Leveraging Language Models for Log Statement Generation in Multilingual Scenarios: How Far Are We?
Pith reviewed 2026-06-29 21:01 UTC · model grok-4.3
The pith
UniLog leads in log statement generation across languages but performance gaps persist due to language-specific idioms and insertion patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
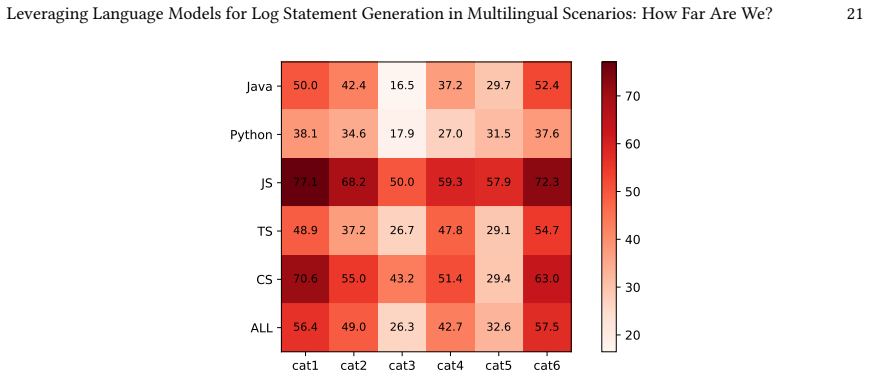
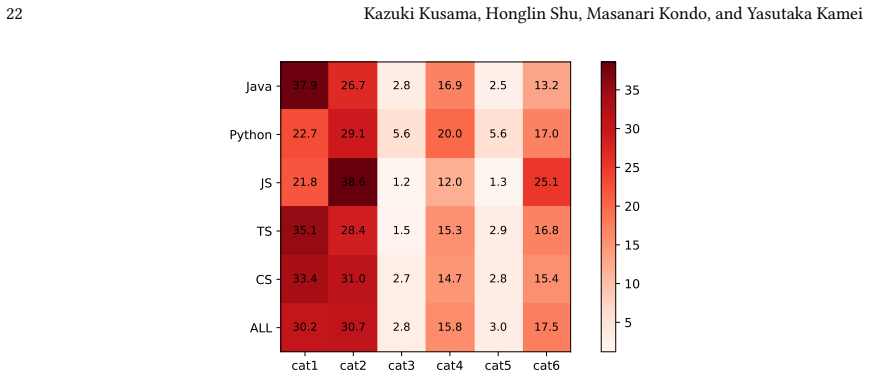
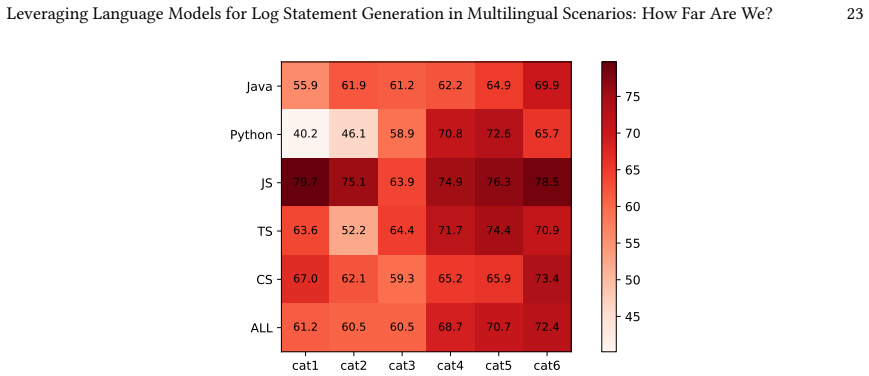
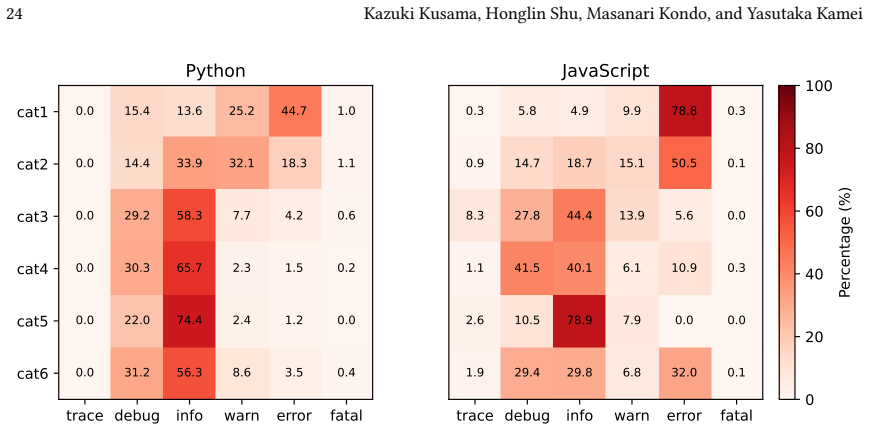
UniLog achieves the best overall performance in generating log statements across multiple programming languages, maintaining high effectiveness even in multilingual environments. Performance varies substantially, with Python presenting a greater challenge whereas JavaScript yields comparatively better results. These disparities stem from variations in log insertion distributions and language-specific logging idioms. Simply scaling model size or the volume of training data is insufficient for multilingual log generation; approaches tailored to the specific characteristics of target languages are required.
