MetaphorVU: Towards Metaphorical Video Understanding
Pith reviewed 2026-06-29 22:41 UTC · model grok-4.3
The pith
Multimodal models lag humans on metaphorical video understanding due to defective cross-domain mapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MetaphorVU-Bench as the first systematic benchmark for metaphorical video understanding. Experiments reveal that current MLLMs struggle with accurate performance, lagging far behind humans primarily because of defective cross-domain mapping. We construct a metaphor knowledge graph to augment mapping and propose MetaphorBoost as an inference-time enhancement framework that produces consistent performance gains across models.
What carries the argument
MetaphorBoost, an inference-time enhancement framework that uses a metaphor knowledge graph as mapping augmentation to improve cross-domain handling in video understanding.
If this is right
- Inference-time augmentation with knowledge graphs can raise MLLM performance on high-order video tasks without retraining.
- Cross-domain mapping defects represent a central bottleneck that targeted augmentation can partially relieve.
- The benchmark supplies a concrete yardstick for tracking progress on metaphorical and abstract reasoning in multimodal models.
- Real-world applicability of MLLMs expands once they handle metaphorical videos more reliably.
Where Pith is reading between the lines
- The same mapping-augmentation tactic could apply to other abstract or figurative reasoning tasks involving images or text.
- Widespread use of the benchmark might push model developers toward architectures that handle cross-domain relations more natively.
- Hybrid neural-symbolic systems could become more common if inference-time graph lookup proves effective across domains.
Load-bearing premise
The newly constructed benchmark accurately measures high-order cognitive capabilities for metaphorical video understanding and the observed gap stems from defective cross-domain mapping rather than benchmark artifacts or other factors.
What would settle it
A model that reaches near-human accuracy on the benchmark without any cross-domain mapping augmentation, or a demonstration that benchmark scores fail to correlate with separate human judgments of metaphorical content.
Figures






















read the original abstract
Metaphorical videos are prevalent across various real-world scenarios to convey complex ideas, and understanding them typically requires high-order cognitive capabilities. The lack of systematic studies on metaphorical video understanding not only constrains the real-world applicability of MLLMs but also impedes the thorough assessment of their high-order cognitive capabilities. To bridge this gap, we propose MetaphorVU-Bench, the first systematic and comprehensive benchmark dedicated to metaphorical video understanding. Through experiments, we find current MLLMs struggle with accurate metaphorical video understanding, lagging far behind human level, primarily due to defective cross-domain mapping. Motivated by this finding, we construct a metaphor knowledge graph as mapping augmentation and propose MetaphorBoost, an inference-time enhancement framework achieving consistent performance improvement. Our benchmark, analysis, and method provide useful insights and a foundation for future research on advancing MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MetaphorVU-Bench as the first systematic benchmark for metaphorical video understanding, reports that current MLLMs lag substantially behind human performance primarily due to defective cross-domain mapping, and presents MetaphorBoost, an inference-time framework that augments inputs via a constructed metaphor knowledge graph to yield consistent gains.
Significance. If the benchmark isolates cross-domain mapping as claimed and the performance gap is shown to arise from that specific deficit rather than other factors, the work would supply a needed evaluation resource and a practical augmentation technique for advancing MLLM capabilities on high-order, non-literal multimodal reasoning tasks.
major comments (2)
- [Abstract] Abstract: the central diagnosis that the observed gap is 'primarily due to defective cross-domain mapping' is load-bearing for the motivation of the knowledge-graph augmentation, yet the abstract (and the reader's available description) provides no controls such as matched literal-video baselines, temporal-vs-mapping ablations, or error analysis that would distinguish mapping failure from general multimodal deficits or benchmark artifacts.
- [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: the claim that MetaphorVU-Bench accurately measures high-order metaphorical capabilities requires explicit reporting of inter-annotator agreement on metaphor interpretations and evidence that items demand cross-domain mapping rather than other video or language skills; without these, the performance gap cannot be confidently attributed to the stated cause.
minor comments (1)
- [Abstract] The abstract states 'consistent performance improvement' without reporting effect sizes, statistical significance, or comparison to stronger baselines.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We agree that the abstract and benchmark sections can be strengthened to better support the central claims, and we outline specific revisions below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central diagnosis that the observed gap is 'primarily due to defective cross-domain mapping' is load-bearing for the motivation of the knowledge-graph augmentation, yet the abstract (and the reader's available description) provides no controls such as matched literal-video baselines, temporal-vs-mapping ablations, or error analysis that would distinguish mapping failure from general multimodal deficits or benchmark artifacts.
