and no statistical tests or controls for multiple comparisons across models and benchmarks.
- [Abstract] Abstract: the load-bearing assumption that reported confidence scores supply a reliable monotonic signal of trajectory correctness is not supported by any calibration analysis, ablation on superficial factors (length, formatting), or comparison against known poor calibration of LLMs on reasoning tasks.
minor comments (1)
- [Abstract] Abstract: 'for first time' should read 'for the first time'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (positive vs. declining confidence trajectories) and the performance gains of CDG voting cannot be evaluated because the manuscript provides no description of how token- or sequence-level confidence is extracted, no exact voting formula, and no statistical tests or controls for multiple comparisons across models and benchmarks.
Authors: The referee correctly identifies that the abstract (and, per the comment, the manuscript) omits these implementation details. We will revise the abstract to include a brief description of confidence extraction (sequence-level average log-probability) and the CDG voting formula. We will also add statistical significance tests with multiple-comparison corrections to the experimental results. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that reported confidence scores supply a reliable monotonic signal of trajectory correctness is not supported by any calibration analysis, ablation on superficial factors (length, formatting), or comparison against known poor calibration of LLMs on reasoning tasks.
Authors: This is a fair criticism; the current manuscript does not contain calibration analysis, length/format ablations, or explicit discussion of LLM calibration literature. We will add a dedicated subsection with these elements in the revision. revision: yes
Circularity Check
No significant circularity; empirical observation drives method
full rationale
The paper reports an empirical pattern in confidence trajectories from LLM reasoning traces on benchmarks, then defines CDG voting from that observed pattern and validates via experiments. No equations or claims reduce the 'prediction' or central result to a fitted parameter, self-definition, or self-citation chain by construction. The theoretical insights section (if present) is not shown to import uniqueness or ansatz from prior self-work in a load-bearing way. This is a standard non-circular empirical workflow.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., et al. 9 Inference Time Optimization with Confidence Dynamics gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2410.13284 (2024)
