CausalFlow: Causal Attribution and Counterfactual Repair for LLM Agent Failures
Pith reviewed 2026-06-29 22:46 UTC · model grok-4.3
The pith
Step-level counterfactual interventions on LLM agent execution traces identify failure causes and generate minimal repairs that flip outcomes to success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
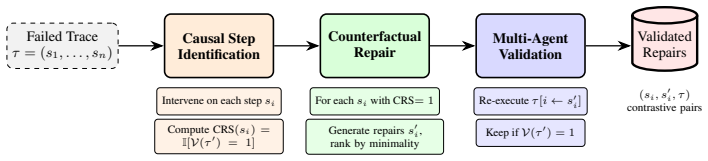
CausalFlow models execution traces as sequential chains of dependent steps and computes Causal Responsibility Scores (CRS) via step-level counterfactual intervention to identify failure-inducing steps. For these steps, it generates minimally edited repairs that flip the final outcome to success, producing validated contrastive pairs of the form (wrong step, corrected step). This supports two uses: targeted test-time repair that recovers from failures with minimal behavioral drift, and training-time supervision suitable for offline preference optimization or reward modeling. Across four benchmarks, it converts failed executions into validated minimal repairs with high minimality and causal-co
What carries the argument
Causal Responsibility Scores (CRS) computed via step-level counterfactual intervention on execution traces, which isolate failure-inducing steps and guide generation of minimally edited repairs.
If this is right
- Targeted test-time repair recovers from failures with minimal behavioral drift.
- Training-time supervision is suitable for offline preference optimization or reward modeling.
- Failed executions convert into validated minimal repairs with high minimality and causal-consensus scores.
- Causal attribution is necessary for reliable improvement across diverse agent tasks.
- The method outperforms heuristic refinement in complex retrieval settings while producing more localized repairs.
Where Pith is reading between the lines
- The contrastive pairs generated could reduce the volume of human feedback needed for agent training by focusing on causally relevant errors.
- Real-time CRS computation during agent runs might enable self-correcting behavior without separate repair modules.
- The approach could transfer to sequential planning in non-LLM systems such as robotic task execution.
- Automated generation of minimal repairs might support iterative improvement loops where agents learn from their own corrected traces.
Load-bearing premise
That step-level counterfactual interventions on execution traces can reliably isolate the minimal set of failure-inducing steps and produce causally valid minimal repairs that flip outcomes without introducing new errors or side effects.
What would settle it
An experiment showing that the generated repairs frequently fail to flip the outcome to success or introduce new errors or side effects would indicate the interventions do not produce causally valid minimal repairs.
Figures


read the original abstract
Large language model (LLM) agents frequently fail on multi-step tasks involving reasoning, tool use, and environment interaction. While such failures are typically logged or retried heuristically, they contain structured signals about where execution broke down. We introduce CausalFlow, an interventional framework that converts failed agent traces into minimal counterfactual repairs and reusable supervision. CausalFlow models execution traces as sequential chains of dependent steps and computes Causal Responsibility Scores(CRS) via step-level counterfactual intervention to identify failure-inducing steps. For these steps, we generate minimally edited repairs that flip the final outcome to success, producing validated contrastive pairs of the form (wrong step, corrected step). CausalFlow supports two complementary uses: targeted test-time repair that recovers from failures with minimal behavioral drift, and training-time supervision suitable for offline preference optimization or reward modeling. Across four benchmarks spanning mathematical reasoning, code generation, question answering, and medical browsing, CausalFlow converts failed executions into validated minimal repairs with high minimality and causal-consensus scores, and demonstrates that causal attribution is necessary for reliable improvement across diverse agent tasks, outperforming heuristic refinement in complex retrieval settings while producing more localized repairs throughout. These results demonstrate that interventional analysis over structured execution traces provides a principled and scalable mechanism for transforming agent failures into reliability gains and learning-ready supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CausalFlow, an interventional framework that models LLM agent execution traces as sequential chains of dependent steps, computes Causal Responsibility Scores (CRS) via step-level counterfactual interventions to identify failure-inducing steps, and generates minimally edited repairs that flip outcomes to produce validated contrastive pairs. These pairs support test-time repair with minimal drift and training-time supervision for preference optimization. Evaluations across four benchmarks (mathematical reasoning, code generation, QA, medical browsing) claim high minimality and causal-consensus scores, necessity of causal attribution for reliable gains, and outperformance over heuristic refinement in complex retrieval settings.
