Towards the Connection between Activation Sparsity and Flat Minima
Pith reviewed 2026-06-29 23:07 UTC · model grok-4.3
The pith
Activation sparsity in MLPs equals augmented flatness divided by input norm times activation gradient, and the ratio decreases during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
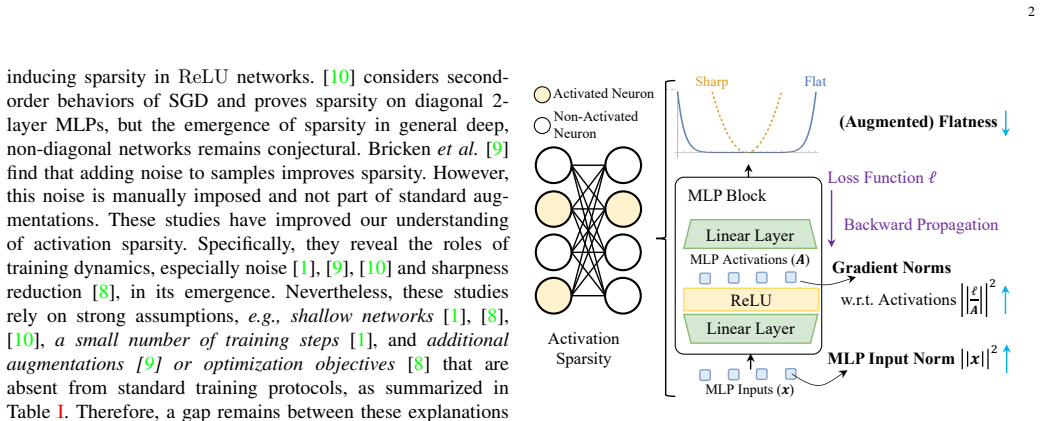
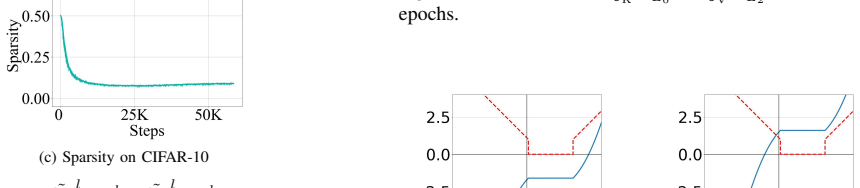
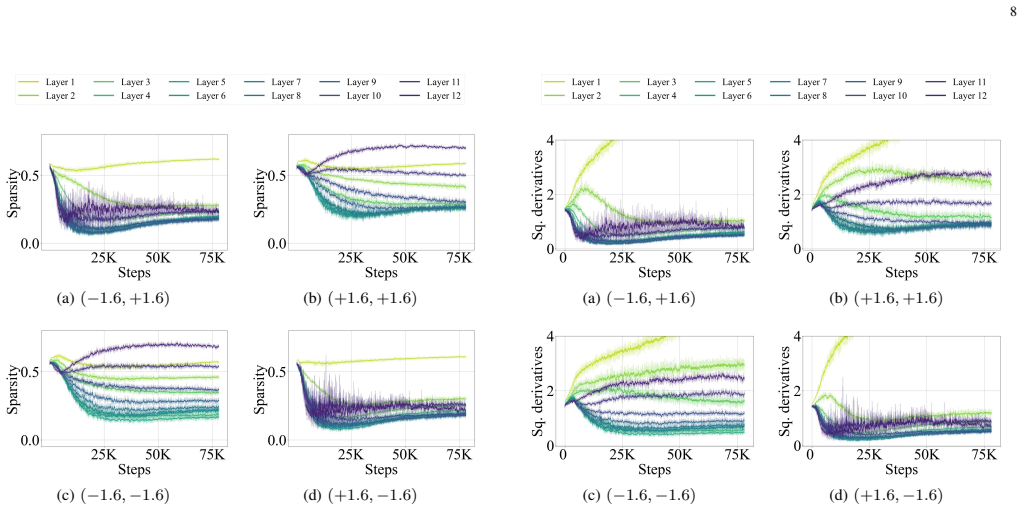
We find that the MLP activation sparsity equals a ratio between augmented flatness, which is a weighted sum of flatness measures, and the product of the input norm and activation gradient of the MLP. We empirically find that this ratio decreases during training, leading to sparse activations. We also propose the notion of derivative sparsity, which reduces to activation sparsity under ReLU, but further enables pruning in the backward propagation and is more stable than activation sparsity.
