A Tertiary Review of Large Language Model-Based Code Generating Tasks: Trends, Challenges, and Future Directions
Pith reviewed 2026-06-29 20:46 UTC · model grok-4.3
The pith
LLM-based code generation tasks show promise on benchmarks yet lack robust real-world validation and face efficiency hurdles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
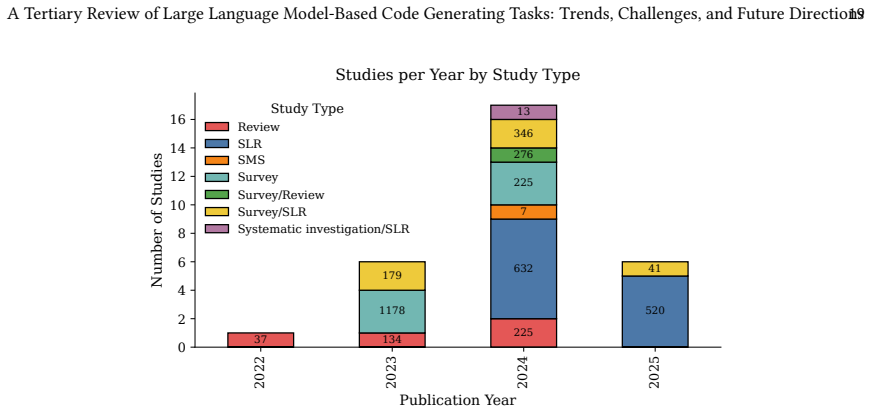
The tertiary study consolidates secondary evidence showing that LLM-based code generating tasks represent a fast-maturing research area with strong reported accuracy on benchmarks but weakly supported real-world generalization, fragile robustness, pervasive efficiency constraints, and under-reported toxicity and bias; it identifies dominant challenges in economic feasibility, evaluation validity, and socio-technical integration, and proposes future directions focused on domain-aware model improvement alongside holistic and standardized evaluation.
What carries the argument
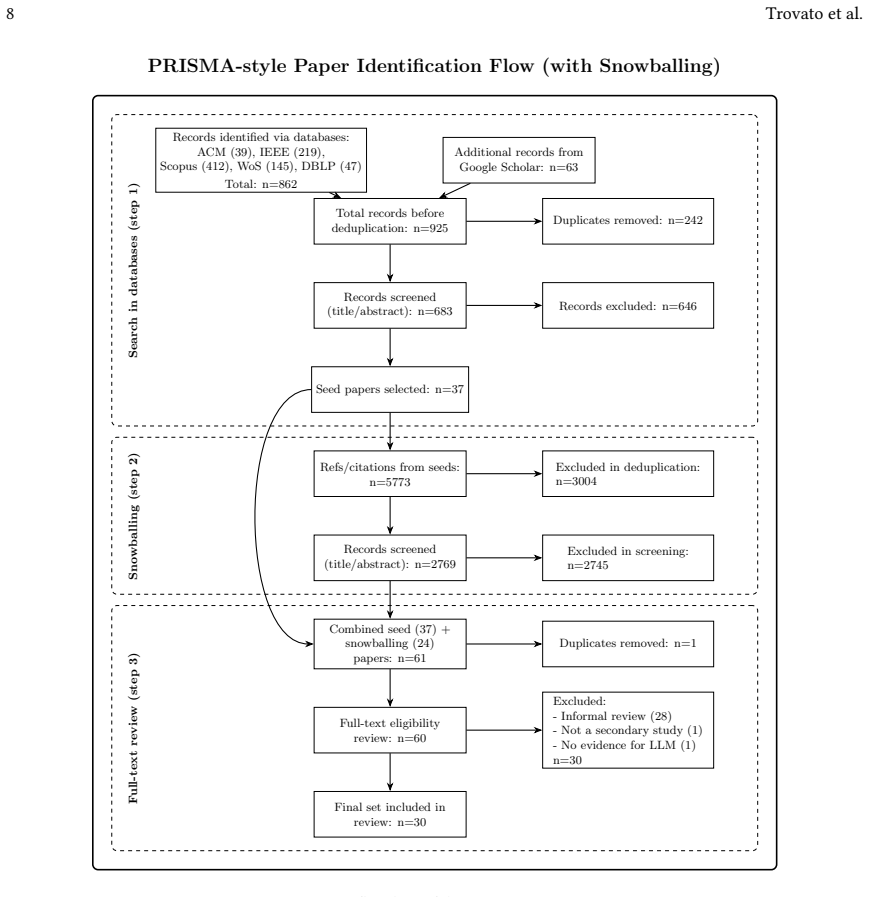
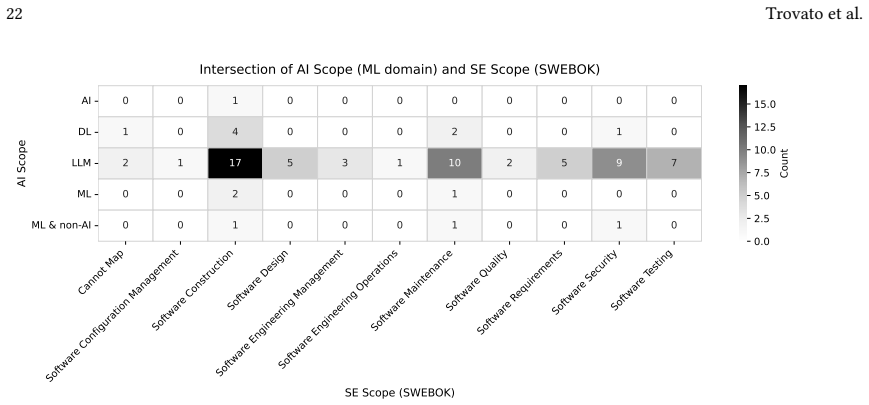
Synthesis of 30 secondary studies using SWEBOK knowledge areas and the HELM framework, identified through library searches and snowballing.
If this is right
- Reported benchmark accuracy provides limited assurance for real-world software engineering applications.
- Efficiency and associated costs must be addressed to make LLM-based code generation economically feasible.
- Standardized and holistic evaluation methods are required to properly assess robustness and integration challenges.
- Domain-aware improvements to models will be necessary to overcome current limitations in applicability.
- Future research should prioritize addressing socio-technical aspects of LLM integration in development processes.
Where Pith is reading between the lines
- Without better evaluation practices, industry adoption of these models risks being based on overstated capabilities.
- Under-reporting of bias and toxicity could lead to unintended consequences in generated code affecting security or fairness.
- Extending this review with primary studies on actual developer productivity metrics could test the generalization claims.
Load-bearing premise
The 30 secondary studies identified through searches and snowballing represent an unbiased and complete sample of the existing literature.
What would settle it