Significance. If the central interventional claims hold with valid counterfactuals, the work offers a scalable mechanism for converting structured failure traces into causally grounded repairs and supervision signals, potentially advancing beyond heuristic retry methods in agentic systems. The emphasis on minimality and contrastive pairs is a potential strength for downstream learning.
major comments (2)
- [Abstract] Abstract: the claims of 'high minimality and causal-consensus scores' and outperformance over heuristics are asserted without any quantitative results, tables, error bars, or specific metric values, preventing assessment of whether the CRS computation and repair generation actually support the central claim of principled, scalable improvement.
- [Abstract] Abstract (CRS computation and repair generation): the description of step-level counterfactual intervention to isolate minimal failure-inducing steps and produce repairs that flip outcomes without new errors lacks any formal definition, equation, or validity argument, making it impossible to evaluate the weakest assumption that such interventions yield causally valid minimal repairs.
minor comments (1)
- [Abstract] The acronym CRS is introduced before its expansion as Causal Responsibility Scores.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript. We address each of the two major comments on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'high minimality and causal-consensus scores' and outperformance over heuristics are asserted without any quantitative results, tables, error bars, or specific metric values, preventing assessment of whether the CRS computation and repair generation actually support the central claim of principled, scalable improvement.
Authors: We agree the abstract would be more informative with concrete numbers. In the revised version we will incorporate specific metric values for minimality and causal-consensus scores along with performance deltas versus heuristic baselines, drawn directly from the experimental results reported in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract (CRS computation and repair generation): the description of step-level counterfactual intervention to isolate minimal failure-inducing steps and produce repairs that flip outcomes without new errors lacks any formal definition, equation, or validity argument, making it impossible to evaluate the weakest assumption that such interventions yield causally valid minimal repairs.
Authors: Abstracts conventionally omit formal definitions and equations to remain accessible. The full formalization of CRS, the step-level counterfactual intervention operator, the minimality objective, and the validity arguments establishing that the resulting repairs are causally grounded appear in Section 3, complete with equations and stated assumptions. We therefore see no need to embed this material in the abstract. revision: no