What carries the argument
The ratio of augmented flatness to the product of input norm and activation gradient
If this is right
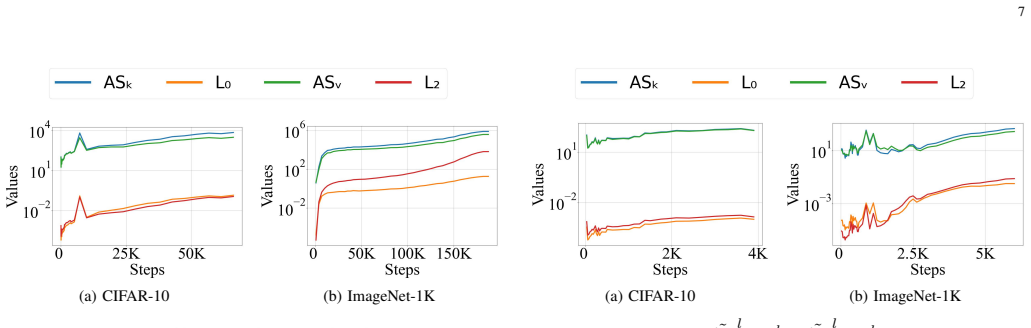
- Activation sparsity emerges as the ratio decreases over training steps.
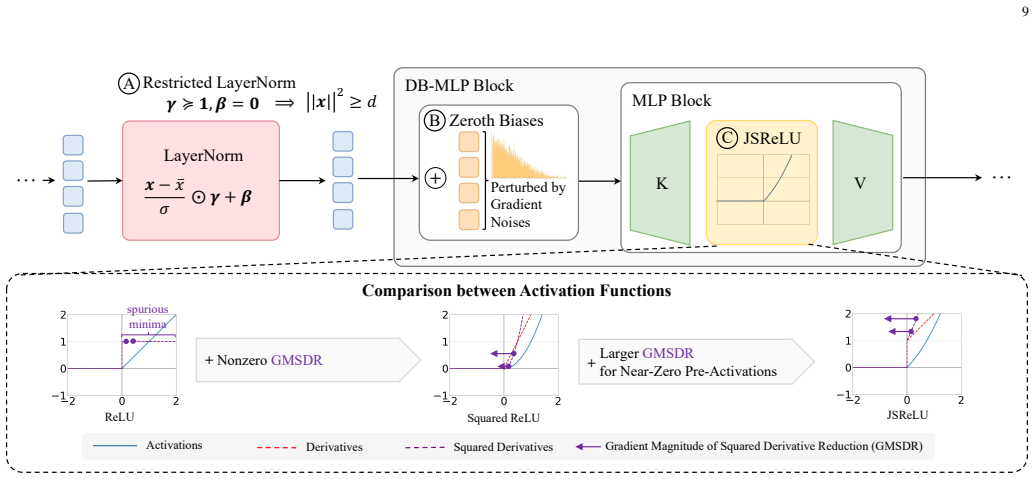
- Three plug-and-play modifications can decrease the ratio and increase sparsity levels.
- Derivative sparsity matches activation sparsity for ReLU activations while supporting backward pass pruning.
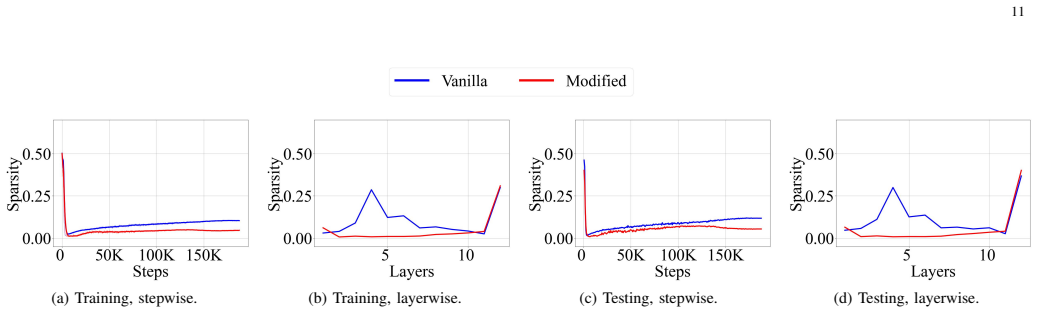
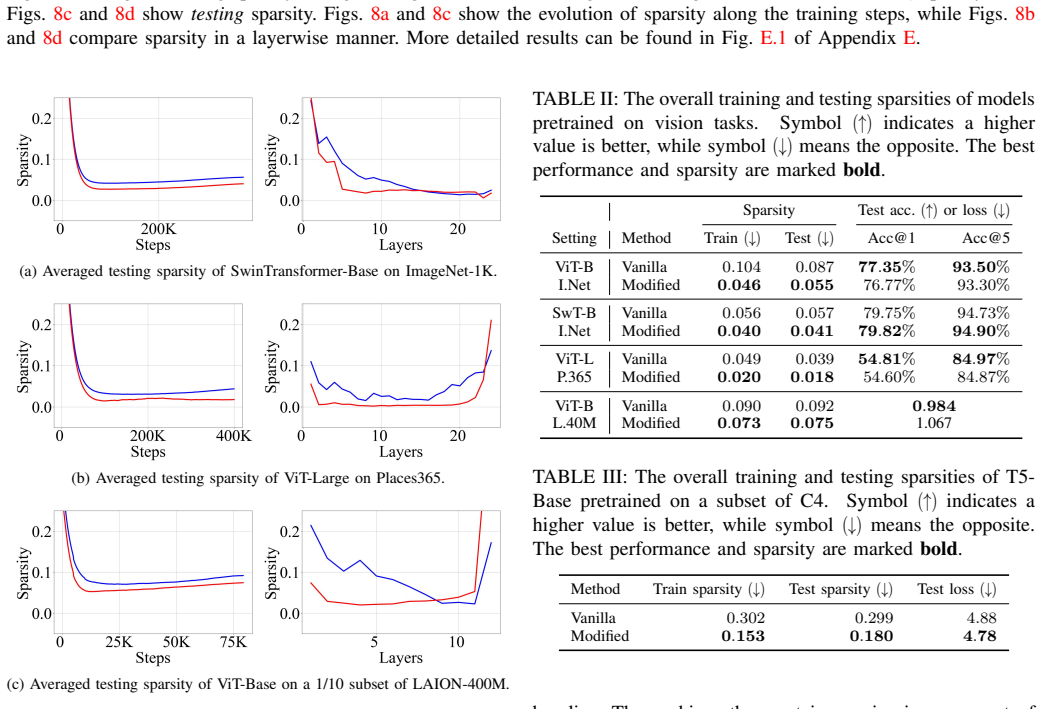
- These modifications achieve at least 36 percent relative improvement in inference sparsity and 50 percent in training sparsity on ImageNet-1K and C4.
Where Pith is reading between the lines
- Similar connections between flatness and sparsity could be explored in other layer types or activation functions.
- Optimizing for flat minima might indirectly promote sparsity as a side effect in deep networks.
- Tracking the ratio could provide a signal for when to apply pruning during the training process.
Load-bearing premise
The flatness of loss landscapes is closely related to MLP activation sparsity and can serve as a naturally emerging assumption for standard deep networks.
What would settle it
If the ratio of augmented flatness to input norm times activation gradient fails to decrease while measured activation sparsity increases over training, the proposed equality would not hold.
Figures
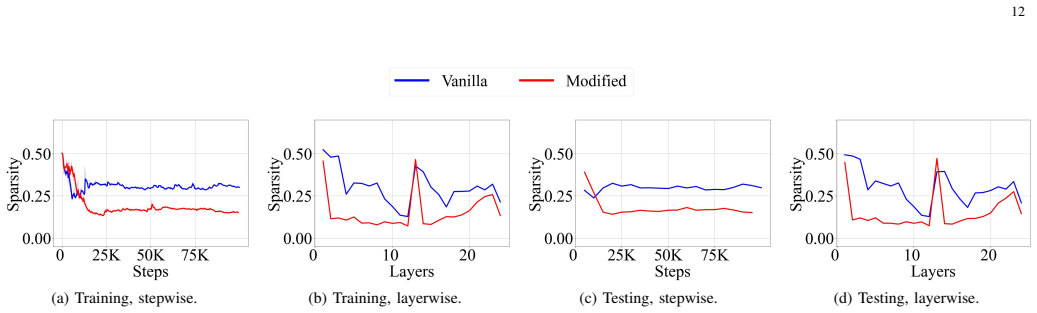
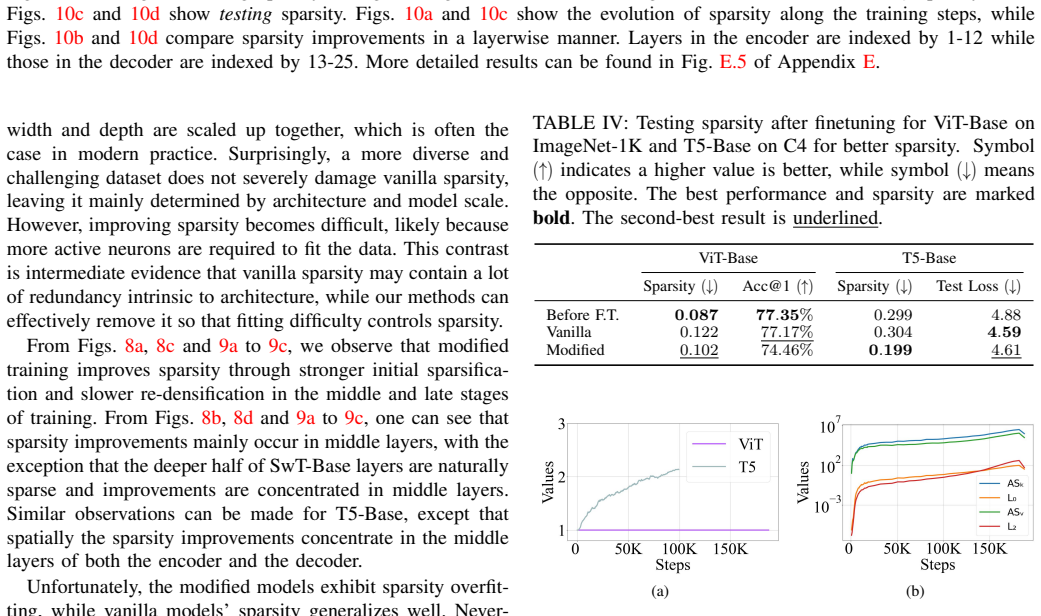
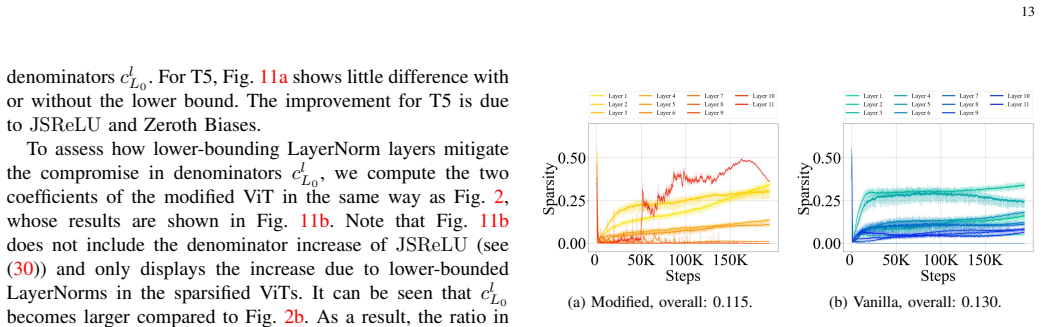
read the original abstract
