Learning Permutation from Structure Without Supervision
Pith reviewed 2026-06-29 22:20 UTC · model grok-4.3
The pith
An entropy-adaptive Gumbel-Sinkhorn locally adjusts temperature by assignment entropy to improve unsupervised permutation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
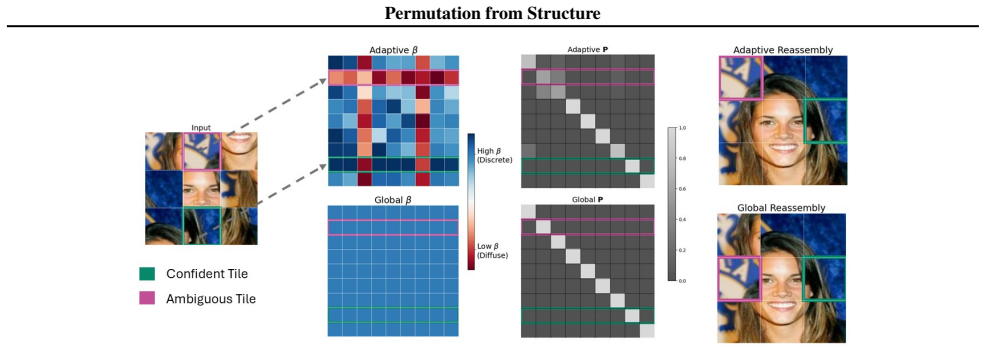
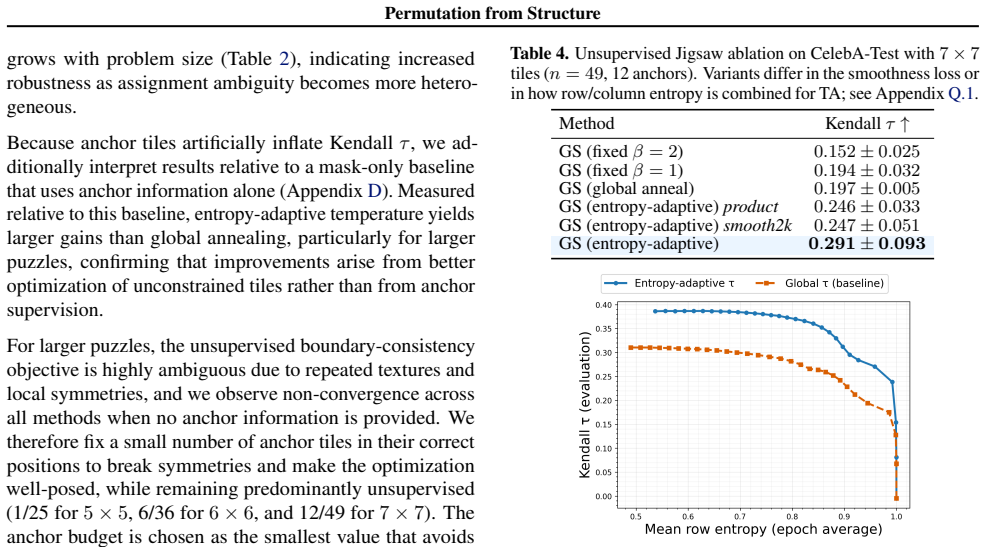
We introduce an entropy-adaptive formulation of Gumbel-Sinkhorn that locally modulates temperature based on assignment uncertainty. This allows confident assignments to discretize early while preserving exploration where uncertainty remains. Across sorting and jigsaw reconstruction tasks and in routing-style settings, adaptive entropy control improves training stability and final permutation quality relative to fixed-temperature baselines, particularly as problem size and assignment ambiguity increase.
