Latent Representation Alignment for Offline Goal-Conditioned Reinforcement Learning
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
Aligning latent representations corrects erroneous generalization in goal-conditioned value functions for offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
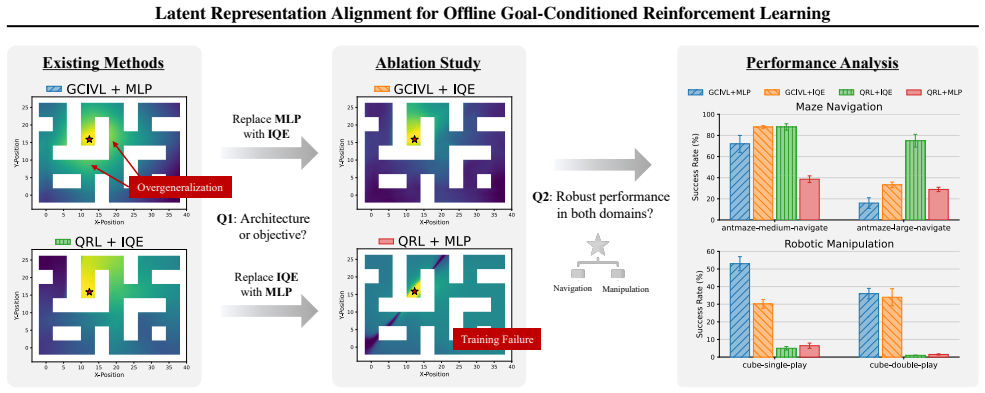
The paper establishes that erroneous generalization in goal-conditioned value functions is the fundamental bottleneck in offline GCRL, and that latent-representation-based value generalization supplies the necessary inductive bias; when integrated with hierarchical planning inside LAVL, this produces effective goal-reaching policies from static datasets.
What carries the argument
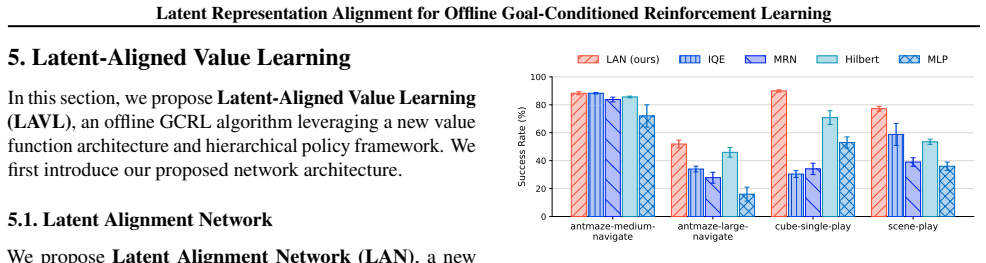
Latent-Aligned Value Learning (LAVL), which aligns latent representations for improved value generalization while performing hierarchical planning.
If this is right
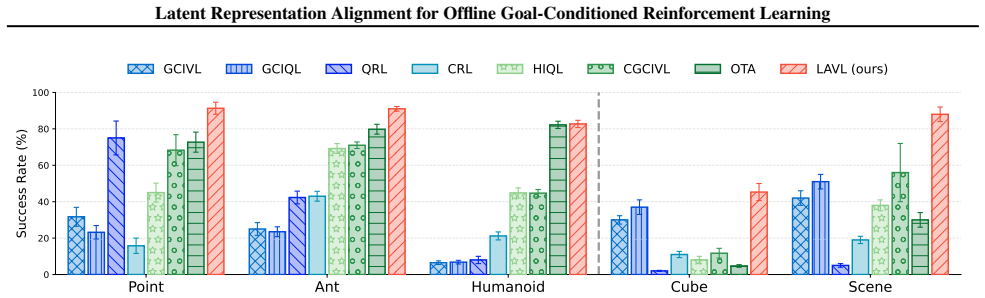
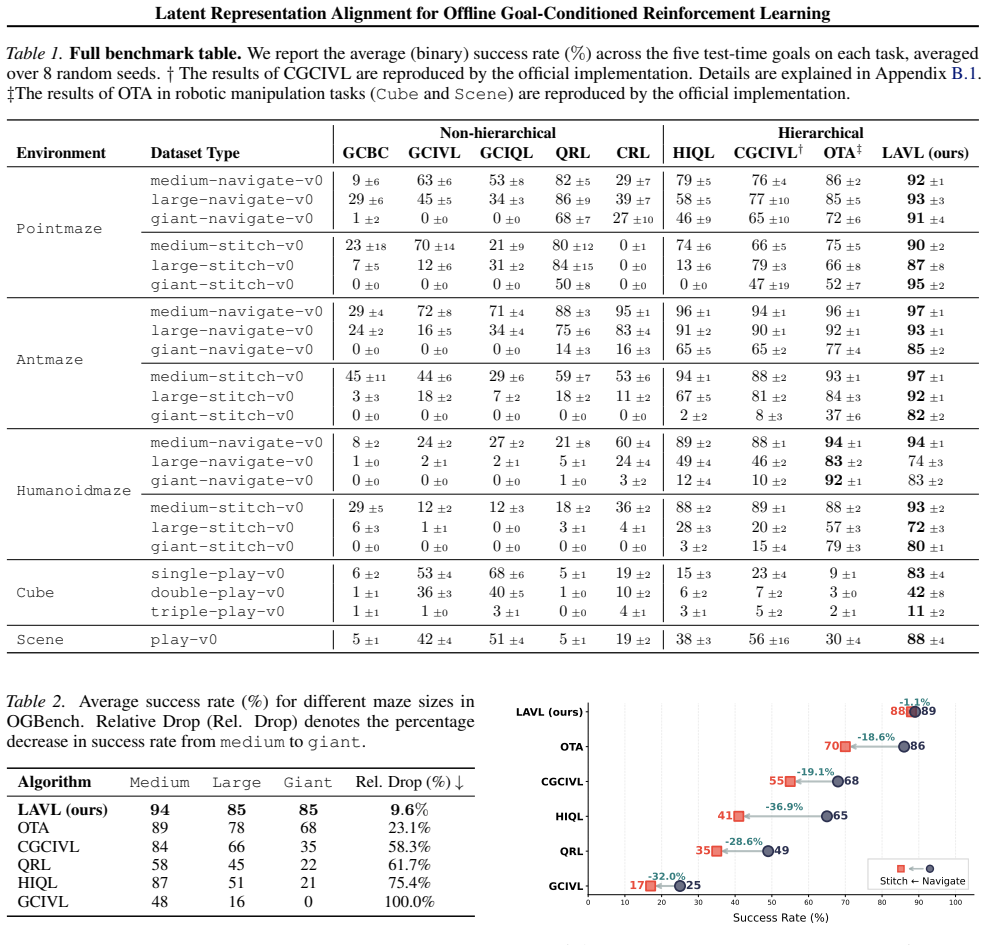
- LAVL achieves the highest score on 20 out of 22 OGBench datasets.
- LAVL maintains performance on long-horizon tasks where existing methods degrade sharply.
- LAVL handles trajectory stitching datasets effectively, enabling reuse of disconnected data segments.
- The method unifies latent alignment and hierarchical planning for offline goal-conditioned learning.
Where Pith is reading between the lines
- The alignment technique could be tested in online goal-conditioned settings to check whether the same bias helps when new data can be collected.
- Representation alignment may reduce reliance on perfectly diverse offline datasets by improving generalization from sparser coverage.
- Hierarchical planning paired with alignment might extend to other sparse-reward domains where value estimation over long sequences is unreliable.
Load-bearing premise
That erroneous generalization in the value function is the core bottleneck and that latent representation alignment supplies sufficient inductive bias to overcome it in long-horizon settings.
What would settle it
A controlled test on OGBench long-horizon trajectory-stitching datasets in which LAVL fails to outperform prior offline GCRL methods would falsify the claim that the alignment supplies the required bias.