What carries the argument
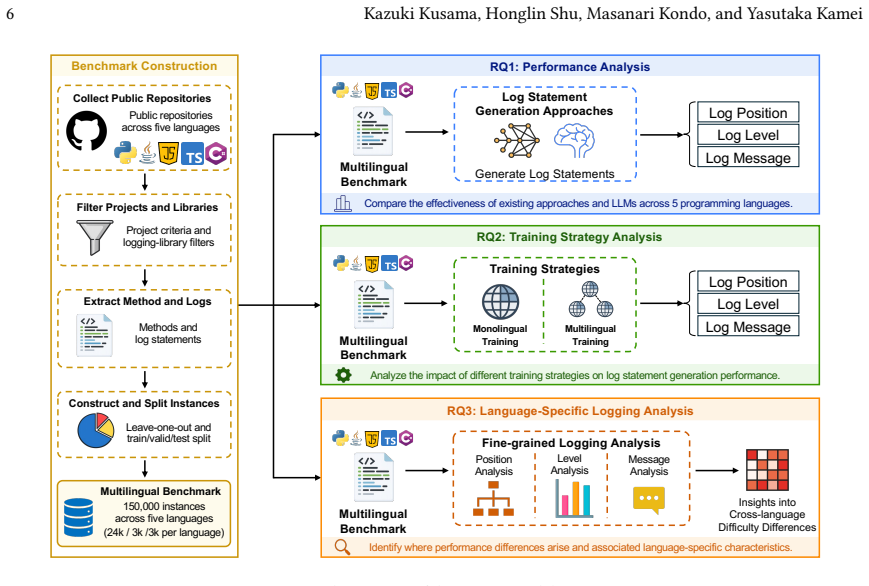
The multilingual benchmark of 150,000 instances across five programming languages used to compare state-of-the-art log generation approaches and large language models.
If this is right
- UniLog maintains high effectiveness even when code mixes multiple programming languages.
- Log generation difficulty differs by language, with Python harder than JavaScript.
- Disparities arise from how logs are typically inserted and from each language's logging idioms.
- Scaling model size or data volume alone will not produce robust multilingual results.
- Future automated logging techniques must explicitly account for language-specific characteristics.
Where Pith is reading between the lines
- Maintenance tools could add per-language fine-tuning or detection steps to improve suggestions in harder languages.
- Teams working across languages may need to supplement training sets with more examples from challenging languages like Python.