Discovery of many additional secondary studies on LLM code generation that report strong real-world generalization or efficient performance would undermine the synthesized conclusions on uneven evaluation.
Figures
read the original abstract
Context. Large language models (LLMs) are increasingly applied to code-generating tasks (CGTs) in software engineering. While reported results are promising, the broader effects of such application and their integration into real-world development remain insufficiently understood with existing tertiary studies provide little in this area. Objective. This tertiary study consolidates secondary evidence on LLM-based CGTs, synthesizing the publication landscape, effects, scenarios, integration challenges, and future research directions. Method. Following systematic review guidelines, we searched in related digital libraries, complemented by backward-and-forward snowballing and screening step. Study quality was assessed and extraction reliability was audited with inter-rater agreement statistics. Evidence was synthesized using SWEBOK knowledge areas and the HELM framework. Results. We identify 30 secondary studies published between 2017-2025, with rapid growth since 2023. Accuracy seems strong on benchmarks but weakly supported for real-world generalization; robustness is fragile across tasks and configurations; efficiency constraints are pervasive; toxicity and bias are under-reported. Dominant challenges concern economic feasibility, evaluation validity, and socio-technical integration. Future directions suggest domain-aware model improvement and the need for holistic, standardized evaluation. Conclusion. LLM-based CGTs represent a fast-maturing yet unevenly evaluated research area, highlighting the need for domain-aware model improvements and holistic, standardized evaluation, addressing efficiency and associated costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This tertiary review identifies 30 secondary studies (2017-2025) on LLM-based code-generating tasks (CGTs) via library searches and snowballing, assesses quality and inter-rater agreement, and synthesizes trends, effects (accuracy, robustness, efficiency, toxicity), scenarios, integration challenges, and future directions using SWEBOK knowledge areas and the HELM framework, concluding that the area is fast-maturing yet unevenly evaluated and requires domain-aware model improvements plus holistic, standardized evaluation addressing efficiency and costs.