Figures
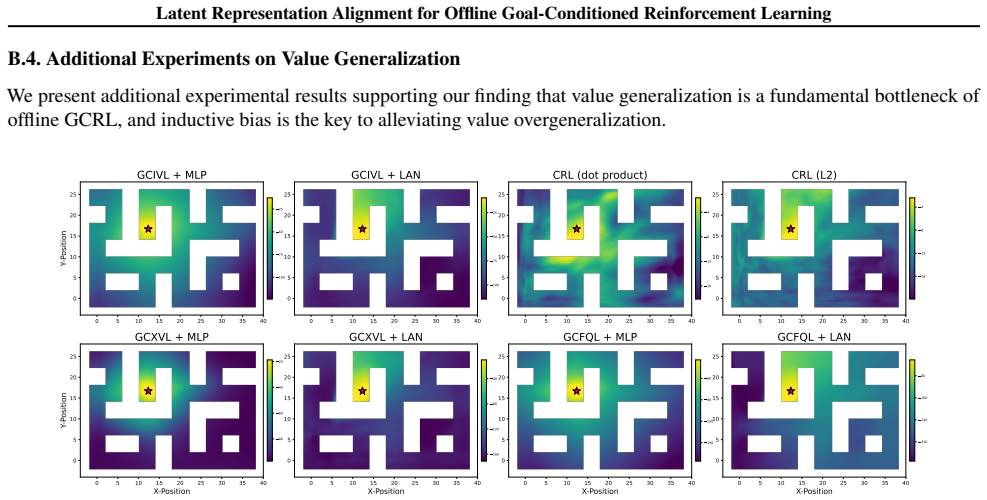
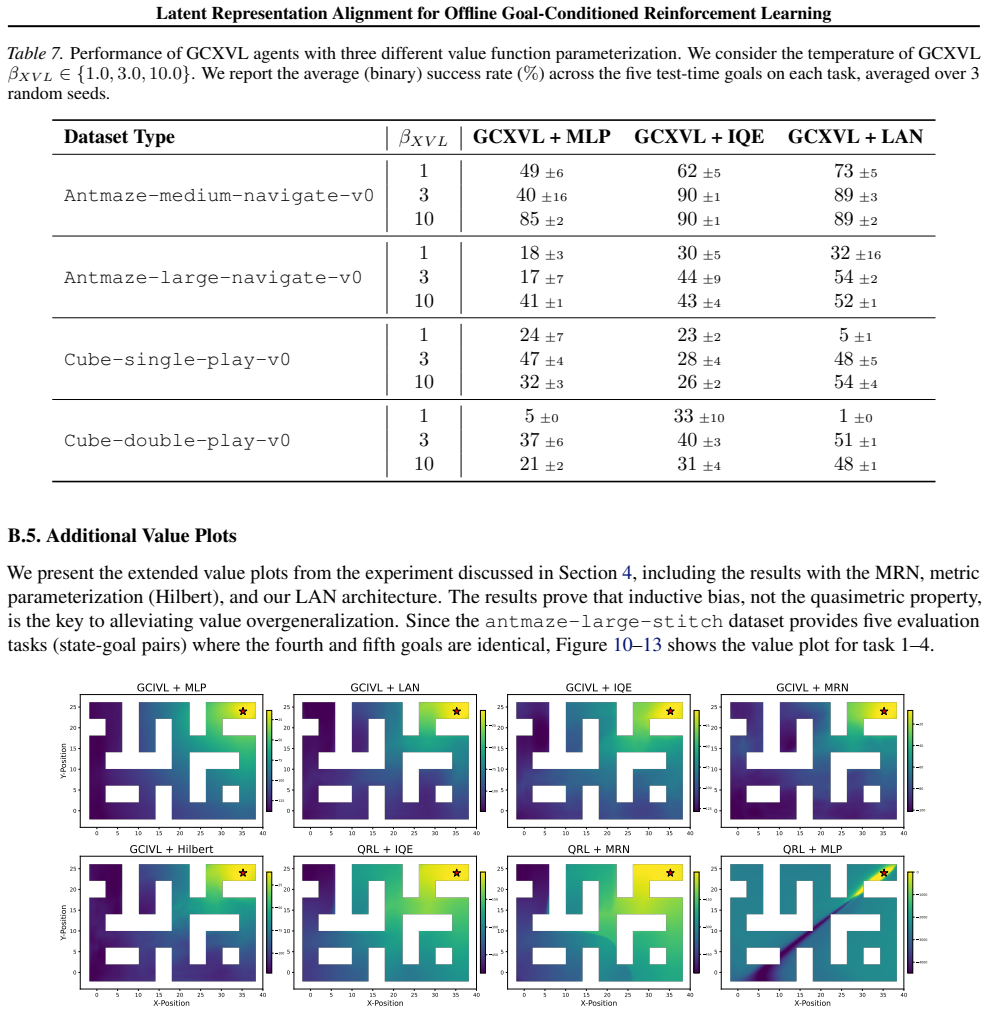
