When In-Distribution Gains Fail: Evaluating Weak-to-Strong Reward Models under Preference Shift
Pith reviewed 2026-06-29 21:21 UTC · model grok-4.3
The pith
Strong reward models trained on weak preference labels succeed within the training distribution yet fail to transfer to shifted preference datasets due to representational drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
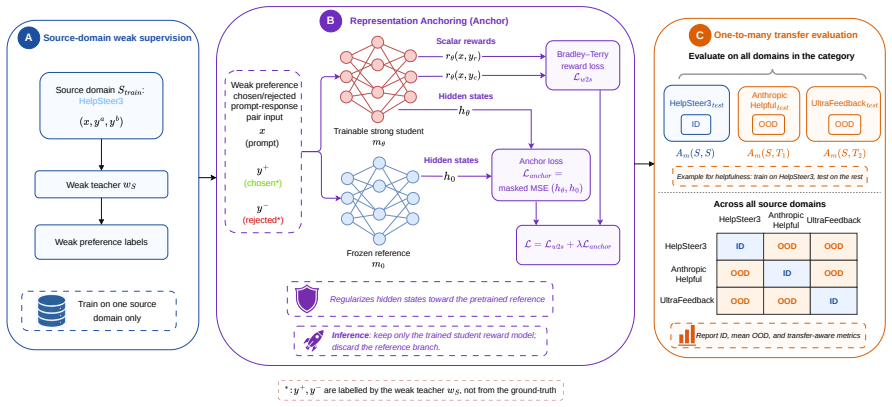
Strong students trained on weak preference labels can appear successful in-distribution while failing to transfer across preference datasets. This stems from a representational failure mode where weak-supervised fine-tuning pulls the strong model toward source-domain features instead of maintaining broadly transferable preference representations. Representation Anchoring constrains excessive drift from the pretrained strong model's representation space during fine-tuning, while still allowing task-relevant adaptation, and thereby improves out-of-distribution transfer across preference domains, datasets, and model families.
What carries the argument
Representation Anchoring (Anchor), a regularizer that constrains the distance of fine-tuned representations from the pretrained strong model's representation space.
If this is right
- In-distribution performance remains competitive under the anchoring regularizer.
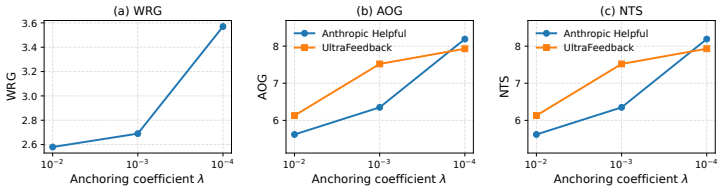
- Out-of-distribution transfer improves consistently across preference domains, datasets, and model families.
- Transfer-aware metrics are required to detect brittleness that standard in-distribution evaluations miss.
- Current weak-to-strong reward modeling approaches exhibit hidden limitations under preference shift.
Where Pith is reading between the lines
- Anchoring techniques may prove useful in other weak-to-strong alignment tasks that involve representation stability.
- Preference dataset construction could benefit from deliberate diversity to reduce dependence on post-hoc anchoring.
- Scalable oversight protocols should incorporate explicit zero-shot shift tests rather than relying solely on matched train-test splits.
