Quantum Parameterized Self-Attention Network for Image Classification
Pith reviewed 2026-06-29 21:59 UTC · model grok-4.3
The pith
A five-parameter quantum circuit computes self-attention scores via state encoding and joint measurement, outperforming classical dot-product attention on image tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
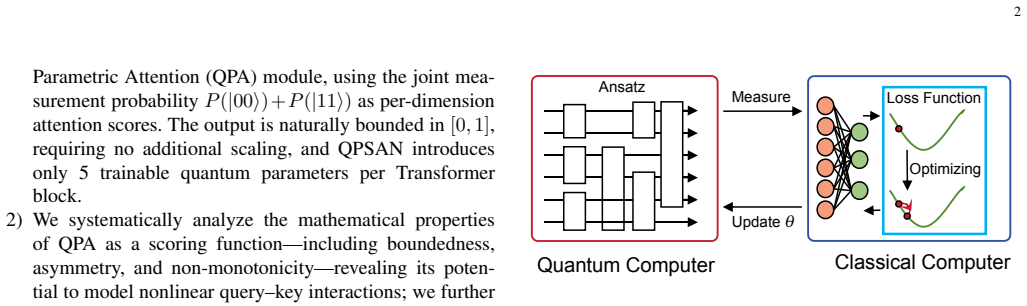
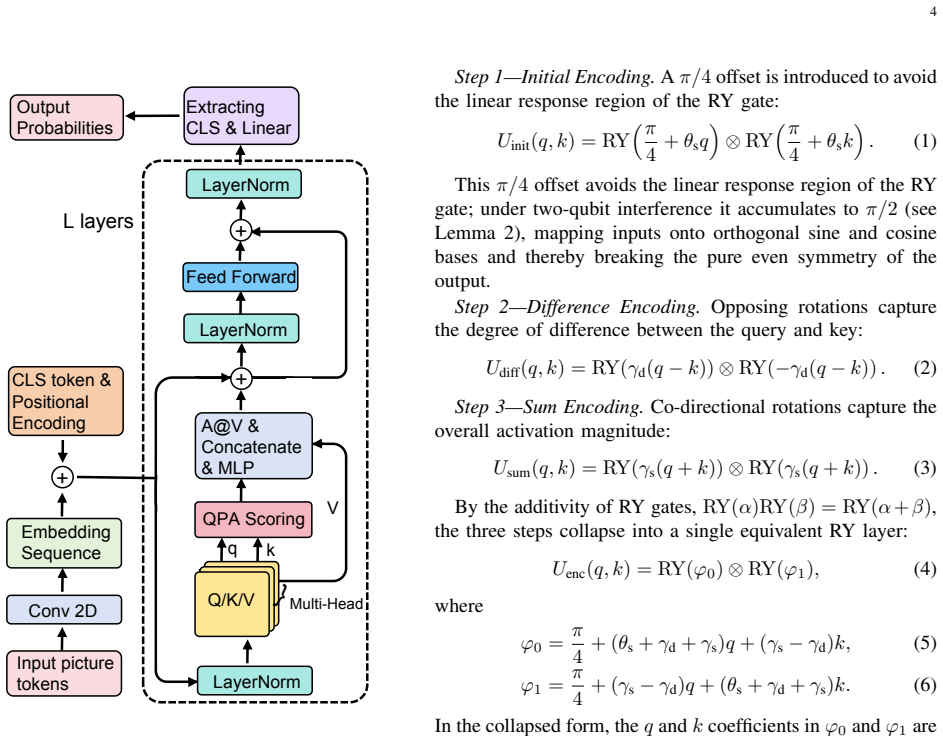
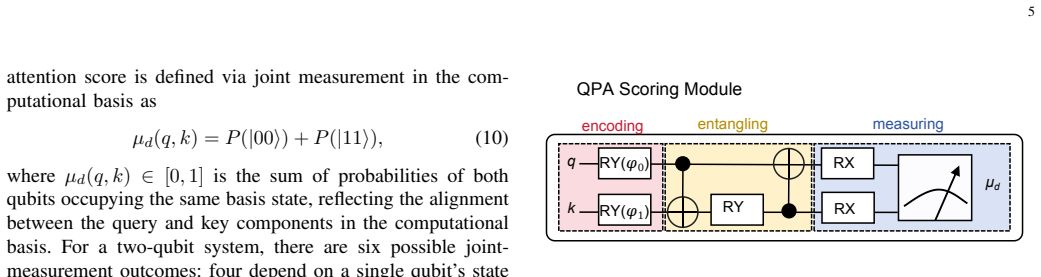
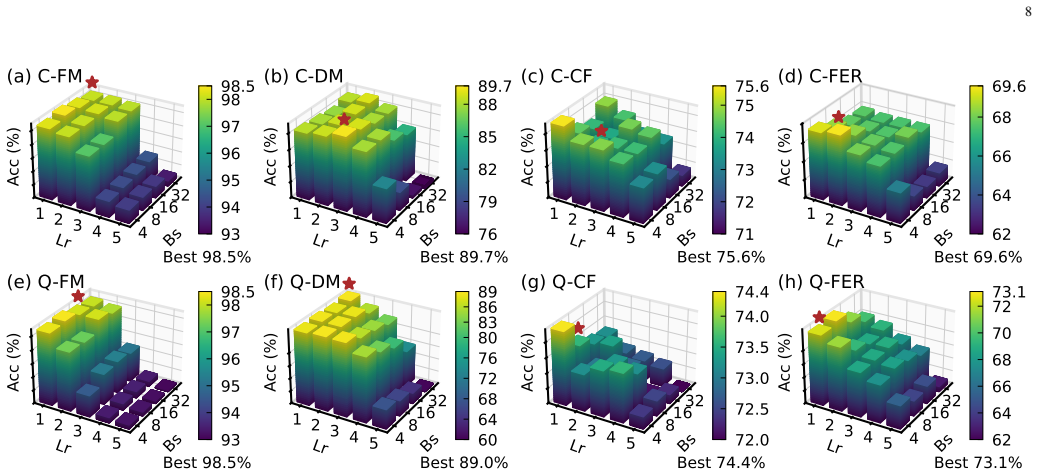
QPSAN replaces the self-attention scoring function with a parameterized quantum circuit containing only five trainable parameters per layer. The circuit encodes query-key pairs into quantum states and extracts scores from joint measurement, automatically yielding bounded outputs. Theoretical examination of the scoring function establishes its capacity for nonlinear query-key interactions and quantifies the encoding-layer constraints through effective degrees of freedom. On four image-classification benchmarks the network surpasses the Vision Transformer, and the advantage scales with data complexity; ablation results indicate the gains arise from the quantum circuit's structural inductive bi
What carries the argument
The five-parameter PQC scoring function that encodes query and key vectors into quantum states for joint measurement to produce attention scores.
If this is right
- Attention scores remain naturally bounded without separate scaling operations.
- The representational advantage over classical dot-product attention grows with increasing data complexity.
- Only five quantum parameters per layer suffice to implement effective self-attention.
- The structural bias of the quantum circuit, rather than parameter volume, drives the reported gains.
Where Pith is reading between the lines
- The same encoding-and-measurement pattern could be tested inside other transformer blocks such as feed-forward layers.
- Because the outputs are intrinsically bounded, training dynamics and gradient behavior may differ from scaled softmax attention even at equal accuracy.
- The effective-degrees-of-freedom analysis supplies a concrete metric for comparing quantum and classical scoring expressivity on new tasks.
Load-bearing premise
The observed performance edge arises specifically from the quantum circuit's structural inductive bias and cannot be matched by any classical network of comparable size and nonlinearity that also produces bounded outputs.
What would settle it
Replace the quantum scoring function inside QPSAN with a classical five-parameter network engineered to produce identically bounded nonlinear scores and measure whether the accuracy gap to ViT disappears on the same four datasets.
