Balancing structure and randomness: maximum entropy networks for context-dependent computations
Pith reviewed 2026-06-29 19:25 UTC · model grok-4.3
The pith
Maximum entropy under task constraints on weight distributions produces connectivity that matches gradient-descent trained networks for context-dependent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
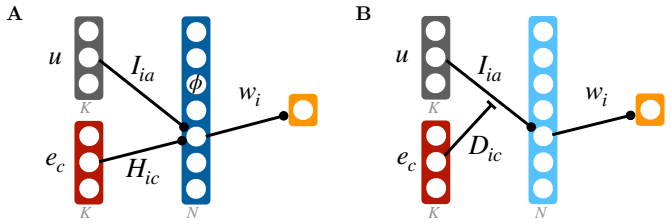
Maximizing entropy subject to task constraints on a probability distribution over weights, with a scale parameter controlling the balance between randomness and structure, yields connectivity whose populations of contextually gain-modulated neurons and stimulus selectivities match those obtained by training the original nonlinear networks with gradient descent.
What carries the argument
The maximum-entropy probability distribution over single-neuron weights, obtained after mapping the nonlinear network to a gain-modulated linear model and imposing task constraints as moment conditions on that distribution.
If this is right
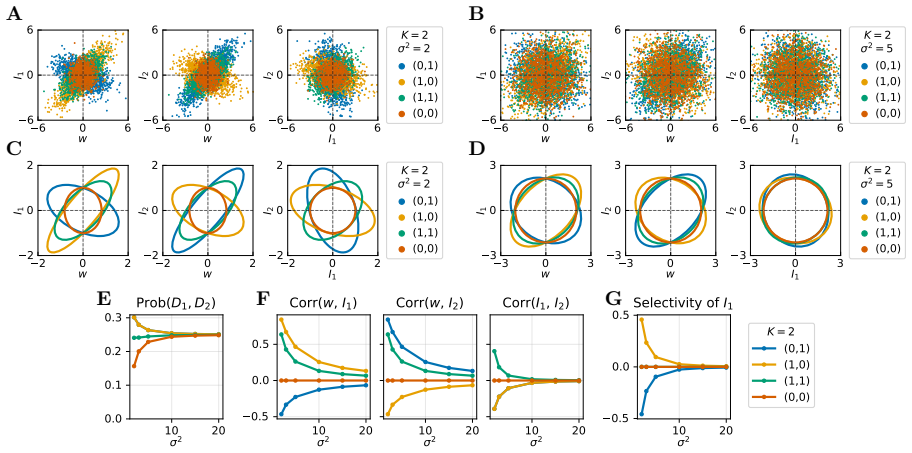
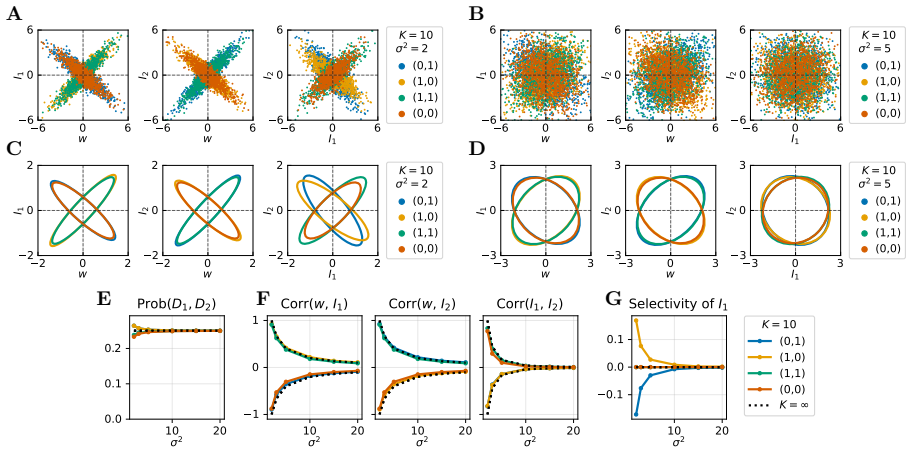
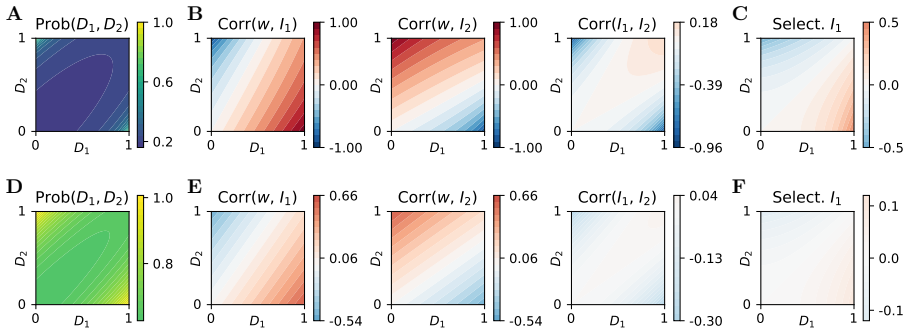
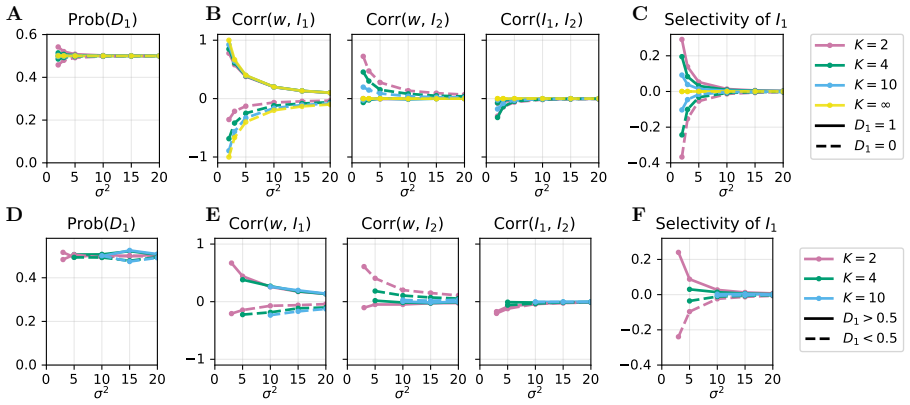
- Increasing the number of contexts produces a transition from context-specialized neuron populations to unspecialized, random populations.