Authors: We acknowledge that the abstract does not explicitly reference the supporting analyses. The full manuscript includes an error analysis (Section 4.3) that breaks down model failures and attributes the majority to cross-domain mapping issues rather than general multimodal or temporal deficits. We will revise the abstract to concisely note this error analysis and the absence of comparable gaps on literal controls where applicable. Adding a full literal-video baseline would require new data collection and is not feasible within the current scope, but we will clarify the design rationale for focusing on metaphorical items. revision: partial
-
Referee: [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: the claim that MetaphorVU-Bench accurately measures high-order metaphorical capabilities requires explicit reporting of inter-annotator agreement on metaphor interpretations and evidence that items demand cross-domain mapping rather than other video or language skills; without these, the performance gap cannot be confidently attributed to the stated cause.
Authors: We will add explicit inter-annotator agreement statistics for the metaphor interpretation annotations in the revised benchmark construction section. The items were curated through a multi-stage process with domain experts to ensure they require cross-domain mapping (detailed in Section 3.2); we will expand the annotation guidelines and item selection criteria to provide clearer evidence distinguishing these from general video comprehension skills. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces MetaphorVU-Bench as a new benchmark and reports empirical performance gaps for MLLMs, then motivates and evaluates MetaphorBoost (knowledge-graph augmentation at inference time) as an improvement. No equations, fitted parameters renamed as predictions, self-definitional mappings, or load-bearing self-citations appear in the abstract or described chain. The central claims rest on experimental results rather than reducing to the inputs by construction. This is the expected non-finding for a benchmark-plus-method paper whose improvements are externally measurable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y ., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y ., Xu, S., Chen, C., Zhu, D., et al. Llava- onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
F., Tevissen, Y ., Guetari, K., and Yacoubi, M
Brkic, M., Razzouki, A. F., Tevissen, Y ., Guetari, K., and Yacoubi, M. A. E. Frame sampling strategies matter: A benchmark for small vision language models.arXiv preprint arXiv:2509.14769,
-
[4]
Flute: Figurative language understanding through textual explanations
Chakrabarty, T., Saakyan, A., Ghosh, D., and Muresan, S. Flute: Figurative language understanding through textual explanations. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 7139–7159,
2022
-
[5]
Chen, T., Liu, H., Wang, Y ., Gan, C., Lyu, M., Zou, G., and Lin, W. Looking beyond visible cues: Implicit video ques- tion answering via dual-clue reasoning.arXiv preprint arXiv:2506.07811,
-
[6]
Deng, A., Yang, T., Yu, S., Spencer, L., Bansal, M., Chen, C., Yeung-Levy, S., and Wang, X. Scivideobench: Bench- marking scientific video reasoning in large multimodal models.arXiv preprint arXiv:2510.08559,
-
[7]
A survey on in- context learning
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., et al. A survey on in- context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pp. 1107–1128,
2024
-
[8]
Google. Gemini-2.5-pro system card, 2025a. URL https://storage.googleapis. com/deepmind-media/Model-Cards/ Gemini-2-5-Pro-Model-Card.pdf. Google. Gemini-3-pro system card, 2025b. URL https://storage.googleapis. com/deepmind-media/Model-Cards/ Gemini-3-Pro-Model-Card.pdf. Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Hu, K., Wu, P., Pu, F., Xiao, W., Zhang, Y ., Yue, X., Li, B., and Liu, Z. Video-mmmu: Evaluating knowledge acqui- sition from multi-discipline professional videos.arXiv preprint arXiv:2501.13826,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y ., and Lin, S. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
R., Bhattacharyya, P., and Shekhar, S
Kalarani, A. R., Bhattacharyya, P., and Shekhar, S. Unveil- ing the invisible: Captioning videos with metaphors. In Findings of the Association for Computational Linguis- tics: EMNLP 2024, pp. 6306–6320,
2024
-
[12]
Looking beyond the pixels: Evaluating visual metaphor under- standing in vlms
Kundu, M., Shekhar, S., and Bhattacharyya, P. Looking beyond the pixels: Evaluating visual metaphor under- standing in vlms. InFindings of the Association for Com- putational Linguistics: EMNLP 2025, pp. 23137–23158,
2025
-
[13]
Meta- cognitive analysis: Evaluating declarative and procedural knowledge in datasets and large language models
Li, Z., Lin, H., Lu, Y ., Xiang, H., Han, X., and Sun, L. Meta- cognitive analysis: Evaluating declarative and procedural knowledge in datasets and large language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 11222–11228,
2024
-
[14]
Li, Z., Chen, X., Lin, H., Lu, Y ., Han, X., and Sun, L. Paperregister: Boosting flexible-grained paper search via hierarchical register indexing.arXiv preprint arXiv:2508.11116, 2025a. Li, Z., Chen, X., Yu, H., Lin, H., Lu, Y ., Tang, Q., Huang, F., Han, X., Sun, L., and Li, Y . Structrag: Boosting knowledge intensive reasoning of llms via inference-time...
