HumanFlow -- Diffusion-Driven MAV Navigation Among Humans via Tightly-Coupled Motion Tracking, Forecasting, and Control
Pith reviewed 2026-06-29 21:41 UTC · model grok-4.3
The pith
HumanFlow couples a latent diffusion model for human motion tracking and forecasting with a flow-matching MPC policy to enable collision-free MAV navigation under partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
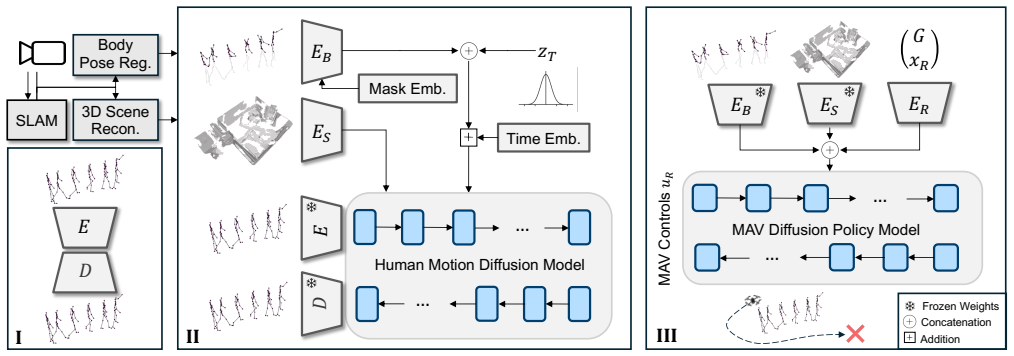
HumanFlow is a latent diffusion model that unifies human motion tracking and forecasting conditioned on the 3D scene context. Its latent space can be tightly coupled with control by conditioning a flow-matching-based approximate MPC policy on these representations. Validation in simulation with real human trajectories for MAV social navigation shows superior navigation performance and collision-free behavior even under partial observability of the human.
What carries the argument
Latent diffusion model for unified human motion tracking and forecasting, whose representations directly condition a flow-matching approximate MPC policy.
If this is right
- The diffusion model produces smooth and accurate human motion predictions under heavy occlusions.
- It outperforms state-of-the-art methods in tracking accuracy while running significantly faster.
- The tightly coupled controller achieves superior navigation performance in simulation using real human trajectories.
- The MAV remains collision-free even when human visibility is only partial.
Where Pith is reading between the lines
- Direct use of the same latent space for both forecasting and control may reduce the lag between perception and action in dynamic settings.
- The scene-conditioned approach could transfer to navigation tasks involving multiple interacting humans or other robot platforms.
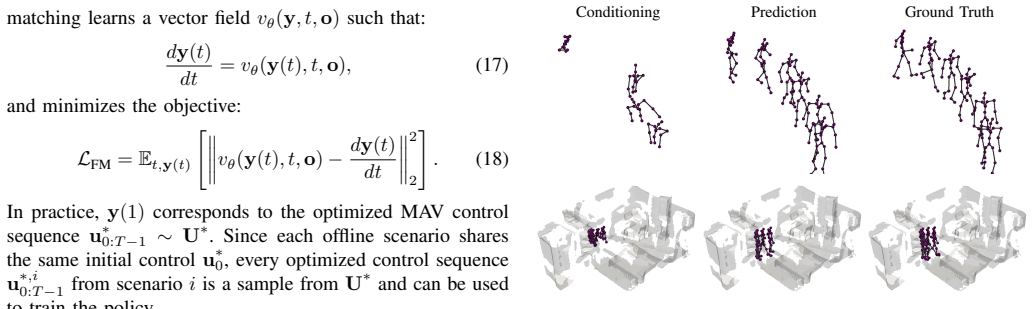
- Testing the same coupling on physical MAV hardware would reveal whether simulation results hold under real sensor noise and dynamics.
- Alternative ways to embed the diffusion latents into the policy might further stabilize the closed-loop behavior.