Significance. If the 30-study sample is representative and the synthesis reliable, the work consolidates evidence on a rapidly expanding topic, highlighting gaps in real-world generalization, robustness across configurations, and evaluation validity that could usefully inform research priorities in software engineering.
major comments (2)
- [Method] Method section: the abstract and description claim adherence to systematic review guidelines, quality assessment, and inter-rater agreement auditing, yet supply no search strings, exact inclusion/exclusion criteria, or handling of data exclusions; this directly affects the load-bearing claim that the 30 studies constitute a representative sample.
- [Results] Results / Discussion: the representativeness assumption for the 30 secondary studies (identified via libraries and snowballing) is asserted without reported coverage metrics, bias checks, or comparison to the broader population of secondary studies on LLM-based CGTs, weakening the synthesis of trends and challenges.
minor comments (2)
- [Abstract] Abstract: the phrasing 'existing tertiary studies provide little in this area' is vague; a brief citation or count of prior tertiary reviews would clarify the novelty claim.
- [Results] The HELM framework application and SWEBOK mapping are described at a high level; an explicit table or appendix showing how individual findings map to framework dimensions would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving methodological transparency. We address each point below and will make revisions to the manuscript.
read point-by-point responses
-
Referee: [Method] Method section: the abstract and description claim adherence to systematic review guidelines, quality assessment, and inter-rater agreement auditing, yet supply no search strings, exact inclusion/exclusion criteria, or handling of data exclusions; this directly affects the load-bearing claim that the 30 studies constitute a representative sample.
Authors: We agree that the current manuscript does not include the specific search strings, detailed inclusion/exclusion criteria, or explicit handling of data exclusions. This is a presentation gap that reduces transparency. In the revised version, we will expand the Method section (and add an appendix if needed) with the exact search strings used across libraries, the complete inclusion and exclusion criteria, and how exclusions were managed during screening and snowballing. These details were part of our protocol and will directly support the representativeness claim. revision: yes
-
Referee: [Results] Results / Discussion: the representativeness assumption for the 30 secondary studies (identified via libraries and snowballing) is asserted without reported coverage metrics, bias checks, or comparison to the broader population of secondary studies on LLM-based CGTs, weakening the synthesis of trends and challenges.
Authors: The observation is correct; we did not report quantitative coverage metrics, formal bias checks, or direct comparisons to the full population of secondary studies. In revision, we will add a dedicated paragraph in the Results or Limitations subsection discussing the sampling approach (multi-library search plus snowballing), its potential biases, and qualitative indicators of coverage. We will also note any challenges in obtaining a definitive population count for comparison. revision: yes
Circularity Check
No significant circularity identified
full rationale
This tertiary review paper follows a standard systematic literature review methodology (library searches, snowballing, quality assessment, inter-rater agreement) to synthesize 30 secondary studies using SWEBOK and HELM frameworks. There are no mathematical derivations, predictions, fitted parameters, equations, or load-bearing self-citations that reduce claims to inputs by construction. The central claims about trends, challenges, and future directions follow directly from the evidence base without self-referential loops or renaming of results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systematic review guidelines and inter-rater agreement statistics ensure reliable evidence synthesis
Reference graph
Works this paper leans on
-
[1]
d.].ACM Digital Library
Association for Computing Machinery (ACM) [n. d.].ACM Digital Library. Association for Computing Machinery (ACM). Accessed: 2025-09-12
