'Si'multaneous 'S'patial-'T'emporal Message Passing for Dynamic Graph Representation Learning
Pith reviewed 2026-06-29 22:23 UTC · model grok-4.3
The pith
SiST-GNN fuses spatial and temporal signals inside one message-passing step on dynamic graphs by connecting each node's recurrent state to its current features via a cross-time edge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
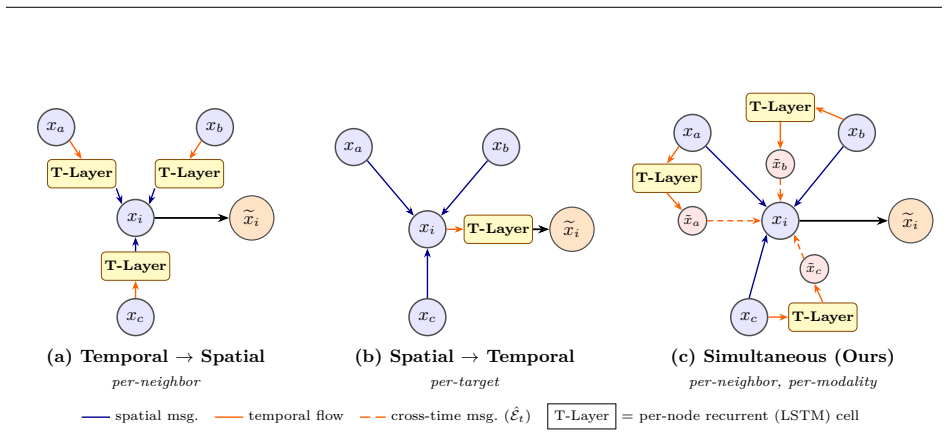
The paper claims that by maintaining a recurrent hidden state per node, pairing it with the node's current feature vector, and treating the pair as two nodes joined by a cross-time edge, running standard graph convolution on the temporally augmented graph produces representations that jointly reason over topology and evolution.
What carries the argument
The temporally augmented graph in which each node's recurrent hidden state and current feature vector are treated as two nodes connected by a cross-time edge.
If this is right
- On fixed-split link prediction, SiST-GNN outperforms the strongest prior method by 109--277%.
- On live-update link prediction, the gains are 68--194%.
- On three discretized dynamic node-classification tasks, SiST-GNN beats the leading discrete-time baseline by 7--22% and matches continuous-time methods that consume raw events.
Where Pith is reading between the lines
- The same cross-time augmentation could be applied to other base GNN layers or recurrent cells without changing the overall architecture.
- If the augmentation preserves trajectory information, the method may reduce the need for separate temporal modules in libraries that already implement standard graph convolution.
- Performance on continuous-time event streams could be tested by feeding raw timestamps directly into the recurrent state update rather than discretizing first.
Load-bearing premise
Treating a node's recurrent hidden state and current feature vector as two nodes joined by a cross-time edge lets the message-passing operator weight a neighbor's contribution by that neighbor's past trajectory without information loss or distortion from the augmentation.
What would settle it
An ablation that removes only the cross-time edges while retaining the recurrent hidden states and measures whether the reported performance margins over sequential baselines shrink or disappear.