What carries the argument
entropy-adaptive Gumbel-Sinkhorn operator that modulates each assignment's temperature according to the entropy of its current distribution
If this is right
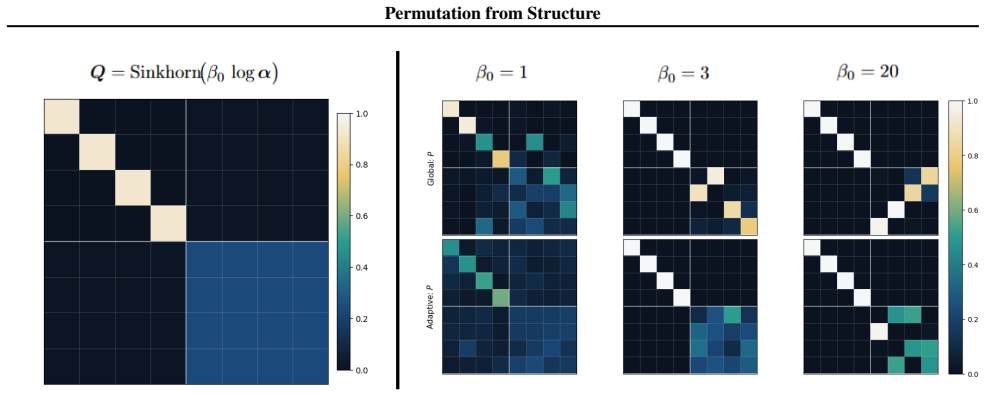
- Confident assignments discretize early while uncertain assignments keep exploring.
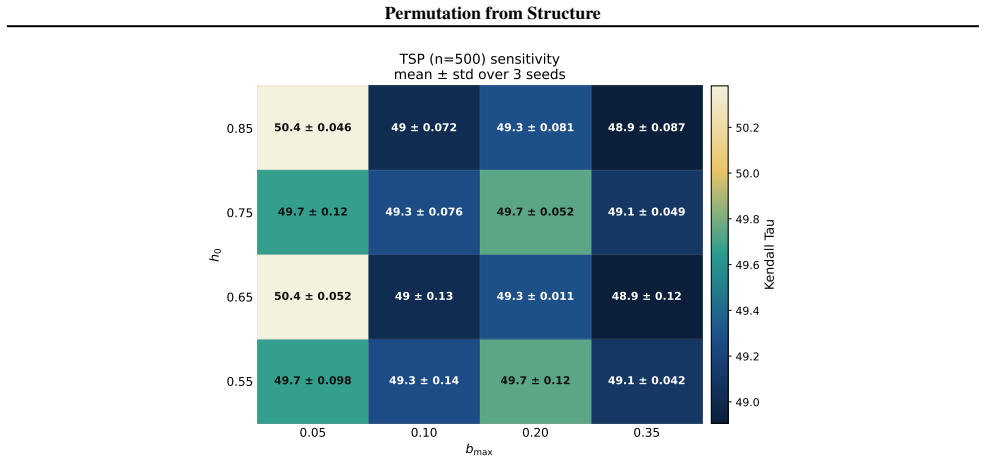
- Training stability increases with problem size and with higher assignment ambiguity.
- Final permutation matrices reach higher quality than those produced by fixed-temperature Gumbel-Sinkhorn.
- The same local-control benefit appears in sorting, jigsaw, and routing-style objectives.
Where Pith is reading between the lines
- The local-entropy idea could transfer to other differentiable combinatorial relaxations that currently rely on global temperature schedules.
- Adaptive modulation might reduce the amount of manual temperature tuning required when applying these methods to new domains.
- Tasks with spatially or structurally varying ambiguity may benefit more than uniform-uncertainty tasks.
Load-bearing premise
The entropy of each assignment's probability distribution supplies a reliable local signal of uncertainty that can safely drive temperature changes without creating optimization artifacts.
What would settle it
A side-by-side run on a large-scale ambiguous sorting or jigsaw task in which the entropy-adaptive version produces equal or lower stability and permutation quality than the best fixed-temperature schedule would falsify the claimed advantage.