2025
-
[2]
d.].dblp: Computer Science Bibliography
Schloss Dagstuhl – Leibniz-Zentrum für Informatik [n. d.].dblp: Computer Science Bibliography. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. Accessed: 2025-09-12
2025
-
[3]
d.].Google Scholar
Google [n. d.].Google Scholar. Google. Accessed: 2025-09-12
2025
-
[4]
d.].IEEE Xplore Digital Library
Institute of Electrical and Electronics Engineers (IEEE) [n. d.].IEEE Xplore Digital Library. Institute of Electrical and Electronics Engineers (IEEE). Accessed: 2025-09-12
2025
-
[5]
d.].OpenAI GPT-4
OpenAI [n. d.].OpenAI GPT-4. OpenAI. Accessed: 2025-09-12
2025
-
[6]
d.].ScienceDirect
Elsevier [n. d.].ScienceDirect. Elsevier. Accessed: 2025-09-12
2025
-
[7]
d.].Scopus
Elsevier [n. d.].Scopus. Elsevier. Accessed: 2025-09-12
2025
-
[8]
d.].Web of Science Core Collection
Clarivate [n. d.].Web of Science Core Collection. Clarivate. Accessed: 2025-09-12
2025
-
[9]
Areeg Ahmed, Shahira Azab, and Yasser Abdelhamid. 2023. Source-code generation using deep learning: a survey. InEPIA Conference on Artificial Intelligence. Springer, 467–482
2023
-
[10]
Gul Aftab Ahmed, James Vincent Patten, Yuanhua Han, Guoxian Lu, David Gregg, Jim Buckley, and Muslim Chochlov. 2023. Using Ensemble Inference to Improve Recall of Clone Detection. In2023 IEEE 17th International Workshop on Software Clones (IWSC). IEEE, 15–21
2023
-
[11]
Domenico Amalfitano, Stefano Faralli, Jean Carlo Rossa Hauck, Santiago Matalonga, and Damiano Distante. 2023. Artificial intelligence applied to software testing: A tertiary study.Comput. Surveys56, 3 (2023), 1–38
2023
-
[12]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Abdulrahman Ahmed Bobakr Baqais and Mohammad Alshayeb. 2020. Automatic software refactoring: a systematic literature review.Software Quality Journal28, 2 (2020), 459–502
2020
-
[14]
Jessica Bates, Paul Best, Janice McQuilkin, and Brian Taylor. 2017. Will web search engines replace bibliographic databases in the systematic identification of research?The Journal of Academic Librarianship43, 1 (2017), 8–17
2017
-
[15]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[16]
Mohamad Adam Bujang and N Baharum. 2017. Guidelines of the minimum sample size requirements for Kappa agreement test. Epidemiol. Biostat. Public Health14, 2 (2017)
2017
-
[17]
M. C. and Coauthors. 2025. Supplementary Material (private Zenodo link under review). https://zenodo.org/records/17582721?preview=1&token= eyJhbGciOiJIUzUxMiJ9.eyJpZCI6ImZmZmFkNjQ2LTc1ZWQtNGRiYi04ZGVmLWQwOTAwMDU2YzRkNCIsImRhdGEiOnt9LCJyYW5kb20iOiJiMWFhN2Y2MzgwNTQ2YmFiZDRkMGMyM2JkOGViYTQ1NSJ9. lm0Y2dGigtT7lxiQMjqjvFHn5-zDqC7ep2BB3b9g8sHIjwsD15NjPvPTfjSGP_j...
-
[18]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
2021
-
[19]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Muslim Chochlov, Gul Aftab Ahmed, James Vincent Patten, Guoxian Lu, Wei Hou, David Gregg, and Jim Buckley. 2022. Using a nearest-neighbour, BERT-based approach for scalable clone detection. In2022 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 582–591. Manuscript submitted to ACM 40 Trovato et al
2022
-
[21]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways.Journal of Machine Learning Research24, 240 (2023), 1–113
2023
-
[22]
CORE. 2025. CORE Conference Portal. https://www.core.edu.au/conference-portal. Accessed: 2025-09-22
2025
-
[23]
Zheyuan Kevin Cui, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. 2025. The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers.A vailable at SSRN 4945566(2025)
2025
-
[24]
Enrique Dehaerne, Bappaditya Dey, Sandip Halder, Stefan De Gendt, and Wannes Meert. 2022. Code generation using machine learning: A systematic review.Ieee Access10 (2022), 82434–82455
2022
-
[25]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[26]
Thomas G Dietterich. 2000. Ensemble methods in machine learning. InInternational workshop on multiple classifier systems. Springer, 1–15
2000
-
[27]
Liming Dong, Qinghua Lu, and Liming Zhu. 2024. A pilot study in surveying data challenges of automatic software engineering tasks. InProceedings of the 4th International Workshop on Software Engineering and AI for Data Quality in Cyber-Physical Systems/Internet of Things. 6–11
2024
-
[28]