Figures
read the original abstract
Dynamic graph neural networks (DGNNs) that operate on snapshot sequences typically fall into one of two categories. \emph{Temporal-first} approaches build per-node temporal embeddings and only afterwards perform spatial aggregation, whereas \emph{Spatial-first} approaches invert this order, feeding the output of a graph convolution into a downstream temporal module. In either case, the rigid sequencing forces the second stage to consume an already-compressed summary produced by the first, ruling out joint reasoning over topology and evolution; concretely, the message-passing operator never gets to weight a neighbor's contribution by that neighbor's \emph{past} trajectory. This paper introduces \textbf{SiST-GNN} (\textbf{Si}multaneous \textbf{S}patial-\textbf{T}emporal \textbf{GNN}), which fuses the two signals inside a single message-passing operation rather than chaining them. Concretely, at each snapshot we maintain a recurrent hidden state per node that summarises its history, pair it with the node's current feature vector, and treat the pair as two nodes joined by a cross-time edge; running a standard graph convolution on this temporally augmented graph yields the updated representation. Our empirical study spans nine public baselines and fourteen model-dataset combinations, covering both fixed-split and live-update evaluation regimes. Across every public benchmark, SiST-GNN sets a new state of the art in link prediction task over the strongest prior method by $109$--$277\%$ in the fixed-split setting and by $68$--$194\%$ in the live-update setting. We additionally construct three dynamic node-classification tasks by discretising the underlying continuous-time event streams; here SiST-GNN beats the leading discrete-time (DTDG) baseline by $7$--$22\%$ and matches continuous-time (CTDG) methods that consume the raw events directly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SiST-GNN, a dynamic GNN architecture that augments each graph snapshot with cross-time edges connecting a node's recurrent hidden state to its current feature vector and then applies standard graph convolution on the resulting structure. This is intended to enable joint spatial-temporal message passing without the information compression inherent in sequential temporal-first or spatial-first pipelines. The central empirical claim is that SiST-GNN achieves new state-of-the-art link-prediction performance on every public benchmark, outperforming the strongest prior method by 109–277% (fixed-split) and 68–194% (live-update) across nine baselines and fourteen model-dataset combinations; it also reports 7–22% gains on three derived dynamic node-classification tasks while matching continuous-time methods.
Significance. If the reported gains prove robust under fully specified and reproducible experimental protocols, the work would constitute a meaningful contribution by demonstrating that a minimal graph-augmentation trick can replace sequential spatio-temporal pipelines while delivering large accuracy improvements. The construction is simple, internally consistent with the stated goal of avoiding compressed summaries, and evaluated across both fixed-split and live-update regimes plus multiple task types. No machine-checked proofs or parameter-free derivations are present, but the breadth of the empirical study (14 combinations) is a positive feature.
major comments (3)
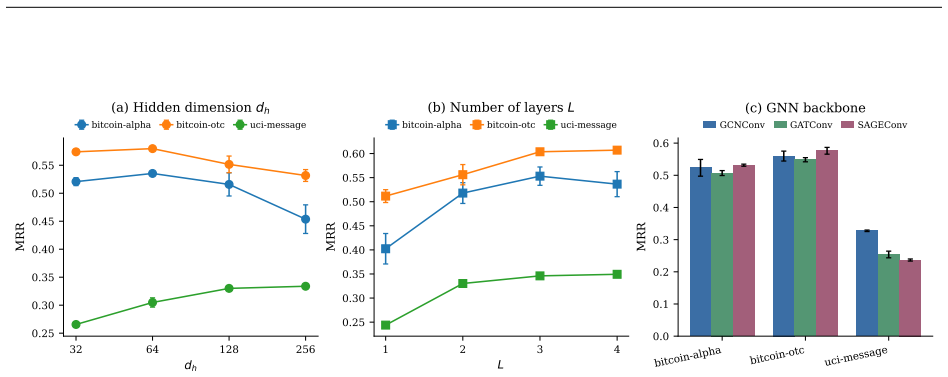
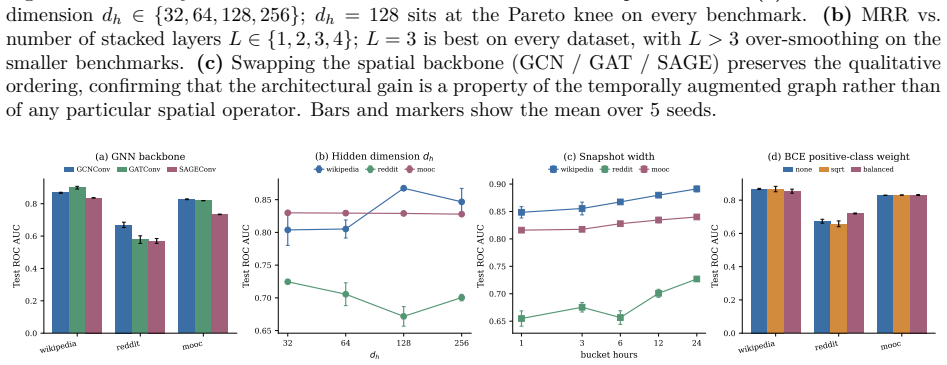
- [§4] §4 (Experimental Evaluation): The manuscript provides no description of baseline re-implementations, hyperparameter search procedures, or whether published numbers were used directly; given the central claim of 109–277% relative gains, this omission is load-bearing and prevents assessment of whether comparisons are fair.