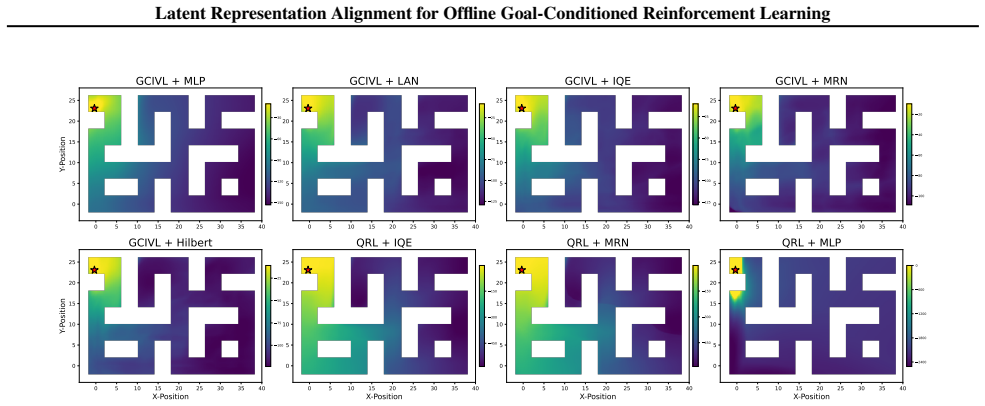
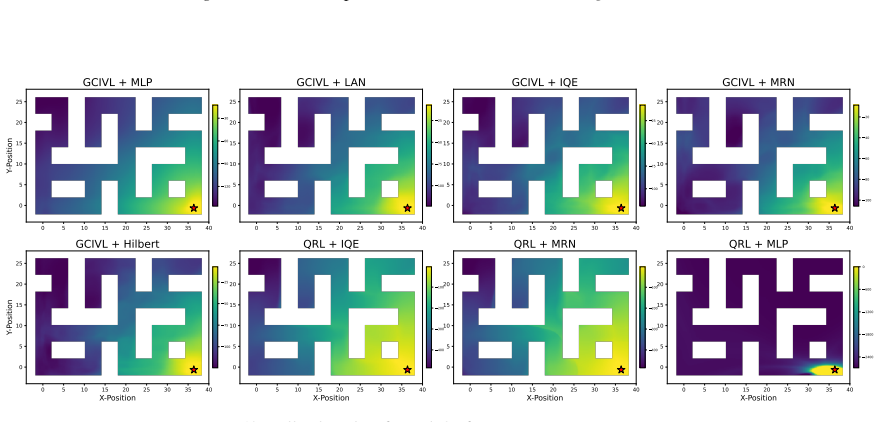
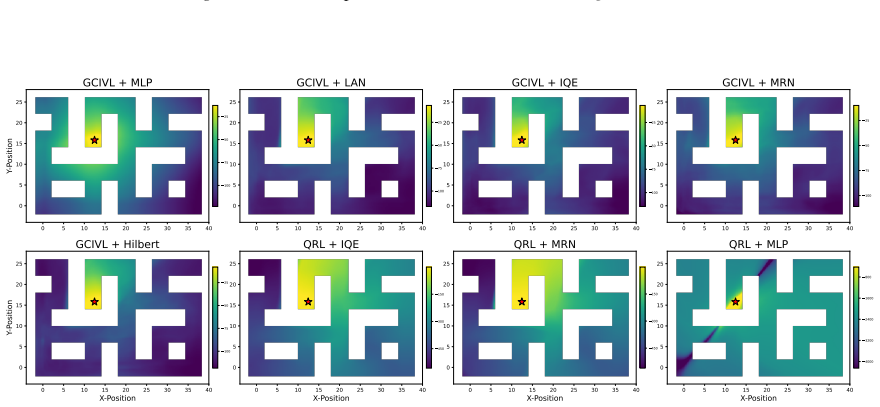