-
[15]
Liu, B., Qiao, P., Ma, M., Zhang, X., Tang, Y ., Xu, P., Liu, K., and Yuan, T. Surveillancevqa-589k: A benchmark for comprehensive surveillance video-language understand- ing with large models.arXiv preprint arXiv:2505.12589,
-
[16]
W., Soldaini, L., Soboroff, I., Weller, O., Kayi, E., et al
Mayfield, J., Yang, E., Lawrie, D., MacAvaney, S., Mc- Namee, P., Oard, D. W., Soldaini, L., Soboroff, I., Weller, O., Kayi, E., et al. On the evaluation of machine- generated reports. InProceedings of the 47th Interna- tional ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pp. 1904–1915,
1904
-
[17]
Concept drift guided layernorm tuning for efficient multimodal metaphor iden- tification
Qian, W., Hu, Z., Song, Z., and Li, J. Concept drift guided layernorm tuning for efficient multimodal metaphor iden- tification. InProceedings of the 2025 International Con- ference on Multimedia Retrieval, pp. 1100–1108,
2025
-
[18]
Understanding figurative meaning through explainable visual entailment
Saakyan, A., Kulkarni, S., Chakrabarty, T., and Muresan, S. Understanding figurative meaning through explainable visual entailment. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 1–23,
2025
-
[19]
Swetha, S., Gupta, R., Kulkarni, P. P., Shatwell, D. G., Santiago, J. A. C., Siddiqui, N., Fioresi, J., and Shah, M. Implicitqa: Going beyond frames towards implicit video reasoning.arXiv preprint arXiv:2506.21742,
-
[20]
URLhttps://arxiv.org/abs/2507.01006. Tian, Y ., Zhang, R., Xu, N., and Mao, W. Bridging word- pair and token-level metaphor detection with explain- able domain mining. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13311–13325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Wang, P., Zhang, Y ., Fei, H., Chen, Q., Wang, Y ., Si, J., Lu, W., Li, M., and Qin, L. S3 agent: Unlocking the power of vllm for zero-shot multi-modal sarcasm de- tection.ACM Transactions on Multimedia Computing, Communications and Applications, 21(11):1–16, 2025a. Wang, Q., Yu, Y ., Yuan, Y ., Mao, R., and Zhou, T. Videorft: Incentivizing video reasonin...
-
[22]
Theoretical Basis for Video Metaphor Taxonomy To ensure reliable and principled evaluation, a systematic video metaphor taxonomy is essential for building the benchmark
13 MetaphorVU: Towards Metaphorical Video Understanding A. Theoretical Basis for Video Metaphor Taxonomy To ensure reliable and principled evaluation, a systematic video metaphor taxonomy is essential for building the benchmark. Since no prior works have explored this kind of taxonomy, we draw on multimodal metaphor theory (Forceville et al., 2009; Forcev...
2009
-
[23]
virtual performance
and its extensions in the video field (Bordwell, 2013b; Stam, 2017; Schechner, 2017; Chandler, 2022), designing the first systematic video metaphor taxonomy, the details are illustrated in follows: According to Film Mise-en-sc`ene Theory (Bordwell et al., 2004; Gibbs & Gibbs, 2002; Arnheim, 1957), video metaphors can be realized through visual element arr...
