EfficientGraph-RAG: Structured Retrieval-State Management for Cross-Task Retrieval-Augmented Generation
Pith reviewed 2026-06-29 22:48 UTC · model grok-4.3
The pith
EfficientGraph-RAG treats retrieval-augmented generation as explicit state management to handle complex evidence decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
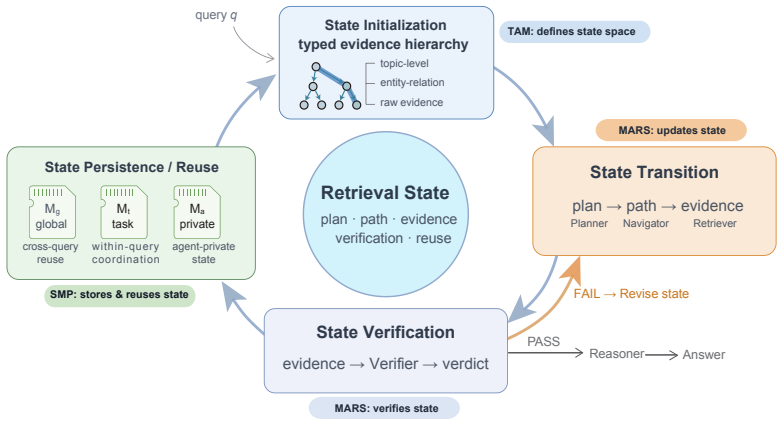
EfficientGraph-RAG defines retrieval state explicitly and manages it through TAM, a typed hierarchical state space over evidence, MARS, role-specialized agents that update and verify the state, and SMP, hierarchy-aware storage for reusable artifacts, producing leading answer-quality metrics on LongBench subsets, HotpotQA parity at 3.51 times lower token cost, and competitive DocVQA efficiency.
What carries the argument
TAM, MARS, and SMP as three coupled mechanisms that make the retrieval state explicit in a typed hierarchical space, update it through specialized agents, and enable controlled reuse.
If this is right
- One shared framework configuration ranks first on the reported answer-quality metrics averaged over the three evaluated LongBench retrieval-style subsets.
- The system matches the strongest agentic baseline on HotpotQA exact match while reducing large-model token usage by 3.51 times.
- It delivers a low-token DocVQA result among retrieval-organizing cross-modal methods.
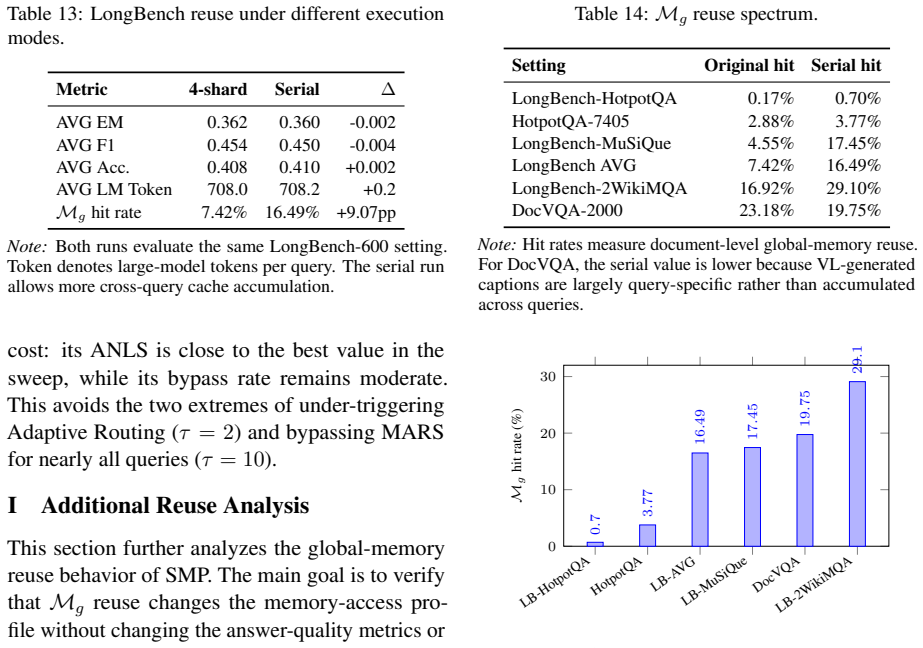
- MARS drives answer quality, TAM supplies typed traversal state and adaptive routing, and SMP enables corpus-dependent reuse with cross-query cache hit rates from 3.77 percent to 23.18 percent.