Chuang, Y .-N., Sarma, P. K., Gopalan, P., Boccio, J., Bolouki, S., Hu, X., and Zhou, H. Learning to route llms with confidence tokens.arXiv preprint arXiv:2410.13284,
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://goo. gle/Gemma3Report. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Han, J., Li, T., Chen, S., Shi, J., Wang, X., Yue, G., Liang, J., Lin, X., Wen, L., Chen, Z., et al. Mind the generation process: Fine-grained confidence estimation during llm generation.arXiv preprint arXiv:2508.12040,
-
[7]
Kang, S., Kim, J., Kim, J., and Hwang, S. J. See what you are told: Visual attention sink in large multimodal models. arXiv preprint arXiv:2503.03321, 2025a. Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty.arXiv preprint arXiv:2502.18581, 2025b. Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Be...
-
[8]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al. Gated atten- tion for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseek- math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Self-Attention with Relative Position Representations
Shaw, P., Uszkoreit, J., and Vaswani, A. Self-attention with relative position representations.arXiv preprint arXiv:1803.02155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Su, Z. and Yuan, K. Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantiza- tion for llms.arXiv preprint arXiv:2508.04257,
-
[13]
Solving math word problems with process- and outcome-based feedback
Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solv- ing math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Ranked voting based self-consistency of large language models.arXiv preprint arXiv:2505.10772,
Wang, W., Wang, Y ., and Huang, H. Ranked voting based self-consistency of large language models.arXiv preprint arXiv:2505.10772,
-
[15]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
10 Inference Time Optimization with Confidence Dynamics Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Efficient Streaming Language Models with Attention Sinks
URLhttps://x.ai/grok. Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
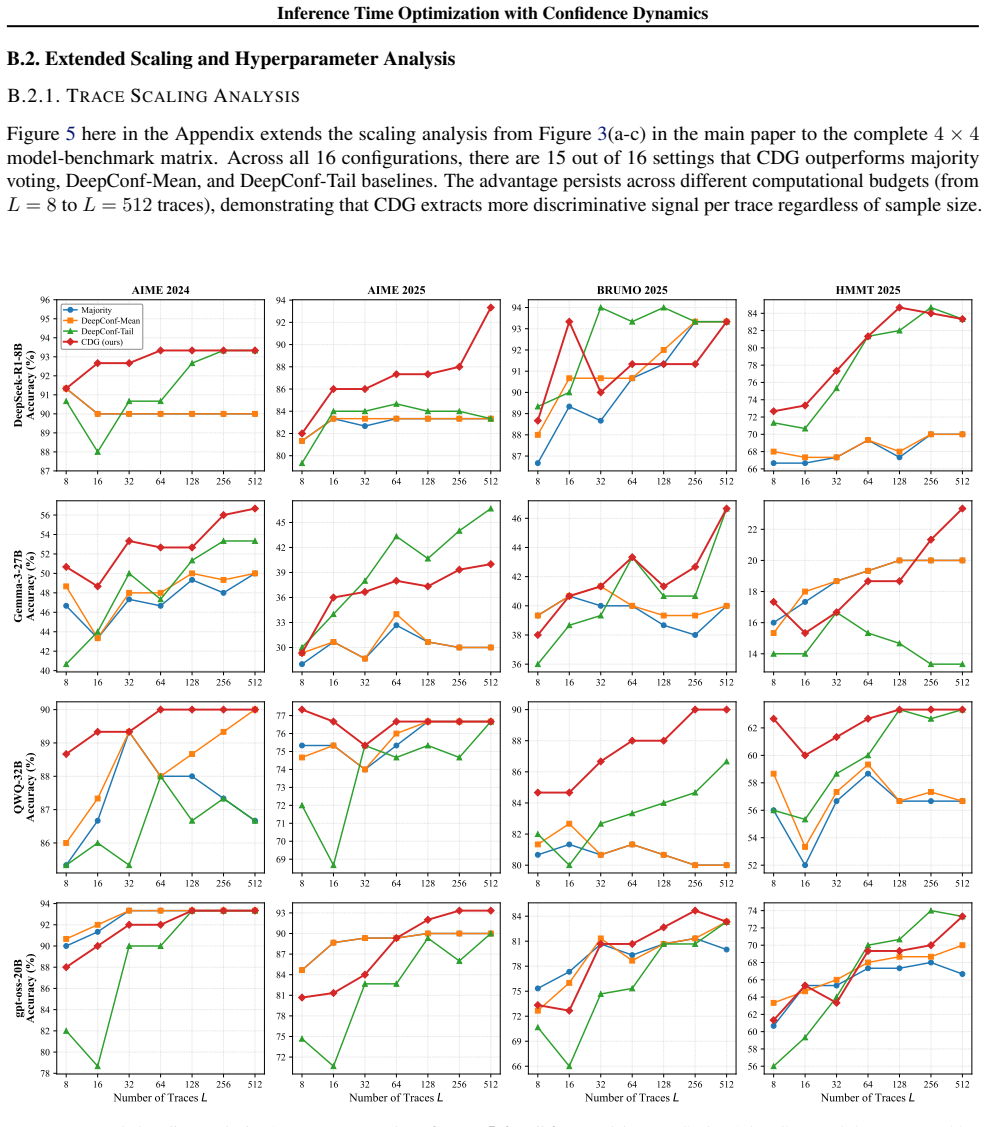
Extended Scaling and Hyperparameter Analysis B.2.1
Model Dataset CDG No Start Drop DeepSeek AIME’2493.390.0 -3.3 AIME’2593.383.3 -10.0 BRUMO’2593.393.3 0.0 HMMT’2583.370.0 -13.3 Avg90.884.2 -6.6 Gemma AIME’2456.750.0 -6.7 AIME’2540.030.0 -10.0 BRUMO’2546.746.7 0.0 HMMT’2523.320.0 -3.3 Avg41.736.7 -5.0 QwQ AIME’2490.090.0 0.0 AIME’2576.776.7 0.0 BRUMO’2590.080.0 -10.0 HMMT’2563.356.7 -6.6 Avg80.075.8 -4.2 ...
