Anatomy-Anchored Self-Supervision: Distilling Vision Foundation Models for Invariant Ultrasound Representation
Pith reviewed 2026-06-29 23:07 UTC · model grok-4.3
The pith
Anatomy-anchored self-supervision learns view-invariant ultrasound representations by distilling anatomical structures from vision foundation models without new labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
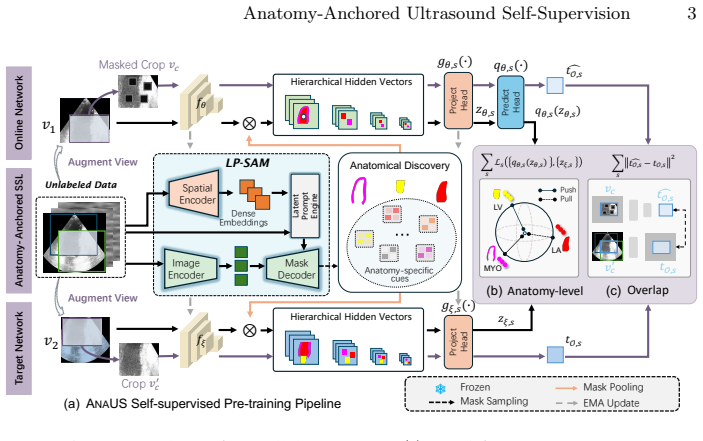
By anchoring representation learning to anatomical structures identified through a one-time-adapted latent-prompt SAM module, the dual-policy framework of semantics-aware anatomy-separating alignment and contextual core-region prediction produces features that remain invariant across different views of the same anatomy yet remain discriminative across distinct structures, yielding stronger downstream performance than image-level or frame-level self-supervision.
What carries the argument
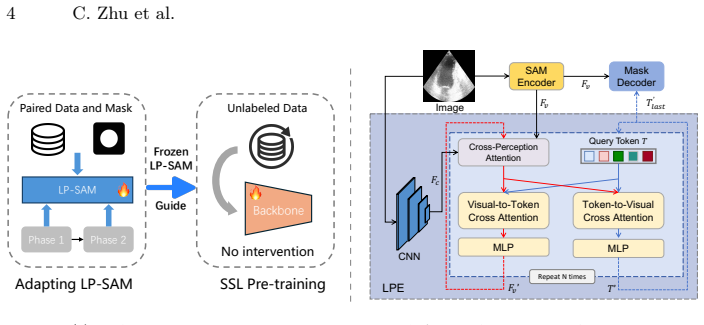
The LP-SAM module (learnable latent prompt engine plus one-time domain-adapted SAM) that supplies annotation-free anatomy masks, combined with the dual-policy self-supervised objectives of inter-view anatomy alignment and core-region reconstruction.
If this is right
- Features extracted from the same anatomical structure become consistent across different imaging views and angles.
- The model must recover fine-grained internal details of anatomical regions when parts are masked or corrupted.
- Downstream ultrasound tasks receive representations already aligned with clinical structures rather than generic visual patches.
- The method retains the inference speed of the underlying foundation model, supporting real-time clinical use.
Where Pith is reading between the lines
- If public mask collections exist for other modalities, the same one-time adaptation step could be reused to anchor self-supervision in those domains.
- The approach reduces dependence on expert-drawn labels for every new ultrasound dataset or scanner.
- The separation of anatomy-specific features may help models generalize across different ultrasound machines or patient populations.
Load-bearing premise
A single domain adaptation step on existing public image-mask pairs is enough for the latent prompt engine to produce reliable anatomy delineations on new ultrasound images without any additional labels.
What would settle it
Run the LP-SAM on a held-out ultrasound dataset never seen during the one-time adaptation and measure whether the resulting anatomy masks produce lower or equal downstream task accuracy compared with a version that uses no anatomy guidance at all.