The observation that activation sparsity emerges in MLP blocks of standardly trained Transformers offers an opportunity to drastically reduce computation costs without sacrificing performance. To theoretically explain this phenomenon, existing works have shown that activation sparsity does not result from the data properties or data fitting but from the implicit bias of the training process. However, these connections are obtained with strong assumptions, which cannot be applied to deep models standardly trained with a large number of steps. Different from these works, we find that the flatness of loss landscapes is also closely related to the MLP activation sparsity and can serve as a weaker and naturally emerging assumption standard deep networks. Specifically, we find that 1) the MLP activation sparsity equals a ratio between "augmented flatness" (a weighted sum of flatness measures) and the product of the input norm and activation gradient of the MLP. We empirically find that this ratio decreases during training, leading to sparse activations. 2) We also propose the notion of derivative sparsity, which reduces to activation sparsity under ReLU, but further enables pruning in the backward propagation and is more stable than activation sparsity. With the theoretical findings, we can further encourage activation sparsity by decreasing the numerator and increasing the denominator of the ratio using three methods. These plug-and-play modifications can effectively reduce the ratio and produce sparser activations. Experiments on ImageNet-1K and C4 demonstrate relative improvements of at least 36% on inference sparsity and at least 50% on training sparsity over vanilla Transformers, indicating further potential cost reduction in both inference and training
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that activation sparsity in MLP blocks of standardly trained Transformers equals a ratio of 'augmented flatness' (a weighted sum of flatness measures) to the product of input norm and activation gradient. It reports an empirical decrease in this ratio during training that produces sparse activations, introduces 'derivative sparsity' (which reduces to activation sparsity under ReLU and enables backward pruning), and proposes three plug-and-play modifications to decrease the numerator or increase the denominator of the ratio. Experiments on ImageNet-1K and C4 report relative gains of at least 36% inference sparsity and 50% training sparsity over vanilla Transformers.
Significance. If the equality is a valid identity or local approximation and the empirical decrease is reproducible, the work supplies a weaker, naturally emerging assumption (flatness) than prior strong assumptions used to explain implicit bias toward sparsity. The derivative-sparsity notion and the three ratio-modification methods are practical contributions that could reduce both training and inference costs in large models.
major comments (2)
- [Abstract and § on theoretical findings] Abstract and theoretical derivation section: the central equality (activation sparsity = augmented flatness / (||input|| * activation gradient)) is stated without derivation steps, explicit assumptions, or error bounds. Because this identity is load-bearing for replacing prior strong assumptions with flatness, the full derivation (including whether it is an exact identity or a local expansion) must be supplied with verifiable conditions.