Load-bearing premise
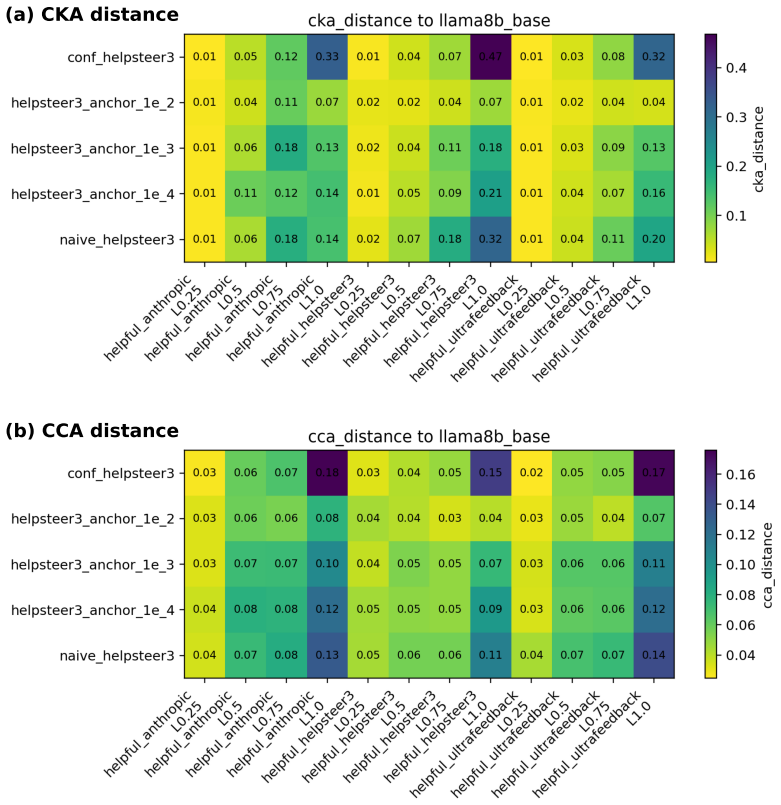
The observed transfer failures are caused by excessive representational drift toward source-domain features that can be mitigated by constraining distance from the pretrained representation space.
What would settle it
If applying Representation Anchoring produces no measurable reduction in representational drift or no corresponding gain in out-of-distribution transfer on held-out preference datasets, the proposed mechanism would be falsified.
Figures

read the original abstract
Weak-to-strong (W2S) generalization is a promising framework for scalable oversight, yet existing evaluations often test students under matched train-test distributions. Therefore, we study W2S preference learning under zero-shot distribution shift and find that strong students trained on weak preference labels can appear successful in-distribution while failing to transfer across preference datasets. We provide evidence for a representational failure mode in which weak-supervised fine-tuning can pull the strong model toward source-domain features instead of maintaining broadly transferable preference representations. To mitigate this, we propose Representation Anchoring (Anchor), a simple yet effective regularizer that constrains excessive drift from the pretrained strong model's representation space during fine-tuning, while still allowing task-relevant adaptation. Across preference domains, datasets, and model families, Anchor consistently improves out-of-distribution transfer while maintaining competitive in-distribution performance. Together, our evaluation protocol, transfer-aware metrics, and method expose hidden brittleness in current W2S reward modeling and provide a practical path toward more robust preference transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies weak-to-strong preference learning under zero-shot distribution shift across preference datasets. It claims that strong students trained on weak labels can succeed in-distribution yet fail to transfer, due to a representational failure mode in which fine-tuning pulls models toward source-domain features rather than maintaining transferable preference representations. It proposes Representation Anchoring (Anchor), a regularizer that constrains drift from the pretrained representation space, and reports that Anchor improves OOD transfer while preserving competitive ID performance across domains, datasets, and model families.
Significance. If the empirical results and controls hold, the work would be significant for scalable oversight research: it supplies a concrete evaluation protocol and transfer-aware metrics that expose brittleness in existing W2S reward modeling, together with a simple, practical regularizer that demonstrably improves robustness. The emphasis on out-of-distribution transfer rather than matched train-test evaluation is a useful corrective to current practice.
major comments (2)
- [Abstract] Abstract: the central claims (in-distribution success with OOD failure, representational drift as the cause, and consistent gains from Anchor) are stated without any quantitative results, error bars, dataset sizes, model scales, or ablation numbers, so the magnitude, statistical reliability, and reproducibility of the findings cannot be assessed from the manuscript text.
- [Method / Experiments] Method / Experiments (implied by the abstract description of Anchor): the attribution of transfer failure specifically to excessive representational drift toward source features is not isolated from alternative explanations such as label noise levels or dataset-construction artifacts; without matched noise controls or head-to-head comparisons against other regularizers of comparable strength (e.g., weight decay or label smoothing), the reported OOD gains from Anchor could arise from generic overfitting reduction rather than preservation of transferable representations.
minor comments (1)
- [Abstract] Abstract: the phrase 'zero-shot distribution shift' is used without a precise definition of what is held fixed versus varied between source and target preference datasets.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each of the major comments below and have made revisions to improve the clarity and rigor of our presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims (in-distribution success with OOD failure, representational drift as the cause, and consistent gains from Anchor) are stated without any quantitative results, error bars, dataset sizes, model scales, or ablation numbers, so the magnitude, statistical reliability, and reproducibility of the findings cannot be assessed from the manuscript text.