Figures
read the original abstract
Transformer now underpins modern AI as its core infrastructure. Its defining capability-dynamically focusing on the most relevant information in complex inputs-is bounded above by the self-attention scoring function. Quantum computing, with its superposition, entanglement, and probabilistic outputs, offers a fundamentally distinct computational framework for exploring beyond the design constraints of classical scoring functions. While quantum attention mechanisms have shown initial promise, existing works remain largely confined to redefining feature similarity measures, leaving the systematic use of parameterized quantum circuits (PQCs) as scoring functions largely unexplored; a substantial portion of existing schemes further rely on purely quantum architectures, precluding effective encoding of high-dimensional image inputs in the Noisy Intermediate-Scale Quantum era. We propose the Quantum Parameterized Self-Attention Network (QPSAN), implementing the self-attention scoring function via PQCs with only 5 trainable quantum parameters per layer. QPSAN computes query-key attention scores through quantum state encoding and joint measurement, yielding naturally bounded outputs without the explicit scaling of classical dot-product attention. We further establish a theoretical framework of the mathematical properties of this scoring function, demonstrating its potential to capture complex nonlinear query-key interactions, and quantifying the structural constraints of the encoding layer via effective degrees of freedom analysis. Experiments on four vision datasets show that QPSAN significantly outperforms the Vision Transformer (ViT) baseline, with the quantum representational advantage amplifying as data complexity increases. Ablation studies indicate that the performance gains may stem from the structural inductive bias of the quantum circuit rather than from parameter scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Quantum Parameterized Self-Attention Network (QPSAN), which implements the self-attention scoring function using parameterized quantum circuits (PQCs) with only 5 trainable quantum parameters per layer. Query-key scores are obtained via quantum state encoding and joint measurement, producing naturally bounded outputs. A theoretical framework analyzes the mathematical properties of this scoring function, including its capacity for complex nonlinear interactions and the structural constraints of the encoding layer via effective degrees of freedom. Experiments on four vision datasets report that QPSAN significantly outperforms a Vision Transformer (ViT) baseline, with the advantage growing as data complexity increases; ablation studies attribute the gains to the quantum circuit's structural inductive bias rather than parameter count.
Significance. If the reported performance gains hold under rigorous controls and the PQC scoring function cannot be replicated by classical networks of comparable size and output bounds, the work supplies a concrete, low-parameter hybrid quantum-classical attention mechanism suitable for NISQ hardware together with an explicit effective-degrees-of-freedom analysis. These elements would constitute a measurable advance over prior quantum attention proposals that either redefine similarity measures or rely on fully quantum pipelines.
major comments (2)
- [Experiments / Ablation studies] Experiments / Ablation studies: the central attribution of performance gains to the 'structural inductive bias of the quantum circuit' (abstract) rests on the premise that the 5-parameter PQC scoring function supplies nonlinearity and bounded outputs unavailable to a classical network of equal parameter count. No direct surrogate experiment is described that replaces the PQC with a 5-parameter classical module (e.g., a small MLP with sigmoid or tanh activations followed by appropriate scaling) while keeping the remainder of the architecture identical. Without this control, the ablation results cannot rule out classical replication of the observed functional form.
- [Theoretical framework] Theoretical framework section: the effective-degrees-of-freedom analysis quantifies encoding-layer constraints but does not derive an explicit comparison between the PQC scoring function and the function class realizable by a classical 5-parameter bounded nonlinear map. Consequently the claim that the observed advantage is 'structural' rather than 'parameter-scale' remains unanchored by a side-by-side functional characterization.
minor comments (2)
- The abstract and experimental description omit dataset sizes, number of runs, error bars, and exact baseline hyperparameters; these details are required to assess the statistical significance of the reported outperformance.
- Notation for the five trainable quantum parameters and the joint-measurement operator should be introduced with explicit equations rather than descriptive text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, acknowledging where the manuscript can be strengthened through additional controls and analysis.
read point-by-point responses
-
Referee: [Experiments / Ablation studies] Experiments / Ablation studies: the central attribution of performance gains to the 'structural inductive bias of the quantum circuit' (abstract) rests on the premise that the 5-parameter PQC scoring function supplies nonlinearity and bounded outputs unavailable to a classical network of equal parameter count. No direct surrogate experiment is described that replaces the PQC with a 5-parameter classical module (e.g., a small MLP with sigmoid or tanh activations followed by appropriate scaling) while keeping the remainder of the architecture identical. Without this control, the ablation results cannot rule out classical replication of the observed functional form.
Authors: We agree that the existing ablation studies, while showing advantages over classical attention variants with comparable or higher parameter counts, do not include an exact 5-parameter classical surrogate (such as a bounded MLP) that replicates the PQC's output form. This leaves open the possibility of classical replication of the functional behavior. We will add this direct control experiment in the revised manuscript, keeping all other architecture elements identical, to more rigorously isolate the contribution of the quantum circuit structure. revision: yes
-
Referee: [Theoretical framework] Theoretical framework section: the effective-degrees-of-freedom analysis quantifies encoding-layer constraints but does not derive an explicit comparison between the PQC scoring function and the function class realizable by a classical 5-parameter bounded nonlinear map. Consequently the claim that the observed advantage is 'structural' rather than 'parameter-scale' remains unanchored by a side-by-side functional characterization.
