Beyond Literal Translation: Evaluating Cultural Effectiveness in Social Media UGC
Pith reviewed 2026-06-29 21:24 UTC · model grok-4.3
The pith
Traditional metrics fail to capture cultural effectiveness in social media UGC translations, which rises with base model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
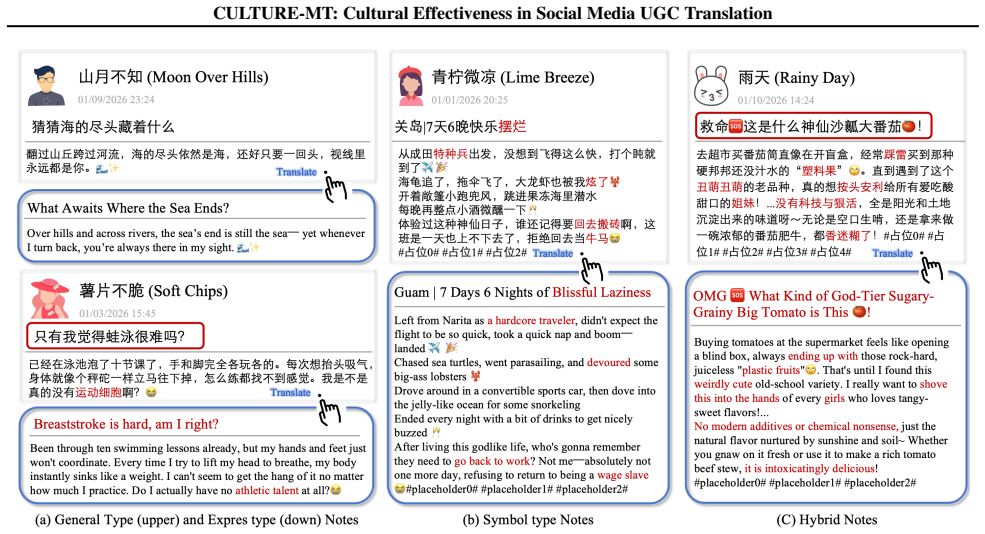
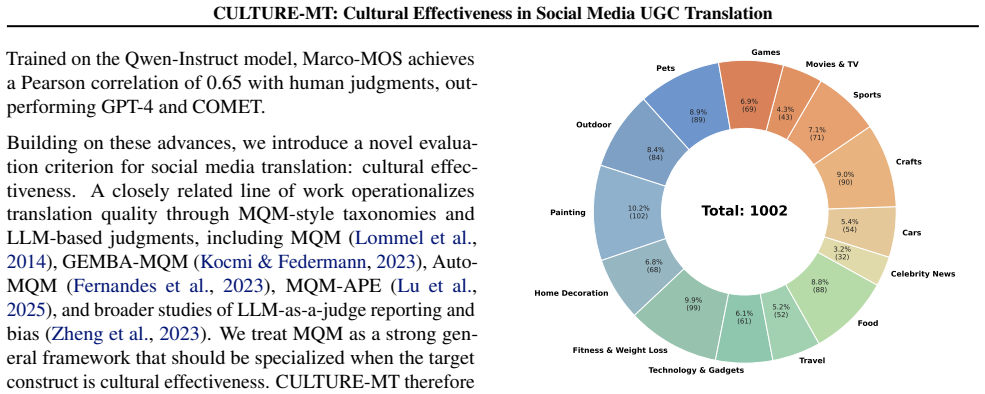
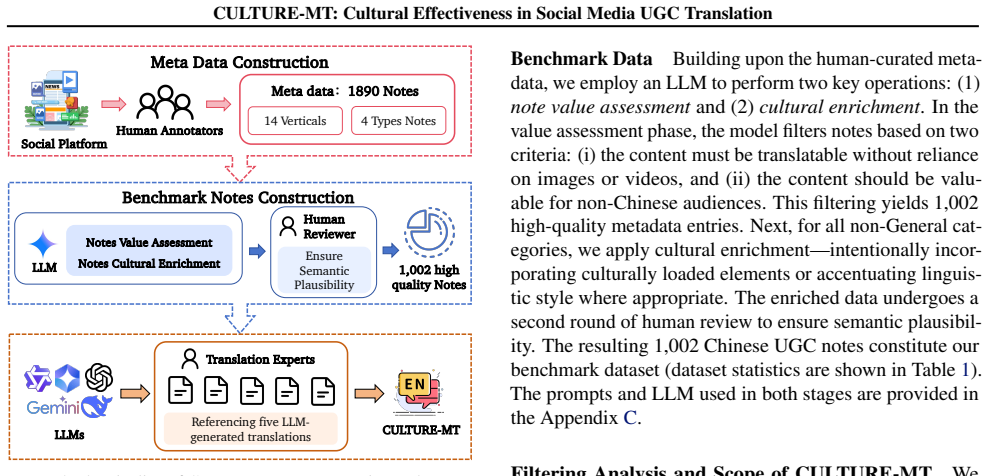
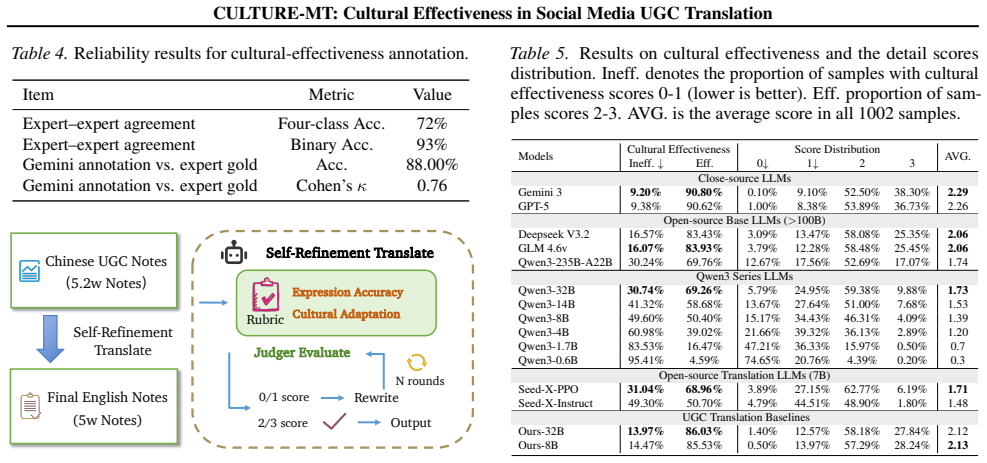
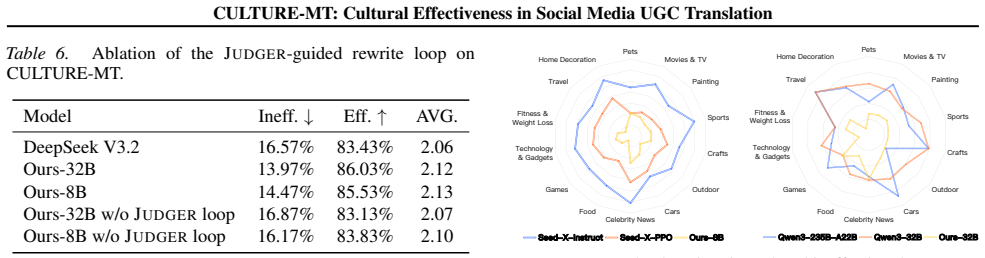
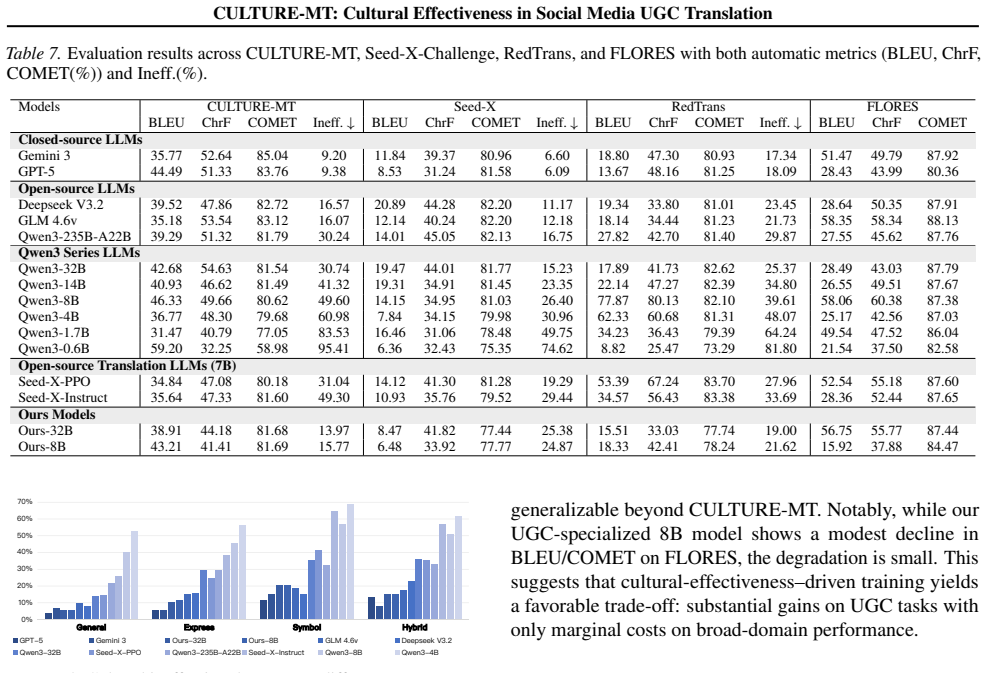