Load-bearing premise
The latent representations from the diffusion model contain sufficient information to condition the flow-matching MPC policy without losing critical dynamic constraints or causing closed-loop instability.
What would settle it
A recorded collision between the MAV and a human during a navigation test that uses the HumanFlow controller under partial human observability.
Figures


read the original abstract
Robust and accurate perception of humans in their 3D scene context is essential for integrating robots into everyday environments. Existing approaches, however, often fail to predict plausible and accurate human motion estimates that are consistent with the surrounding scene, especially in the presence of heavy occlusions or partial visibility. This can limit both safety and efficiency for robotic operations. We introduce HumanFlow, a latent diffusion model that unifies human motion tracking and forecasting, conditioned on the 3D scene context. We show that our human motion model produces smooth and accurate predictions under challenging conditions, including heavy occlusions, and outperforms state-of-the-art methods in tracking accuracy while being significantly more efficient. Furthermore, we show how HumanFlow's latent space can be tightly coupled with control by conditioning a flow-matching-based, approximate MPC policy on these representations. We validate our policy in simulation with real human trajectories for MAV social navigation, demonstrating superior navigation performance and remaining collision-free, even under partial observability of the human.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HumanFlow, a latent diffusion model that unifies 3D scene-conditioned human motion tracking and forecasting. It claims to produce smooth, accurate predictions under heavy occlusions that outperform SOTA methods in tracking accuracy while being more efficient. The model’s latent space is then tightly coupled to a flow-matching approximate MPC policy to enable collision-free MAV social navigation under partial observability, with validation on real human trajectories in simulation.
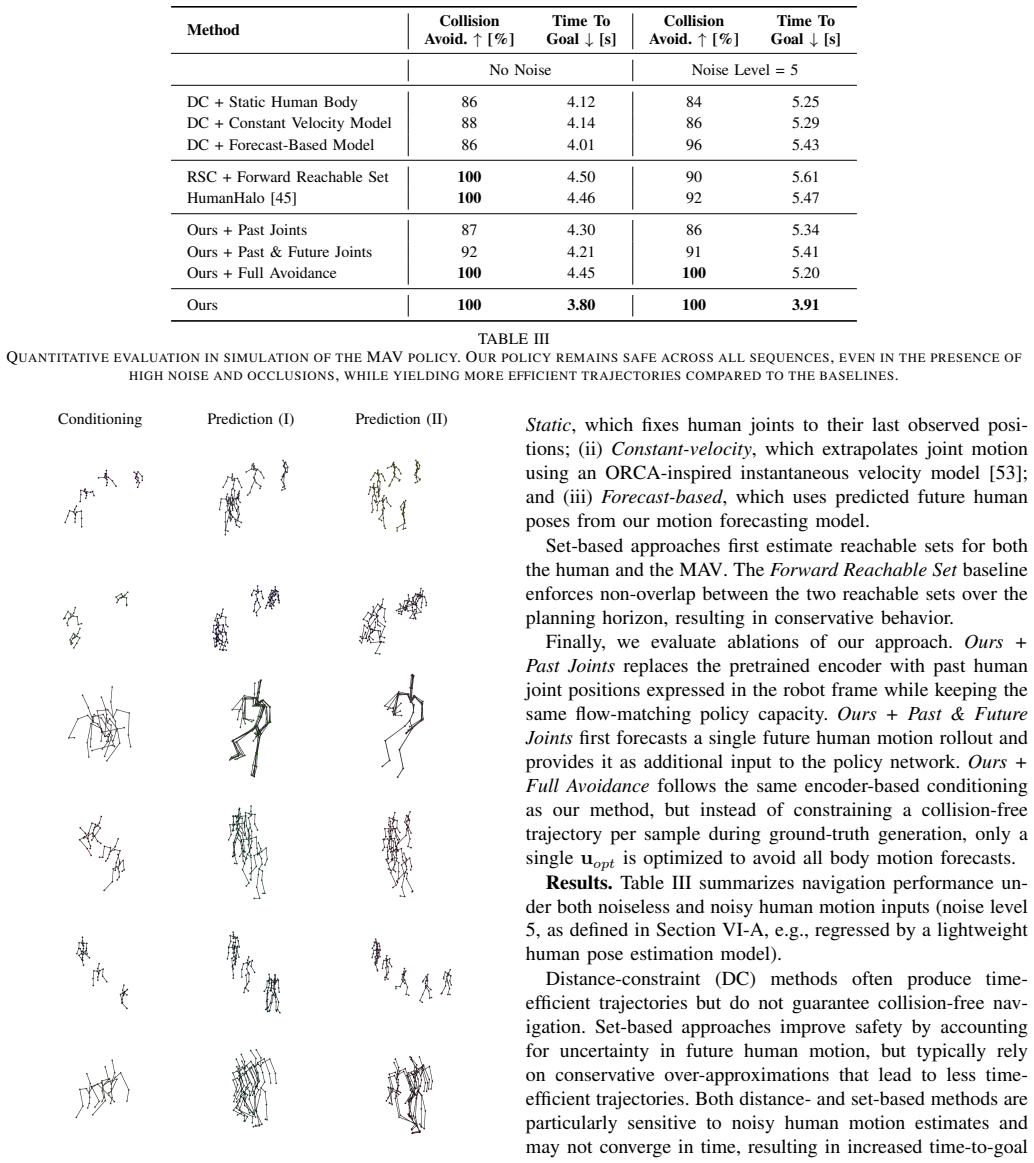
Significance. If the central claims hold, the work would offer a concrete route to tightly integrated perception-control pipelines for robots in human environments, leveraging diffusion latents for both forecasting and policy conditioning. The efficiency and occlusion robustness claims, if substantiated with ablations and error bars, would be a notable contribution to the MAV navigation literature.
major comments (2)