Authors: The theoretical framework derives properties of the PQC scoring function, including its capacity for nonlinear interactions and the encoding-layer constraints via effective degrees of freedom. We acknowledge that it stops short of an explicit side-by-side comparison to the function class of a classical 5-parameter bounded nonlinear map. In revision we will add such a characterization (e.g., via series expansion or expressivity bounds) to better anchor the distinction between structural bias and parameter count. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes QPSAN with a 5-parameter PQC for attention scoring, derives mathematical properties and effective degrees of freedom for the encoding layer, and reports experimental outperformance on vision datasets. No quoted equations or steps reduce claimed predictions or advantages to fitted inputs by construction, self-definitional loops, or load-bearing self-citations. The central performance attribution rests on separate ablation experiments rather than tautological redefinitions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- trainable quantum parameters per layer =
5
axioms (1)
- domain assumption Quantum state encoding followed by joint measurement yields a scoring function whose outputs are naturally bounded and can capture nonlinear query-key interactions
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017, pp. 5998–6008
2017
-
[2]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[3]
Query-key normalization for transformers,
A. Henry, P. R. Dachapally, S. S. Pawar, and Y . Chen, “Query-key normalization for transformers,” inFindings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 4246–4253
2020
-
[4]
Quantum self-attention neural networks for text classification,
G. Li, X. Zhao, and X. Wang, “Quantum self-attention neural networks for text classification,”Sci. China Inf. Sci., vol. 67, no. 4, p. 142501, 2024
2024
-
[5]
Qksan: A quantum kernel self-attention network,
R.-X. Zhao, J. Shi, and X. Li, “Qksan: A quantum kernel self-attention network,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 10 184–10 195, 2024
2024
-
[6]
QSAN: A near-term achievable quantum self-attention network,
J. Shi, R.-X. Zhao, W. Wang, S. Zhang, and X. Li, “QSAN: A near-term achievable quantum self-attention network,”IEEE Trans. Neural Netw. Learn. Syst., vol. 36, no. 8, pp. 13 995–14 008, 2024
2024
-
[7]
Hqvit: Hybrid quan- tum vision transformer for image classification,
H. Zhang, Q. Zhao, M. Zhou, and L. Feng, “Hqvit: Hybrid quan- tum vision transformer for image classification,” 2025, arXiv preprint arXiv:2504.02730
-
[8]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” inInternational Conference on Learning Representations, 2015
2015
-
[9]
Effective approaches to attention-based neural machine translation,
M.-T. Luong, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” inProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015, pp. 1412–1421
2015
-
[10]
Non-local neural net- works,
X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural net- works,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7794–7803
2018
-
[11]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022
2021
-
[12]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, “Training data-efficient image transformers & distillation through attention,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 10 347–10 357
2021
-
[13]
Linear differential vision transformer: Learn- ing visual contrasts via pairwise differentials,
Y . Pu, J. Ying, Q. Li, T. Ye, D. Han, X. Wang, Z. Wang, X. Shao, G. Huang, and X. Li, “Linear differential vision transformer: Learn- ing visual contrasts via pairwise differentials,” 2025, arXiv preprint arXiv:2511.00833
-
[14]
The linear attention resurrection in vision transformer,
C. Zheng, “The linear attention resurrection in vision transformer,” 2025, arXiv preprint arXiv:2501.16182
-
[15]
A general survey on attention mecha- nisms in deep learning,
G. Brauwers and F. Frasincar, “A general survey on attention mecha- nisms in deep learning,”IEEE Trans. Knowl. Data Eng., vol. 35, no. 4, pp. 3279–3298, 2021
2021
-
[16]