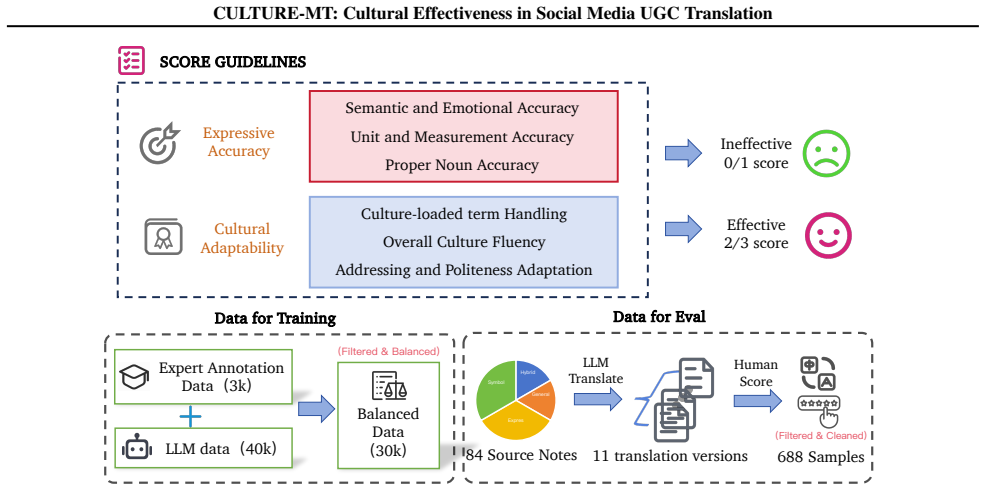
The authors construct CULTURE-MT with UGC notes grouped into four categories by culture-loaded symbols and linguistic style features, then train Qwen3 models on UGC-oriented data to serve as baselines. Testing 15 models reveals that traditional metrics do not align with cultural effectiveness scores produced by the JUDGER, and that cultural effectiveness on base LLMs increases with model size.
What carries the argument
The CULTURE-MT benchmark and its trained JUDGER, which scores translations on the four-type categorization of culture-loaded symbols and linguistic features for cultural effectiveness.
If this is right
- Standard metrics cannot be relied upon alone when judging translations of informal social media content.
- Cultural effectiveness forms a separate evaluation axis that better matches real-world requirements.
- Base large language models exhibit improving cultural effectiveness as their size grows.
- Fine-tuned UGC-oriented models provide usable baselines for further refinement of translation systems.
- An open leaderboard using the JUDGER enables ongoing community comparison of new models on this criterion.