- [§4] §4: No information is supplied on the number of random seeds, standard deviations, or statistical significance tests for any reported metric; without these, the large performance deltas cannot be distinguished from run-to-run variance or post-hoc selection.
- [§3] §3 (Method): The assumption that inserting cross-time edges between hidden states and current features permits the message-passing operator to weight neighbors by their full past trajectories without distortion or information loss is stated but not supported by any analysis, ablation, or information-flow argument; this is the mechanistic justification for the architecture and therefore load-bearing for the claimed advantage over sequential baselines.
minor comments (2)
- [Title] The title contains unusual quote formatting around individual letters; this should be cleaned for readability.
- [Abstract] The abstract states results across 'fourteen model-dataset combinations' but does not enumerate which datasets or which exact prior methods constitute the 'strongest prior' in each case; adding an explicit table or list would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving transparency and rigor in the experimental and methodological sections. We address each major comment below and commit to revisions that enhance reproducibility and provide additional support for the architectural choices.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation): The manuscript provides no description of baseline re-implementations, hyperparameter search procedures, or whether published numbers were used directly; given the central claim of 109–277% relative gains, this omission is load-bearing and prevents assessment of whether comparisons are fair.
Authors: We agree that additional details are necessary to substantiate the comparisons. In the revised manuscript, §4 will be expanded to describe the re-implementation process for each baseline (including any adaptations from original codebases), the hyperparameter search procedure (ranges, selection criteria, and computational budget), and a clear statement for each result indicating whether published numbers were used or experiments were re-run under our evaluation protocol. This will enable direct assessment of fairness. revision: yes
-
Referee: [§4] §4: No information is supplied on the number of random seeds, standard deviations, or statistical significance tests for any reported metric; without these, the large performance deltas cannot be distinguished from run-to-run variance or post-hoc selection.
Authors: We acknowledge the need for statistical rigor. The revised version will report all metrics as averages over multiple random seeds (minimum of 5), include standard deviations, and apply appropriate statistical tests (e.g., paired t-tests) to evaluate the significance of improvements. These additions will be incorporated into tables and text in §4. revision: yes
-
Referee: [§3] §3 (Method): The assumption that inserting cross-time edges between hidden states and current features permits the message-passing operator to weight neighbors by their full past trajectories without distortion or information loss is stated but not supported by any analysis, ablation, or information-flow argument; this is the mechanistic justification for the architecture and therefore load-bearing for the claimed advantage over sequential baselines.
Authors: The design is motivated by enabling joint message passing over current features and historical summaries within a single graph convolution, as outlined in §3. While the manuscript emphasizes empirical outcomes over formal analysis, we will add an ablation study isolating the effect of the cross-time edges and a short discussion of how the augmented graph structure facilitates trajectory-aware weighting. This provides further empirical grounding for the claimed advantage. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces an architectural construction (recurrent state paired with current features via cross-time edges, followed by standard graph convolution) and reports empirical link-prediction gains on public benchmarks. No equations, derivations, or self-citations are shown that reduce any claimed result to a fitted parameter or prior result by construction. The central claim remains an independent empirical outcome rather than a renaming or self-referential prediction.