- [Abstract] Abstract and methods description: the headline claim that the diffusion latent space can be directly conditioned into the flow-matching approximate MPC without loss of dynamic constraints or introduction of instability is load-bearing for the navigation results, yet no derivation, constraint-preservation proof, or ablation is referenced showing that velocity/acceleration bounds or occlusion uncertainty are preserved in the latent encoding.
- [Validation] Validation section: the reported superior navigation performance and collision-free behavior under partial observability rest on the assumption that the latent representations transmit scene-consistent human dynamics; without ablations that isolate the effect of the latent conditioning versus a baseline MPC, it is impossible to confirm that the coupling itself is responsible for the gains rather than other implementation choices.
minor comments (2)
- [Abstract] The abstract states performance gains but provides no quantitative metrics, dataset descriptions, or error bars; these should be added to the results section for reproducibility.
- [Methods] Notation for the latent space and flow-matching policy should be introduced with explicit equations early in the methods to clarify the conditioning mechanism.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of the latent-to-control coupling.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: the headline claim that the diffusion latent space can be directly conditioned into the flow-matching approximate MPC without loss of dynamic constraints or introduction of instability is load-bearing for the navigation results, yet no derivation, constraint-preservation proof, or ablation is referenced showing that velocity/acceleration bounds or occlusion uncertainty are preserved in the latent encoding.
Authors: We agree that an explicit derivation would improve clarity. In the revised manuscript we will add a short derivation in the methods section showing that the flow-matching approximate MPC preserves velocity and acceleration bounds when conditioned on the latent representations, together with a targeted ablation that quantifies stability under varying occlusion levels. revision: yes
-
Referee: [Validation] Validation section: the reported superior navigation performance and collision-free behavior under partial observability rest on the assumption that the latent representations transmit scene-consistent human dynamics; without ablations that isolate the effect of the latent conditioning versus a baseline MPC, it is impossible to confirm that the coupling itself is responsible for the gains rather than other implementation choices.