Where Pith is reading between the lines
- Model scaling alone may narrow the gap in handling cultural references without additional task-specific training.
- The same four-category approach could be tested on other informal text types such as forum posts or chat logs.
- Translation pipelines might benefit from early filtering of training data to emphasize informal cultural markers.
Load-bearing premise
The four-type categorization of culture-loaded symbols and linguistic features together with the JUDGER judgments accurately reflect real cultural transmission and emotion resonance in actual UGC translations.
What would settle it
A human evaluation study in which native speakers from the target cultures rate the same set of translations for cultural resonance and the ratings diverge from the JUDGER scores while aligning with traditional metrics.
Figures







read the original abstract
Social media platforms enable large-scale cross-lingual communication, but translating user-generated content (UGC) remains challenging due to its informal style, cultural references, and interaction-based expressions. While recent LLMs have improved translation quality, existing benchmarks and metrics often fail to capture whether translations convey intended meaning and cultural resonance in real-world settings. In this work, we introduce CULTURE-MT, a benchmark for social media translation that focuses on both CULtural Transmission and UGC-specific emotion REsonance. CULTURE-MT consists of 1,002 UGC notes across 14 domains, categorized into four types based on culture-loaded symbols and linguistic style features. We also construct UGC-oriented training data to fine-tune Qwen3-8B and Qwen3-32B as baselines. We propose cultural effectiveness as a new evaluation criterion, focusing on expression accuracy and cultural adaptability. Testing 15 models, including the baselines, we find that traditional metrics fail to capture cultural effectiveness. We also observe that cultural effectiveness on base LLMs correlates with model size. Our work provides a comprehensive evaluation system for UGC translation models and will offer an open evaluation platform to advance research in this area. We release the CULTURE-MT benchmark and provide an online leaderboard where submitted translation results can be evaluated by our trained JUDGER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CULTURE-MT, a benchmark of 1,002 social-media UGC notes across 14 domains, partitioned into four types according to culture-loaded symbols and linguistic-style features. The authors construct UGC-oriented training data, fine-tune Qwen3-8B and Qwen3-32B as baselines, define a cultural-effectiveness criterion (expression accuracy plus cultural adaptability) scored by a fine-tuned JUDGER, evaluate 15 models, and report that conventional metrics fail to track cultural effectiveness while the latter correlates with model size on base LLMs. The benchmark and an online JUDGER leaderboard are released.
Significance. If the four-type taxonomy and JUDGER prove reliable proxies, the work supplies a needed evaluation framework for the cultural and affective dimensions of UGC translation that literal metrics miss. The explicit release of the benchmark together with a public leaderboard is a concrete, reusable contribution that lowers the barrier for subsequent research.
major comments (2)
- [JUDGER training and evaluation procedure (methods/results sections describing JUDGER fine-tuning and scoring)] The central claims—that traditional metrics fail to capture cultural effectiveness and that effectiveness correlates with model size—rest on the JUDGER’s validity as a proxy for real-world cultural transmission and emotion resonance. The manuscript provides no inter-annotator agreement figures for the 1,002-note annotation, no held-out human correlation study, and no external validation against actual social-media reception data. This absence is load-bearing for both headline results.
- [Benchmark construction and categorization (section defining the four types)] The four-type categorization of culture-loaded symbols and linguistic features is introduced without an explicit argument for exhaustiveness, without comparison to alternative taxonomies, and without ablation showing that the chosen partition drives the reported metric differences. Because the benchmark construction and all downstream claims depend on this taxonomy, its justification is required.
minor comments (2)
- [Evaluation setup] The abstract states that 15 models were tested but does not list them or indicate whether the fine-tuned Qwen3 models are included in that count; a table enumerating all evaluated systems and their parameter counts would improve clarity.
- [Conclusion and release statement] The paper promises an open leaderboard but does not specify the submission format, evaluation latency, or licensing terms for the released data; these details belong in the final section or an appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validity of our JUDGER and the justification for the four-type taxonomy in CULTURE-MT. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: The central claims—that traditional metrics fail to capture cultural effectiveness and that effectiveness correlates with model size—rest on the JUDGER’s validity as a proxy for real-world cultural transmission and emotion resonance. The manuscript provides no inter-annotator agreement figures for the 1,002-note annotation, no held-out human correlation study, and no external validation against actual social-media reception data. This absence is load-bearing for both headline results.