Axiom & Free-Parameter Ledger
axioms (2)
- ad hoc to paper Standard graph convolution applied to an augmented graph with cross-time edges performs joint spatial-temporal reasoning
- domain assumption Recurrent hidden states per node can be paired with current features without loss of temporal information
invented entities (1)
-
cross-time edge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Matthias Fey and Jan Eric Lenssen
doi: 10.1109/TKDE.2025.3621291. Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric.CoRR, abs/1903.02428,
-
[2]
Fast Graph Representation Learning with PyTorch Geometric
URLhttp://arxiv.org/abs/1903.02428. Palash Goyal, Nitin Kamra, Xinran He, and Yan Liu. Dyngem: Deep embedding method for dynamic graphs.arXiv preprint arXiv:1805.11273,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[3]
doi: https://doi.org/10.1016/j.knosys.2019.06.024
ISSN 0950-7051. doi: https://doi.org/10.1016/j.knosys.2019.06.024. URLhttps://www.sciencedirect.com/science/article/ pii/S0950705119302916. Ehsan Hajiramezanali, Arman Hasanzadeh, Nick Duffield, Krishna Narayanan, Mingyuan Zhou, and Xiaoning Qian. Variational graph recurrent neural networks. Curran Associates Inc., Red Hook, NY, USA,
-
[4]
ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URLhttps://doi.org/10.1162/neco.1997.9.8.1735. Shenyang Huang, Farimah Poursafaei, Jacob Danovitch, Matthias Fey, Weihua Hu, Emanuele Rossi, Jure Leskovec, Michael M. Bronstein, Guillaume Rabusseau, and Reihaneh Rabbany. Temporal graph benchmark for machine learning on temporal graphs. InThirty-seventh Conf...
-
[5]
Adam: A Method for Stochastic Optimization
URLhttps://arxiv.org/abs/1412.6980. Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
doi: 10.1109/ICDM.2016.0033. Srijan Kumar, William L. Hamilton, Jure Leskovec, and Dan Jurafsky. Community interaction and conflict on the web. InProceedings of the 2018 World Wide Web Conference, WWW ’18, pp. 933–943, Republic and Canton of Geneva, CHE,
-
[7]
International World Wide Web Conferences Steering Committee. ISBN 9781450356398. doi: 10.1145/3178876.3186141. URLhttps://doi.org/10.1145/3178876.3186141. Srijan Kumar, Xikun Zhang, and Jure Leskovec. Predicting dynamic embedding trajectory in temporal interaction networks. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discove...
-
[8]
Association for Computing Machinery. ISBN 9781450362016. doi: 10.1145/3292500.3330895. URLhttps://doi.org/10.1145/3292500.3330895. Jure Leskovec, Jon Kleinberg, and Christos Faloutsos. Graphs over time: densification laws, shrinking diameters and possible explanations. InProceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Dis- cov...
-
[9]
Association for Computing Machinery. ISBN 159593135X. doi: 10.1145/1081870.1081893. URLhttps://doi.org/10.1145/1081870.1081893. 17 Hao Li, Hao Wan, Yuzhou Chen, Dongsheng Ye, Yulia Gel, and Hao Jiang. TMetanet: Topological meta-learning framework for dynamic link prediction. InForty-second International Conference on Machine Learning,
-
[10]
Giang Hoang Nguyen, John Boaz Lee, Ryan A
URL https://openreview.net/forum?id=A6RjIi2ONN. Giang Hoang Nguyen, John Boaz Lee, Ryan A. Rossi, Nesreen K. Ahmed, Eunyee Koh, and Sungchul Kim. Continuous-time dynamic network embeddings. InCompanion Proceedings of the The Web Conference 2018, WWW ’18, pp. 969–976, Republic and Canton of Geneva, CHE,
2018
-
[11]
International World Wide Web Conferences Steering Committee. ISBN 9781450356404. doi: 10.1145/3184558.3191526. URLhttps://doi.org/10.1145/ 3184558.3191526. Pietro Panzarasa, Tore Opsahl, and Kathleen M. Carley. Patterns and dynamics of users’ behavior and interaction: Network analysis of an online community.Journal of the American Society for Information ...