- [Abstract and empirical analysis section] Empirical findings on ratio decrease: the manuscript reports that the ratio decreases during training but supplies no derivation connecting this decrease to gradient descent dynamics or the flatness assumption itself. This step is load-bearing for the explanatory claim that flatness provides a weaker account of the implicit bias; without a dynamics argument the decrease remains an observed correlation rather than a consequence.
minor comments (2)
- [Abstract] The abstract mentions three methods for encouraging sparsity but does not name them; a one-sentence enumeration would improve clarity.
- [Throughout] Notation for 'augmented flatness' and 'derivative sparsity' should be introduced with a forward reference to their defining equations on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical sections. The comments highlight important areas for improving rigor and clarity. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and § on theoretical findings] Abstract and theoretical derivation section: the central equality (activation sparsity = augmented flatness / (||input|| * activation gradient)) is stated without derivation steps, explicit assumptions, or error bounds. Because this identity is load-bearing for replacing prior strong assumptions with flatness, the full derivation (including whether it is an exact identity or a local expansion) must be supplied with verifiable conditions.
Authors: We agree that the central equality requires an explicit derivation to support the claim that flatness provides a weaker assumption. In the revised manuscript we will add a dedicated derivation subsection that presents the step-by-step reasoning, states all assumptions (including activation-function properties and the precise definition of augmented flatness), and indicates whether the relation is an exact identity or a local approximation together with any error bounds. This addition will make the theoretical foundation verifiable. revision: yes
-
Referee: [Abstract and empirical analysis section] Empirical findings on ratio decrease: the manuscript reports that the ratio decreases during training but supplies no derivation connecting this decrease to gradient descent dynamics or the flatness assumption itself. This step is load-bearing for the explanatory claim that flatness provides a weaker account of the implicit bias; without a dynamics argument the decrease remains an observed correlation rather than a consequence.
Authors: The manuscript presents the decrease of the ratio as an empirical observation that holds consistently across the reported training runs. We do not supply a dynamical derivation showing that gradient descent necessarily reduces the ratio under the flatness assumption; the flatness perspective is offered as a static explanatory lens rather than a complete dynamical account. In revision we will explicitly label the decrease as an empirical finding, avoid implying a proven dynamical consequence, and add a short discussion noting the absence of a dynamics argument as an open question for future work. revision: partial
Circularity Check
No significant circularity; equality is a derived identity and ratio trend is empirical
full rationale
The paper presents an equality relating MLP activation sparsity to a ratio of augmented flatness over (input norm × activation gradient). This is framed as a mathematical finding (likely from local expansion around the loss), not a self-definition where one quantity is defined in terms of the other. The subsequent claim that the ratio decreases during training (producing sparsity) is explicitly empirical observation, not a derived prediction or fitted input. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are load-bearing for the central result. The derivation remains self-contained against external flatness measures and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption flatness of loss landscapes is closely related to MLP activation sparsity and serves as a weaker naturally emerging assumption for standard deep networks
invented entities (2)
-
augmented flatness
no independent evidence
-
derivative sparsity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The lazy neuron phenomenon: On emergence of activation sparsity in transformers,
Z. Li, C. You, S. Bhojanapalli, D. Li, A. S. Rawat, S. J. Reddi, K. Ye, F. Chern, F. Yu, R. Guo, and S. Kumar, “The lazy neuron phenomenon: On emergence of activation sparsity in transformers,” inThe Eleventh International Conference on Learning Representations, 2023. 1, 2, 3, 4, 7, 8, 10, 11, 25
2023
-
[2]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research, vol. 21, no. 140, pp. 1–67, 2020. 1, 3, 10
2020
-
[3]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2020. 1, 7, 10