Authors: We agree that stronger validation evidence would bolster the JUDGER's role as a proxy. The 1,002 notes were annotated by three experts in linguistics and cultural studies using a detailed protocol; we will add inter-annotator agreement metrics (Fleiss' kappa) to the methods section in revision. We will also include a held-out human correlation analysis comparing JUDGER scores to independent human ratings of cultural effectiveness on a subset of translations. External validation against real-world social-media reception data (e.g., engagement metrics) cannot be performed here due to platform data access restrictions and is noted as a limitation; the public benchmark release is intended to support such extensions by the community. revision: partial
-
Referee: The four-type categorization of culture-loaded symbols and linguistic features is introduced without an explicit argument for exhaustiveness, without comparison to alternative taxonomies, and without ablation showing that the chosen partition drives the reported metric differences. Because the benchmark construction and all downstream claims depend on this taxonomy, its justification is required.
Authors: The taxonomy combines culture-loaded symbols with UGC-specific linguistic features and draws from established translation studies frameworks (e.g., Newmark's culture-specific categories adapted to informal digital contexts). In the revision we will add an explicit justification subsection, reference alternative taxonomies (such as purely semantic or pragmatic partitions), and include an ablation experiment quantifying how the four-type split influences the divergence between traditional metrics and cultural-effectiveness scores. revision: yes
- External validation of JUDGER scores against actual social-media reception/engagement data, which requires proprietary platform metrics unavailable for this study.
Circularity Check
No significant circularity
full rationale
The paper introduces CULTURE-MT benchmark, four-type taxonomy, UGC training data, fine-tuned JUDGER, and cultural effectiveness metric as new contributions. It reports empirical results on 15 models (traditional metrics fail; effectiveness correlates with size) without equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction. The derivation chain consists of independent data collection, model testing, and observation rather than self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://blog.google/products/gemini/ gemini-3, 2025. Accessed: 2026-01-24. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. Guo, H., Wang, Y ., Cao, S., Zhao, F., Wang, B., Li, L., Chen, L., Lyu, X., Xu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
URL https: //aclanthology.org/2025.acl-long.632/
doi: 10.18653/v1/2025.acl-long.632. URL https: //aclanthology.org/2025.acl-long.632/. Jin, Y ., Choi, M., Verma, G., Wang, J., and Kumar, S. Mm- soc: Benchmarking multimodal large language models in social media platforms. InACL, 2024. Kim, Y . and Introne, J. Belief alignment vs opinion leadership: Understanding cross-linguistic digital ac- tivism in k-p...
-
[3]
emnlp-main.698/
URL https://aclanthology.org/2024. emnlp-main.698/. OpenAI. Introducing gpt-5. https://openai.com/ zh-Hans-CN/index/introducing-gpt-5/ ,
2024
-
[4]
doi: 10.18653/v1/2024.findings-emnlp
Accessed: 2026-01-24. Rehman, M. Z. U., Kasu, S. K. R., Koppula, S. R., Chirra, S. R. R., Singh, S. S., and Kumar, N. X-mutest: A multi- lingual benchmark for explainable hate speech detection and a novel llm-consulted explanation framework.arXiv preprint arXiv:2601.03194, 2026. Team, V ., Hong, W., Yu, W., Gu, X., Wang, G., Gan, G., Tang, H., Cheng, J., ...
-
[5]
Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv
URL https://aclanthology.org/2024. findings-emnlp.765/. Ye, F. T.-F. and Gao, X. Marriage discourse on chinese social media: An llm-assisted analysis, 2026. URL https://arxiv.org/abs/2512.23609. Zhang, C., Abdul-Mageed, M., and Jawahar, G. Contrastive learning of sociopragmatic meaning in social media. In Findings of the Association for Computational Ling...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[6]
Translation Feasibility: Determine whether the content can be accurately translated without relying on additional visual information, such as images or videos
-
[7]
Only if both criteria are satisfied, return a positive decision
Cross-lingual Value: Determine whether the content is worth recommending to English-speaking or other non-Chinese users, i.e., whether it is relevant, informative, or appealing to audiences beyond the Chinese-speaking community. Only if both criteria are satisfied, return a positive decision. Your output must strictly follow the format below: ``` Reason: ...