- Static analysis combined with log generation might help surface language-specific patterns that current models miss.
Load-bearing premise
The 150,000-instance benchmark and chosen evaluation metrics accurately represent the practical difficulty of log statement generation for developers in real multilingual codebases.
What would settle it
A follow-up study on production multilingual projects that finds uniform performance across languages after simply increasing model size or training data volume, without any language-specific tailoring.
Figures

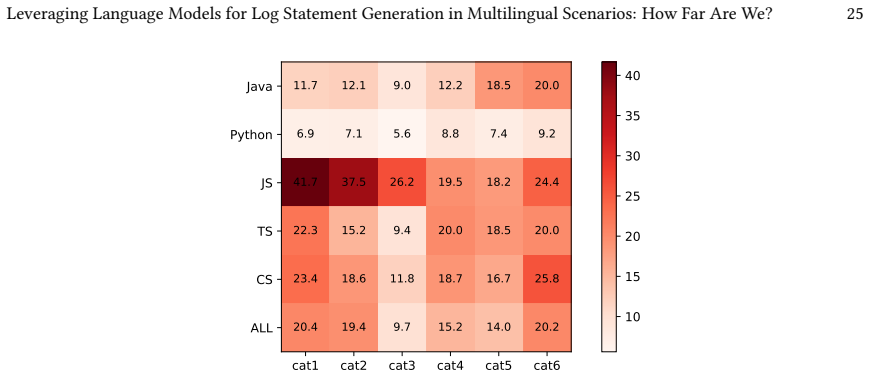
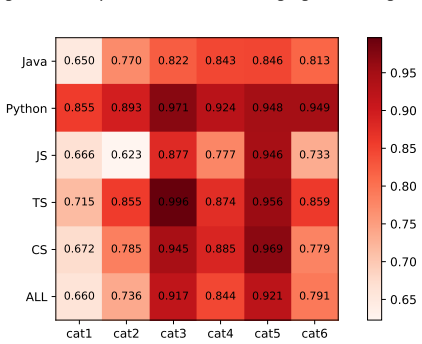
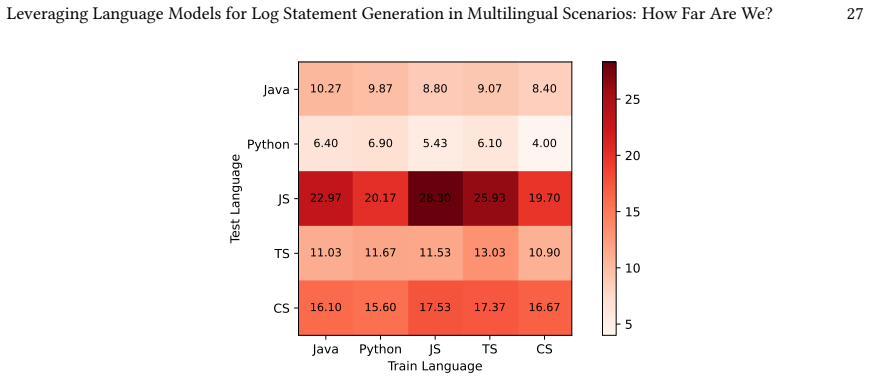


read the original abstract
Log statements capture critical information for software maintenance activities such as testing, debugging, and failure analysis. Because of this importance, developers must carefully design log statements, which requires significant effort. To support developers, various end-to-end automated log statement generation approaches have been proposed, whereas these approaches have mainly been evaluated within a single programming language environment and their effectiveness in multilingual environments remains underexplored. In this paper, we therefore comparatively evaluate three state-of-the-art log statement generation approaches and five large language models (LLMs) across multiple programming languages. For this purpose, we constructed a multilingual benchmark comprising 150,000 instances across five programming languages. Our empirical results demonstrate that UniLog, a state-of-the-art approach, achieves the best overall performance, maintaining high effectiveness even in multilingual environments. We also observe substantial variance in the difficulty of log generation across languages: Python presents a greater challenge, whereas JavaScript yields comparatively better performance. Detailed analysis reveals that these disparities stem from variations in log insertion distributions and language-specific logging idioms. Our findings indicate that simply scaling model size or the volume of training data is insufficient for multilingual log generation; rather, designing approaches tailored to the specific characteristics of target languages is crucial. These findings suggest that future automated logging techniques should explicitly account for language-specific logging characteristics to achieve robust performance in multilingual software development environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates three state-of-the-art automated log statement generation approaches and five LLMs on a constructed multilingual benchmark of 150,000 instances spanning five programming languages. It finds that UniLog performs best overall, with substantial variance in task difficulty across languages (Python most challenging, JavaScript easiest), attributed to differences in log insertion distributions and language-specific idioms. The authors conclude that simply scaling model size or training data volume is insufficient, and that language-tailored approaches are necessary for robust multilingual performance.