Where Pith is reading between the lines
- The same state-management pattern could reduce repeated large-model calls in other multi-step retrieval or reasoning pipelines that currently restart from raw context each time.
- Hierarchy-aware caching might allow systems to maintain performance as corpus size grows without proportional increases in per-query token budgets.
- Making verification and reuse explicit could simplify debugging of retrieval failures compared with opaque flat-chunk pipelines.
Load-bearing premise
The typed hierarchical state space and role-specialized agents can be implemented without introducing verification errors or excessive overhead that would offset the reported quality and token gains.
What would settle it
Re-running the LongBench and HotpotQA evaluations after disabling MARS while keeping TAM and SMP, then checking whether answer quality drops below the agentic baseline and token savings vanish, would directly test whether the three mechanisms are jointly responsible for the gains.
Figures


read the original abstract
Retrieval-augmented generation (RAG) has become the standard way to ground large language models in external knowledge, but many systems still organize evidence as flat chunks and retrieve it through largely unstructured search. This weak structure becomes a bottleneck for complex retrieval: the system must decide where to search, how to move from coarse topics to entity-relation evidence, which evidence has been verified, and which intermediate artifacts can be reused. We define these intermediate variables as a retrieval state and study RAG as structured state management. EfficientGraph-RAG makes this state explicit through three coupled mechanisms: TAM defines a typed hierarchical state space over evidence, MARS updates and verifies the state through role-specialized agents, and SMP stores reusable state under hierarchy-aware access control. Using one shared framework configuration, EfficientGraph-RAG ranks first on the reported answer-quality metrics averaged over the three evaluated LongBench retrieval-style subsets, matches the strongest agentic baseline on HotpotQA EM while reducing large-model token usage by $3.51\times$, and provides a low-token DocVQA result among retrieval-organizing cross-modal methods. Component analysis shows role-specific mechanisms: MARS is the main answer-quality driver, TAM supplies the typed traversal state and Adaptive Routing signal, and SMP enables corpus-dependent reuse, with cross-query cache hit rates ranging from 3.77% to 23.18%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EfficientGraph-RAG as a retrieval-augmented generation framework that treats RAG as explicit structured state management. It defines three coupled mechanisms—TAM (a typed hierarchical state space over evidence), MARS (state updates and verification via role-specialized agents), and SMP (reusable state storage under hierarchy-aware access control)—and reports that a single shared configuration ranks first on averaged answer-quality metrics across three LongBench retrieval-style subsets, matches the strongest agentic baseline on HotpotQA exact match while achieving a 3.51× reduction in large-model token usage, and yields a low-token result on DocVQA among cross-modal retrieval-organizing methods. Component ablations attribute quality gains primarily to MARS, traversal signals to TAM, and reuse to SMP (with cross-query cache hit rates of 3.77–23.18%).
Significance. If the empirical rankings and token reductions prove robust under statistical scrutiny and the state-transition rules can be implemented without offsetting overhead, the explicit state-management abstraction could provide a reusable foundation for complex, multi-hop, and cross-modal RAG tasks. The separation of typed traversal, role-specialized verification, and hierarchy-aware caching is a concrete contribution that future work could extend or compare against.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported first-place ranking on LongBench answer-quality metrics and the 3.51× token reduction are presented without error bars, number of runs, or statistical significance tests. This directly undermines the central claim that one configuration outperforms baselines, as the magnitude of improvement cannot be assessed for reliability.