Authors: We concur that isolating the contribution of the latent conditioning is necessary. We will expand the validation section with new ablation experiments that compare the full HumanFlow-conditioned policy against an otherwise identical baseline MPC that receives only raw observations, thereby confirming that the performance gains under partial observability arise from the tight coupling. revision: yes
Circularity Check
No circularity; abstract presents empirical claims without visible derivation chain
full rationale
The provided abstract and context contain no equations, parameter-fitting descriptions, self-citations, or uniqueness theorems that could reduce any prediction or result to its inputs by construction. Claims of outperforming SOTA in tracking accuracy and achieving collision-free navigation under partial observability are stated as validation outcomes without reference to internal reductions or load-bearing self-references. The work is therefore self-contained against external benchmarks on the basis of the given text, with no identifiable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Learning using Rectified Linear Units (ReLU)
Abien Fred Agarap. Deep learning using rectified linear units (relu), 2019. URL https://arxiv.org/abs/1803.08375
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Intention-aware online pomdp planning for autonomous driving in a crowd
Haoyu Bai, Shaojun Cai, Nan Ye, David Hsu, and Wee Sun Lee. Intention-aware online pomdp planning for autonomous driving in a crowd. In2015 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 454–460, 2015. doi: 10.1109/ICRA.2015.7139219
-
[3]
Multi-HMR: Multi-person whole- body human mesh recovery in a single shot
Fabien Baradel*, Matthieu Armando, Salma Galaaoui, Romain Br ´egier, Philippe Weinzaepfel, Gr ´egory Rogez, and Thomas Lucas*. Multi-HMR: Multi-person whole- body human mesh recovery in a single shot. InECCV, 2024
2024
-
[4]
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J. Black. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. InComputer Vision – ECCV 2016, Lecture Notes in Computer Science. Springer International Publishing, October 2016
2016
-
[5]
Long-term human motion prediction with scene context
Zhe Cao, Hang Gao, Karttikeya Mangalam, Qizhi Cai, Minh V o, and Jitendra Malik. Long-term human motion prediction with scene context. InECCV, 2020
2020
-
[6]
VidBot: Learning general- izable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation
Hanzhi Chen, Boyang Sun, Anran Zhang, Marc Polle- feys, and Stefan Leutenegger. VidBot: Learning general- izable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. InCVPR, 2025
2025
-
[7]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010, 2023
2023
-
[8]
Murray, and Joel W
Richard Cheng, Gabor Orosz, Richard M. Murray, and Joel W. Burdick. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks, 2019
2019
-
[9]
Dif- fusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. InRSS, 2023
2023
-
[10]
Non- isotropic gaussian diffusion for realistic 3d human motion prediction
Cecilia Curreli, Dominik Muhle, Abhishek Saroha, Zhen- zhang Ye, Riccardo Marin, and Daniel Cremers. Non- isotropic gaussian diffusion for realistic 3d human motion prediction. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 1871– 1882, June 2025
2025
-
[11]
Hybrid predictive control for aerial robotic physical interaction towards inspection opera- tions
Georgios Darivianakis, Kostas Alexis, Michael Burri, and Roland Siegwart. Hybrid predictive control for aerial robotic physical interaction towards inspection opera- tions. InIEEE International Conference on Robotics and Automation (ICRA), pages 53–58, 2014. doi: 10. 1109/ICRA.2014.6906589
-
[12]
Anca D. Dragan. Robot planning with mathematical models of human state and action, 2017. URL https: //arxiv.org/abs/1705.04226
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Michael Everett, Yu Fan Chen, and Jonathan P. How. Collision avoidance in pedestrian-rich environments with deep reinforcement learning.IEEE Access, 9: 10357–10377, 2021. ISSN 2169-3536
2021
-
[14]
PAMPC: Perception-aware model predic- tive control for quadrotors
Davide Falanga, Philipp Foehn, Peng Lu, and Davide Scaramuzza. PAMPC: Perception-aware model predic- tive control for quadrotors. InIEEE/RSJ Int. Conf. Intell. Robot. Syst. (IROS), 2018
2018
-
[15]
Distribution-aligned diffusion for human mesh recovery
Lin Geng Foo, Jia Gong, Hossein Rahmani, and Jun Liu. Distribution-aligned diffusion for human mesh recovery. arXiv preprint arXiv:2211.16940, 2023
-
[16]
Herbert, Jaime F