Significance. Should the benchmark prove representative and the analysis hold, this work is significant in extending log generation research to multilingual settings and providing empirical evidence against naive scaling. The large-scale benchmark construction represents a concrete contribution that can support future studies in the area.
major comments (1)
- [Methods (benchmark construction and evaluation setup)] The central claim that 'designing approaches tailored to the specific characteristics of target languages is crucial' and that scaling is insufficient rests on the observed performance variance across the five languages being attributable to language-specific properties rather than artifacts. The methods description of the 150,000-instance benchmark provides no information on sampling strategy, stratification by project domain or logging framework, deduplication across languages, controls for code complexity, or steps taken to ensure comparable instance difficulty. This is load-bearing for the recommendation in the abstract and conclusion.
minor comments (1)
- [Abstract] The abstract states clear empirical outcomes but supplies no information on benchmark construction details, chosen metrics, statistical tests, or potential data leakage, so the support for the central claims cannot be fully verified from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological transparency. We address the major comment below and will revise the manuscript accordingly to strengthen the presentation of our benchmark.
read point-by-point responses
-
Referee: The central claim that 'designing approaches tailored to the specific characteristics of target languages is crucial' and that scaling is insufficient rests on the observed performance variance across the five languages being attributable to language-specific properties rather than artifacts. The methods description of the 150,000-instance benchmark provides no information on sampling strategy, stratification by project domain or logging framework, deduplication across languages, controls for code complexity, or steps taken to ensure comparable instance difficulty. This is load-bearing for the recommendation in the abstract and conclusion.
Authors: We agree that the current methods description is insufficiently detailed on these points and that this information is necessary to support our claims. In the revised manuscript we will expand the benchmark construction section to explicitly describe: (1) the sampling strategy (repositories selected from GitHub with language-specific filters and minimum activity thresholds); (2) stratification by project domain and logging framework (where available in the source data); (3) deduplication across languages using normalized code similarity thresholds; (4) controls for code complexity (matching distributions of AST node count and cyclomatic complexity across languages); and (5) steps taken to ensure comparable instance difficulty (balancing the proportion of logging statements and context length). We will also add a dedicated threats-to-validity subsection discussing potential residual confounding. These additions will clarify that the observed performance differences align with language-specific log insertion patterns and idioms rather than benchmark artifacts. revision: yes
Circularity Check
No circularity: empirical results on external benchmark
full rationale
The paper reports measured performance of UniLog and LLMs on a constructed 150k-instance multilingual benchmark, with variance attributed to observed log insertion patterns and idioms. No equations, self-definitional derivations, fitted parameters presented as predictions, or load-bearing self-citations appear. All claims rest on direct comparison against the benchmark data rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jagrit Acharya and Gouri Ginde. 2025. Can We Enhance Bug Report Quality Using LLMs?: An Empirical Study of LLM-Based Bug Report Generation. InProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering. 994–1003
2025
-
[2]
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified Pre-training for Program Understanding and Generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2655–2668
2021
- [3]
-
[4]
2024.Claude 3.5 Sonnet