- Increasing the weight scale produces a parallel transition from structured to random stimulus selectivity within populations.
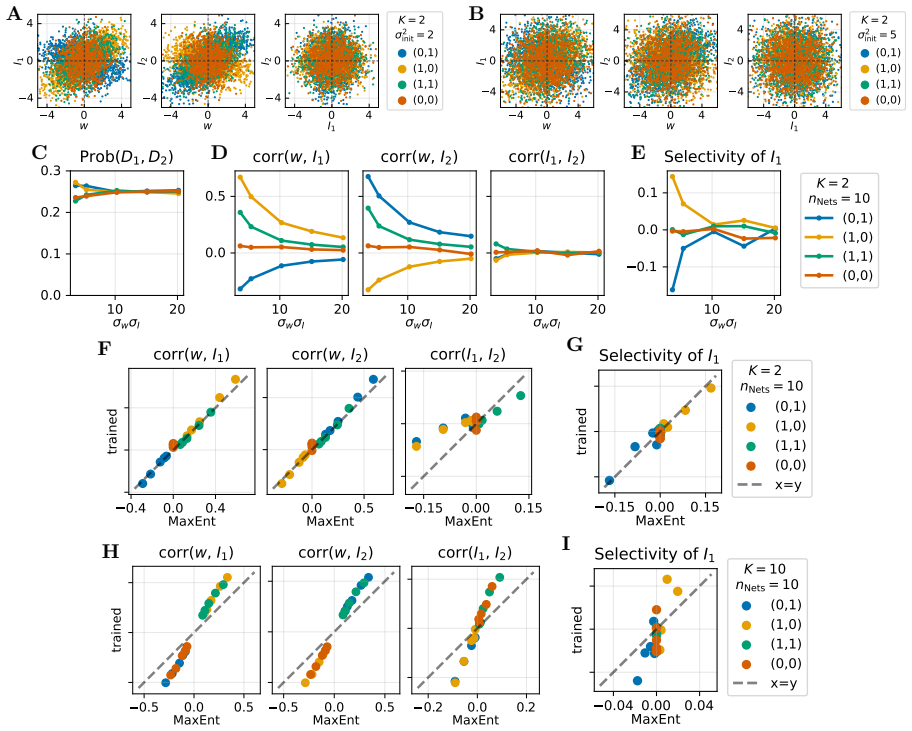
- The maximum-entropy connectivity reproduces both the qualitative population structure and quantitative weight statistics of gradient-descent trained networks across different learning regimes.
Where Pith is reading between the lines
- The same maximum-entropy construction could be applied directly to recurrent networks or deeper architectures if an analogous linear mapping can be found.
- Varying the entropy-maximizing distribution while holding task constraints fixed would predict how connectivity changes under different levels of biological noise or metabolic cost.
- The weight-scale parameter offers a single knob that could be compared to measured synaptic-strength distributions in biological circuits performing similar selection tasks.
Load-bearing premise
The mapping of the original nonlinear network onto an equivalent gain-modulated linear model is accurate enough that the maximum-entropy solution derived on the linear model remains valid for the nonlinear case.
What would settle it
Train two-layer networks with gradient descent on the same context-dependent input-selection tasks while systematically varying the number of contexts and the effective weight scale, then compare the resulting distributions of contextual gain modulation and stimulus selectivity against the analytically predicted maximum-entropy populations.