2020
-
[4]
Mlp-mixer: An all-mlp architecture for vision,
I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Un- terthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreitet al., “Mlp-mixer: An all-mlp architecture for vision,”Advances in neural information processing systems, vol. 34, pp. 24 261–24 272, 2021. 1
2021
-
[5]
ReLU strikes back: Ex- ploiting activation sparsity in large language models,
S. I. Mirzadeh, K. Alizadeh-Vahid, S. Mehta, C. C. del Mundo, O. Tuzel, G. Samei, M. Rastegari, and M. Farajtabar, “ReLU strikes back: Ex- ploiting activation sparsity in large language models,” inThe Twelfth International Conference on Learning Representations, 2024. 1, 4
2024
-
[6]
Deja vu: Contextual sparsity for efficient llms at inference time,
Z. Liu, J. Wang, T. Dao, T. Zhou, B. Yuan, Z. Song, A. Shrivastava, C. Zhang, Y . Tian, C. Reet al., “Deja vu: Contextual sparsity for efficient llms at inference time,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 22 137–22 176. 1
2023
-
[7]
Training-free activation sparsity in large language models,
J. Liu, P. Ponnusamy, T. Cai, H. Guo, Y . Kim, and B. Athiwaratkun, “Training-free activation sparsity in large language models,” inThe Thirteenth International Conference on Learning Representations, 2025. 1
2025
-
[8]
Sharpness-aware minimization leads to low-rank features,
M. Andriushchenko, D. Bahri, H. Mobahi, and N. Flammarion, “Sharpness-aware minimization leads to low-rank features,” inThirty- seventh Conference on Neural Information Processing Systems, 2023. 1, 2, 3, 4, 8
2023
-
[9]
Emergence of sparse representations from noise,
T. Bricken, R. Schaeffer, B. Olshausen, and G. Kreiman, “Emergence of sparse representations from noise,” inProceedings of the 40th International Conference on Machine Learning. PMLR, 06 2023, pp. 3148–3191. 1, 2, 3
2023
-
[10]
SGD with large step sizes learns sparse features,
M. Andriushchenko, A. V . Varre, L. Pillaud-Vivien, and N. Flammarion, “SGD with large step sizes learns sparse features,” inProceedings of the 40th International Conference on Machine Learning. PMLR, 07 2023, pp. 903–925, ISSN: 2640-3498. 1, 2, 3
2023
-
[11]
Sharpness-aware minimization for efficiently improving generalization,
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur, “Sharpness-aware minimization for efficiently improving generalization,” inInternational Conference on Learning Representations, 2020. 1, 2
2020
-
[12]
How sharpness-aware minimization minimizes sharpness?
K. Wen, T. Ma, and Z. Li, “How sharpness-aware minimization minimizes sharpness?” inThe Eleventh International Conference on Learning Representations, 2023. 1
2023
-
[13]
On large-batch training for deep learning: Generalization gap and sharp minima,
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang, “On large-batch training for deep learning: Generalization gap and sharp minima,” inInternational Conference on Learning Represen- tations, 2016. 2
2016
-
[14]
A tail-index analysis of stochastic gradient noise in deep neural networks,
U. Simsekli, L. Sagun, and M. Gurbuzbalaban, “A tail-index analysis of stochastic gradient noise in deep neural networks,” inProceedings of the 36th International Conference on Machine Learning. PMLR, 05 2019, pp. 5827–5837, ISSN: 2640-3498. 2, 9
2019
-
[15]
Towards theoretically understanding why sgd generalizes better than adam in deep learning,
P. Zhou, J. Feng, C. Ma, C. Xiong, S. C. H. Hoi, and W. E, “Towards theoretically understanding why sgd generalizes better than adam in deep learning,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 21 285–21 296. 2, 9
2020
-
[16]
The alignment property of sgd noise and how it helps select flat minima: A stability analysis,
L. Wu, M. Wang, and W. Su, “The alignment property of sgd noise and how it helps select flat minima: A stability analysis,”Advances in Neural Information Processing Systems, vol. 35, pp. 4680–4693, 2022. 2, 9, 13
2022
-
[17]
Averaging weights leads to wider optima and better generalization,
P. Izmailov, A. Wilson, D. Podoprikhin, D. Vetrov, and T. Garipov, “Averaging weights leads to wider optima and better generalization,” in34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, 2018, pp. 876–885. 2
2018
-
[18]
Fan- tastic generalization measures and where to find them,
Y . Jiang, B. Neyshabur, H. Mobahi, D. Krishnan, and S. Bengio, “Fan- tastic generalization measures and where to find them,” inInternational Conference on Learning Representations, 2019. 2
2019
-
[19]
Sharpness-aware lookahead for accelerating convergence and improving generalization,
C. Tan, J. Zhang, J. Liu, and Y . Gong, “Sharpness-aware lookahead for accelerating convergence and improving generalization,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 375–10 388, 2024. 2
