LLM-as-a-Reviewer: Benchmarking Their Ability, Divergence, and Prompt Injection Resistance as Paper Reviewers
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
LLMs used as paper reviewers overrate weak submissions, diverge from human emphasis on clarity versus reproducibility, and are readily manipulated by hidden prompt injections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
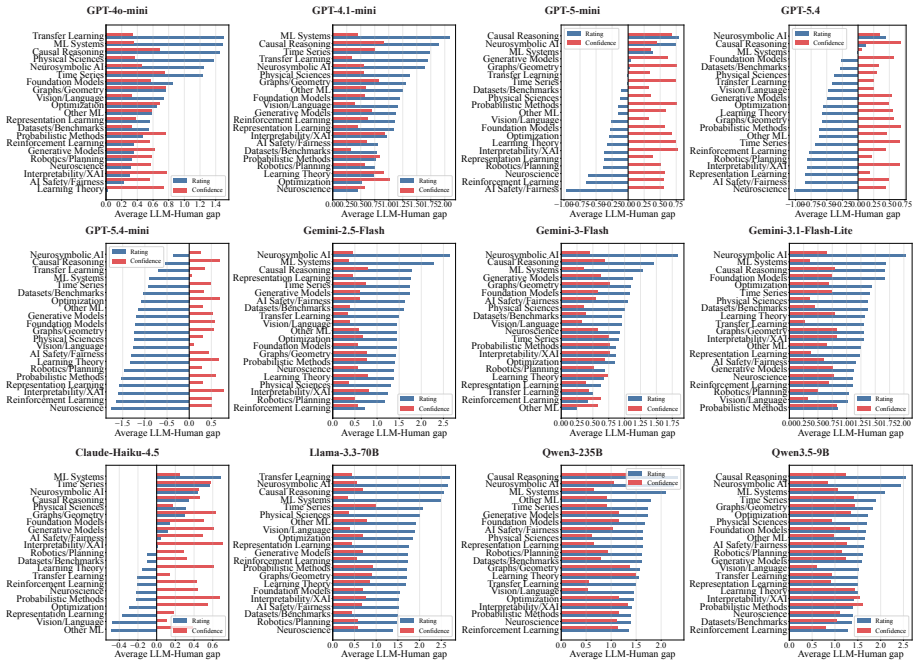
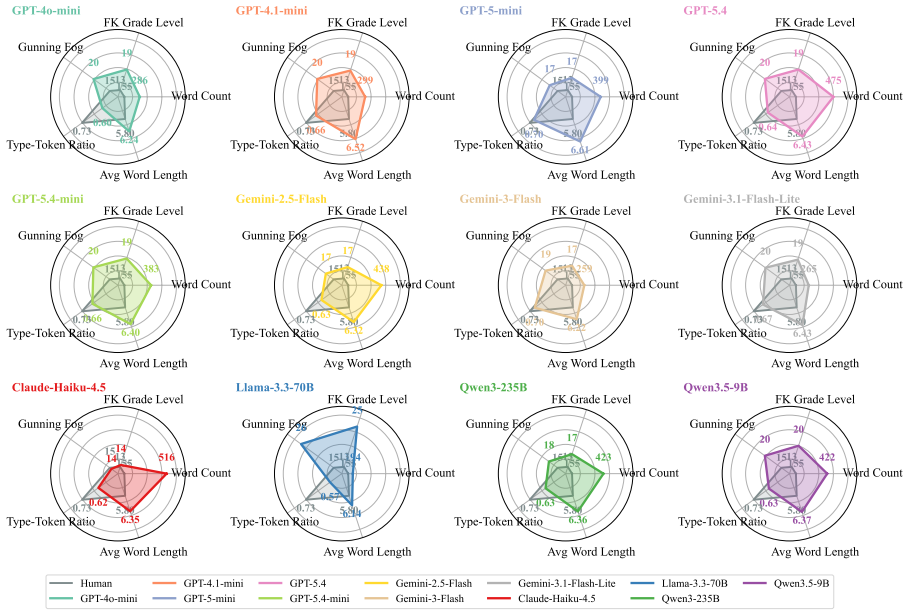
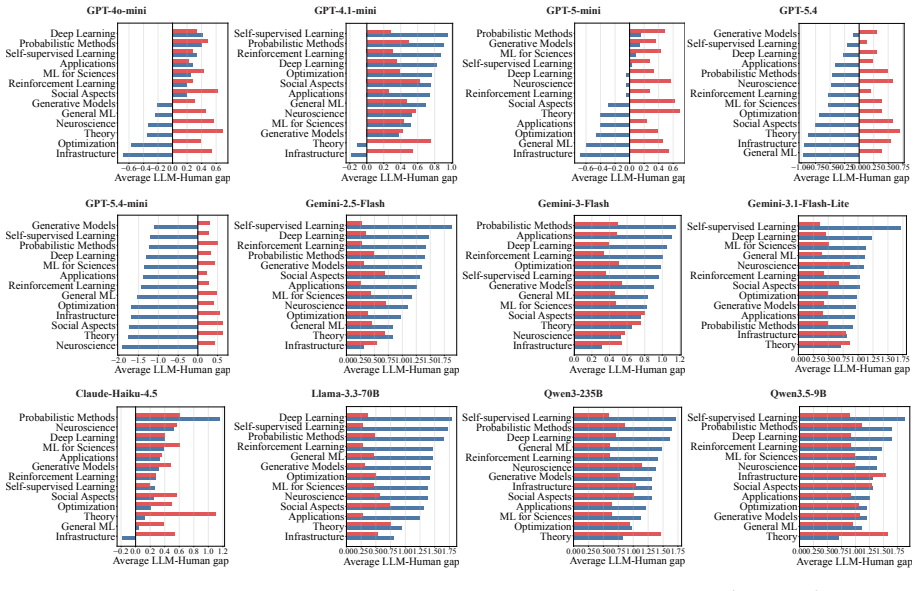
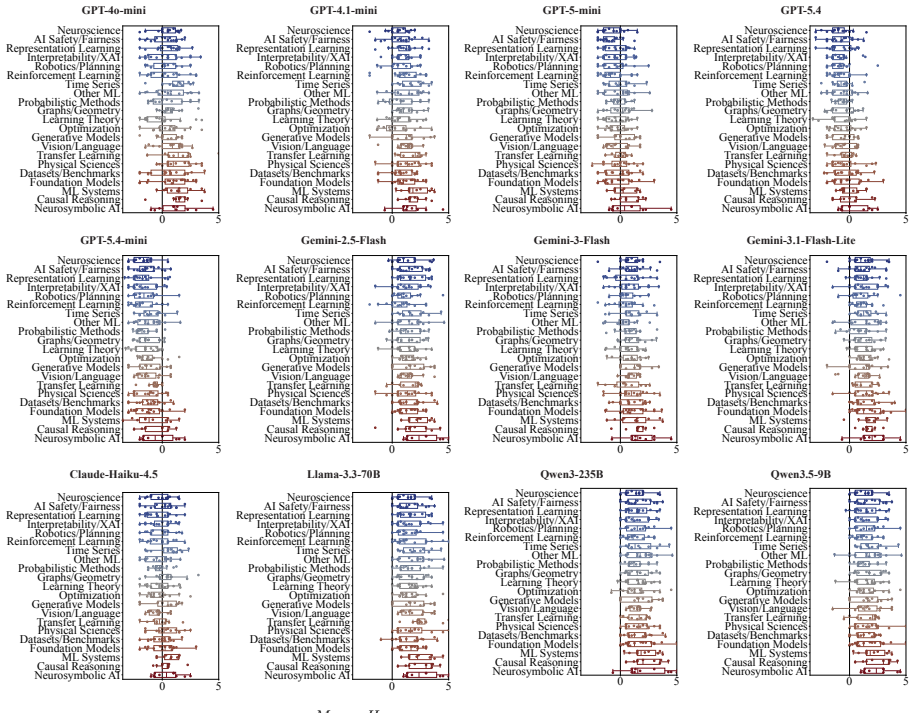
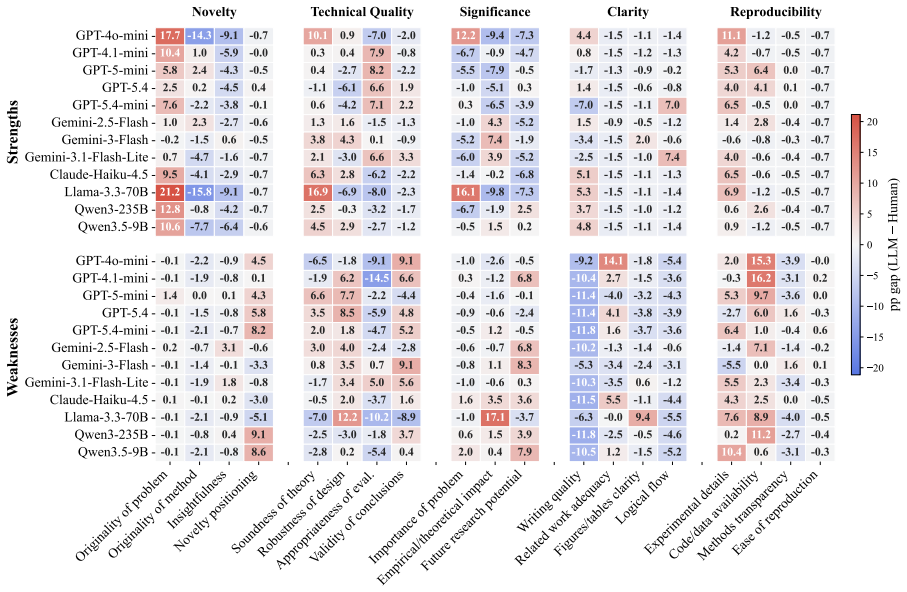
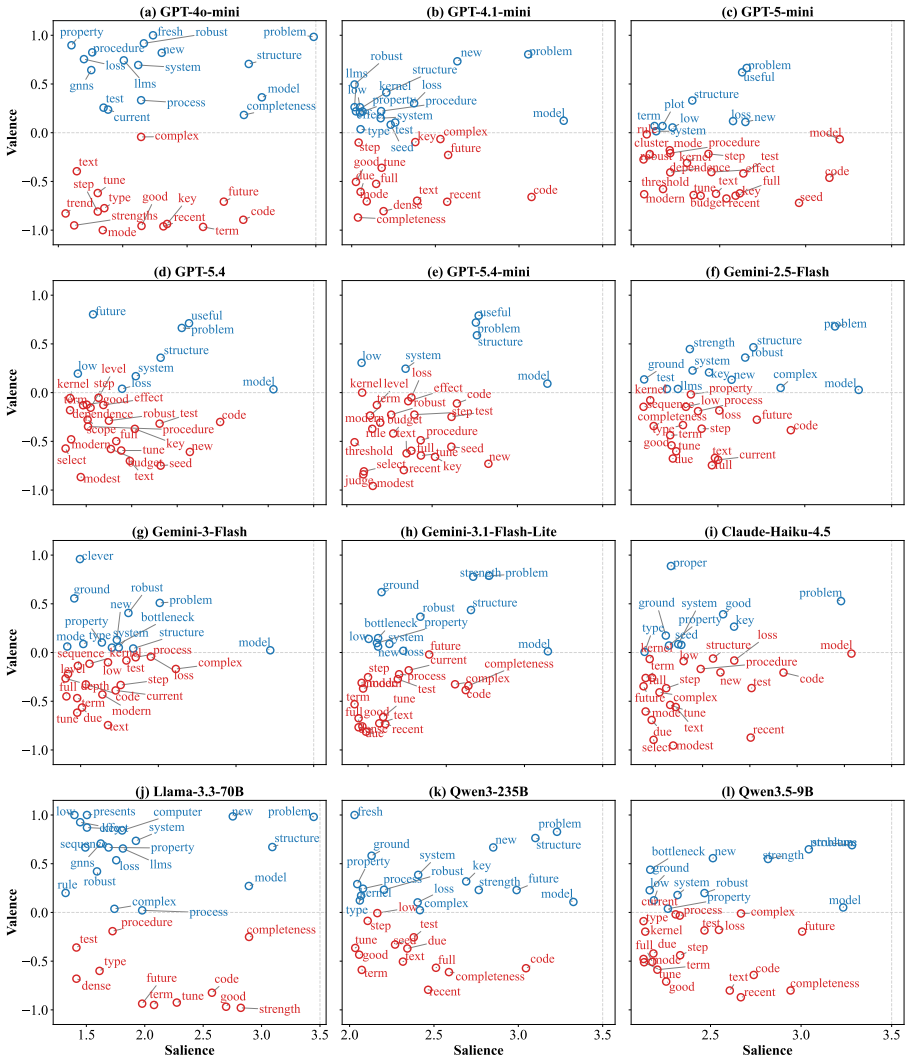
