Quantum Adaptive Self-Attention for Quantum Transformer Models
Pith reviewed 2026-05-22 21:38 UTC · model grok-4.3
The pith
A Transformer with one 36-parameter quantum circuit in the value projection of a single encoder layer achieves best results on chaotic time-series tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that Quantum Adaptive Self-Attention (QASA) replaces the classical value projection inside a single encoder layer with a parameterized quantum circuit and thereby obtains the lowest mean squared error on four of nine synthetic forecasting tasks plus a 6.0 percent mean absolute error reduction on the real ETTh1 dataset. They further claim that this improvement is task-conditional—strongest on chaotic, noisy, and trend-heavy signals and absent or reversed on clean periodic waveforms—and that a single optimally placed quantum layer consistently beats configurations that insert quantum layers at multiple positions. The work concludes that architectural parsimony, achieved by a
What carries the argument
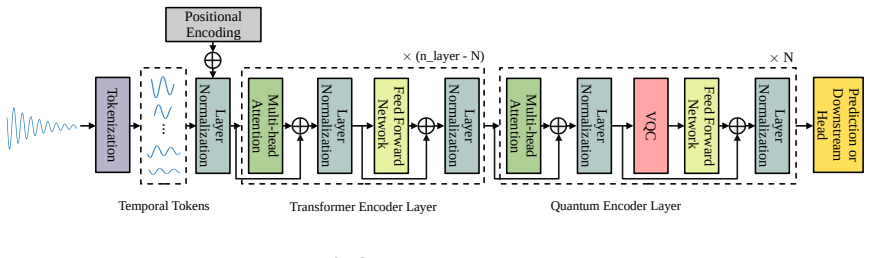
Quantum Adaptive Self-Attention (QASA), the module that substitutes the value projection in one Transformer encoder layer with a parameterized quantum circuit of 36 trainable parameters while leaving all other layers classical.
If this is right
- The hybrid model matches or exceeds quantum baselines that use two to four times more quantum parameters.
- Adding quantum layers beyond the single optimal position degrades forecasting accuracy.
- Quantum enhancement appears on chaotic, noisy, and trend-dominated signals but not on clean periodic waveforms.
- Layer position controls quantum benefit more strongly than the total number of quantum layers.
- Statistical tests show significant outperformance over QLSTM on the seasonal-trend task.
Where Pith is reading between the lines
- The same minimal-replacement strategy could be tested in other attention-based or sequence models to check whether position-specific quantum gains appear on analogous signal types.
- The observed drop when multiple quantum layers are added hints that interface overhead between quantum and classical parts may grow with scale, an effect worth measuring directly.
- The task taxonomy suggests an adaptive router that inspects input statistics and decides whether to route a given sequence through the quantum or classical path.
- If the position effect generalizes, future hybrid designs should optimize layer placement before increasing quantum depth.
Load-bearing premise
The measured performance differences arise from the quantum circuit rather than from classical hyperparameter choices, random seeds, or selective choice of which tasks count as chaotic versus periodic.
What would settle it
If an exhaustive hyperparameter search on the classical Transformer, run with the same compute budget and multiple random seeds, closes the error gap on the chaotic benchmarks, the claim that the quantum circuit itself supplies the advantage would be falsified.
Figures



read the original abstract
Integrating quantum computing into deep learning architectures is a promising but poorly understood endeavor: when does a quantum layer actually help, and how much quantum is enough? We address both questions through Quantum Adaptive Self-Attention (QASA), a hybrid Transformer that replaces the value projection in a \emph{single} encoder layer with a parameterized quantum circuit (PQC), while keeping all other layers classical. This \emph{minimal quantum integration} strategy uses only 36 trainable quantum parameters -- fewer than any competing quantum model -- yet achieves the best MSE on 4 of 9 synthetic benchmarks and a 6.0\% MAE reduction on the real-world ETTh1 dataset. An ablation study reveals that quantum layer \emph{position} matters more than \emph{count}: adding more quantum layers degrades performance, while a single layer at the optimal position consistently outperforms multi-layer quantum configurations. Comparison with two recent quantum time-series baselines -- QLSTM and QnnFormer -- confirms that QASA matches or exceeds models with $2$--$4\times$ more quantum parameters, significantly outperforming QLSTM on the seasonal trend task ($p{=}0.009$, Cohen's $d{>}6$). Crucially, the benefit is \emph{task-conditional}: QASA excels on chaotic, noisy, and trend-dominated signals, while classical Transformers remain superior for clean periodic waveforms -- providing a practical taxonomy for when quantum enhancement is warranted. These findings establish an \emph{architectural parsimony} principle for hybrid quantum-classical design: maximal quantum benefit is achieved not by maximizing quantum resources, but by strategically placing minimal quantum computation where it matters most.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Quantum Adaptive Self-Attention (QASA), a hybrid quantum-classical Transformer that replaces the value projection in only one encoder layer with a parameterized quantum circuit (PQC) using 36 trainable quantum parameters. It reports that this minimal integration achieves the best MSE on 4 of 9 synthetic time-series benchmarks and a 6.0% MAE reduction on the ETTh1 dataset relative to classical Transformers and quantum baselines (QLSTM, QnnFormer). Ablations indicate that quantum layer position matters more than count (additional layers degrade performance), the benefit is task-conditional (stronger on chaotic/noisy/trend signals, weaker on clean periodic ones), and comparisons include a p=0.009 result versus QLSTM on one task.