2025
-
[8]
What topics would users in this domain want to share or read about?
Topic suggestion.For each (Domain, Note) pair from metadata, we prompt an LLM with real examples and ask:“What topics would users in this domain want to share or read about?”The model returns a short list of plausible, user-motivated topics
-
[9]
Note generation.For each suggested topic, we prompt the LLM again to write a full note, conditioned on the domain, note type, and 1–2 metadata examples as style references. We multi-sample with temperature = 1 and top-p = 1, and ensure that all generated notes are sufficiently dissimilar from the original 1,890 metadata instances to prevent overlap with t...
-
[10]
planting grass
Express Notes • Determine whether the note exhibits a strong expressive or emotional writing style, such as recommendation-style (“planting grass”), review-style, checklist-style, emotional resonance, or interactive prompting. • If the expressive characteristics are not sufficiently clear, moderately enhance the stylistic features. • Do not introduce slan...
-
[11]
Symbol Notes If the note contains few culture-loaded elements, appropriately add one or two of the following: • Internet slang, meme terms, or buzzwords associated with Chinese online culture • Culture-specific content such as Chinese idioms, sayings, or classical expressions
-
[12]
Enhance the note so that it exhibits clear expressive stylistic features while also containing rich culture-loaded symbols
Hybrid Notes Assess both linguistic style and the presence of culture-loaded terms. Enhance the note so that it exhibits clear expressive stylistic features while also containing rich culture-loaded symbols. General Requirements: • Do not make extensive modifications. • Preserve semantic coherence and accuracy. • Ensure the rewritten text conforms to natu...
-
[13]
Preserve each placeholder exactly and keep it in the corresponding position in the translated text
Placeholders in the form of #占位x# must not be translated. Preserve each placeholder exactly and keep it in the corresponding position in the translated text
-
[14]
Do not include any additional content, notes, or explanations
Output only the translated result. Do not include any additional content, notes, or explanations
-
[15]
Preserve all structural tags such as <title></title>, <content></content>, etc., and output the translation using the same format
-
[16]
The translation should: - Faithfully preserve the original emotional tone (e.g., excitement, sarcasm, complaint, humor, irony)
The source text is user-generated social media content. The translation should: - Faithfully preserve the original emotional tone (e.g., excitement, sarcasm, complaint, humor, irony). - Sound natural and idiomatic to native English speakers on social platforms. - Avoid overly formal, academic, or literal phrasing
-
[17]
- Do not add explanations or annotations
When the original text contains culture-specific expressions, slang, or implicit context that may not be immediately clear to English readers: - Translate them into an equivalent expression that conveys the same intent and emotion. - Do not add explanations or annotations
-
[18]
Do not omit emotionally or pragmatically important details or structure
Do not introduce information that is not present in the original text. Do not omit emotionally or pragmatically important details or structure. The [CONTENT] to be translated is as follows: {content} Please provide the translated result: Figure 11.The prompt for CULTURE-MT translation generation. G. Judger Training Flowchart Figure 12 illustrates the scor...
-
[19]
Source:“我真的会谢!”
No loss or distortion of factual in- formation. Source:“我真的会谢!”
-
[20]
I’m literally done
Emotional tone matches the origi- nal (e.g., excitement, sarcasm, frustra- tion). Reference:“I’m literally done.” (Correct emotional expression)
-
[21]
I will really thank you
Correct handling of pragmatic in- ference and ambiguity caused by dis- course focus shifts. Incorrect:“I will really thank you.” (Literal translation, wrong emotion) Unit and Measure- ment Accuracy When culturally specific units are involved, whether conversions are accurate, clear, and whether implicit information in Chinese is properly supplemented when...
-
[22]
Correct numerical conversion.Source:“他180斤。”
-
[23]
He weighs 180jin(about 90 kilograms)
Clear and unambiguous units.Reference:“He weighs 180jin(about 90 kilograms).”