Figures
read the original abstract
Self-supervised pre-training paradigm has gained increasing prominence for learning transferable representations in medical imaging, yet existing methods for ultrasound (US) images operate at the image or frame level, overlooking the anatomical context for clinical-aligned representation learning. In this work, we propose an anatomy-anchored ultrasound self-supervision framework ANAUS that shifts representation learning from generic visual regions to clinically meaningful anatomical structures. Utilizing a learnable latent prompt engine alongside a one-time domain adaptation on existing public image-mask pairs, we empower the LP-SAM module to achieve annotation-free anatomy delineation at scale. Building upon this anatomical grounding, we propose a dual-policy self-supervised learning paradigm consisting of inter-view semantics-aware anatomy-separating alignment and contextual core-region prediction to enhance representation learning. Specifically, the former enforces feature invariance within identical anatomical regions while promoting discriminability across distinct structures; the latter compels the model to reconstruct corrupted regions, thereby capturing fine-grained structural details. Extensive evaluations on six public datasets demonstrate that ANAUS consistently outstrips current state-of-the-art methods while maintaining the computational efficiency essential for clinical deployment. Code is available at https://github.com/zhcz328/ANAUS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ANAUS, an anatomy-anchored self-supervised pre-training framework for ultrasound images. It employs a learnable latent prompt engine (LP-SAM) with one-time domain adaptation on public image-mask pairs to enable annotation-free anatomy delineation at scale. A dual-policy SSL paradigm is introduced consisting of inter-view semantics-aware anatomy-separating alignment (enforcing invariance within anatomical regions) and contextual core-region prediction (reconstructing corrupted regions). The authors claim that this yields representations that consistently outperform current state-of-the-art methods on six public datasets while preserving computational efficiency for clinical use. Code is released at the provided GitHub link.
Significance. If the central claims hold, the work could meaningfully advance self-supervised representation learning in ultrasound by shifting from generic visual features to clinically meaningful anatomical structures, potentially improving downstream task performance in a domain where annotations are scarce. The one-time adaptation strategy and code release are strengths that support scalability and reproducibility. However, the significance is tempered by the need to confirm that performance gains are attributable to the proposed anatomical grounding rather than other factors.
major comments (3)
- [§3.2] §3.2 (LP-SAM module and domain adaptation): No direct quantitative validation (e.g., Dice/IoU scores, visual comparisons, or consistency metrics across probe/frequency shifts) of the annotation-free masks produced by the adapted LP-SAM is reported on the six target evaluation datasets. This is load-bearing for the central claim, as the inter-view alignment and core-region prediction objectives explicitly rely on these masks for anatomical grounding; without it, gains cannot be confidently attributed to the proposed mechanism.
- [Table 2] Table 2 (main quantitative results) and §4.1 (experimental setup): The reported outperformance lacks accompanying statistical significance tests, confidence intervals, or details on the number of runs, undermining the assertion that ANAUS 'consistently outstrips' SOTA methods across all six datasets.
- [§4.3] §4.3 (ablation studies): The contribution of the anatomy-separating alignment policy versus standard contrastive objectives is not isolated; an ablation removing the LP-SAM-derived anatomical regions would be required to confirm that the dual-policy design drives the observed gains.
minor comments (2)
- [§3.4] The notation for the dual-policy objectives (e.g., the exact formulation of the inter-view alignment loss) could be clarified with an explicit equation in §3.4 to aid reproducibility.