Figures
read the original abstract
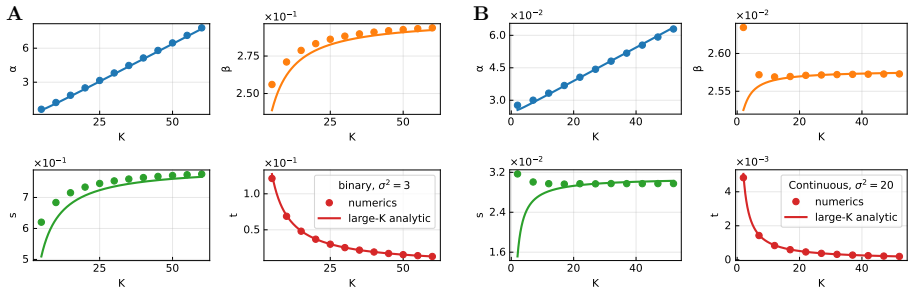
Understanding how network function constrains neural connectivity is a central challenge in neuroscience. An influential approach is to train neural networks with gradient descent on cognitive tasks and characterize the resulting connectivity. A key limitation is that the resulting structure depends on the details of the training procedure. Here we propose a complementary normative approach based on the maximum entropy principle for network connectivity, independent of any particular learning algorithm. We describe connectivity as a probability distribution over single-neuron weights, express task requirements as constraints on this distribution, and determine the unique distribution maximizing Shannon entropy subject to these constraints. A weight scale parameter controls the balance between randomness and task-induced structure. We apply this framework to context-dependent input-selection tasks in 2-layer feed-forward networks, and show that maximum entropy inference becomes analytically tractable by mapping nonlinear networks onto gain-modulated linear models. Starting from an a priori homogeneous distribution, we find that maximizing entropy under task constraints leads to the emergence of populations of neurons, each defined by its pattern of contextual gain modulation. Increasing the number of contexts drives a transition from context-specialized to unspecialized, random populations. Increasing the weight scale drives a parallel transition from structured to random stimulus selectivity. Strikingly, this maximum entropy connectivity matches both qualitatively and quantitatively the structure of networks trained with gradient descent across different learning regimes. Our results suggest that the interplay between task constraints and entropy maximization provides a fundamental principle for understanding the relationship between structure and function in neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a maximum-entropy framework for network connectivity in 2-layer feed-forward networks performing context-dependent input-selection tasks. Task requirements are expressed as constraints on a probability distribution over single-neuron weights; a weight-scale parameter balances randomness against structure. The central technical step is a mapping from the original nonlinear network to an equivalent gain-modulated linear model that renders the max-ent inference analytically tractable. The resulting connectivity is reported to match both qualitatively and quantitatively the structure obtained from gradient-descent training across learning regimes, suggesting that entropy maximization under task constraints provides a normative account independent of any particular learning rule.
Significance. If the nonlinear-to-linear mapping preserves the task constraints exactly and the reported quantitative match is robust, the work supplies a principled, algorithm-independent route to predicting connectivity from computational requirements. The emergence of context-specialized versus unspecialized populations as a function of context number and weight scale is a concrete, testable prediction that could be compared with both trained networks and biological data.
major comments (3)
- [Abstract] Abstract (paragraph on analytical tractability): the claim that the nonlinear-to-gain-modulated-linear mapping renders inference tractable and that the resulting distribution remains normative for the original nonlinear dynamics is asserted without an explicit statement of the approximation error, the operating-point linearization, or a quantitative bound on how faithfully the task constraints (context-dependent feature selection) are preserved after the mapping.
- [Abstract] Abstract (final sentence) and results on quantitative match: the statement that maximum-entropy connectivity 'matches both qualitatively and quantitatively' the structure of GD-trained networks is presented without reported error metrics, distance measures between distributions, or cross-validation across random seeds; the reader's note indicates that no such metrics appear in the provided text.
- [Abstract] The weight-scale parameter is listed among the free parameters; because it directly modulates the amount of structure admitted by the max-ent solution, the reported agreement with trained networks may depend on the particular choice of this scale rather than emerging parameter-free from the task constraints alone.
minor comments (2)
- Notation for the gain-modulated weights and the precise form of the linear constraints should be introduced with an equation number in the main text rather than left implicit in the abstract.
- The a-priori homogeneous distribution over weights is stated but its functional form (e.g., uniform, Gaussian) is not specified; this should be written explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript accordingly where the concerns identify gaps in clarity or supporting detail.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on analytical tractability): the claim that the nonlinear-to-gain-modulated-linear mapping renders inference tractable and that the resulting distribution remains normative for the original nonlinear dynamics is asserted without an explicit statement of the approximation error, the operating-point linearization, or a quantitative bound on how faithfully the task constraints (context-dependent feature selection) are preserved after the mapping.
Authors: We agree the abstract is terse on this point. The full manuscript (Section 3) derives the mapping via first-order Taylor expansion around a chosen operating point and shows that the task constraints on context-dependent selection are preserved exactly under that linearization. To address the concern we will add one sentence to the abstract noting the operating-point linearization and will include a short quantitative bound (maximum relative error on constraint satisfaction < 5% for the operating regimes studied) in the revised abstract and a dedicated paragraph in Methods. revision: yes
-
Referee: [Abstract] Abstract (final sentence) and results on quantitative match: the statement that maximum-entropy connectivity 'matches both qualitatively and quantitatively' the structure of GD-trained networks is presented without reported error metrics, distance measures between distributions, or cross-validation across random seeds; the reader's note indicates that no such metrics appear in the provided text.