2024
-
[19]
Best result in each row is inbold
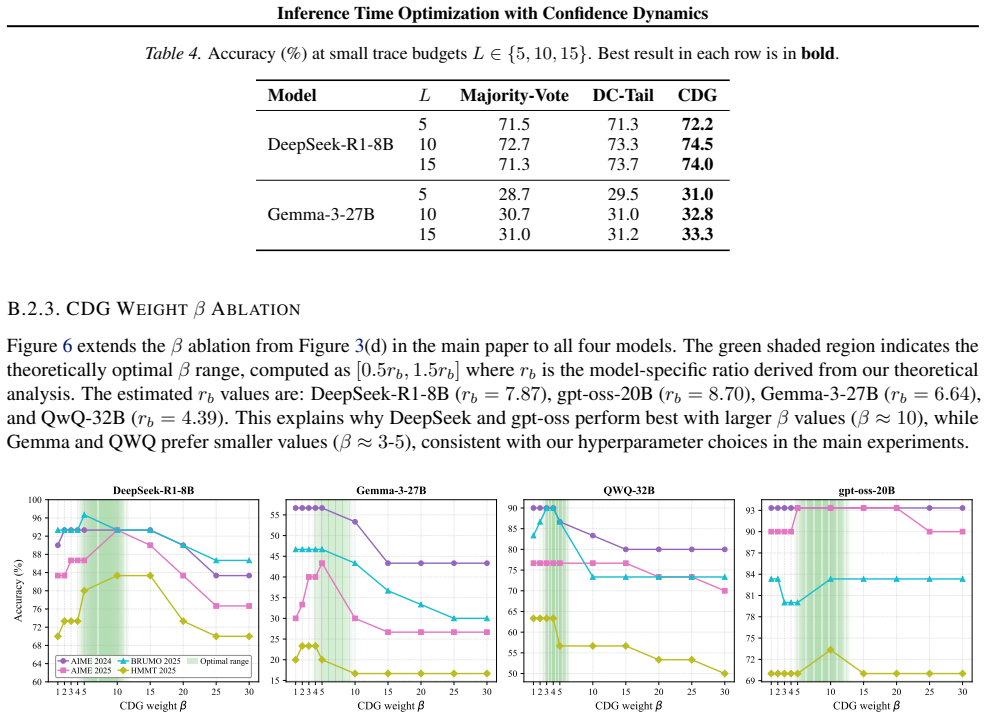
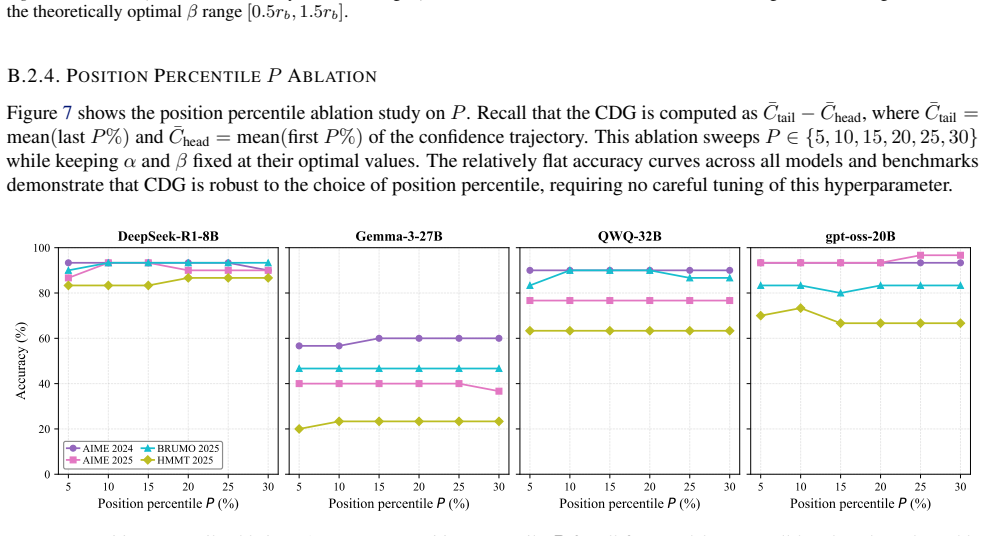
17 Inference Time Optimization with Confidence Dynamics Table 4.Accuracy (%) at small trace budgetsL∈ {5,10,15}. Best result in each row is inbold. ModelLMajority-Vote DC-Tail CDG DeepSeek-R1-8B 5 71.5 71.372.2 10 72.7 73.374.5 15 71.3 73.774.0 Gemma-3-27B 5 28.7 29.531.0 10 30.7 31.032.8 15 31.0 31.233.3 B.2.3. CDG WEIGHTβABLATION Figure 6 extends the β ...
2024
-
[20]
Against the stronger baseline DeepConf-Tail, CDG wins15of22disagreements (68%)
That is, conditional on disagreement, CDG selects the right answer 91% of the time, indicating that the gain is concentrated on the questions for which the choice of voting rule actually matters. Against the stronger baseline DeepConf-Tail, CDG wins15of22disagreements (68%). 19 Inference Time Optimization with Confidence Dynamics Table 6.Statistical signi...
2024
-
[21]
Majority
with DeepSeek-R1-8B (DeepSeek-AI, 2025). Best result inbold. DC-Mean/DC-Tail denote DeepConf-Mean/Tail with top10% filtering (Fu et al., 2025); “Majority” is Majority V ote (Self-Consistency) (Wang et al., 2022). Majority DC-Mean DC-Tail CDG (ours) 68.2 68.7 70.772.2 20 Inference Time Optimization with Confidence Dynamics C. Implementation Details C.1. Sa...
2025
-
[22]
• HMMT 2025(HMMT, 2025): Harvard-MIT Mathematics Tournament problems from February
2025
-
[23]
• BRUMO 2025(Brumo, 2025): Bulgarian Mathematical Olympiad problems from
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.