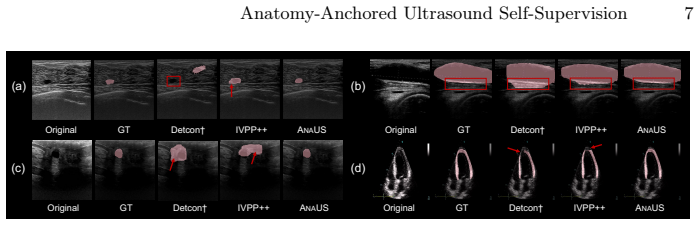
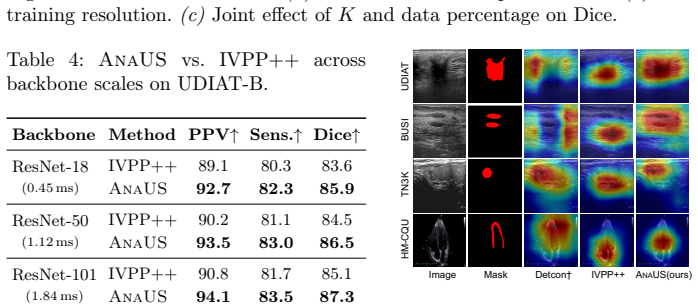
- [Figure 3] Figure 3 (qualitative results) would benefit from side-by-side comparison of LP-SAM masks against any available ground-truth annotations on the evaluation sets to illustrate delineation quality.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the attribution of our results to the proposed anatomical grounding. We address each major point below and will incorporate the requested validations and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LP-SAM module and domain adaptation): No direct quantitative validation (e.g., Dice/IoU scores, visual comparisons, or consistency metrics across probe/frequency shifts) of the annotation-free masks produced by the adapted LP-SAM is reported on the six target evaluation datasets. This is load-bearing for the central claim, as the inter-view alignment and core-region prediction objectives explicitly rely on these masks for anatomical grounding; without it, gains cannot be confidently attributed to the proposed mechanism.
Authors: We agree this validation is important for attributing gains to the anatomical mechanism. While §3.2 describes the one-time adaptation and we include qualitative mask examples in the supplement, we did not report Dice/IoU or cross-probe consistency metrics on the six target datasets. In revision we will add quantitative evaluation (Dice/IoU where partial annotations exist, plus consistency metrics across probe/frequency shifts) to directly support the load-bearing role of the LP-SAM masks. revision: yes
-
Referee: [Table 2] Table 2 (main quantitative results) and §4.1 (experimental setup): The reported outperformance lacks accompanying statistical significance tests, confidence intervals, or details on the number of runs, undermining the assertion that ANAUS 'consistently outstrips' SOTA methods across all six datasets.
Authors: We acknowledge the need for statistical rigor. Table 2 reports single-run results due to compute limits. In the revision we will rerun experiments with multiple random seeds (at least three), report means ± standard deviations, confidence intervals, and paired statistical significance tests (e.g., Wilcoxon or t-tests) against the strongest baselines to substantiate the 'consistently outstrips' claim. revision: yes
-
Referee: [§4.3] §4.3 (ablation studies): The contribution of the anatomy-separating alignment policy versus standard contrastive objectives is not isolated; an ablation removing the LP-SAM-derived anatomical regions would be required to confirm that the dual-policy design drives the observed gains.
Authors: We agree that isolating the effect of the LP-SAM-derived regions is necessary. Our existing §4.3 ablations compare dual-policy variants but do not include a direct control that removes anatomical region information. In revision we will add an ablation that replaces the anatomy-separating alignment with a standard contrastive objective operating on whole-image features (no LP-SAM masks), thereby quantifying the incremental benefit of the anatomical grounding. revision: yes
Circularity Check
No circularity: empirical claims rest on external dataset evaluations, not self-referential fits or derivations.