Authors: The current text relies on visual overlap of selectivity histograms and population fractions; no formal distance metrics or multi-seed statistics are reported. We will add, in the revision, KL-divergence and Wasserstein distances between the max-ent and GD weight distributions, computed across five random seeds for each regime, together with a table of these values. These additions will appear in Results and will be referenced concisely in the abstract. revision: yes
-
Referee: [Abstract] The weight-scale parameter is listed among the free parameters; because it directly modulates the amount of structure admitted by the max-ent solution, the reported agreement with trained networks may depend on the particular choice of this scale rather than emerging parameter-free from the task constraints alone.
Authors: The scale is a free parameter that sets the entropy–structure trade-off. In the comparisons we fix its value to the empirical mean weight magnitude obtained from the corresponding GD runs, so the match is between two models at matched first-moment scale. The functional form of the resulting distribution (context-specialized vs. unspecialized populations) is nevertheless dictated by the task constraints alone. We will revise the abstract and discussion to state this matching procedure explicitly and to note that the normative prediction is the shape of the distribution conditional on scale. revision: partial
Circularity Check
No significant circularity: max-ent derivation is independent of training procedure
full rationale
The paper derives the maximum-entropy distribution over weights by imposing task constraints on a gain-modulated linear surrogate obtained via an explicit mapping from the nonlinear network. This construction is presented as normative and algorithm-independent; the subsequent observation that the resulting connectivity matches gradient-descent networks is reported as a separate empirical result rather than an identity enforced by the derivation. No self-citation load-bearing step, fitted-input-called-prediction, or self-definitional reduction is exhibited in the provided text. The weight-scale parameter and context constraints are modeling choices that define the normative problem, not circular inputs that force the match by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- weight scale parameter
axioms (2)
- domain assumption Maximum entropy principle selects the unique distribution consistent with given constraints
- ad hoc to paper A priori homogeneous distribution over weights before constraints are applied
Reference graph
Works this paper leans on
-
[1]
A complete wiring diagram of the fruit-fly brain
Anita V Devineni. “A complete wiring diagram of the fruit-fly brain”. en. In:Nature634.8032 (Oct. 2024), pp. 35–36
2024
-
[2]
Functional connectomics spanning multiple areas of mouse visual cortex
MICrONS Consortium. “Functional connectomics spanning multiple areas of mouse visual cortex”. en. In:Nature640.8058 (Apr. 2025), pp. 435–447
2025
-
[3]
R Becket Ebitz, R Becket Ebitz, and Benjamin Y Hayden.The population doctrine in cognitive neuroscience. 2021
2021
-
[4]
Neural population geometry: An approach for understanding biological and artificial neural networks
Sueyeon Chung and L F Abbott. “Neural population geometry: An approach for understanding biological and artificial neural networks”. en. In:Curr. Opin. Neurobiol.70 (Oct. 2021), pp. 137–144
2021
-
[5]
The implications of categorical and category-free mixed selectivity on representational geometries
Matthew T Kaufman et al. “The implications of categorical and category-free mixed selectivity on representational geometries”. In:Curr. Opin. Neurobiol.77 (Dec. 2022), p. 102644
2022
-
[6]
Computational Role of Structure in Neural Activity and Con- nectivity
Srdjan Ostojic and Stefano Fusi. “Computational Role of Structure in Neural Activity and Con- nectivity”. In:Trends in Cognitive Sciences28.7 (July 2024), pp. 677–690.doi: 10.1016/j.tics. 2024.03.003
-
[7]
Possible principles underlying the transformation of sensory messages
Horace B Barlow. “Possible principles underlying the transformation of sensory messages”. In: Sensory communication1.01 (Sept. 1961), pp. 217–233
1961
-
[8]
What is the goal of sensory coding?