Significance. If the reported gains can be shown to arise specifically from the 36-parameter PQC rather than classical hyperparameter variance or post-hoc choices, the work would offer concrete empirical evidence for an 'architectural parsimony' principle in hybrid quantum ML: strategic placement of minimal quantum resources can outperform both fully classical and more heavily quantumized models on selected tasks, along with a practical taxonomy for when quantum layers are warranted in time-series Transformers.
major comments (4)
- [Abstract / Results] Abstract and Results: The headline performance claims (best MSE on 4/9 synthetics, 6.0% MAE on ETTh1, p=0.009 vs QLSTM) rest on direct empirical comparisons, yet the manuscript provides no information on the number of independent random seeds/runs per model, whether error bars or standard deviations accompany the reported metrics, or any multiple-comparison correction across 10 datasets; without these, the statistical isolation of the quantum effect from optimization variance cannot be verified.
- [Ablation study] Ablation study: The claim that 'quantum layer position matters more than count' and that a single layer at the 'optimal position' outperforms multi-layer configurations requires that the optimal position was not selected after inspecting test-set performance across all candidate positions; if the selection was post-hoc, the position effect is confounded by selection bias and does not support the architectural recommendation.
- [Abstract / Discussion] Abstract and Discussion: The task-conditional taxonomy ('QASA excels on chaotic, noisy, and trend-dominated signals, while classical Transformers remain superior for clean periodic waveforms') is presented as a key finding, but it is unclear whether the 'chaotic/periodic' labels were fixed a priori before any training or assigned post-hoc on the basis of observed performance differences; the latter would render the interpretation circular and undermine the practical guidance offered.
- [Experiments] Experiments: Full details on dataset splits, hyperparameter search ranges, training protocol, and circuit diagram for the 36-parameter PQC are absent, preventing independent reproduction and making it impossible to rule out that the reported advantages arise from classical implementation choices rather than the quantum circuit itself.
minor comments (1)
- [Abstract] The abstract states 'significantly outperforming QLSTM on the seasonal trend task (p=0.009, Cohen's d>6)' but does not specify which exact task or dataset this refers to among the synthetic benchmarks.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We will revise the manuscript to enhance its statistical reporting, clarify methodological choices, and provide full experimental details to improve reproducibility and address the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: The headline performance claims (best MSE on 4/9 synthetics, 6.0% MAE on ETTh1, p=0.009 vs QLSTM) rest on direct empirical comparisons, yet the manuscript provides no information on the number of independent random seeds/runs per model, whether error bars or standard deviations accompany the reported metrics, or any multiple-comparison correction across 10 datasets; without these, the statistical isolation of the quantum effect from optimization variance cannot be verified.
Authors: We agree that these statistical details are essential. In the revised manuscript, we will provide the number of independent random seeds used for all experiments, include standard deviations as error bars in the result tables, and apply a multiple-comparison correction (such as Bonferroni) across the 10 datasets. This will allow readers to verify the statistical isolation of the quantum effect. revision: yes
-
Referee: [Ablation study] Ablation study: The claim that 'quantum layer position matters more than count' and that a single layer at the 'optimal position' outperforms multi-layer configurations requires that the optimal position was not selected after inspecting test-set performance across all candidate positions; if the selection was post-hoc, the position effect is confounded by selection bias and does not support the architectural recommendation.
Authors: We will revise the ablation study section to explicitly describe the procedure used to select the optimal position, including whether it was based on validation-set performance. If any ambiguity remains regarding selection bias, we will note this limitation and consider additional validation experiments in the revision. revision: yes
-
Referee: [Abstract / Discussion] Abstract and Discussion: The task-conditional taxonomy ('QASA excels on chaotic, noisy, and trend-dominated signals, while classical Transformers remain superior for clean periodic waveforms') is presented as a key finding, but it is unclear whether the 'chaotic/periodic' labels were fixed a priori before any training or assigned post-hoc on the basis of observed performance differences; the latter would render the interpretation circular and undermine the practical guidance offered.
Authors: We will add a dedicated subsection detailing the a priori definitions and data-generation properties used to classify tasks as chaotic, noisy, trend-dominated, or periodic. This will clarify that the taxonomy is grounded in the known characteristics of the synthetic benchmarks rather than post-hoc performance observations. revision: yes
-
Referee: [Experiments] Experiments: Full details on dataset splits, hyperparameter search ranges, training protocol, and circuit diagram for the 36-parameter PQC are absent, preventing independent reproduction and making it impossible to rule out that the reported advantages arise from classical implementation choices rather than the quantum circuit itself.