2017
-
[24]
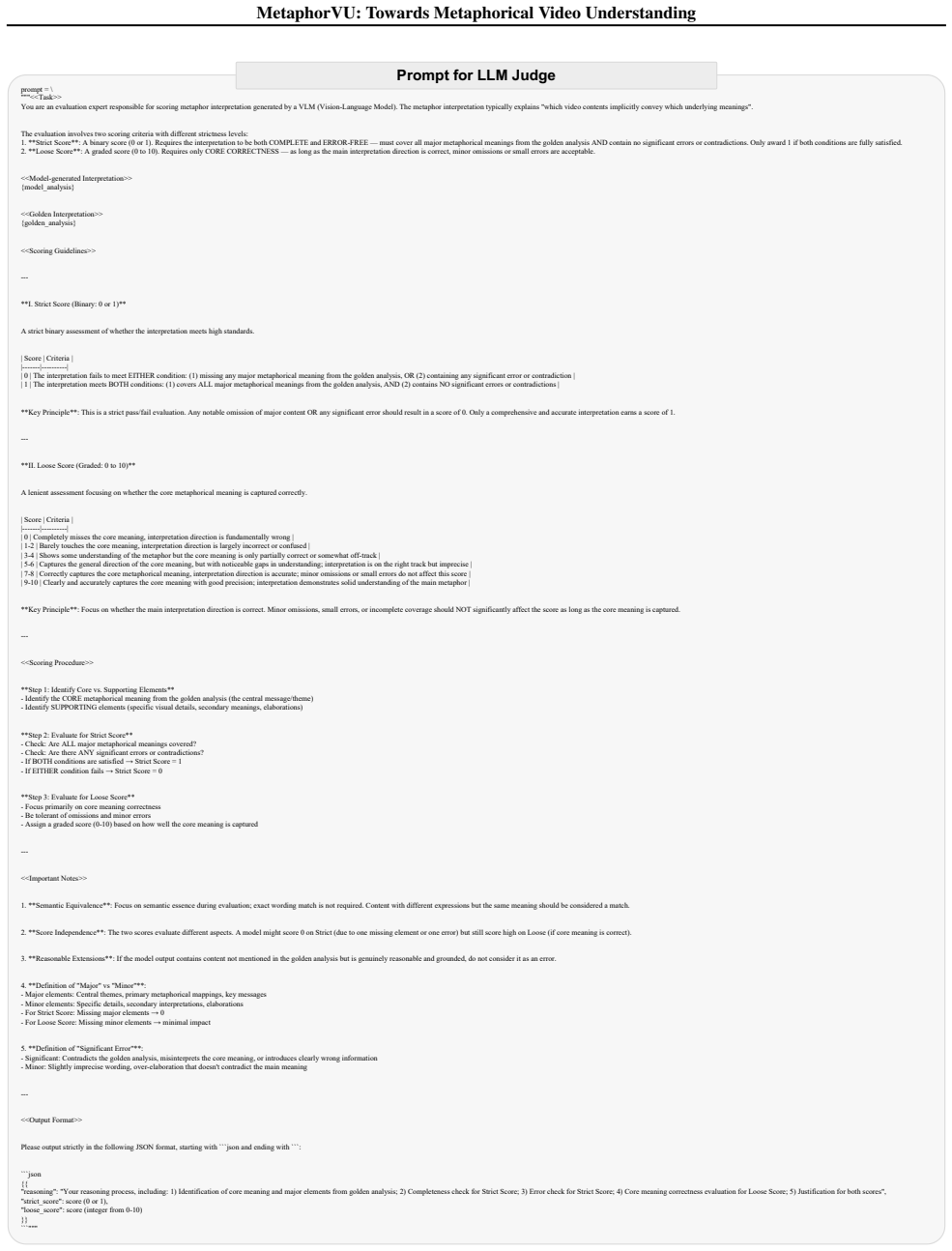
C.2. Prompt for LLM Judge Since the output video metaphor interpretation in MetaphorVU-Bench is free-form text, rule-based metrics are difficult to provide a score aligning with actual human habits (Mayfield et al., 2024; Li et al., 2025d). To this end, we follow the metrics in previous free-form QA evaluation works (Li et al., 2025b;e; Yu et al., 2025; L...