-
[12]
URLhttps://onlinelibrary.wiley.com/doi/abs/ 10.1002/asi.21015
doi: https://doi.org/10.1002/asi.21015. URLhttps://onlinelibrary.wiley.com/doi/abs/ 10.1002/asi.21015. Aldo Pareja, Giacomo Domeniconi, Jie Chen, Tengfei Ma, Toyotaro Suzumura, Hiroki Kanezashi, Tim Kaler, Tao B. Schardl, and Charles E. Leiserson. EvolveGCN: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the Thirty-Fourth AAAI...
-
[13]
ISBN 9781713871088
Curran Associates Inc. ISBN 9781713871088. Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. Tem- poral graph networks for deep learning on dynamic graphs. InICML 2020 Workshop on Graph Representation Learning,
2020
-
[14]
Structured sequence modeling with graph convolutional recurrent networks
Youngjoo Seo, Michaël Defferrard, Pierre Vandergheynst, and Xavier Bresson. Structured sequence modeling with graph convolutional recurrent networks. InNeural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part I, pp. 362–373, Berlin, Heidelberg,
2018
-
[15]
Springer-Verlag. ISBN 978-3-030-04166-3. doi: 10.1007/978-3-030-04167-0_33. URLhttps://doi.org/10.1007/ 978-3-030-04167-0_33. Rakshit Trivedi, Mehrdad Farajtabar, Prasenjeet Biswal, and Hongyuan Zha. Dyrep: Learning representations over dynamic graphs. InInternational Conference on Learning Representations,
-
[16]
URLhttps://openreview. net/forum?id=rJXMpikCZ. Lu Wang, Xiaofu Chang, Shuang Li, Yunfei Chu, Hui Li, Wei Zhang, Xiaofeng He, Le Song, Jingren Zhou, and Hongxia Yang. Tcl: Transformer-based dynamic graph modelling via contrastive learning.arXiv preprint arXiv:2105.07944, 2021a. Xuhong Wang, Ding Lyu, Mengjian Li, Yang Xia, Qi Yang, Xinwen Wang, Xinguang Wa...
-
[17]
Association for Computing Machinery. ISBN 9781450390965. doi: 10.1145/3485447.3512164. URLhttps://doi.org/10.1145/ 3485447.3512164. Ronald J. Williams and Jing Peng. An efficient gradient-based algorithm for on-line training of recurrent network trajectories.Neural Comput., 2(4):490–501, December
-
[18]
doi: 10.1162/neco.1990.2.4.490
ISSN 0899-7667. doi: 10.1162/neco.1990.2.4.490. URLhttps://doi.org/10.1162/neco.1990.2.4.490. Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInterna- tional Conference on Learning Representations,
-
[19]
Association for Computing Machinery. ISBN 9781450393850. doi: 10.1145/3534678.3539300. URLhttps://doi.org/10.1145/3534678.3539300. Le Yu, Leilei Sun, Bowen Du, and Weifeng Lv. Towards better dynamic graph learning: New architecture and unified library. InThirty-seventh Conference on Neural Information Processing Systems,
-
[20]
Yanping Zheng, Zhewei Wei, and Jiajun Liu
doi: 10.1109/TITS.2019.2935152. Yanping Zheng, Zhewei Wei, and Jiajun Liu. Decoupled graph neural networks for large dynamic graphs.Proc. VLDB Endow., 16(9):2239–2247, May
-
[21]
ISSN 2150-8097. doi: 10.14778/3598581.3598595. URLhttps: //doi.org/10.14778/3598581.3598595. Yifan Zhu, Fangpeng Cong, Dan Zhang, Wenwen Gong, Qika Lin, Wenzheng Feng, Yuxiao Dong, and Jie Tang. Wingnn: Dynamic graph neural networks with random gradient aggregation window. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Min...
-
[22]
Association for Computing Machinery. ISBN 9798400701030. doi: 10.1145/3580305.3599551. URL https://doi.org/10.1145/3580305.3599551. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.