A survey of efficient attention methods: Hardware-efficient, sparse, compact, and linear attention,
J. Zhang, R. Su, C. Liu, J. Wei, Z. Wang, P. Zhang, H. Wang, H. Jiang, H. Huang, C. Xianget al., “A survey of efficient attention methods: Hardware-efficient, sparse, compact, and linear attention,” 2025
2025
-
[17]
Evidence for the utility of quantum computing before fault tolerance,
Y . Kim, A. Eddins, S. Anand, K. X. Wei, E. Van Den Berg, S. Rosenblatt, H. Nayfeh, Y . Wu, M. Zaletel, K. Temmeet al., “Evidence for the utility of quantum computing before fault tolerance,”Nature, vol. 618, no. 7965, pp. 500–505, 2023
2023
-
[18]
The power of quantum neural networks,
A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, “The power of quantum neural networks,”Nat. Comput. Sci., vol. 1, no. 6, pp. 403–409, 2021
2021
-
[19]
Advances in Neural Information Processing Systems, 31
M. Schuld, “Supervised quantum machine learning models are kernel methods,” 2021, arXiv preprint arXiv:2101.11020
-
[20]
Entanglement-induced provable and robust quantum learning advantages,
H. Zhao and D.-L. Deng, “Entanglement-induced provable and robust quantum learning advantages,”npj Quantum Inf., vol. 11, no. 1, p. 127, 2025
2025
-
[21]
A variational eigenvalue solver on a photonic quantum processor,
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’brien, “A variational eigenvalue solver on a photonic quantum processor,”Nat. Commun., vol. 5, no. 1, p. 4213, 2014
2014
-
[22]
Variational quantum algorithms,
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, “Variational quantum algorithms,”Nat. Rev. Phys., vol. 3, no. 9, pp. 625–644, 2021
2021
-
[23]
Supervised learning with quantum- enhanced feature spaces,
V . Havlí ˇcek, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum- enhanced feature spaces,”Nature, vol. 567, no. 7747, pp. 209–212, 2019
2019
-
[24]
Quantum circuit learning,
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,”Phys. Rev. A, vol. 98, no. 3, p. 032309, 2018
2018
-
[25]
Superior resilience to poisoning and amenability to unlearning in quantum machine learning,
Y .-Q. Chen and S.-X. Zhang, “Superior resilience to poisoning and amenability to unlearning in quantum machine learning,”Nat. Commun., vol. 17, p. 3716, 2026
2026
-
[26]
W. Zhang, J. Wang, T. Ye, and C. Liao, “Dual-qubit hierarchical fuzzy neural network for image classification: Enabling relational learning via quantum entanglement,” 2025, arXiv preprint arXiv:2512.13274
-
[27]
Expressibility and entan- gling capability of parameterized quantum circuits for hybrid quantum- classical algorithms,
S. Sim, P. D. Johnson, and A. Aspuru-Guzik, “Expressibility and entan- gling capability of parameterized quantum circuits for hybrid quantum- classical algorithms,”Adv. Quantum Technol., vol. 2, no. 12, p. 1900070, 2019
2019
-
[28]
Barren plateaus in variational quantum computing,
M. Larocca, S. Thanasilp, S. Wang, K. Sharma, J. Biamonte, P. J. Coles, L. Cincio, J. R. McClean, Z. Holmes, and M. Cerezo, “Barren plateaus in variational quantum computing,”Nat. Rev. Phys., vol. 7, no. 4, pp. 174–189, 2025
2025
-
[29]
CLAQS: Compact learnable all-quantum token mixer with shared-ansatz for text classification,
J. Chen, Y . Zhou, H. Jiang, Y . Pan, Y . Li, H. Zhao, W. Zhang, Y . Wang, and T. Liu, “CLAQS: Compact learnable all-quantum token mixer with shared-ansatz for text classification,” 2025, arXiv preprint arXiv:2510.06532
-
[30]
Quantum-inspired interpretable deep learning architecture for text sentiment analysis,
B. Li, D. Zhang, Z. Zhao, J. Gao, and Y . Yuan, “Quantum-inspired interpretable deep learning architecture for text sentiment analysis,” 2024, arXiv preprint arXiv:2408.07891
-
[31]
Quantum-inspired self-attention in a large language model,
N. Kuznetsov, N. Ismagilov, and E. Campos, “Quantum-inspired self-attention in a large language model,” 2026, arXiv preprint arXiv:2603.03318
-
[32]
Quantum vision transformers,
I. Kerenidis, N. Mathur, J. Landman, M. Strahm, Y . Y . Liet al., “Quantum vision transformers,”Quantum, vol. 8, p. 1265, 2024
2024
-
[33]
Quantum complex-valued self-attention model,