Alvan R Feinstein and Domenic V Cicchetti. 1990. High agreement but low kappa: I. The problems of two paradoxes.Journal of clinical epidemiology 43, 6 (1990), 543–549
1990
-
[29]
Joseph L Fleiss. 1971. Measuring nominal scale agreement among many raters.Psychological bulletin76, 5 (1971), 378
1971
-
[30]
2023.Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Product quality model
International Organization for Standardization. 2023.Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Product quality model. ISO
2023
-
[31]
Gordon Fraser and Andrea Arcuri. 2011. Evosuite: automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 416–419
2011
-
[32]
Gordon Fraser and Andrea Arcuri. 2012. Whole test suite generation.IEEE Transactions on Software Engineering39, 2 (2012), 276–291
2012
-
[33]
Simon Cornelius Gorissen, Stefan Sauer, and Wolf G Beckmann. 2024. A survey of natural language-based editing of low-code applications using large language models. InInternational Conference on Human-Centred Software Engineering. Springer, 243–254
2024
-
[34]
Muhammet Kürşat Görmez, Murat Yılmaz, and Paul M Clarke. 2024. Large language models for software engineering: A systematic mapping study. InEuropean Conference on Software Process Improvement. Springer, 64–79
2024
-
[35]
Sumit Gulwani, Oleksandr Polozov, Rishabh Singh, et al. 2017. Program synthesis.Foundations and Trends®in Programming Languages4, 1-2 (2017), 1–119
2017
-
[36]
Eddie Guo, Mehul Gupta, Jiawen Deng, Ye-Jean Park, Michael Paget, and Christopher Naugler. 2024. Automated paper screening for clinical reviews using large language models: data analysis study.Journal of Medical Internet Research26 (2024), e48996
2024
-
[37]
Michael Gusenbauer and Neal R Haddaway. 2020. Which academic search systems are suitable for systematic reviews or meta-analyses? Evaluating retrieval qualities of Google Scholar, PubMed, and 26 other resources.Research synthesis methods11, 2 (2020), 181–217
2020
-
[38]
Kilem Li Gwet. 2008. Computing inter-rater reliability and its variance in the presence of high agreement.Brit. J. Math. Statist. Psych.61, 1 (2008), 29–48
2008
-
[39]
2014.Handbook of inter-rater reliability: The definitive guide to measuring the extent of agreement among raters
Kilem L Gwet. 2014.Handbook of inter-rater reliability: The definitive guide to measuring the extent of agreement among raters. Advanced Analytics, LLC
2014
-
[40]
Neal Robert Haddaway, Alexandra Mary Collins, Deborah Coughlin, and Stuart Kirk. 2015. The role of Google Scholar in evidence reviews and its applicability to grey literature searching.PloS one10, 9 (2015), e0138237
2015
-
[41]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
- [42]
- [43]
-
[44]
Zhang Huangzhao, Zhang Kechi, Li Zhuo, Li Jia, Li Yongmin, Zhao Yunfei, Zhu Yuqi, Liu Fang, Li Ge, and Jin Zhi. 2024. Deep learning for code generation: A survey.SCIENCE CHINA Information Sciences ISSN(2024)
2024
-
[45]
Aleksi Huotala, Miikka Kuutila, Paul Ralph, and Mika Mäntylä. 2024. The promise and challenges of using LLMs to accelerate the screening process of systematic reviews. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering. 262–271
2024
-
[46]
Rasha Ahmad Husein, Hala Aburajouh, and Cagatay Catal. 2025. Large language models for code completion: A systematic literature review. Computer Standards & Interfaces92 (2025), 103917
2025
-
[47]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.arXiv preprint arXiv:2406.00515(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [48]
-
[49]
Barbara Kitchenham and Pearl Brereton. 2013. A systematic review of systematic review process research in software engineering.Information and software technology55, 12 (2013), 2049–2075. Manuscript submitted to ACM A Tertiary Review of Large Language Model-Based Code Generating Tasks: Trends, Challenges, and Future Directions41
2013
-
[50]
Barbara Kitchenham, Stuart Charters, et al. 2007. Guidelines for performing systematic literature reviews in software engineering. (2007)
2007
-
[51]
Barbara Kitchenham, Lech Madeyski, and David Budgen. 2022. SEGRESS: Software engineering guidelines for reporting secondary studies.IEEE Transactions on Software Engineering49, 3 (2022), 1273–1298
2022
-
[52]
Barbara Kitchenham, Rialette Pretorius, David Budgen, O Pearl Brereton, Mark Turner, Mahmood Niazi, and Stephen Linkman. 2010. Systematic literature reviews in software engineering–a tertiary study.Information and software technology52, 8 (2010), 792–805