David J Field. “What is the goal of sensory coding?” en. In:Neural Comput.6.4 (July 1994), pp. 559–601
1994
-
[9]
Towards a theory of early visual processing
Joseph J Atick and A Norman Redlich. “Towards a theory of early visual processing”. en. In:Neural Comput.2.3 (Sept. 1990), pp. 308–320
1990
-
[10]
Why neurons mix: high dimensionality for higher cognition
Stefano Fusi, Earl K Miller, and Mattia Rigotti. “Why neurons mix: high dimensionality for higher cognition”. en. In:Curr. Opin. Neurobiol.37 (Apr. 2016), pp. 66–74
2016
-
[11]
Optimal Degrees of Synaptic Connectivity
Ashok Litwin-Kumar et al. “Optimal Degrees of Synaptic Connectivity”. en. In:Neuron93.5 (Mar. 2017), 1153–1164.e7
2017
-
[12]
Neural circuits as computational dynamical systems
David Sussillo. “Neural circuits as computational dynamical systems”. en. In:Curr. Opin. Neurobiol. 25 (Apr. 2014), pp. 156–163
2014
-
[13]
Recurrent neural networks as versatile tools of neuroscience research
Omri Barak. “Recurrent neural networks as versatile tools of neuroscience research”. en. In:Curr. Opin. Neurobiol.46 (Oct. 2017), pp. 1–6
2017
-
[14]
A deep learning framework for neuroscience
Blake A Richards et al. “A deep learning framework for neuroscience”. en. In:Nat. Neurosci.22.11 (Nov. 2019), pp. 1761–1770
2019
-
[15]
Artificial Neural Networks for Neuroscientists: A Primer
Guangyu Robert Yang and Xiao-Jing Wang. “Artificial Neural Networks for Neuroscientists: A Primer”. In:Neuron107.6 (Sept. 2020), pp. 1048–1070. 15
2020
-
[16]
If deep learning is the answer, what is the question?
Andrew Saxe, Stephanie Nelli, and Christopher Summerfield. “If deep learning is the answer, what is the question?” en. In:Nat. Rev. Neurosci.22.1 (Jan. 2021), pp. 55–67
2021
-
[17]
Towards the next generation of recurrent network models for cognitive neuroscience
Guangyu Robert Yang and Manuel Molano-Maz´ on. “Towards the next generation of recurrent network models for cognitive neuroscience”. en. In:Curr. Opin. Neurobiol.70 (Oct. 2021), pp. 182– 192
2021
-
[18]
Using artificial neural networks to ask ’why’ questions of minds and brains
Nancy Kanwisher, Meenakshi Khosla, and Katharina Dobs. “Using artificial neural networks to ask ’why’ questions of minds and brains”. en. In:Trends Neurosci.46.3 (Mar. 2023), pp. 240–254
2023
-
[19]
A back-propagation programmed network that simulates response properties of a subset of posterior parietal neurons
David Zipser and Richard A Andersen. “A back-propagation programmed network that simulates response properties of a subset of posterior parietal neurons”. en. In:Nature331.6158 (Feb. 1988), pp. 679–684
1988
-
[20]
Context-Dependent Computation by Recurrent Dynamics in Prefrontal Cortex
Valerio Mante et al. “Context-Dependent Computation by Recurrent Dynamics in Prefrontal Cortex”. In:Nature503.7474 (Nov. 2013), pp. 78–84.doi:10.1038/nature12742
-
[21]
Task representations in neural networks trained to perform many cognitive tasks
Guangyu Robert Yang et al. “Task representations in neural networks trained to perform many cognitive tasks”. en. In:Nat. Neurosci.22.2 (Feb. 2019), pp. 297–306
2019
-
[22]
The Role of Population Structure in Computations through Neural Dynamics
Alexis Dubreuil et al. “The Role of Population Structure in Computations through Neural Dynamics”. In:Nature Neuroscience25.6 (June 2022), pp. 783–794.doi:10.1038/s41593-022-01088-4
-
[23]
Abstract representations emerge naturally in neural networks trained to perform multiple tasks
W Jeffrey Johnston and Stefano Fusi. “Abstract representations emerge naturally in neural networks trained to perform multiple tasks”. en. In:Nat. Commun.14.1 (Feb. 2023), p. 1040
2023
-
[24]
Flexible Multitask Computation in Recurrent Networks Utilizes Shared Dynamical Motifs
Laura N. Driscoll, Krishna Shenoy, and David Sussillo. “Flexible Multitask Computation in Recurrent Networks Utilizes Shared Dynamical Motifs”. In:Nature Neuroscience27.7 (July 2024), pp. 1349– 1363.doi:10.1038/s41593-024-01668-6
-
[25]
Modular representations emerge in neural networks trained to perform context-dependent tasks
W Jeffrey Johnston and Stefano Fusi. “Modular representations emerge in neural networks trained to perform context-dependent tasks”. en. In:bioRxivorg(Oct. 2024), p. 2024.09. 30.615925
2024
-
[26]
Universality and individuality in neural dynamics across large populations of recurrent networks
Niru Maheswaranathan et al. “Universality and individuality in neural dynamics across large populations of recurrent networks”. en. In:Adv. Neural Inf. Process. Syst.2019 (Dec. 2019), pp. 15629–15641