2024
-
[20]
Emergence of invariance and disentanglement in deep representations,
A. Achille and S. Soatto, “Emergence of invariance and disentanglement in deep representations,”Journal of Machine Learning Research, vol. 19, no. 50, pp. 1–34, 2018. 2, 5
2018
-
[21]
Anticor- related noise injection for improved generalization,
A. Orvieto, H. Kersting, F. Proske, F. Bach, and A. Lucchi, “Anticor- related noise injection for improved generalization,” inProceedings of the 39th International Conference on Machine Learning. PMLR, 06 2022, pp. 17 094–17 116, ISSN: 2640-3498. 2, 5
2022
-
[22]
Swad: Domain generalization by seeking flat minima,
J. Cha, S. Chun, K. Lee, H.-C. Cho, S. Park, Y . Lee, and S. Park, “Swad: Domain generalization by seeking flat minima,”Advances in Neural Information Processing Systems, vol. 34, pp. 22 405–22 418, 2021. 2
2021
-
[23]
Gradient norm aware minimization seeks first-order flatness and improves generalization,
X. Zhang, R. Xu, H. Yu, H. Zou, and P. Cui, “Gradient norm aware minimization seeks first-order flatness and improves generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 20 247–20 257. 2
2023
-
[24]
Flatness- aware minimization for domain generalization,
X. Zhang, R. Xu, H. Yu, Y . Dong, P. Tian, and P. Cui, “Flatness- aware minimization for domain generalization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5189–5202. 2
2023
-
[25]
Relative flatness and generalization,
H. Petzka, M. Kamp, L. Adilova, C. Sminchisescu, and M. Boley, “Relative flatness and generalization,” inAdvances in neural information processing systems, vol. 34, 2021, pp. 18 420–18 432. 2, 9
2021
-
[26]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255. 3, 7, 10
2009
-
[27]
Transformer feed-forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed-forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 5484–5495. 3, 4
2021
-
[28]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2022, pp. 8493–8502. 3, 4
2022
-
[29]
On the adversarial robustness of mixture of experts,
J. Puigcerver, R. Jenatton, C. Riquelme, P. Awasthi, and S. Bhojanapalli, “On the adversarial robustness of mixture of experts,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 9660–9671. 3
2022
-
[30]
Inducing and ex- ploiting activation sparsity for fast inference on deep neural networks,
M. Kurtz, J. Kopinsky, R. Gelashvili, A. Matveev, J. Carr, M. Goin, W. Leiserson, S. Moore, N. Shavit, and D. Alistarh, “Inducing and ex- ploiting activation sparsity for fast inference on deep neural networks,” in Proceedings of the 37th International Conference on Machine Learning. PMLR, 11 2020, pp. 5533–5543, ISSN: 2640-3498. 3, 4
2020
-
[31]
Non-negative matrix factorization with sparseness con- straints
P. O. Hoyer, “Non-negative matrix factorization with sparseness con- straints.”Journal of machine learning research, vol. 5, no. 9, 2004. 3
2004
-
[32]
Accelerating convolutional neural networks via activa- tion map compression,
G. Georgiadis, “Accelerating convolutional neural networks via activa- tion map compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7085–7095. 4
2019
-
[33]
Adaptively sparse transformers,
G. M. Correia, V . Niculae, and A. F. T. Martins, “Adaptively sparse transformers,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, 11 2019, pp. 2174–2184. 4 15
2019
-
[34]
SwinBERT: End-to-end transformers with sparse attention for video captioning,
K. Lin, L. Li, C.-C. Lin, F. Ahmed, Z. Gan, Z. Liu, Y . Lu, and L. Wang, “SwinBERT: End-to-end transformers with sparse attention for video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 949–17 958. 4
2022
-
[35]
Where we have arrived in proving the emergence of sparse symbolic concepts in AI models,
Q. Ren, J. Gao, W. Shen, and Q. Zhang, “Where we have arrived in proving the emergence of sparse symbolic concepts in AI models,” 05
-
[36]
Available: http://arxiv.org/abs/2305.01939 4
[Online]. Available: http://arxiv.org/abs/2305.01939 4
-
[37]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009. 7, 8
2009
-
[38]
Searching for efficient transformers for language modeling,
D. So, W. Ma ´nke, H. Liu, Z. Dai, N. Shazeer, and Q. V . Le, “Searching for efficient transformers for language modeling,” inAdvances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 6010–6022. 10
2021
-
[39]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022. 10
2021
-
[40]
Places: A 10 million image database for scene recognition,
B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. 10
2017
-
[41]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, “Laion-400M: Open dataset of clip-filtered 400 million image-text pairs,”arXiv preprint arXiv:2111.02114, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763. 10, 24, 25