David Fridovich-Keil, Sylvia L. Herbert, Jaime F. Fisac, Sampada Deglurkar, and Claire J. Tomlin. Planning, fast and slow: A framework for adaptive real-time safe trajectory planning.IEEE International Conference on Robotics and Automation, 2018
2018
-
[17]
Hu- mans in 4D: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Ra- jasegaran, Angjoo Kanazawa*, and Jitendra Malik*. Hu- mans in 4D: Reconstructing and tracking humans with transformers. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[18]
Diffpose: Toward more reliable 3d pose estimation
Jia Gong, Lin Geng Foo, Zhipeng Fan, Qiuhong Ke, Hossein Rahmani, and Jun Liu. Diffpose: Toward more reliable 3d pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023
2023
-
[19]
Karen Liu, Yuting Ye, and Lingni Ma
Vladimir Guzov, Yifeng Jiang, Fangzhou Hong, Gerard Pons-Moll, Richard Newcombe, C. Karen Liu, Yuting Ye, and Lingni Ma. HMD2: Environment-aware motion generation from single egocentric head-mounted device. InInternational Conference on 3D Vision (3DV), March 2025
2025
-
[20]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. De- noising diffusion probabilistic models.arXiv preprint arxiv:2006.11239, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
Zhiming Hu, Zheming Yin, Daniel Haeufle, Syn Schmitt, and Andreas Bulling. Hoimotion: Forecasting human motion during human-object interactions using egocen- tric 3d object bounding boxes.IEEE Transactions on Visualization and Computer Graphics (TVCG), pages 1– 11, 2024
2024
-
[23]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36, 2024
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[24]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2151–2162, 2023
2023
-
[25]
Marigold: Affordable adaptation of diffusion- based image generators for image analysis, 2025
Bingxin Ke, Kevin Qu, Tianfu Wang, Nando Metzger, Shengyu Huang, Bo Li, Anton Obukhov, and Konrad Schindler. Marigold: Affordable adaptation of diffusion- based image generators for image analysis, 2025
2025
-
[26]
Occluded human mesh recovery
Rawal Khirodkar, Shashank Tripathi, and Kris Kitani. Occluded human mesh recovery. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), pages 1705–1715, Piscataway, NJ, June
2022
-
[27]
IEEE. doi: 10.1109/CVPR52688.2022.00176
-
[28]
Huang, Otmar Hilliges, and Michael J
Muhammed Kocabas, Chun-Hao P. Huang, Otmar Hilliges, and Michael J. Black. PARE: Part attention regressor for 3D human body estimation. InProc. International Conference on Computer Vision (ICCV), pages 11127–11137, October 2021
2021
-
[29]
A software package for sequential quadratic programming
Dieter Kraft. A software package for sequential quadratic programming. Technical Report DFVLR-FB 88-28, In- stitut f ¨ur Dynamik der Flugsysteme, Oberpfaffenhofen, July 1988
1988
-
[30]
Henrik Kretzschmar, Markus Spies, Christoph Sprunk, and Wolfram Burgard. Socially compliant mobile robot navigation via inverse reinforcement learning.The In- ternational Journal of Robotics Research, 35(11):1289– 1307, 2016. doi: 10.1177/0278364915619772
-
[31]
Jotr: 3d joint contrastive learning with transformers for occluded human mesh recovery.ICCV, 2023
Jiahao Li, Zongxin Yang, Xiaohan Wang, Jianxin Ma, Chang Zhou, and Yi Yang. Jotr: 3d joint contrastive learning with transformers for occluded human mesh recovery.ICCV, 2023
2023
-
[32]
Ross, and Angjoo Kanazawa
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. Learn to dance with AIST++: Music con- ditioned 3d dance generation.ICCV, 2021
2021
-
[33]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, and Maximilian Nickel Matt Le. Flow matching for generative modeling.ICLR, 2023
2023
-
[34]
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, October 2015
2015
-
[35]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learn- ing Representations, 2019. URL https://openreview.net/ forum?id=Bkg6RiCqY7
2019
-
[36]
Troje, Gerard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. InInter- national Conference on Computer Vision, pages 5442– 5451, October 2019
2019
-
[37]
Kuchenbecker
Pau Marquez Julbe, Julian Nubert, Henrik Hose, Sebas- tian Trimpe, and Katherine J. Kuchenbecker. Diffusion- based approximate MPC: Fast and consistent imitation of multi-modal action distributions. InIROS, 2025
2025
-
[38]
I.M. Mitchell, A.M. Bayen, and C.J. Tomlin. A time- dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games.IEEE Transactions on Automatic Control, 50(7):947–957, 2005. doi: 10.1109/ TAC.2005.851439
-
[39]
Pytorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K ¨opf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chin- tala. Pytorch: an imperative style, high-perf...