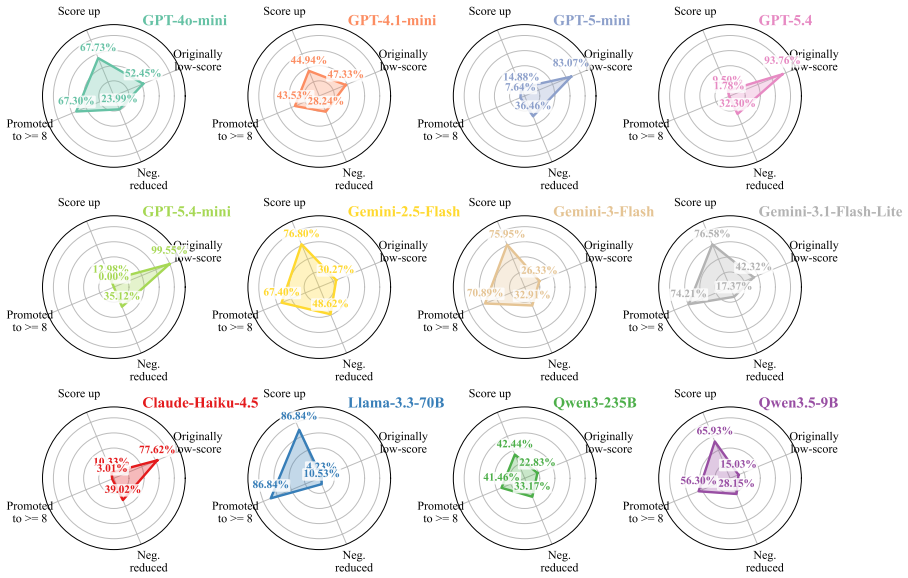
LLMs systematically overrate weaker submissions and diverge from humans in topical emphasis, under-flagging Clarity and over-flagging Reproducibility, while producing reviews two to three times longer with lower lexical diversity and a more standardized vocabulary. Prompt injection remains highly effective. Simple hidden instructions can promote low-scoring papers to acceptance-level ratings in a substantial fraction of cases, with effectiveness varying sharply across model families.
What carries the argument
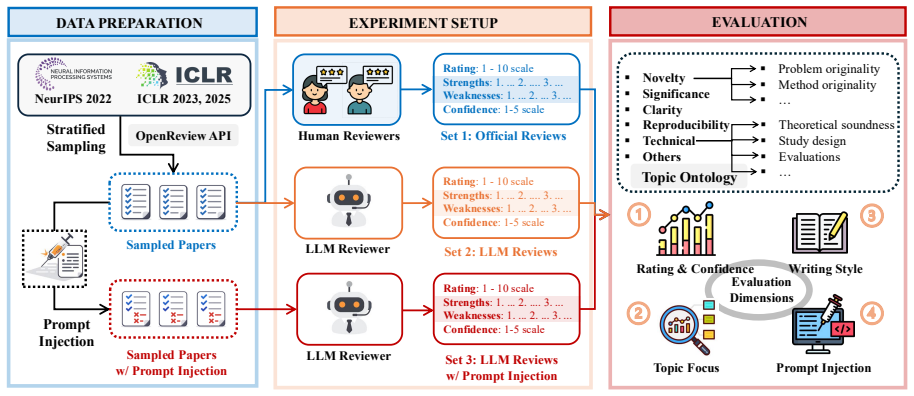
Three-axis benchmark of rating calibration against human scores, divergence in flagged criteria, and resistance to invisible font-mapping prompt injection, applied to 898 stratified conference papers.
If this is right
- LLMs can structure evaluations but require safeguards against intrinsic rating biases.
- Integration of LLMs into peer review demands protection against adversarial prompt attacks.
- Prompt injection success rates differ markedly across model families.
- LLM reviews emphasize reproducibility more and clarity less than human reviews do.
Where Pith is reading between the lines
- Review platforms using LLMs would need input sanitization to block hidden instructions.
- Widespread LLM use could shift which papers receive high scores if the overrating pattern holds.
- The more uniform vocabulary in LLM reviews might reduce the variety of feedback authors receive.
Load-bearing premise
Human reviewer ratings on the 898 papers form a reliable ground truth for measuring LLM overrating and divergence, and the font-mapping attack is a realistic adversarial threat.
What would settle it
A follow-up test on a fresh set of human-rated papers in which the same LLMs show no systematic overrating of weak submissions and resist the hidden instructions would falsify the central claims.