- [§3] §3 (TAM/MARS/SMP definitions): the state-update rules, verification logic in MARS, and access-control policy in SMP are described only at the mechanism level with no formal transition functions, pseudocode, or token-accounting boundary (including agent verification steps). This is load-bearing because the abstract presents the joint effect of TAM/MARS/SMP as producing the benchmark numbers; without these details the claimed efficiency cannot be reproduced or costed.
minor comments (2)
- [Abstract] The three specific LongBench retrieval-style subsets and the exact answer-quality metrics used for the averaged ranking are not named in the abstract or summary tables.
- [Experiments] Dataset details (sizes, splits, preprocessing) and the precise definition of the 'strongest agentic baseline' on HotpotQA are omitted, complicating direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the presentation of results and reproducibility.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported first-place ranking on LongBench answer-quality metrics and the 3.51× token reduction are presented without error bars, number of runs, or statistical significance tests. This directly undermines the central claim that one configuration outperforms baselines, as the magnitude of improvement cannot be assessed for reliability.
Authors: We agree that the absence of error bars, run counts, and significance tests limits the ability to assess reliability. In the revised manuscript we will report results averaged over multiple independent runs with standard deviations and will include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the primary LongBench and HotpotQA comparisons. revision: yes
-
Referee: [§3] §3 (TAM/MARS/SMP definitions): the state-update rules, verification logic in MARS, and access-control policy in SMP are described only at the mechanism level with no formal transition functions, pseudocode, or token-accounting boundary (including agent verification steps). This is load-bearing because the abstract presents the joint effect of TAM/MARS/SMP as producing the benchmark numbers; without these details the claimed efficiency cannot be reproduced or costed.
Authors: We acknowledge that §3 currently presents the mechanisms at a descriptive level. To improve reproducibility we will add formal state-transition functions, pseudocode for MARS verification and SMP access control, and explicit token-accounting boundaries that include the agent verification steps. These additions will be placed in §3 and the appendix. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents an empirical RAG framework (TAM/MARS/SMP) whose central claims are benchmark rankings and token reductions measured on LongBench, HotpotQA and DocVQA. No equations, fitted parameters, or first-principles derivations appear; the reported outcomes are external experimental results rather than quantities forced by internal definitions or self-citations. Component analysis attributes performance to the three mechanisms but does not redefine any metric in terms of itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG : Learning to retrieve, generate, and critique through self-reflection. In International Conference on Learning Representations (ICLR)
2024
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench : A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 3119--3137
2024
-
[3]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1877--1901
2020
-
[4]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. https://arxiv.org/abs/2312.10997 Retrieval-Augmented Generation for Large Language Models: A Survey . arXiv preprint arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics (COLING), pages 6609--6625
2020
-
[7]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459--9474
2020
-
[8]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. 2023. BLIP-2 : Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning (ICML)
2023
-
[9]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, Junpeng Ren, Zehao Lin, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhiqiang Yin, Qingchen Yu, Bo Tang, and 3 others. 2025. https://arxiv.org/abs/2505.22101 MemOS : An operating system for memory-augmented generation ( MAG ) in larg...
-
[10]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[11]
Minesh Mathew, Dimosthenis Karatzas, and C. V. Jawahar. 2021. DocVQA : A dataset for VQA on document images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2200--2209
2021
-
[12]
OpenAI . 2023. GPT-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT : Towards LLM s as operating systems. arXiv preprint arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR : Recursive abstractive processing for tree-organized retrieval. In International Conference on Learning Representations (ICLR)
2024
-
[16]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agentic retrieval-augmented generation: A survey on agentic RAG . arXiv preprint arXiv:2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA : Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue : Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics (TACL), 10:539--554
2022
-
[19]
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. 2025. https://arxiv.org/abs/2406.04692 Mixture-of-Agents Enhances Large Language Model Capabilities . In Proceedings of the International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. 2023. Augmenting language models with long-term memory. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[21]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2369--2380
2018
-
[22]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR)
2023
-
[23]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. MemoryBank : Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence
2024
-
[24]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[25]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.