2019
-
[40]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[41]
Courville
Ethan Perez, Florian Strub, Harm de Vries, Vincent Du- moulin, and Aaron C. Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018
2018
-
[42]
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J. Guibas. HuMoR: 3d human motion model for robust pose estimation. In International Conference on Computer Vision (ICCV), 2021
2021
-
[43]
Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data
Tim Salzmann, Boris Ivanovic, Punarjay Chakravarty, and Marco Pavone. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, pages 683–700, Cham, 2020. Springer International Publishing
2020
-
[44]
Han, Florian Shkurti, and Angela P
Sepehr Samavi, James R. Han, Florian Shkurti, and Angela P. Schoellig. Sicnav: Safe and interactive crowd navigation using model predictive control and bilevel op- timization.IEEE Transactions on Robotics, 41:801–818, 2025
2025
-
[45]
Leveraging neural network gradients within trajectory optimization for proactive human-robot interactions.IEEE International Conference on Robotics and Automation, 2020
Simon Schaefer, Karen Leung, Boris Ivanovic, and Marco Pavone. Leveraging neural network gradients within trajectory optimization for proactive human-robot interactions.IEEE International Conference on Robotics and Automation, 2020
2020
-
[46]
HumanHalo - safe and efficient 3d navigation among humans via minimally conservative mpc
Simon Schaefer, Helen Oleynikova, Sandra Hirche, and Stefan Leutenegger. HumanHalo - safe and efficient 3d navigation among humans via minimally conservative mpc. Inarxiv, 2024
2024
-
[47]
Mingyi Shi, Sebastian Starke, Yuting Ye, Taku Ko- mura, and Jungdam Won. Phasemp: Robust 3d pose estimation via phase-conditioned human motion prior. In2023 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 14679–14691, 2023. doi: 10.1109/ICCV51070.2023.01353
-
[48]
HUMOF: Human motion forecasting in interactive social scenes
Caiyi Sun, Yujing Sun, Xiao Han, Zemin Yang, Jiawei Liu, Xinge Zhu, Siu Ming Yiu, and Yuexin Ma. HUMOF: Human motion forecasting in interactive social scenes. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[49]
Move beyond trajectories: Distribution space coupling for crowd navigation.Robotics: Science and Systems, 2021
Muchen Sun, Francesca Baldini, Peter Trautman, and Todd Murphey. Move beyond trajectories: Distribution space coupling for crowd navigation.Robotics: Science and Systems, 2021
2021
-
[50]
Rahul Tallamraju, Nitin Saini, Elia Bonetto, Michael Pabst, Yu Tang Liu, Michael Black, and Aamir Ahmad. Aircaprl: Autonomous aerial human motion capture us- ing deep reinforcement learning.IEEE Robotics and Automation Letters, 5(4):6678–6685, October 2020. URL https://ieeexplore.ieee.org/document/9158379
-
[51]
Human motion diffusion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffusion model. InICLR, 2023
2023
-
[52]
Murray, and Andreas Krause
Pete Trautman, Jeremy Ma, Richard M. Murray, and Andreas Krause. Robot navigation in dense human crowds: Statistical models and experimental studies of human–robot cooperation.The International Journal of Robotics Research, 34(3):335–356, 2015. doi: 10.1177/ 0278364914557874
2015
-
[53]
Dimos Tzoumanikas, Wenbin Li, Marius Grimm, Ketao Zhang, Mirko Kovac, and Stefan Leutenegger. Fully autonomous micro air vehicle flight and landing on a moving target using visual–inertial estimation and model-predictive control.Journal of Field Robotics, 36 (1):49–77, 2019. doi: https://doi.org/10.1002/rob.21821. URL https://onlinelibrary.wiley.com/doi/a...