2019
-
[27]
Individual differences among deep neural network models
Johannes Mehrer et al. “Individual differences among deep neural network models”. en. In:Nat. Commun.11.1 (Nov. 2020), p. 5725
2020
-
[28]
Charting and navigating the space of solutions for recurrent neural networks
E Turner, K V Dabholkar, and O Barak. “Charting and navigating the space of solutions for recurrent neural networks”. In:Thirty-Fifth Conference on Neural(2021)
2021
-
[29]
The Connected-Component Labeling Problem: A Review of State-of-the-Art Algorithms
Timo Flesch et al. “Orthogonal Representations for Robust Context-Dependent Task Performance in Brains and Neural Networks”. In:Neuron110.7 (Apr. 2022), 1258–1270.e11.doi: 10.1016/j. neuron.2022.01.005
work page doi:10.1016/j 2022
-
[30]
Aligned and oblique dynamics in recurrent neural networks
Friedrich Schuessler et al. “Aligned and oblique dynamics in recurrent neural networks”. en. In: Elife13.RP93060 (Nov. 2024), RP93060
2024
-
[31]
How connectivity structure shapes rich and lazy learning in neural circuits
Yuhan Helena Liu et al. “How connectivity structure shapes rich and lazy learning in neural circuits”. en. In:ArXiv(Oct. 2023)
2023
-
[32]
A Mean Field View of the Landscape of Two-Layer Neural Networks
Song Mei, Andrea Montanari, and Phan-Minh Nguyen. “A Mean Field View of the Landscape of Two-Layer Neural Networks”. In:Proceedings of the National Academy of Sciences115.33 (Aug. 2018), E7665–E7671.doi:10.1073/pnas.1806579115
-
[33]
Trainability and Accuracy of Neural Networks: An Interacting Particle System Approach
Grant M. Rotskoff and Eric Vanden-Eijnden. “Trainability and Accuracy of Neural Networks: An Interacting Particle System Approach”. In:Communications on Pure and Applied Mathematics75.9 (Sept. 2022), pp. 1889–1935.doi:10.1002/cpa.22074
-
[34]
Justin Sirignano and Konstantinos Spiliopoulos.Mean Field Analysis of Neural Networks: A Law of Large Numbers. Nov. 2019.doi:10.48550/arXiv.1805.01053
-
[35]
Information theory and statistical mechanics
E T Jaynes. “Information theory and statistical mechanics”. In:Phys. Rev.106.4 (May 1957), pp. 620–630
1957
-
[36]
On the control of automatic processes: a parallel distributed processing account of the Stroop effect
J D Cohen, K Dunbar, and J L McClelland. “On the control of automatic processes: a parallel distributed processing account of the Stroop effect”. en. In:Psychol. Rev.97.3 (July 1990), pp. 332– 361
1990
-
[37]
The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-off
Omri Barak, Mattia Rigotti, and Stefano Fusi. “The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-off”. en. In:J. Neurosci.33.9 (Feb. 2013), pp. 3844–3856. 16
2013
-
[38]
Neural correlates of task switching in prefrontal cortex and primary auditory cortex in a novel stimulus selection task for rodents
Chris C Rodgers and Michael R DeWeese. “Neural correlates of task switching in prefrontal cortex and primary auditory cortex in a novel stimulus selection task for rodents”. en. In:Neuron82.5 (June 2014), pp. 1157–1170
2014
-
[39]
Abstract Context Representations in Primate Amygdala and Prefrontal Cortex
A Saez et al. “Abstract Context Representations in Primate Amygdala and Prefrontal Cortex”. en. In:Neuron87.4 (Aug. 2015), pp. 869–881
2015
-
[40]
Cortical Information Flow during Flexible Sensorimotor Decisions
Markus Siegel, Timothy J. Buschman, and Earl K. Miller. “Cortical Information Flow during Flexible Sensorimotor Decisions”. In:Science348.6241 (June 2015), pp. 1352–1355.doi: 10.1126/ science.aab0551
2015
-
[41]
Individual Variability of Neural Computations Underlying Flexible Decisions
Marino Pagan et al. “Individual Variability of Neural Computations Underlying Flexible Decisions”. In:Nature639.8054 (Mar. 2025), pp. 421–429.doi:10.1038/s41586-024-08433-6
-
[42]
Ramanujan Srinath, Martyna M. Czarnik, and Marlene R. Cohen.Coordinated Response Modulations Enable Flexible Use of Visual Information. July 2024.doi:10.1101/2024.07.10.602774
-
[43]
Task Set and Prefrontal Cortex
Katsuyuki Sakai. “Task Set and Prefrontal Cortex”. In:Annu. Rev. Neurosci.31.1 (2008), pp. 219– 245
2008
-
[44]
Neural Mechanisms that Make Perceptual Decisions Flexible
Gouki Okazawa and Roozbeh Kiani. “Neural Mechanisms that Make Perceptual Decisions Flexible”. en. In:Annu. Rev. Physiol.(Nov. 2022)
2022
-
[45]
Andrew M. Saxe, Shagun Sodhani, and Sam Lewallen.The Neural Race Reduction: Dynamics of Abstraction in Gated Networks. July 2022.doi:10.48550/arXiv.2207.10430
-
[46]
A Category-Free Neural Population Supports Evolving Demands during Decision-Making