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce CausalFlow as an interventional framework computing CRS via step-level counterfactual interventions on traces to generate minimal repairs. No equations, formal derivations, or load-bearing self-citations are visible that reduce any claimed prediction or result to its inputs by construction. The central mechanism (interventional analysis producing contrastive pairs) is described at a conceptual level without mathematical steps that would trigger self-definitional, fitted-input, or uniqueness-imported patterns. The derivation chain is therefore self-contained against external benchmarks, consistent with the default expectation that most papers exhibit no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgentBench: Evaluating LLMs as Agents
URLhttps://openreview.net/forum?id=zAdUB0aCTQ. arXiv:2308.03688. Ming Ma, Jue Zhang, Fangkai Yang, Yu Kang, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. Dover: Intervention-driven auto debugging for llm multi-agent systems, 2026. URL https://arxiv.org/abs/2512.06749. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/fllm63129.2024.10852426 2026
-
[2]
The gold answer is provided for reference ONLY - DO NOT directly use it in your repair
-
[3]
Fix the logical error in THIS step only - not the entire solution path
-
[4]
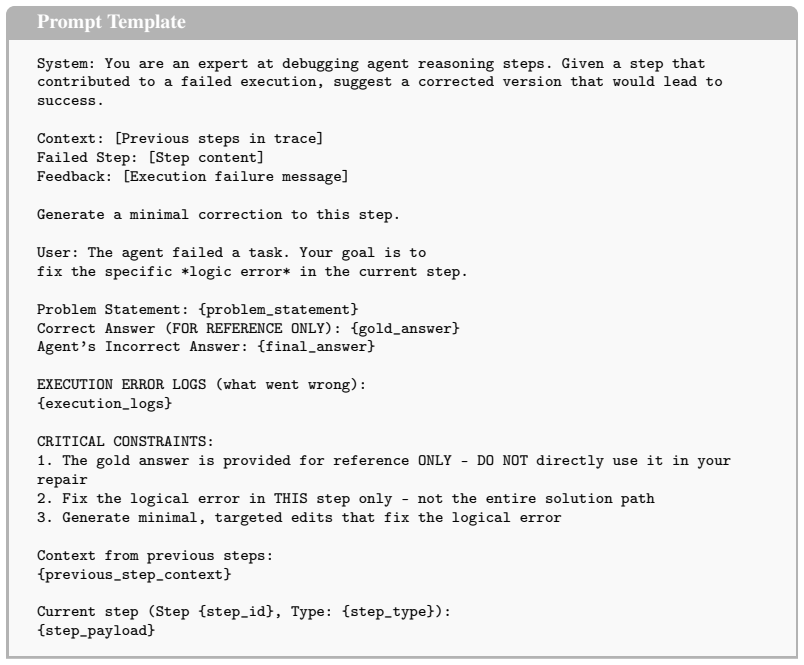
Note that variables in brackets are dynamically populated during the repair generation phase
Generate minimal, targeted edits that fix the logical error Context from previous steps: {previous_step_context} Current step (Step {step_id}, Type: {step_type}): {step_payload} Figure 2: Structured prompt template used to generate minimal counterfactual interventions for a candidate step. Note that variables in brackets are dynamically populated during t...
2021
-
[5]
EXPLANATION: Why was the previous solution wrong? Identify the exact reasoning or calculation error
-
[6]
ERROR KEYWORDS: List 3-5 concise keywords describing the error type (e.g., ’arithmetic error’, ’wrong formula’, ’misread problem’)
-
[7]
CORRECT SOLUTION: Solve the problem correctly step by step
-
[8]
INSTRUCTIONS: Write step-by-step instructions for solving this type of problem correctly in future
-
[9]
Apply your reflection to get it right
GENERAL ADVICE: What general principle should be remembered to avoid this kind of mistake? Self-Reflection: -- Stage 3: Re-Answer -- System: You are a careful math solver. Apply your reflection to get it right. User: Using your self-reflection as a guide, solve the math problem correctly. Problem: {problem} Your Self-Reflection: {reflection} Now provide t...
2024
-
[10]
Limitations
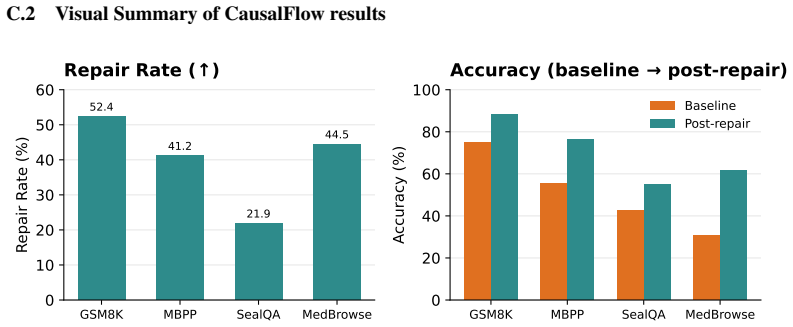
The claim that causal attribution outperforms heuristic refinement in complex retrieval settings is supported by the SealQA Hard and MedBrowseComp results, where Self-Refine and Self-Reflection produce negative or near-zero deltas while CausalFlow achieves +12.6pp and +30.8pp respectively. Scope limitations noted in the abstract, such as the dependency on...
2005
-
[11]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.