-
[24]
He weighs 180
Necessary contextual supplementa- tion for omitted units in Chinese. Incorrect:“He weighs 180.” (Unit missing) Incorrect:“He weighs 180 pounds.” (Wrong unit) Proper Noun Accu- racy For names of people, places, brands, and works, whether of- ficial or widely accepted transla- tions are used
-
[25]
北京”→“Beijing
Use standardized translations (e.g., “北京”→“Beijing”). Source:“看了《甄传》。”
-
[26]
WatchedEmpresses in the Palace
When no official translation ex- ists, adopt common transliteration or convention-based translations. Reference:“WatchedEmpresses in the Palace.”
-
[27]
WatchedZhen Huan Biography
Maintain consistency throughout the text. Incorrect:“WatchedZhen Huan Biography.” (Non-standard) Cultural Adaptation Culture-loaded Term Handling Whether idioms, slang, and platform-specific expressions are appropriately interpreted, ex- plained, or culturally adapted to ensure comprehension by target readers
-
[28]
Source:“这课太水了。”
Avoid destructive literal transla- tion. Source:“这课太水了。”
-
[29]
This course is basically filler
Prefer culturally equivalent expres- sions in the target language. Reference:“This course is basically filler.” (Colloquial English)
-
[30]
This course has too much water
Use explanatory translation when necessary to integrate naturally into context. Incorrect:“This course has too much water.” (Literal translation) Overall Cultural Flu- ency Whether the translation aligns with usage norms of English so- cial media and reads like original content rather than a translation
-
[31]
Source:“氛围感拉满。”
Conforms to English social media style and lexical preferences. Source:“氛围感拉满。”
-
[32]
The vibes are absolutely im- maculate
Avoids Chinese-style English syn- tactic patterns. Reference:“The vibes are absolutely im- maculate.”
-
[33]
The atmosphere feeling is pulled full
Overall fluent, natural, and platform-native. Incorrect:“The atmosphere feeling is pulled full.” Addressing and Po- liteness Adaptation Whether culturally specific forms of address and vocatives are adapted to fit social norms and politeness conventions of the tar- get culture
-
[34]
Source:“姐妹们看过来!”
Consider appropriate levels of fa- miliarity and context. Source:“姐妹们看过来!”
-
[35]
Hey guys, check this out!
Avoid awkwardness or unintended offense caused by literal address trans- lation. Reference:“Hey guys, check this out!”
-
[36]
Sisters, look here!
Seek functionally equivalent ex- pressions in the target culture. Incorrect:“Sisters, look here!” (Awkward, slogan-like) Table 10.Domain-wiseIneffective Share(score 0–1; lower is better,↓). Domain Seed-X-PPO Seed-X-Instruct Ours-8B Qwen3-8B Ours-32B Qwen3-32B Qwen3-4B Qwen-235B Gemini 3 Deepseek V3.2 GLM-4.6v A VG. Outdoor 33.33% 48.81% 39.29% 47.62% 25.0...
-
[37]
姐妹"、"老师"、
评分要求: 语义准确性核心要求: * 正确理解原文语义及情感:译文需准确反映原文的字面意思和隐含情感(如讽刺、兴奋、沮丧)。口语化表达里容易缺少标点符号,也容易出现因为断句理解错误而语义曲解。 * 文化适应性称呼翻译:对"姐妹"、"老师"、"宝子"等称呼的翻译需考虑文化背景和社交礼仪,不能存在冒犯或歧义。 * 符合目标文化语境:译文需符合英语文化语境和目标受众(社交媒体用户)的阅读习惯,避免中式英语。 * 文化负载词处理:对承载特定文化、网络或语境含义的词汇(如"绝绝子"、"种草"),直译无法理解的,必须进行意译或文化替换,不可直译。 * 单位换算准确性:涉及中式单位(如"亩"、"斤"、"里")与国际单位的换算时,需准确并明确限定范围,避免歧义;对于中文习惯省略的单位,译文中需补充完整。 * 专有名词准确...