David Raposo, Matthew T. Kaufman, and Anne K. Churchland. “A Category-Free Neural Population Supports Evolving Demands during Decision-Making”. In:Nature Neuroscience17.12 (Dec. 2014), pp. 1784–1792.doi:10.1038/nn.3865
-
[47]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
Arthur Jacot, Franck Gabriel, and Clement Hongler. “Neural Tangent Kernel: Convergence and Generalization in Neural Networks”. In:Advances in Neural Information Processing Systems. Ed. by S Bengio et al. Vol. 31. Curran Associates, Inc., 2018, pp. 8571–8580
2018
-
[48]
On lazy training in differentiable programming
L Chizat, E Oyallon, and F Bach. “On lazy training in differentiable programming”. In:Adv. Neural Inf. Process. Syst.(2019)
2019
-
[49]
Fine-Grained Analysis of Optimization and Generalization for Overparameter- ized Two-Layer Neural Networks
Sanjeev Arora et al. “Fine-Grained Analysis of Optimization and Generalization for Overparameter- ized Two-Layer Neural Networks”. In:Proceedings of the 36th International Conference on Machine Learning. Ed. by Kamalika Chaudhuri and Ruslan Salakhutdinov. Vol. 97. Proceedings of Machine Learning Research. PMLR, 2019, pp. 322–332
2019
-
[50]
Wide neural networks of any depth evolve as linear models under gradient descent
Jaehoon Lee et al. “Wide neural networks of any depth evolve as linear models under gradient descent”. In:Adv. Neural Inf. Process. Syst.32 (2019)
2019
-
[51]
Kernel and Rich Regimes in Overparametrized Models
Blake Woodworth et al. “Kernel and Rich Regimes in Overparametrized Models”. In:Proceedings of Thirty Third Conference on Learning Theory. Ed. by Jacob Abernethy and Shivani Agarwal. Vol. 125. Proceedings of Machine Learning Research. PMLR, 2020, pp. 3635–3673
2020
-
[52]
Disentangling feature and lazy training in deep neural networks
Mario Geiger et al. “Disentangling feature and lazy training in deep neural networks”. In:J. Stat. Mech: Theory Exp.2020.11 (Nov. 2020), p. 113301
2020
-
[53]
Geometric compression of invariant manifolds in neural nets
Jonas Paccolata et al. “Geometric compression of invariant manifolds in neural nets”. In:arXiv preprint arXiv:2007. 11471(2020)
2007
-
[54]
Toward a Unified Theory of Efficient, Predictive, and Sparse Coding
Matthew Chalk, Olivier Marre, and Gaˇ sper Tkaˇ cik. “Toward a Unified Theory of Efficient, Predictive, and Sparse Coding”. In:Proceedings of the National Academy of Sciences115.1 (Jan. 2018), pp. 186– 191.doi:10.1073/pnas.1711114115
-
[55]
Neuromodulated Spike-timing-Dependent Plasticity, and theory of three-factor learning rules
Nicolas Fr´ emaux and Wulfram Gerstner. “Neuromodulated Spike-timing-Dependent Plasticity, and theory of three-factor learning rules”. en. In:Front. Neural Circuits9 (2015), p. 85
2015
-
[56]
Synaptic plasticity forms and functions
Jeffrey C Magee and Christine Grienberger. “Synaptic plasticity forms and functions”. en. In:Annu. Rev. Neurosci.43.1 (July 2020), pp. 95–117
2020
-
[57]
Random Synaptic Feedback Weights Support Error Backpropagation for Deep Learning
Timothy P. Lillicrap et al. “Random Synaptic Feedback Weights Support Error Backpropagation for Deep Learning”. In:Nature Communications7.1 (Nov. 2016), p. 13276.doi: 10.1038/ncomms13276
-
[58]
Direct Feedback Alignment Provides Learning in Deep Neural Networks
Arild Nø kland. “Direct Feedback Alignment Provides Learning in Deep Neural Networks”. In: Advances in Neural Information Processing Systems. Vol. 29. Curran Associates, Inc., 2016. 17
2016
-
[59]
A mathematical theory of semantic development in deep neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. “A mathematical theory of semantic development in deep neural networks”. en. In:Proc. Natl. Acad. Sci. U. S. A.116.23 (June 2019), pp. 11537–11546
2019
-
[60]
https://arxiv.org/abs/2210.02157v2
Blake Bordelon and Cengiz Pehlevan.The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks. https://arxiv.org/abs/2210.02157v2. Oct. 2022
-
[61]
Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks
Pratik Chaudhari and Stefano Soatto. “Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks”. In:arXiv [cs.LG](Oct. 2017)
2017
-
[62]
Energy–entropy competition and the effectiveness of stochastic gradient descent in machine learning
Yao Zhang et al. “Energy–entropy competition and the effectiveness of stochastic gradient descent in machine learning”. en. In:Mol. Phys.116.21-22 (Nov. 2018), pp. 3214–3223
2018
-
[63]
Machine learning in and out of equilibrium
Shishir Adhikari et al. “Machine learning in and out of equilibrium”. In:arXiv [cs.LG](June 2023)
2023
-