2024
-
[25]
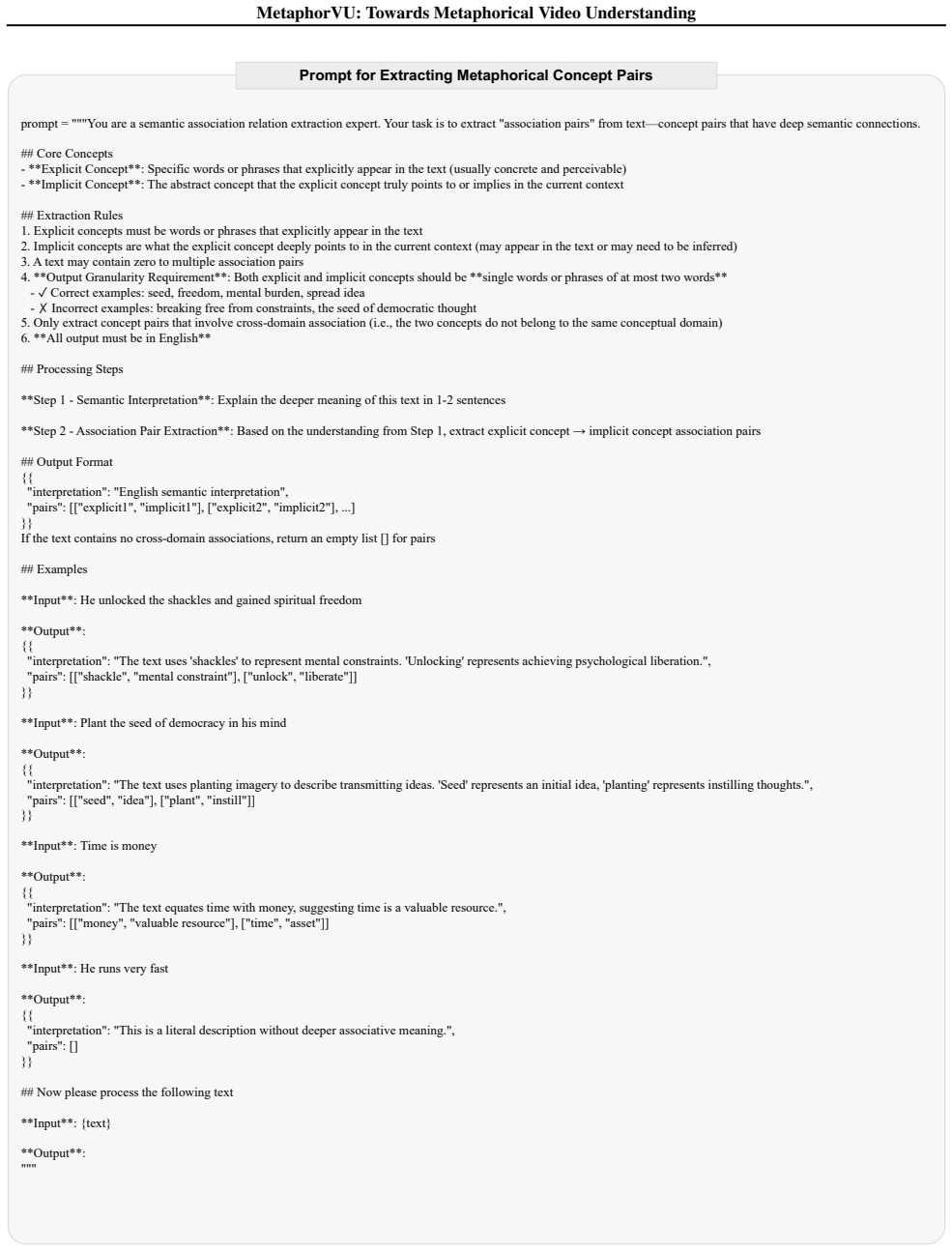
Note that a portion of the data was originally in Chinese, to ensure the universality of the metaphorical knowledge graph, we use GPT-5 to translate the original text into English. D.2. Prompt for Extracting Metaphorical Concept Pairs Since several previous works that have been widely recognized by the community have demonstrated that current LLMs possess...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.