Authors: We agree with this observation. The original abstract was written to be concise, but we recognize that including quantitative highlights would better convey the strength of the results. In the revised version, we have updated the abstract to include specific numbers on in-distribution and out-of-distribution performance gains from Anchor, along with details on the datasets, model scales, and number of runs for error bars. revision: yes
-
Referee: [Method / Experiments] Method / Experiments (implied by the abstract description of Anchor): the attribution of transfer failure specifically to excessive representational drift toward source features is not isolated from alternative explanations such as label noise levels or dataset-construction artifacts; without matched noise controls or head-to-head comparisons against other regularizers of comparable strength (e.g., weight decay or label smoothing), the reported OOD gains from Anchor could arise from generic overfitting reduction rather than preservation of transferable representations.
Authors: This is a valid concern. Our manuscript provides evidence through representation probing and similarity metrics showing that standard W2S fine-tuning leads to greater drift from the pretrained space, correlating with OOD failure. However, to address potential confounds from generic regularization, we have conducted additional experiments comparing Anchor to weight decay and label smoothing at matched regularization strengths. These results, now included in the revised paper, demonstrate that Anchor yields superior OOD performance, suggesting the benefit is not solely from overfitting reduction. For label noise and dataset artifacts, we used consistent weak label generation procedures across domains, but we have added a discussion of these factors and note that future work could explore explicit noise matching. revision: partial
Circularity Check
No circularity: empirical claims rest on experimental observations, not self-referential derivations or fitted inputs.
full rationale
The paper presents an empirical study of weak-to-strong preference learning under distribution shift, proposing Representation Anchoring as a regularizer based on observed transfer failures. No equations, derivations, or first-principles results are described in the abstract or reader summary. Claims about representational drift and mitigation are framed as experimental findings rather than mathematical reductions to inputs. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way. The central argument relies on external benchmarks (preference datasets, model families) and does not reduce by construction to fitted parameters renamed as predictions. This is a standard non-finding for an evaluation-focused ML paper without visible theoretical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang
Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526. Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. 2022. Fine- tuning can distort pretrained features and underper- form out-of-distribution. InInternational Conference on Learning Representations. Natha...
2022
-
[2]
Scalable agent alignment via reward modeling: a research direction
Mixout: Effective regularization to finetune large-scale pretrained language models. InInterna- tional Conference on Learning Representations. Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, and Shane Legg. 2018. Scalable agent alignment via reward modeling: a research direction. Preprint, arXiv:1811.07871. Hongyu Li, Liang Ding, Meng ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
InThe Thirteenth International Conference on Learning Representations
MACPO: Weak-to-strong alignment via multi- agent contrastive preference optimization. InThe Thirteenth International Conference on Learning Representations. Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO: Simple preference optimization with a reference-free reward. InThe Thirty-eighth Annual Conference on Neural Information Processing Sys- tems. Fan N...
2024
-
[4]
Training language models to follow instructions with human feedback
Weak-for-strong: Training weak meta-agent to harness strong executors. InSecond Conference on Language Modeling. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welind...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
InAdvances in neural information processing systems, volume 36, pages 53728–53741
Direct preference optimization: Your language model is secretly a reward model. InAdvances in neural information processing systems, volume 36, pages 53728–53741. Junhao Shi, Qinyuan Cheng, Zhaoye Fei, Yining Zheng, Qipeng Guo, and Xipeng Qiu. 2025. How to miti- gate overfitting in weak-to-strong generalization? In Proceedings of the 63rd Annual Meeting o...
-
[6]
InThe Thirteenth International Conference on Learning Representations
Spurious forgetting in continual learning of language models. InThe Thirteenth International Conference on Learning Representations. Zhanhui Zhou, Zhixuan Liu, Jie Liu, Zhichen Dong, Chao Yang, and Yu Qiao. 2024. Weak-to-strong search: Align large language models via searching over small language models. InThe Thirty-eighth An- nual Conference on Neural I...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.