full rationale
The paper describes a proposed ANAUS framework that uses a learnable latent prompt engine and one-time domain adaptation to enable LP-SAM for anatomy delineation, followed by dual-policy self-supervised objectives (inter-view alignment and core-region prediction). No equations, derivations, or first-principles predictions appear in the abstract or description. The central claims of outperformance are tied to evaluations on six public datasets rather than any reduction of outputs to fitted inputs or self-citations by construction. This is a standard empirical method paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data in brief28, 104863 (2020)
Al-Dhabyani, W., Gomaa, M., Khaled, H., Fahmy, A.: Dataset of breast ultrasound images. Data in brief28, 104863 (2020)
2020
-
[2]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Basu, S., Singla, S., Gupta, M., Rana, P., Gupta, P., Arora, C.: Unsupervised contrastive learning of image representations from ultrasound videos with hard negative mining. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 423–433. Springer (2022)
2022
-
[3]
IETE Technical Review32(6), 435–453 (2015)
Biradar, N., Dewal, M.L., Rohit, M.K.: Speckle noise reduction in b-mode echocar- diographic images: A comparison. IETE Technical Review32(6), 435–453 (2015)
2015
-
[4]
Applied Sciences11(2), 672 (2021)
Born, J., Wiedemann, N., Cossio, M., Buhre, C., Brändle, G., Leidermann, K., Goulet, J., Aujayeb, A., Moor, M., Rieck, B., et al.: Accelerating detection of lung pathologies with explainable ultrasound image analysis. Applied Sciences11(2), 672 (2021)
2021
-
[5]
https://www.butterflynetwork.com/index
ButterflyNetwork: Butterfly videos. https://www.butterflynetwork.com/index. html (2020), accessed: September 20, 2020
2020
-
[6]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PMLR (2020)
2020
-
[7]
Improved Baselines with Momentum Contrastive Learning
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum con- trastive learning. arXiv preprint arXiv:2003.04297 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[8]
Chen, Y., Zhang, C., Liu, L., Feng, C., Dong, C., Luo, Y., Wan, X.: Uscl: pretrain- ing deep ultrasound image diagnosis model through video contrastive representa- tion learning. In: Medical image computing and computer assisted intervention– MICCAI 2021: 24th International conference, Strasbourg, France, September 27– October 1, 2021, Proceedings, Part V...
2021
-
[9]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009) 10 C. Zhu et al
2009
-
[10]
In: Eu- ropean Conference on Computer Vision
Fu, Z., Jiao, J., Yasrab, R., Drukker, L., Papageorghiou, A.T., Noble, J.A.: Anatomy-aware contrastive representation learning for fetal ultrasound. In: Eu- ropean Conference on Computer Vision. pp. 422–436. Springer (2022)
2022
-
[11]
In: 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI)
Gao, Y., Maraci, M.A., Noble, J.A.: Describing ultrasound video content using deep convolutional neural networks. In: 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI). pp. 787–790. IEEE (2016)
2016
- [12]
-
[13]
Computers in biology and medicine155, 106389 (2023)
Gong, H., Chen, J., Chen, G., Li, H., Li, G., Chen, F.: Thyroid region prior guided attention for ultrasound segmentation of thyroid nodules. Computers in biology and medicine155, 106389 (2023)
2023
-
[14]
Advances in neural information processing systems33, 21271–21284 (2020)
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Do- ersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al.: Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems33, 21271–21284 (2020)
2020
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9729–9738 (2020)
2020
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hénaff, O.J., Koppula, S., Alayrac, J.B., Van den Oord, A., Vinyals, O., Carreira, J.: Efficient visual pretraining with contrastive detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10086–10096 (2021)
2021
-
[18]
IEEE Journal of Biomedical and Health Informatics (2025)