Figures
read the original abstract
Many learning problems require uncovering a hidden ordering that reveals structure in unordered data, such as monotonicity in sorting or spatial continuity in jigsaw reconstruction. In these settings, permutations can be learned as latent operators by optimizing objectives defined directly on the reordered output, often without access to ground-truth orderings. Differentiable relaxations such as Gumbel-Sinkhorn make this approach practical by approximating permutation matrices with doubly stochastic matrices. However, learning from structure without supervision induces a non-uniform uncertainty: some assignments become confident early, while others remain ambiguous. Existing methods control this process using a single global temperature, forcing all assignments to sharpen or diffuse simultaneously and leading to instability at scale. We introduce an entropy-adaptive formulation of Gumbel-Sinkhorn that locally modulates temperature based on assignment uncertainty. This allows confident assignments to discretize early while preserving exploration where uncertainty remains. Across sorting and jigsaw reconstruction tasks and in routing-style settings, adaptive entropy control improves training stability and final permutation quality relative to fixed-temperature baselines, particularly as problem size and assignment ambiguity increase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an entropy-adaptive formulation of Gumbel-Sinkhorn that locally modulates temperature based on assignment uncertainty. This allows confident assignments to discretize early while preserving exploration where uncertainty remains. It reports improved training stability and final permutation quality relative to fixed-temperature baselines on sorting, jigsaw reconstruction, and routing-style tasks, particularly as problem size and assignment ambiguity increase.
Significance. If the empirical claims hold with proper validation and the adaptive mechanism integrates cleanly, the approach could address a practical limitation of global temperature schedules in differentiable permutation learning, offering better handling of non-uniform uncertainty in unsupervised structure discovery tasks.
major comments (2)
- [Abstract] Abstract: the central empirical claim of improved stability and quality is asserted without any quantitative results, error bars, dataset details, ablation studies, or baseline comparisons, which is load-bearing for assessing whether the adaptive entropy control delivers the stated benefits.
- Method description (no equation or section cited in provided text): no derivation is supplied showing how per-assignment entropy modulates temperature inside the Gumbel noise + scaled softmax + Sinkhorn pipeline while preserving exact double-stochasticity after each iteration or avoiding new gradient artifacts.
minor comments (1)
- [Abstract] Abstract could specify the exact problem sizes, number of tasks, and fixed-temperature baselines used to support the scaling claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of empirical claims and the technical derivation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of improved stability and quality is asserted without any quantitative results, error bars, dataset details, ablation studies, or baseline comparisons, which is load-bearing for assessing whether the adaptive entropy control delivers the stated benefits.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claims. In the revision we will incorporate concise numerical results (e.g., stability metrics such as training-loss variance and final permutation accuracy deltas versus fixed-temperature baselines), dataset sizes, and a brief mention of the main baselines and tasks. revision: yes
-
Referee: [—] Method description (no equation or section cited in provided text): no derivation is supplied showing how per-assignment entropy modulates temperature inside the Gumbel noise + scaled softmax + Sinkhorn pipeline while preserving exact double-stochasticity after each iteration or avoiding new gradient artifacts.
Authors: The manuscript introduces the entropy-adaptive formulation but does not contain a self-contained derivation of the per-assignment temperature modulation or explicit verification of the listed properties. We will add a dedicated subsection that (i) derives the entropy-based temperature schedule inside the Gumbel-Sinkhorn iteration, (ii) shows that each Sinkhorn step continues to produce a doubly-stochastic matrix, and (iii) analyzes the resulting gradient to confirm absence of new artifacts. revision: yes
Circularity Check
No significant circularity; proposal is an independent modification
full rationale