ANTHROPIC. 2024.Claude 3.5 Sonnet. Retrieved March 5, 2026 from https://www.anthropic.com/news/claude-3-5-sonnet
2024
-
[5]
2026.log4net
Apache Software Foundation. 2026.log4net. Retrieved March 5, 2026 from https://logging.apache.org/log4net/index.html
2026
-
[6]
Siqi Bao, Huang He, Fan Wang, Hua Wu, and Haifeng Wang. 2020. PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 85–96
2020
-
[7]
Boyuan Chen and Zhen Ming (Jack) Jiang. 2021. A Survey of Software Log Instrumentation.Comput. Surveys54, 4 (2021), Article 90
2021
-
[8]
Wei Chen, Yeyun Gong, Song Wang, Bolun Yao, Weizhen Qi, Zhongyu Wei, and Xiaowu et al. Hu. 2022. DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 4852–4864
2022
-
[9]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling Projects in GitHub for MSR Studies. , 560–564 pages
2021
-
[10]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, et al. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zishuo Ding, Heng Li, and Weiyi Shang. 2022. LoGenText: Automatically Generating Logging Texts Using Neural Machine Translation. InProceedings of the 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering. 349–360
2022
-
[12]
Zishuo Ding, Yiming Tang, Xiaoyu Cheng, Heng Li, and Weiyi Shang. 2023. LoGenText-Plus: Improving Neural Machine Translation Based Logging Texts Generation with Syntactic Templates.ACM Transactions on Software Engineering and Methodology33, 2 (2023), Article 38
2023
- [13]
-
[14]
2026.logging Logging facility for Python
Python Software Foundation. 2026.logging Logging facility for Python. Retrieved March 5, 2026 from https://docs.python.org/3.13/library/logging.html
2026
-
[15]
Qiang Fu, Jieming Zhu, Wenlu Hu, Jian-Guang Lou, Rui Ding, Qingwei Lin, Dongmei Zhang, et al. 2014. Where Do Developers Log? An Empirical Study on Logging Practices in Industry. InCompanion Proceedings of the 36th International Conference on Software Engineering. 24–33
2014
-
[16]
2026.google-java-format
Google. 2026.google-java-format. Retrieved March 5, 2026 from https://github.com/google/google-java-format
2026
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, and Aiesha Letman et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Shenghui Gu, Guoping Rong, He Zhang, and Haifeng Shen. 2023. Logging Practices in Software Engineering: A Systematic Mapping Study.IEEE Transactions on Software Engineering49, 2 (2023), 902–923
2023
-
[19]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R. Lyu. 2021. A Survey on Automated Log Analysis for Reliability Engineering.Comput. Surveys54, 6 (2021), Article 130
2021
-
[20]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, and Tianyu Liu et al. 2024. Qwen2.5-Coder Technical Report. arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, and Florian Bressand et al
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, and Florian Bressand et al
- [23]
-
[24]
Kazuki Kusama, Honglin Shu, Masanari Kondo, and Yasutaka Kamei. 2025. How Small is Enough? Empirical Evidence of Quantized Small Language Models for Automated Program Repair. In2025 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 393–399
2025
-
[25]
Heng Li, Tse-Hsun (Peter) Chen, Weiyi Shang, and Ahmed E. Hassan. 2018. Studying Software Logging Using Topic Models.Empirical Software Engineering23, 5 (2018), 2655–2694
2018
-
[26]
Heng Li, Weiyi Shang, Bram Adams, Mohammed Sayagh, and Ahmed E. Hassan. 2021. A Qualitative Study of the Benefits and Costs of Logging From Developers’ Perspectives.IEEE Transactions on Software Engineering47, 12 (2021), 2858–2873
2021
-
[27]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering. arXiv:2507.15003
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. A Diversity-Promoting Objective Function for Neural Conversation Models. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 110–119
2016
-
[29]
Wen Li, Li Li, and Haipeng Cai. 2022. On the vulnerability proneness of multilingual code. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 847–859
2022
-
[30]
Wen Li, Austin Marino, Haoran Yang, Na Meng, Li Li, and Haipeng Cai. 2024. How Are Multilingual Systems Constructed: Characterizing Language Use and Selection in Open-Source Multilingual Software.ACM Transactions on Software Engineering and Methodology33, 3, Article 63 (2024), 46 pages. Manuscript submitted to ACM Leveraging Language Models for Log Statem...