Jiang, C., Zhu, C., Guo, H., Tan, G., Liu, C., Li, K.: Mcbl-unet: A hybrid mamba- cnn boundary enhanced light-weight unet for placenta ultrasound image segmen- tation. IEEE Journal of Biomedical and Health Informatics (2025)
2025
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4015–4026 (2023)
2023
-
[20]
IEEE trans- actions on medical imaging38(9), 2198–2210 (2019)
Leclerc, S., Smistad, E., Pedrosa, J., Østvik, A., Cervenansky, F., Espinosa, F., Espeland, T., Berg, E.A.R., Jodoin, P.M., Grenier, T., et al.: Deep learning for seg- mentation using an open large-scale dataset in 2d echocardiography. IEEE trans- actions on medical imaging38(9), 2198–2210 (2019)
2019
-
[21]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
2017
-
[22]
arXiv preprint arXiv:2510.22990 (2025)
Megahed, Y., Ducharme, R., Erman, A., Walker, M., Hawken, S., Chan, A.D.: Usf-mae: Ultrasound self-supervised foundation model with masked autoencoding. arXiv preprint arXiv:2510.22990 (2025)
-
[23]
In: 10th International symposium on medical information processing and analysis
Pedraza, L., Vargas, C., Narváez, F., Durán, O., Muñoz, E., Romero, E.: An open access thyroid ultrasound image database. In: 10th International symposium on medical information processing and analysis. vol. 9287, pp. 188–193. SPIE (2015)
2015
-
[24]
Nature neuroscience2(1), 79–87 (1999)
Rao, R.P., Ballard, D.H.: Predictive coding in the visual cortex: a functional inter- pretation of some extra-classical receptive-field effects. Nature neuroscience2(1), 79–87 (1999)
1999
-
[25]
Advances in neural information processing systems33, 596–608 (2020)
Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C.A., Cubuk, E.D., Kurakin, A., Li, C.L.: Fixmatch: Simplifying semi-supervised learning with Anatomy-Anchored Ultrasound Self-Supervision 11 consistency and confidence. Advances in neural information processing systems33, 596–608 (2020)
2020
-
[26]
arXiv preprint arXiv:2403.07715 (2024)
VanBerlo, B., Wong, A., Hoey, J., Arntfield, R.: Intra-video positive pairs in self- supervised learning for ultrasound. arXiv preprint arXiv:2403.07715 (2024)
-
[27]
Advances in Neural Information Processing Systems (2017)
Vaswani, A.: Attention is all you need. Advances in Neural Information Processing Systems (2017)
2017
-
[28]
Advances in neural information processing systems35, 16423–16438 (2022)
Wen, X., Zhao, B., Zheng, A., Zhang, X., Qi, X.: Self-supervised visual representa- tion learning with semantic grouping. Advances in neural information processing systems35, 16423–16438 (2022)
2022
-
[29]
Qiao, Y ., Zhang, C., Kang, T., Kim, D., Zhang, C., and Hong, C
Wu, J., Ji, W., Liu, Y., Fu, H., Xu, M., Xu, Y., Jin, Y.: Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv preprint arXiv:2304.12620 (2023)
-
[30]
In: Medical Imaging 2017: Image Processing
Wunderling, T., Golla, B., Poudel, P., Arens, C., Friebe, M., Hansen, C.: Com- parison of thyroid segmentation techniques for 3d ultrasound. In: Medical Imaging 2017: Image Processing. vol. 10133, pp. 346–352. SPIE (2017)
2017
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., Hu, H.: Simmim: A simple framework for masked image modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9653–9663 (2022)
2022
-
[32]
Artificial Intelligence in Medicine107, 101880 (2020)
Yap, M.H., Goyal, M., Osman, F., Martí, R., Denton, E., Juette, A., Zwiggelaar, R.: Breast ultrasound region of interest detection and lesion localisation. Artificial Intelligence in Medicine107, 101880 (2020)
2020
-
[33]
In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
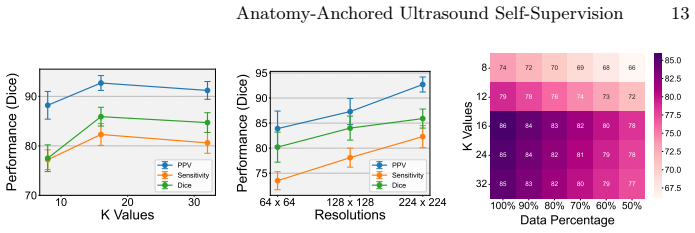
Zhu, C., Lin, J., Tan, G., Zhu, N., Li, K., Wang, C., Li, S.: Advancing ultrasound medical continuous learning with task-specific generalization and adaptability. In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). pp. 3019–3025. IEEE (2024) 12 C. Zhu et al. Table 3: Hyperparameter sensitivity on UDIAT-B (Dice, %). Default set...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.