-
[38]
评分标准: 你需要为整篇翻译给出一个 0到3分 的总体分数,定义如下: * 0分:译文有严重错误,无法传递原文语义、内容丢失或曲解原文语义。无法让英文用户感受到原文的语境或者情绪。 * 1分:译文存在明显问题,但主要语义尚可被艰难理解。存在关键错误、文化误译,缺乏文化适应性,严重影响阅读体验。 * 2分:译文准确传达了原文的主要信息,语法基本正确,语境或情绪表达合理。 * 3分:译文精准、表达自然、符合英语文化语境,语法规范,传达原文的所有信息和情感,精准符合英语社交平台受众的阅读习惯。
-
[39]
输出格式: 希望你既要输出思考的过程,也要进行一个总结,并给出最终的0到3的分数。回复的格式参考如下: 问题1位置:xxx 对问题1的评论:xxx 问题2位置:xxx 对问题2的评论:xxx 综上,对整句的翻译意见:xxx 最终分数:(只有数字)”
-
[40]
引产"是指人工诱发分娩以使胎儿存活,应译为
评估示例: * 示例1: 可参考的上下文:0.第一次看鸟片好紧张 1.#手养鹦鹉[话题]# #玄凤鹦鹉[话题]# #合法饲养[话题]# 尊滴好尴尬 2.昨天我家的狗子被不认识的大狼狗给那啥了,那狗比我家狗足足大了2倍,看到的时候已经屁股对着屁股了,我老公说这时候不能去动他们,不然会出不来,受伤的,我家狗2条后腿都悬空着的[惊恐R] 原文:<comment3>必须引产,生不出来,太危险</comment3> 译文:<comment3>An abortion is necessary, it can't be born, it's too dangerous.</comment3> 输出: 问题1位置:An abortion is necessary 对问题1的评论:"引产"是指人工诱发分娩以使胎儿存活,应译...
-
[41]
请你根据上述提示,对这个翻译内容以规定的格式进行评估,仅输出评估内容,不要输出其他无关内容。 {content} 输出: Figure 13.The Prompt for Cultural Effectiveness Evaluation. 18 CULTURE-MT: Cultural Effectiveness in Social Media UGC Translation You are a highly rigorous translation quality evaluation expert with full proficiency in both Chinese and English, and with deep familiarity with internet culture. Yo...
-
[42]
姐妹(“girls
Scoring Requirements Core requirements for semantic accuracy: • Correct understanding of meaning and emotion: The translation must accurately reflect both the literal meaning and the implicit emotions of the source text (e.g., sarcasm, excitement, frustration). Colloquial expressions often lack punctuation, and incorrect sentence segmentation may easily l...
-
[43]
• 1 point: The translation has obvious problems, but the main meaning can still be understood with difficulty
Scoring Criteria You must assign an overall score from 0 to 3 for the entire translation, defined as follows: • 0 points: The translation contains severe errors, fails to convey the original meaning, distorts or omits key content, and does not allow English readers to perceive the original context or emotion. • 1 point: The translation has obvious problem...
-
[44]
Output Format You are required to output both your reasoning process and a final summary, and then provide the final score from 0 to 3. The response format should follow the example below: Issue 1 Location: xxx Comment on Issue 1: xxx Issue 2 Location: xxx Comment on Issue 2: xxx Overall translation feedback: xxx Final Score: (number only)
-
[45]
引产” refers to inducing labor to deliver a viable fetus and should be translated as “induced labor
Evaluation Examples Example 1 Reference Context: 0. First time watching a bird video, so nervous 1.#Hand-raisedParrot[Topic]# #Cockatiel[Topic]# #LegalPetOwnership[Topic]# So embarrassing 2.Yesterday my dog was “that-ed” by a huge unfamiliar dog—twice her size. When we saw them, they were already butt to butt. My husband said we couldn’t separate them or ...
-
[46]
Only output the evaluation content
Task Instruction Please evaluate the following translation content according to the above instructions and required format. Only output the evaluation content. Do not output any other unrelated content. {content} Output: Figure 14.The Translation Version of The Prompt for Cultural Effectiveness Evaluation. 19 CULTURE-MT: Cultural Effectiveness in Social M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.