2024
-
[31]
Briand, and Michael R
Yichen Li, Yintong Huo, Zhihan Jiang, Renyi Zhong, Pinjia He, Yuxin Su, Lionel C. Briand, and Michael R. Lyu. 2024. Exploring the Effectiveness of LLMs in Automated Logging Statement Generation: An Empirical Study.IEEE Transactions on Software Engineering(2024)
2024
-
[32]
Yichen Li, Jinyang Liu, Junsong Pu, Zhihan Jiang, Zhuangbin Chen, Xiao He, and Tieying et al. Zhang. 2025. Automated Proactive Logging Quality Improvement for Large-Scale Codebases. In2025 40th IEEE/ACM International Conference on Automated Software Engineering. 3426–3437
2025
-
[33]
Zhenhao Li, Tse-Hsun (Peter) Chen, and Weiyi Shang. 2021. Where Shall We Log? Studying and Suggesting Logging Locations in Code Blocks. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 361–372
2021
-
[34]
Zhenhao Li, Heng Li, Tse-Hsun Peter Chen, and Weiyi Shang. 2021. DeepLV: Suggesting Log Levels Using Ordinal Based Neural Networks. In Proceedings of the 43rd International Conference on Software Engineering. 1461–1472
2021
-
[35]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InProceedings of Text Summarization Branches Out. 74–81
2004
-
[36]
Jiahao Liu, Jun Zeng, Xiang Wang, Kaihang Ji, and Zhenkai Liang. 2022. TeLL: Log Level Suggestions via Modeling Multi-Level Code Block Information. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. 27–38
2022
-
[37]
Antonio Mastropaolo, Valentina Ferrari, Luca Pascarella, and Gabriele Bavota. 2024. Log Statements Generation via Deep Learning: Widening the Support Provided to Developers.Journal of Systems and Software210 (2024), 111947
2024
-
[38]
Antonio Mastropaolo, Luca Pascarella, and Gabriele Bavota. 2022. Using deep learning to generate complete log statements. InProceedings of the 44th International Conference on Software Engineering. 2279–2290
2022
-
[39]
2026..NET documentation
Microsoft. 2026..NET documentation. Retrieved March 5, 2026 from https://learn.microsoft.com/en-us/dotnet/
2026
-
[40]
2026.NLog
NLog. 2026.NLog. Retrieved March 5, 2026 from https://nlog-project.org/
2026
-
[41]
2024.Hello GPT-4o
OpenAI. 2024.Hello GPT-4o. Retrieved March 5, 2026 from https://openai.com/index/hello-gpt-4o/
2024
-
[42]
2024.Introducing GPT-4.1 in the API
OpenAI. 2024.Introducing GPT-4.1 in the API. Retrieved March 5, 2026 from https://openai.com/index/gpt-4-1/
2024
-
[43]
2025.Introducing GPT-5.2
OpenAI. 2025.Introducing GPT-5.2. Retrieved March 5, 2026 from https://openai.com/index/introducing-gpt-5-2/
2025
-
[44]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 311–318
2002
-
[45]
2026.Pino
pino. 2026.Pino. Retrieved March 5, 2026 from https://getpino.io/
2026
-
[46]
2026.Prettier
Prettier. 2026.Prettier. Retrieved March 5, 2026 from https://prettier.io/
2026
-
[47]
2026.Black
Python Software Foundation. 2026.Black. Retrieved March 5, 2026 from https://black.readthedocs.io/
2026
-
[48]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, and Bo Zheng et al. 2025. Qwen2.5 Technical Report. arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
2025.winston: A logger for just about everything
Charlie Robbins. 2025.winston: A logger for just about everything. Retrieved March 5, 2026 from https://github.com/winstonjs/winston
2025
-
[50]
2026.Serilog