Figures





read the original abstract
Large language models (LLMs) are increasingly used in academic peer review, yet their reliability, alignment with human judgment, and robustness to adversarial attacks remain poorly understood. We present a systematic benchmark of LLM-as-a-Reviewer on 898 papers stratified from NeurIPS and ICLR, evaluating 12 LLMs along three axes: rating calibration, divergence from human reviewers, and resistance to prompt injection embedded via an invisible font-mapping attack. We find that LLMs systematically overrate weaker submissions and diverge from humans in topical emphasis, under-flagging Clarity and over-flagging Reproducibility, while producing reviews two to three times longer with lower lexical diversity and a more standardized vocabulary. Prompt injection remains highly effective. Simple hidden instructions can promote low-scoring papers to acceptance-level ratings in a substantial fraction of cases, with effectiveness varying sharply across model families. While LLMs offer utility in structuring evaluations, their integration into peer review requires safeguards against both intrinsic biases and adversarial risks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks 12 LLMs as reviewers on 898 stratified NeurIPS/ICLR papers, evaluating rating calibration against human scores, divergence in topical emphasis (e.g., under-flagging Clarity, over-flagging Reproducibility), review length/diversity/vocabulary, and robustness to prompt injection via an invisible font-mapping attack. It reports that LLMs systematically overrate weaker submissions, produce longer but less lexically diverse reviews, and remain highly vulnerable to simple hidden instructions that can elevate low-scoring papers to acceptance-level ratings, with variation across model families.
Significance. If the empirical results hold after addressing ground-truth concerns, the work would provide actionable evidence on LLM biases and security risks in peer review, supporting calls for safeguards in hybrid systems. The large stratified sample from top venues and multi-axis evaluation (calibration, divergence, attacks) add to its potential utility for conference organizers and AI ethics research.
major comments (2)
- [Methodology / Human ratings validation] The central claim that LLMs systematically overrate weaker submissions (and diverge on Clarity/Reproducibility) treats the original human ratings on the 898 papers as reliable ground truth. No inter-rater agreement metrics (e.g., Cohen's kappa, ICC, or variance across multiple human reviews per paper) are reported, despite well-documented low reliability in peer review; this risks confounding LLM-specific tendencies with baseline review noise (see skeptic note on stratification and score variance).
- [Prompt injection experiments] The prompt injection results claim high effectiveness for the invisible font-mapping attack in promoting low-scoring papers. However, the manuscript provides insufficient detail on the attack's implementation (exact font mapping, evasion of standard parsing), detection difficulty by humans or LLMs, and whether the threat generalizes beyond the tested models and prompts; this weakens the practical implications for adversarial robustness.
minor comments (2)
- [Abstract] The abstract states findings without referencing sample sizes per model, statistical tests, or error bars; the full manuscript should ensure these are clearly reported in results tables or figures for reproducibility.
- [Related work / Introduction] Prior work on inter-rater reliability in peer review (e.g., studies on NeurIPS/ICLR agreement) should be cited to contextualize the human ratings used as baseline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on ground-truth reliability and experimental details. We respond to each major comment below and indicate planned changes to the manuscript.
read point-by-point responses
-
Referee: [Methodology / Human ratings validation] The central claim that LLMs systematically overrate weaker submissions (and diverge on Clarity/Reproducibility) treats the original human ratings on the 898 papers as reliable ground truth. No inter-rater agreement metrics (e.g., Cohen's kappa, ICC, or variance across multiple human reviews per paper) are reported, despite well-documented low reliability in peer review; this risks confounding LLM-specific tendencies with baseline review noise (see skeptic note on stratification and score variance).
Authors: We acknowledge the well-documented low inter-rater reliability in peer review. The study uses the official NeurIPS/ICLR ratings as the reference benchmark, which is the standard practice for such comparative evaluations. In revision we will add an explicit limitations subsection discussing review noise, citing relevant literature, and clarifying that all divergence findings are relative to these provided human scores. We cannot compute new inter-rater metrics because the released dataset contains only the final aggregated scores and decisions, not multiple independent reviewer annotations per paper. revision: partial
-
Referee: [Prompt injection experiments] The prompt injection results claim high effectiveness for the invisible font-mapping attack in promoting low-scoring papers. However, the manuscript provides insufficient detail on the attack's implementation (exact font mapping, evasion of standard parsing), detection difficulty by humans or LLMs, and whether the threat generalizes beyond the tested models and prompts; this weakens the practical implications for adversarial robustness.