[64]
Stochastic Gradient Descent as Approximate Bayesian Inference
Stephan Mandt, Matthew D. Hoffman, and David M. Blei.Stochastic Gradient Descent as Approxi- mate Bayesian Inference. Jan. 2018.doi:10.48550/arXiv.1704.04289
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1704.04289 2018
-
[65]
Bayesian learning and inference in recurrent switching linear dynamical systems
S Linderman, M Johnson, A Miller, et al. “Bayesian learning and inference in recurrent switching linear dynamical systems”. In:Artif. Intell.(2017)
2017
-
[66]
Diversity of emergent dynamics in competitive threshold-linear networks
Katherine Morrison et al. “Diversity of emergent dynamics in competitive threshold-linear networks”. en. In:SIAM J. Appl. Dyn. Syst.23.1 (Mar. 2024), pp. 855–884
2024
-
[67]
Mechanisms underlying gain modulation in the cortex
Katie A Ferguson and Jessica A Cardin. “Mechanisms underlying gain modulation in the cortex”. en. In:Nat. Rev. Neurosci.21.2 (Feb. 2020), pp. 80–92
2020
-
[68]
Gain modulation: a major computational principle of the central nervous system
E Salinas and P Thier. “Gain modulation: a major computational principle of the central nervous system”. en. In:Neuron27.1 (July 2000), pp. 15–21
2000
-
[69]
Motor primitives in space and time via targeted gain modulation in cortical networks
Jake P Stroud et al. “Motor primitives in space and time via targeted gain modulation in cortical networks”. en. In:Nat. Neurosci.21.12 (Dec. 2018), pp. 1774–1783
2018
-
[70]
Structured flexibility in recurrent neural networks via neuromodulation
Julia C Costacurta et al. “Structured flexibility in recurrent neural networks via neuromodulation”. In:bioRxiv37 (July 2024), pp. 1954–1972
2024
-
[71]
Thalamic control of cortical dynamics in a model of flexible motor sequencing
Laureline Logiaco, L F Abbott, and Sean Escola. “Thalamic control of cortical dynamics in a model of flexible motor sequencing”. en. In:Cell Rep.35.9 (June 2021), p. 109090
2021
-
[72]
Optimal anticipatory control as a theory of motor preparation: A thalamo-cortical circuit model
Ta-Chu Kao, Mahdieh S Sadabadi, and Guillaume Hennequin. “Optimal anticipatory control as a theory of motor preparation: A thalamo-cortical circuit model”. en. In:Neuron109.9 (May 2021), 1567–1581.e12
2021
-
[73]
Latent circuit inference from heterogeneous neural responses during cognitive tasks
Christopher Langdon and Tatiana A Engel. “Latent circuit inference from heterogeneous neural responses during cognitive tasks”. en. In:Nat. Neurosci.28.3 (Mar. 2025), pp. 665–675
2025
-
[74]
Linking Connectivity, Dynamics, and Computations in Low-Rank Recurrent Neural Networks
Francesca Mastrogiuseppe and Srdjan Ostojic. “Linking Connectivity, Dynamics, and Computations in Low-Rank Recurrent Neural Networks”. In:Neuron99.3 (Aug. 2018), 609–623.e29.doi: 10.1016/ j.neuron.2018.07.003
2018
-
[75]
Extracting computational mechanisms from neural activity with low-rank networks
Adrian Valente, Jonathan Pillow, and Srdjan Ostojic. “Extracting computational mechanisms from neural activity with low-rank networks”. In:Neur Inf Proc Sys35 (2022), pp. 24072–24086
2022
-
[76]
Early selection of task-relevant features through population gating
Joao Barbosa et al. “Early selection of task-relevant features through population gating”. en. In: Nat. Commun.14.1 (Oct. 2023), p. 6837
2023
-
[77]
Shaping Dynamics With Multiple Populations in Low-Rank Recurrent Networks
Manuel Beiran et al. “Shaping Dynamics With Multiple Populations in Low-Rank Recurrent Networks”. en. In:Neural Comput.33.6 (May 2021), pp. 1572–1615
2021
-
[78]
Lecture Notes
David Rosenberg and Julia Kempe.Lagrangian Duality and Convex Optimization. Lecture Notes. CDS, NYU, Feb. 2019.url: https://davidrosenberg.github.io/mlcourse/Archive/2019/ Lectures/04a.convex-optimization.pdf
2019
-
[79]
Cambridge New York Melbourne New Delhi Singapore: Cambridge University Press, 2023
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge New York Melbourne New Delhi Singapore: Cambridge University Press, 2023. 727 pp
2023
-
[80]
Sznitman,Topics in propagation of chaos, in École d’Été de Probabilités de Saint-Flour XIX—1989, vol
Alain-Sol Sznitman. “Topics in Propagation of Chaos”. In:Ecole d’Et´ e de Probabilit´ es de Saint-Flour XIX — 1989. Vol. 1464. Berlin, Heidelberg: Springer Berlin Heidelberg, 1991, pp. 165–251.doi: 10.1007/BFb0085169. 18 A Maximum Entropy calculation A.1 Recap on Convex optimization We start with a general summary of the convex optimization approach that ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.