Serilog. 2026.Serilog. Retrieved March 5, 2026 from https://serilog.net/
2026
-
[51]
Tatsuya Shirai, Olivier Nourry, Yutaro Kashiwa, Kenji Fujiwara, and Hajimu Iida. 2026. Does Programming Language Matter? An Empirical Study of Fuzzing Bug Detection. InProceedings of the 23rd International Conference on Mining Software Repositories. To appear
2026
- [52]
-
[53]
Honglin Shu, Dong Wang, Antonio Mastropaolo, Gabriele Bavota, and Yasutaka Kamei. 2025. An Empirical Study on Language Models for Generating Log Statements in Test Code.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[54]
2026.Apache Log4j
The Apache Software Foundation. 2026.Apache Log4j. Retrieved March 5, 2026 from https://logging.apache.org/log4j/2.x/
2026
-
[55]
Dong Wang, Junji Yu, Honglin Shu, Michael Fu, Chakkrit Tantithamthavorn, Yasutaka Kamei, and Junjie Chen. 2025. On the Evaluation of Large Language Models in Multilingual Vulnerability Repair.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[56]
Yutong Wang and Cindy Rubio-González. 2025. LLM4FP: LLM-Based Program Generation for Triggering Floating-Point Inconsistencies Across Compilers. InProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. 225–234
2025
-
[57]
Xiaoyuan Xie, Zhipeng Cai, Songqiang Chen, and Jifeng Xuan. 2024. FastLog: An End-to-End Method to Efficiently Generate and Insert Logging Statements. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 26–37
2024
-
[58]
Junjielong Xu, Ziang Cui, Yuan Zhao, Xu Zhang, Shilin He, Pinjia He, and Liqun et al. Li. 2024. UniLog: Automatic Logging via LLM and In-Context Learning. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. Article 14, 12 pages
2024
-
[59]
Haoran Yang, Wen Li, and Haipeng Cai. 2022. Language-agnostic dynamic analysis of multilingual code: promises, pitfalls, and prospects. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1621–1626
2022
-
[60]
Haoran Yang, Weile Lian, Shaowei Wang, and Haipeng Cai. 2023. Demystifying Issues, Challenges, and Solutions for Multilingual Software Development. In2023 IEEE/ACM 45th International Conference on Software Engineering. 1840–1852
2023
-
[61]
Haoran Yang, Yu Nong, Tao Zhang, Xiapu Luo, and Haipeng Cai. 2024. Learning to Detect and Localize Multilingual Bugs.Proceedings of the ACM on Software Engineering1, Article 97 (2024), 24 pages
2024
-
[62]
Ding Yuan, Soyeon Park, and Yuanyuan Zhou. 2012. Characterizing Logging Practices in Open-Source Software. InProceedings of the 34th International Conference on Software Engineering. 102–112
2012
-
[63]
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv:2504.02605 Manuscript submitted to ACM 38 Kazuki ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Renyi Zhong, Yichen Li, Guangba Yu, Wenwei Gu, Jinxi Kuang, Yintong Huo, and Michael R. Lyu. 2025. Larger Is Not Always Better: Exploring Small Open-source Language Models in Logging Statement Generation.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[65]
Lyu, and Dongmei Zhang
Jieming Zhu, Pinjia He, Qiang Fu, Hongyu Zhang, Michael R. Lyu, and Dongmei Zhang. 2015. Learning to Log: Helping Developers Make Informed Logging Decisions. InProceedings of the 37th International Conference on Software Engineering - Volume 1. 415–425. Manuscript submitted to ACM
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.