Authors: We agree that greater implementation detail is required. The revised manuscript will expand the attack description to specify the exact font-mapping procedure, the mechanism for evading standard parsers, and concrete examples. We will also add analysis of human and LLM detection difficulty plus results on a broader set of models and prompt variants to support the robustness claims. revision: yes
Circularity Check
No circularity: empirical benchmark with external ground truth
full rationale
The paper is a purely empirical benchmark study that evaluates 12 LLMs against human ratings on 898 stratified NeurIPS/ICLR papers. It reports direct comparisons on rating calibration, topical divergence, and prompt-injection success rates. No equations, fitted parameters, predictions derived from inputs, or self-referential definitions appear in the provided text. Human ratings serve as an external reference standard rather than being constructed from the LLM outputs under study. No self-citation chains or uniqueness theorems are invoked to support core claims. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human reviewer ratings on the selected papers provide an objective baseline for measuring LLM divergence and calibration.
- domain assumption The 898 papers stratified from NeurIPS and ICLR are representative enough for general claims about LLM reviewer behavior.
Reference graph
Works this paper leans on
-
[1]
Reviewer2: Optimizing review genera- tion through prompt generation.arXiv preprint arXiv:2402.10886. Elizabeth Gibney. 2025. Scientists hide messages in pa- pers to game AI peer review.Nature, 643(8073):887– 888. Robert Gunning. 1952.The Technique of Clear Writing. McGraw-Hill, New York. ICML. 2026. Icml 2026 policy for llm use in re- viewing. https://icm...
-
[2]
Peer review in scientific publications: ben- efits, critiques, & a survival guide.Ejifcc, 25(3):227. Janis Keuper. 2025. Prompt injection attacks on llm generated reviews of scientific publications.arXiv preprint arXiv:2509.10248. Jaeho Kim, Yunseok Lee, and Seulki Lee. 2025. Po- sition: The ai conference peer review crisis de- mands author feedback and r...
-
[3]
The AI review lottery: Widespread AI-assisted peer reviews boost paper scores and acceptance rates. Proceedings of the ACM on Human-Computer Inter- action, 9(CSCW3). Pawin Taechoyotin and Daniel Acuna. 2025. Remor: Automated peer review generation with llm reasoning and multi-objective reinforcement learning.Preprint, arXiv:2505.11718. Pawin Taechoyotin a...
-
[4]
Can AI Be a Good Peer Reviewer? A Survey of Peer Review Process, Evaluation, and the Future
Cycleresearcher: Improving automated re- search via automated review. InInternational Con- ference on Learning Representations, volume 2025, pages 3669–3709. Kahim Wong, Jicheng Zhou, Kemou Li, Yain-Whar Si, Xiaowei Wu, and Jiantao Zhou. 2025. Fontguard: A robust font watermarking approach leveraging deep font knowledge.IEEE Transactions on Multimedia. Si...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Reviewrl: Towards automated scientific review with rl.arXiv preprint arXiv:2508.10308, 2025
Reviewrl: Towards automated scientific review with rl.Preprint, arXiv:2508.10308. Yangshijie Zhang, Xinda Wang, Jialin Liu, Wenqiang Wang, Zhicong Ma, and Xingxing Jia. 2026. Style attack disguise: When fonts become a camouflage for adversarial intent. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pa...
-
[6]
prior work - Others (if not listed above, and please clarify)
Novelty - Originality of the problem - Originality of method - Insightfulness of contributions - Positioning of novelty vs. prior work - Others (if not listed above, and please clarify)
-
[7]
Technical Quality - Soundness of theoretical claims - Robustness of study design - Appropriateness of evaluations - Validity of conclusions - Others (if not listed above, and please clarify)
-
[8]
Significance - Importance of the problem - Strength of empirical/theoretical impact - Potential for future research or generalizability - Others (if not listed above, and please clarify)
-
[9]
Clarity - Quality of writing and structure - Adequacy of related work - Interpretability of figures/tables - Logical flow of arguments - Others (if not listed above, and please clarify)
-
[10]
Reproducibility - Completeness of experimental/methodological details - Availability of code/data/artifacts - Transparency in methods and limitations - Ease of reproduction - Others (if not listed above, and please clarify)
-
[11]
prior_knowledge
Others - if the paper has notable aspects not covered above, and please clarify. Your review must be returned as valid JSON in this exact format: { "prior_knowledge": { "seen_before": "Yes|No", "explanation": "Brief explanation if you have seen this paper or know official reviews" }, "summary": "A single paragraph (3-5 sentences) summarizing the paper's m...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.