F. Chen, Q. Zhao, L. Feng, L. Tang, Y . Lin, and H. Huang, “Quantum complex-valued self-attention model,” 2025, arXiv preprint arXiv:2503.19002
-
[34]
Quantum mixed-state self-attention network,
F. Chen, Q. Zhao, L. Feng, C. Chen, Y . Lin, and J. Lin, “Quantum mixed-state self-attention network,”Neural Netw., vol. 185, p. 107123, 2025
2025
-
[35]
Transfer learning in hybrid classical-quantum neural networks,
A. Mari, T. R. Bromley, J. Izaac, M. Schuld, and N. Killoran, “Transfer learning in hybrid classical-quantum neural networks,”Quantum, vol. 4, p. 340, 2020
2020
-
[36]
QHSA-ViT: A quantum discrete fourier transform-based hierarchical self-attention fusion vision transformer for traffic sign recognition in intelligent vehicular networks,
Z. Qu, M. Zhou, L. Sun, Y . Yu, and G. Muhammad, “QHSA-ViT: A quantum discrete fourier transform-based hierarchical self-attention fusion vision transformer for traffic sign recognition in intelligent vehicular networks,”IEEE Internet Things J., 2025, early Access
2025
-
[37]
Quantum Adaptive Self-Attention for Quantum Transformer Models
C.-S. Chen and E.-J. Kuo, “Quantum adaptive self-attention for quantum transformer models,” 2025, arXiv preprint arXiv:2504.05336
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Quantum-enhanced attention mechanism in nlp: A hybrid classical-quantum approach,
S. M. Tomal, A. A. Shafin, D. Bhattacharjee, M. D. Amin, and R. S. Shahir, “Quantum-enhanced attention mechanism in nlp: A hybrid classical-quantum approach,” 2025, arXiv preprint arXiv:2501.15630. 13
-
[39]
A hybrid Transformer architecture with a quantized self-attention mechanism applied to molecular generation,
A. M. Smaldone, Y . Shee, G. W. Kyro, M. H. Farag, Z. Chandani, E. Kyoseva, and V . S. Batista, “A hybrid Transformer architecture with a quantized self-attention mechanism applied to molecular generation,” J. Chem. Theory Comput., vol. 21, no. 10, pp. 5143–5154, 2025
2025
-
[40]
Torchquantum case study for robust quantum circuits,
H. Wang, Z. Liang, J. Gu, Z. Li, Y . Ding, W. Jiang, Y . Shi, D. Z. Pan, F. T. Chong, and S. Han, “Torchquantum case study for robust quantum circuits,” inProceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design, 2022, pp. 1–9
2022
-
[41]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms,” 2017, arXiv preprint arXiv:1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Deep deterministic uncertainty: A new simple baseline,
J. Mukhoti, A. Kirsch, J. Van Amersfoort, P. H. Torr, and Y . Gal, “Deep deterministic uncertainty: A new simple baseline,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 384–24 394
2023
-
[43]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” University of Toronto, Technical Report, 2009
2009
-
[44]
Challenges in representation learning: A report on three machine learning contests,
I. J. Goodfellow, D. Erhan, P. L. Carrier, A. Courville, M. Mirza, B. Hamner, W. Cukierski, Y . Tang, D. Thaler, D.-H. Leeet al., “Challenges in representation learning: A report on three machine learning contests,” inInternational Conference on Neural Information Processing. Springer, 2013, pp. 117–124
2013
-
[45]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” in International Conference on Machine Learning. PMLR, 2020, pp. 5156–5165
2020
-
[46]
Effect of data encoding on the expressive power of variational quantum-machine-learning models,
M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum-machine-learning models,” Phys. Rev. A, vol. 103, no. 3, p. 032430, 2021
2021
-
[47]
Schölkopf and A
B. Schölkopf and A. J. Smola,Learning with Kernels: Support V ector Machines, Regularization, Optimization, and Beyond. MIT press, 2002
2002
-
[48]
S. G. Krantz and H. R. Parks,A Primer of Real Analytic Functions. Springer Science & Business Media, 2002
2002
-
[49]
R. A. Horn and C. R. Johnson,Matrix Analysis. Cambridge university press, 2012. PROOFS OFMAINRESULTS We provide complete proofs of Lemmas 1–2, Properties 1– 3, and Theorems 1–2. Proof of Lemma 1 (Non-separable kernel) Step 1: Equivalent rotation angles.All three encoding steps act prior to the entanglement layer; each step applies RY gates independently o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.