The paper proposes an entropy-adaptive variant of Gumbel-Sinkhorn as a direct change to the existing operator, allowing local temperature modulation based on per-assignment entropy. No equations, derivations, or self-citations are exhibited that reduce this adaptation or its claimed benefits to a quantity defined by the method itself, a fitted input renamed as prediction, or a load-bearing self-citation chain. The central claim rests on the modification plus empirical results on sorting/jigsaw tasks rather than any self-referential reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Gumbel-Sinkhorn relaxation can approximate permutation matrices via doubly stochastic matrices
Reference graph
Works this paper leans on
-
[1]
Stochastic optimization of sorting net- works via continuous relaxations
Aditya Grover, Eric Wang, Aaron Zweig, and Ste- fano Ermon. Stochastic optimization of sorting net- works via continuous relaxations. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=H1 eSS3CcKX
2019
-
[2]
Softsort: A continuous relaxation for the argsort operator
Sebastian Prillo and Julian Eisenschlos. Softsort: A continuous relaxation for the argsort operator. InPro- ceedings of Machine Learning Research, 2020
2020
-
[3]
Differentiable ranks and sorting using optimal trans- port
Marco Cuturi, Olivier Teboul, and Jean-Philippe Vert. Differentiable ranks and sorting using optimal trans- port. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[4]
Fast differentiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differentiable sorting and ranking. InProceedings of Machine Learning Research, 2020
2020
-
[5]
Deeppermnet: Visual permutation learning
Rodrigo Santa Cruz, Basura Fernando, Anoop Cherian, and Stephen Gould. Deeppermnet: Visual permutation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[6]
Learning latent permutations with gumbel-sinkhorn networks
Gonzalo Mena, David Belanger, Scott Linderman, and Jasper Snoek. Learning latent permutations with gumbel-sinkhorn networks. InInternational Confer- ence on Learning Representations (ICLR), 2018. URL https://openreview.net/forum?id=By t3oJ-0W
2018
-
[7]
Learning Permutations with Sinkhorn Policy Gradient
Patrick Emami and Sanjay Ranka. Learning permu- tations with sinkhorn policy gradient.arXiv preprint arXiv:1805.07010, 2018. URL https://arxiv. org/abs/1805.07010
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Unsu- pervised learning for solving the travelling salesman problem.Advances in neural information processing systems, 36:47264–47278, 2023
Yimeng Min, Yiwei Bai, and Carla P Gomes. Unsu- pervised learning for solving the travelling salesman problem.Advances in neural information processing systems, 36:47264–47278, 2023
2023
-
[9]
COPER: Correlation-based permutations for multi-view clustering
Ran Eisenberg, Jonathan Svirsky, and Ofir Linden- baum. COPER: Correlation-based permutations for multi-view clustering. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=5Z EbpBYGwH
2025
-
[10]
Sinkhorn Distances: Lightspeed Computation of Optimal Transportation Distances
Marco Cuturi. Sinkhorn distances: Lightspeed compu- tation of optimal transport. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2013. URL https://arxiv.org/abs/1306.0895
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Ot4p: Unlocking effective orthogonal group path for permutation relaxation
Yaming Guo, Chen Zhu, Hengshu Zhu, and Tieru Wu. Ot4p: Unlocking effective orthogonal group path for permutation relaxation. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2024. URL https://openreview.net/forum?id=pM JFaBzoG3
2024
-
[12]
arXiv preprint arXiv:2408.11620 , year=
L´ena¨ıc Chizat. Annealed sinkhorn for optimal trans- port: convergence, regularization path, and debias- ing.arXiv preprint arXiv:2408.11620, 2024. URL https://arxiv.org/abs/2408.11620
-
[13]
Re- visiting the noise model of stochastic gradient descent
Barak Battash, Lior Wolf, and Ofir Lindenbaum. Re- visiting the noise model of stochastic gradient descent. InInternational Conference on Artificial Intelligence and Statistics, pages 4780–4788. PMLR, 2024
2024
-
[14]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categori- cal reparameterization with gumbel-softmax. InIn- ternational Conference on Learning Representations (ICLR), 2017. URL https://arxiv.org/abs/ 1611.01144
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representations (ICLR), 2017. URL ht tps://arxiv.org/abs/1611.00712
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Sun and others
X. Sun and others. A unified perspective on regular- ization and perturbation in differentiable subset selec- tion. InProceedings of Machine Learning Research (PMLR), 2023. URL https://proceedings. mlr.press/v206/sun23e.html
2023
-
[17]
Felix Petersen, Hilde Kuehne, Christian Borgelt, and Oliver Deussen. Differentiable top-k classification learning. InProceedings of Machine Learning Re- search, 2022. URL https://arxiv.org/abs/ 2206.07290
-
[18]
Feature selection using stochas- tic gates
Yutaro Yamada, Ofir Lindenbaum, Sahand Negahban, and Yuval Kluger. Feature selection using stochas- tic gates. In Hal Daum ´e III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Ma- chine Learning Research, pages 10648–10659. PMLR, 13–18 Jul 2020. URL https://proceedings. mlr.pres...