2010
-
[53]
Ron Kohavi et al. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. InIjcai, Vol. 14. Montreal, Canada, 1137–1145
1995
-
[54]
Zoe Kotti, Rafaila Galanopoulou, and Diomidis Spinellis. 2023. Machine learning for software engineering: A tertiary study.Comput. Surveys55, 12 (2023), 1–39
2023
-
[55]
2018.Content analysis: An introduction to its methodology
Klaus Krippendorff. 2018.Content analysis: An introduction to its methodology. Sage publications
2018
- [56]
-
[57]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
- [58]
-
[59]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer
-
[60]
BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.arXiv preprint arXiv:1910.13461(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[61]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode.Science378, 6624 (2022), 1092–1097
2022
-
[62]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. 2022. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[63]
Jialiang Lin, Yao Yu, Yu Zhou, Zhiyang Zhou, and Xiaodong Shi. 2020. How many preprints have actually been printed and why: a case study of computer science preprints on arXiv.Scientometrics124, 1 (2020), 555–574
2020
-
[64]
Hsiao-Chuan Liu, Chia-Tung Tsai, and Min-Yuh Day. 2024. A Pilot Study on AI-Assisted Code Generation with Large Language Models for Software Engineering. InInternational Conference on Technologies and Applications of Artificial Intelligence. Springer, 162–175
2024
-
[65]
Kui Liu, Li Li, Anil Koyuncu, Dongsun Kim, Zhe Liu, Jacques Klein, and Tegawendé F Bissyandé. 2021. A critical review on the evaluation of automated program repair systems.Journal of Systems and Software171 (2021), 110817
2021
-
[66]
Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica22, 3 (2012), 276–282
2012
-
[67]
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey.arXiv preprint arXiv:2402.06196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
David Moher, Larissa Shamseer, Mike Clarke, Davina Ghersi, Alessandro Liberati, Mark Petticrew, Paul Shekelle, Lesley A Stewart, and Prisma-P Group. 2015. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement.Systematic reviews4, 1 (2015), 1
2015
-
[69]
automatic patch generation learned from human-written patches
Martin Monperrus. 2014. A critical review of" automatic patch generation learned from human-written patches": Essay on the problem statement and the evaluation of automatic software repair. InProceedings of the 36th International Conference on Software Engineering. 234–242
2014
-
[70]
Robert G Newcombe. 1998. Two-sided confidence intervals for the single proportion: Comparison of seven methods.Statistics in Medicine17, 8 (1998), 857–872
1998
-
[71]
Björn Nykvist, Biljana Macura, Maria Xylia, and Erik Olsson. 2025. Testing the utility of GPT for title and abstract screening in environmental systematic evidence synthesis.Environmental Evidence14, 1 (2025), 7
2025
-
[72]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[73]
Alison O’Mara-Eves, James Thomas, John McNaught, Makoto Miwa, and Sophia Ananiadou. 2015. Using text mining for study identification in systematic reviews: a systematic review of current approaches.Systematic reviews4, 1 (2015), 5
2015
- [74]
-
[75]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
Jorge Pérez, Jessica Díaz, Javier Garcia-Martin, and Bernardo Tabuenca. 2020. Systematic literature reviews in software engineering—enhancement of the study selection process using Cohen’s Kappa statistic.Journal of Systems and Software168 (2020), 110657
2020
-
[78]
Kai Petersen, Sairam Vakkalanka, and Ludwik Kuzniarz. 2015. Guidelines for conducting systematic mapping studies in software engineering: An update.Information and software technology64 (2015), 1–18. Manuscript submitted to ACM 42 Trovato et al
2015
-
[79]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[80]
Leonardo Criollo Ramírez, Xavier Limón, Ángel J Sánchez-García, and Juan Carlos Pérez-Arriaga. 2024. State of the Art of the Security of Code Generated by LLMs: A Systematic Literature Review. In2024 12th International Conference in Software Engineering Research and Innovation (CONISOFT). IEEE, 331–339
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.