2021
-
[43]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. 12
2022
-
[44]
Gradient descent aligns the layers of deep linear networks,
Z. Ji and M. Telgarsky, “Gradient descent aligns the layers of deep linear networks,” in7th International Conference on Learning Representations, ICLR 2019, 2019. 13
2019
-
[45]
Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction,
D. St ¨oger and M. Soltanolkotabi, “Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction,”Advances in Neural Information Processing Systems, vol. 34, pp. 23 831–23 843, 2021. 13
2021
-
[46]
Implicit balancing and regularization: Generalization and convergence guarantees for overpa- rameterized asymmetric matrix sensing,
M. Soltanolkotabi, D. St ¨oger, and C. Xie, “Implicit balancing and regularization: Generalization and convergence guarantees for overpa- rameterized asymmetric matrix sensing,” inThe Thirty Sixth Annual Conference on Learning Theory. PMLR, 2023, pp. 5140–5142. 13
2023
-
[47]
From lazy to rich: Exact learning dynamics in deep linear networks,
C. C. J. Domin ´e, N. Anguita, A. M. Proca, L. Braun, D. Kunin, P. A. Mediano, and A. M. Saxe, “From lazy to rich: Exact learning dynamics in deep linear networks,” inThe Thirteenth International Conference on Learning Representations, 2025. 13
2025
-
[48]
Unique properties of flat minima in deep networks,
R. Mulayoff and T. Michaeli, “Unique properties of flat minima in deep networks,” inInternational conference on machine learning. PMLR, 2020, pp. 7108–7118. 13
2020
-
[49]
Power-law escape rate of SGD,
T. Mori, L. Ziyin, K. Liu, and M. Ueda, “Power-law escape rate of SGD,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 15 959–15 975. 13
2022
-
[50]
Information-theoretic analysis of gener- alization capability of learning algorithms,
A. Xu and M. Raginsky, “Information-theoretic analysis of gener- alization capability of learning algorithms,” inAdvances in Neural Information Processing Systems, vol. 30, 2017. 13, 27
2017
-
[51]
User-friendly introduction to pac-bayes bounds.arXiv preprint arXiv:2110.11216,
P. Alquier, “User-friendly introduction to PAC-Bayes bounds,” 2023. [Online]. Available: http://arxiv.org/abs/2110.11216 13
-
[52]
Reasoning about generalization via conditional mutual information,
T. Steinke and L. Zakynthinou, “Reasoning about generalization via conditional mutual information,” 2020. [Online]. Available: https://arxiv.org/abs/2001.09122 13
-
[53]
Chaining mutual information and tightening generalization bounds,
A. Asadi, E. Abbe, and S. Verdu, “Chaining mutual information and tightening generalization bounds,” inAdvances in Neural Information Processing Systems, vol. 31, 2018. 13
2018
-
[54]
Con- ditioning and processing: Techniques to improve information-theoretic generalization bounds,
H. Hafez-Kolahi, Z. Golgooni, S. Kasaei, and M. Soleymani, “Con- ditioning and processing: Techniques to improve information-theoretic generalization bounds,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 16 457–16 467. 13
2020
-
[55]
Tighter information-theoretic generalization bounds from supersamples,
Z. Wang and Y . Mao, “Tighter information-theoretic generalization bounds from supersamples,” inProceedings of the 40th International Conference on Machine Learning. PMLR, 2023, pp. 36 111–36 137. 13, 27
2023
-
[56]
Lever- aging flatness to improve information-theoretic generalization bounds for SGD,
Z. Peng, J. Zhang, Y . Wang, L. Qi, Y . Shi, and Y . Gao, “Lever- aging flatness to improve information-theoretic generalization bounds for SGD,” inThe Thirteenth International Conference on Learning Representations, 2025. 13, 27
2025
-
[57]
(2023) vision/references/classification at main · pytorch/vision
PyTorch. (2023) vision/references/classification at main · pytorch/vision. [Online]. Available: https://github.com/pytorch/vision/ tree/main/references/classification 25
2023
-
[58]
X l ⊤ ∂ℓ(Fθ ,s) ∂Al ⊙D l 2 F # ,AF θl V =E s∼U{D}
Huggingface. (2023) T5-like span-masked language modeling. [Online]. Available: https://github.com/huggingface/transformers/tree/ main/examples/flax/language-modeling 25 16 APPENDIXA RESULTS FORARCHITECTURES WITHSKIPCONNECTIONS In the main part of the paper, we list theoretical results for networks defined by (2), where networks can have MLP blocks inMLP ...
2023
-
[59]
˜F(y| ˜θ′ l,K ,x)− ˜F(y| ˜θ,x) F(y|θ,x) # = tr E
Plugging this coincidence obtains the first chaining of the equalities. Furthermore, whenX l = x⊤ is LayerNorm-ed, letU l = u⊤ be the input of that application of LayerNorm, then x=γ⊙ u−¯u1dq 1 d ∥u−¯u1d∥2 2 +ϵ LayerNorm +β,(B.39) where¯u= 1 d Pd i=1 ui,γandβare affine parameters. By assumption that affine parameters andϵ LayerNorm are turned off,i.e., γ=...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.