2020
-
[19]
Contextual feature selection with conditional stochastic gates
Ram Dyuthi Sristi, Ofir Lindenbaum, Shira Lifshitz, Maria Lavzin, Jackie Schiller, Gal Mishne, and Hadas Benisty. Contextual feature selection with conditional stochastic gates. InForty-first International Confer- ence on Machine Learning, 2024. 11 Permutation from Structure
2024
-
[20]
Differentiable unsupervised feature selection based on a gated laplacian
Ofir Lindenbaum, Uri Shaham, Erez Peterfreund, Jonathan Svirsky, Nicolas Casey, and Yuval Kluger. Differentiable unsupervised feature selection based on a gated laplacian. InAdvances in Neural Information Processing Systems, volume 34, pages 1530–1542,
-
[21]
cc/paper/2021/hash/0bc10d8a74dbafb f242e30433e83aa56-Abstract.html
URL https://proceedings.neurips. cc/paper/2021/hash/0bc10d8a74dbafb f242e30433e83aa56-Abstract.html
2021
-
[22]
Hybrid autoencoders for tabular data: Leveraging model-based augmenta- tion in low-label settings.Advances in Neural Infor- mation Processing Systems, 38:95066–95085, 2026
Erel Naor and Ofir Lindenbaum. Hybrid autoencoders for tabular data: Leveraging model-based augmenta- tion in low-label settings.Advances in Neural Infor- mation Processing Systems, 38:95066–95085, 2026
2026
-
[23]
Unsupervised learning permutations for tsp using gumbel-sinkhorn operator
Yimeng Min and Carla Gomes. Unsupervised learning permutations for tsp using gumbel-sinkhorn operator. InNeurIPS 2023 Workshop Optimal Transport and Machine Learning, 2023
2023
- [24]
-
[25]
Gur Elkin, Ofir Itzhak Shahar, and Ohad Ben- Shahar. Puzlm: Solving jigsaw puzzles with sequence- to-sequence language models.arXiv preprint arXiv:2511.06315, 2025. URL https://arxi v.org/abs/2511.06315
-
[26]
Ranking via Sinkhorn Propagation
Ryan Prescott Adams and Richard S Zemel. Rank- ing via sinkhorn propagation.arXiv preprint arXiv:1106.1925, 2011
work page internal anchor Pith review Pith/arXiv arXiv 1925
-
[27]
Learning coupled embedding using multiview diffu- sion maps
Ofir Lindenbaum, Arie Yeredor, and Moshe Salhov. Learning coupled embedding using multiview diffu- sion maps. InInternational Conference on Latent Vari- able Analysis and Signal Separation, pages 127–134. Springer, 2015
2015
-
[28]
Multi-channel fusion for seismic event detection and classification
Ofir Lindenbaum, Neta Rabin, Yuri Bregman, and Amir Averbuch. Multi-channel fusion for seismic event detection and classification. In2016 IEEE In- ternational Conference on the Science of Electrical Engineering (ICSEE), pages 1–5. IEEE, 2016
2016
-
[29]
Multi-view kernel consensus for data analysis.Applied and Computational Harmonic Analysis, 49(1):208– 228, 2020
Moshe Salhov, Ofir Lindenbaum, Yariv Aizenbud, Avi Silberschatz, Yoel Shkolnisky, and Amir Averbuch. Multi-view kernel consensus for data analysis.Applied and Computational Harmonic Analysis, 49(1):208– 228, 2020. 12 Permutation from Structure A. Proof of Proposition 1 We prove Proposition 1 for the block-ambiguous cost matrix defined in (5). Letn=n 1 +n ...
2020
-
[30]
, n} with |F|=k
Select an anchor set F⊆ {1, . . . , n} with |F|=k . Unless otherwise stated, anchor positions are sampled uniformly at random
-
[31]
Place all anchor tiles at their correct positions according toπ ⋆
-
[32]
Assign the remainingn−ktiles to the remaining positions using a uniform random permutation
-
[33]
This procedure uses exactly the same anchor information available to the learning methods but does not exploit any structural cues from image content or boundary consistency
Compute Kendallτbetween the resulting permutation andπ ⋆. This procedure uses exactly the same anchor information available to the learning methods but does not exploit any structural cues from image content or boundary consistency. The reported values are Monte Carlo estimates of the expected Kendall τ under the above process. For each puzzle size and an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.