Authors: We agree that complete details are required for reproducibility. The revised manuscript will include the exact dataset splits, the full hyperparameter search ranges and method, the complete training protocol (optimizer, epochs, batch size, etc.), and a circuit diagram with the gate sequence for the 36-parameter PQC. These will be added to the Experiments section and supplementary material. revision: yes
Circularity Check
No circularity; all claims are direct empirical observations from experiments
full rationale
The paper advances no derivation chain, first-principles result, or mathematical prediction. Its central claims (best MSE on 4/9 benchmarks, 6% MAE reduction on ETTh1, position mattering more than layer count, task-conditional benefit) are presented solely as outcomes of training and testing QASA against classical Transformers, QLSTM, and QnnFormer, plus an ablation study. No equation reduces a fitted parameter to a renamed prediction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled in. The reported p=0.009 and Cohen's d are statistical comparisons of experimental runs, not circular fits. The architecture is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 36 trainable quantum parameters
axioms (1)
- domain assumption Parameterized quantum circuits can be embedded into classical neural network layers to process sequential data.
Forward citations
Cited by 1 Pith paper
-
Do Quantum Transformers Help? A Systematic VQC Architecture Comparison on Tabular Benchmarks
Fully-connected VQCs match quantum transformer performance on tabular data with far fewer parameters and better noise resilience.
Reference graph
Works this paper leans on
-
[1]
The fine-grained complexity of gradient compu- tation for training large language models
[AS24] Josh Alman and Zhao Song. The fine-grained complexity of gradient compu- tation for training large language models. arXiv preprint arXiv:2402.04497 ,
-
[2]
The quantum strong exponential-time hypothesis
[BPS19] Harry Buhrman, Subhasree Patro, and Florian Speelman. The quantum strong exponential-time hypothesis. arXiv preprint arXiv:1911.05686 ,
-
[3]
Optimizing supply chain networks with the power of graph neural networks
[CC25] Chi-Sheng Chen and Ying-Jung Chen. Optimizing supply chain networks with the power of graph neural networks. arXiv preprint arXiv:2501.06221 ,
-
[4]
[CCT25a] Chi-Sheng Chen, Samuel Yen-Chi Chen, and Huan-Hsin Tseng. Exploring the potential of qeegnet for cross-task and cross-dataset electroencephalography encoding with quantum machine learning. arXiv preprint arXiv:2503.00080 ,
-
[5]
Large cog- nition model: Towards pretrained eeg foundation model
[CCT25b] Chi-Sheng Chen, Ying-Jung Chen, and Aidan Hung-Wen Tsai. Large cog- nition model: Towards pretrained eeg foundation model. arXiv preprint arXiv:2502.17464,
-
[6]
Qeegnet: Quantum machine learning for enhanced electroen- cephalography encoding
[CCTW24] Chi-Sheng Chen, Samuel Yen-Chi Chen, Aidan Hung-Wen Tsai, and Chun- Shu Wei. Qeegnet: Quantum machine learning for enhanced electroen- cephalography encoding. In 2024 IEEE Workshop on Signal Processing Sys- tems (SiPS), pages 153–158. IEEE,
work page 2024
-
[7]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
[CGCB14] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Necomimi: Neural-cognitive multimodal eeg-informed image generation with diffusion models
[Che24] Chi-Sheng Chen. Necomimi: Neural-cognitive multimodal eeg-informed image generation with diffusion models. arXiv preprint arXiv:2410.00712 ,
-
[9]
[CKM+22] El Amine Cherrat, Iordanis Kerenidis, Natansh Mathur, Jonas Landman, Mar- tin Strahm, and Yun Yvonna Li. Quantum vision transformers. arXiv preprint arXiv:2209.08167,
-
[10]
Quantum multimodal contrastive learning framework
[CTH24] Chi-Sheng Chen, Aidan Hung-Wen Tsai, and Sheng-Chieh Huang. Quantum multimodal contrastive learning framework. arXiv preprint arXiv:2408.13919,
-
[11]
Psycho gundam: Electroencephalogra- phy based real-time robotic control system with deep learning
[CW24a] Chi-Sheng Chen and Wei-Sheng Wang. Psycho gundam: Electroencephalogra- phy based real-time robotic control system with deep learning. arXiv preprint arXiv:2411.06414,
-
[12]
Accepted in Quantum 2023-11-03, click title to verify. Published under CC-BY 4.0. 15 [CW24b] Chi-Sheng Chen and Chun-Shu Wei. Mind’s eye: Image recognition by eeg via multimodal similarity-keeping contrastive learning. arXiv preprint arXiv:2406.16910,
-
[13]
Quantum long short-term memory
[CYF22] Samuel Yen-Chi Chen, Shinjae Yoo, and Yao-Lung L Fang. Quantum long short-term memory. In Icassp 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages 8622–8626. IEEE,
work page 2022
-
[14]
Quixer: A quantum transformer model
[KMCC24] Nikhil Khatri, Gabriel Matos, Luuk Coopmans, and Stephen Clark. Quixer: A quantum transformer model. arXiv preprint arXiv:2406.04305 ,
-
[15]
Accepted in Quantum 2023-11-03, click title to verify. Published under CC-BY 4.0. 16 [VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30,
work page 2023
-
[16]
Accepted in Quantum 2023-11-03, click title to verify. Published under CC-BY 4.0. 17
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.