-
[54]
Guy, Ming Lin, and Dinesh Manocha
Jur van den Berg, Stephen J. Guy, Ming Lin, and Dinesh Manocha. Reciprocal n-body collision avoid- ance. In C ´edric Pradalier, Roland Siegwart, and Ger- hard Hirzinger, editors,Robotics Research, pages 3–19, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg. ISBN 978-3-642-19457-3
2011
-
[55]
Emanuele Vespa, Nils Funk, Paul H. J. Kelly, and Stefan Leutenegger. Adaptive-resolution octree-based volumetric SLAM. InInternational Conference on 3D Vision (3DV), pages 654–662, Qu´ebec City, QC, Canada, September 2019. doi: 10.1109/3DV .2019.00077
work page doi:10.1109/3dv 2019
-
[56]
Toro-Arcila, and America Morales-Diaz
Rodolfo Villalobos-Salazar, Abimael Contreras-Carlos, Carlos A. Toro-Arcila, and America Morales-Diaz. Hi- erarchical drone navigation control for ensuring safety with stationary humans. In2024 21st International Con- ference on Electrical Engineering, Computing Science and Automatic Control (CCE), pages 1–6, 2024. doi: 10.1109/CCE62852.2024.10771000
-
[57]
Yin Wang, Zhiying Leng, Frederick W. B. Li, Shun- Cheng Wu, and Xiaohui Liang. Fg-t2m: Fine-grained text-driven human motion generation via diffusion model. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 21978–21987, 2023. doi: 10.1109/ICCV51070.2023.02014
-
[58]
Scene- aware human motion forecasting via mutual distance prediction
Chaoyue Xing, Wei Mao, and Miaomiao Liu. Scene- aware human motion forecasting via mutual distance prediction. InECCV, 2024
2024
-
[59]
Decoupling human and camera motion from videos in the wild
Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa. Decoupling human and camera motion from videos in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2023
2023
-
[60]
Learning motion priors for 4d human body capture in 3d scenes
Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys, and Siyu Tang. Learning motion priors for 4d human body capture in 3d scenes. InInternational Conference on Computer Vision (ICCV), October 2021
2021
-
[61]
Probabilistic human mesh recovery in 3d scenes from egocentric views
Siwei Zhang, Qianli Ma, Yan Zhang, Sadegh Aliakbar- ian, Darren Cosker, and Siyu Tang. Probabilistic human mesh recovery in 3d scenes from egocentric views. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[62]
RoHM: Robust human motion reconstruction via diffusion
Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexan- der Winkler, Petr Kadlecek, Siyu Tang, and Federica Bogo. RoHM: Robust human motion reconstruction via diffusion. InCVPR, 2024
2024
-
[63]
3d-aware neural body fitting for occlusion robust 3d human pose estimation
Yi Zhang, Pengliang Ji, Angtian Wang, Jieru Mei, Adam Kortylewski, and Alan L Yuille. 3d-aware neural body fitting for occlusion robust 3d human pose estimation. ICCV, 2023
2023
-
[64]
GIMO: Gaze-informed human motion prediction in con- text.arXiv preprint arXiv:2204.09443, 2022
Yang Zheng, Yanchao Yang, Kaichun Mo, Jiaman Li, Tao Yu, Yebin Liu, Karen Liu, and Leonidas J Guibas. GIMO: Gaze-informed human motion prediction in con- text.arXiv preprint arXiv:2204.09443, 2022. HumanFlow – Supplementary Material I. MODELARCHITECTURES A. Human Motion Model Autoencoder.Before encoding, the input is flattened along the joint dimension an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.