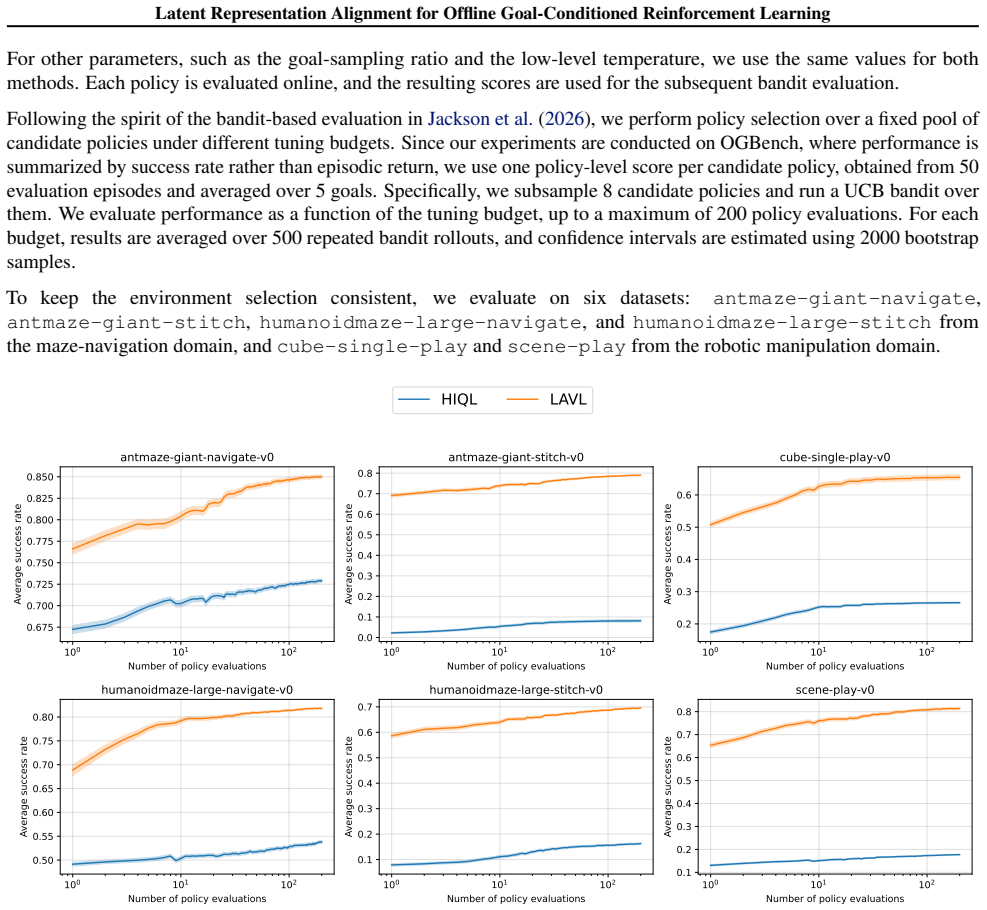
read the original abstract
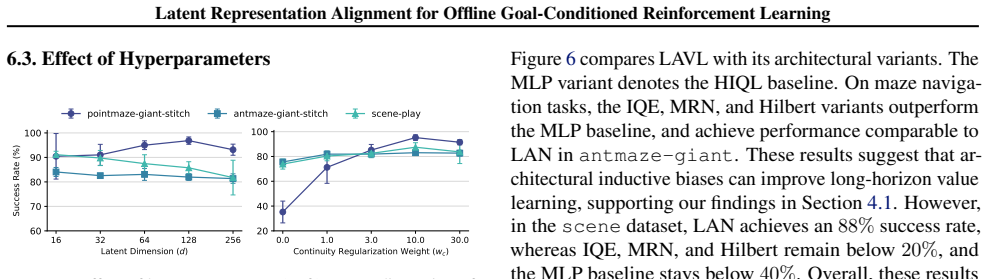
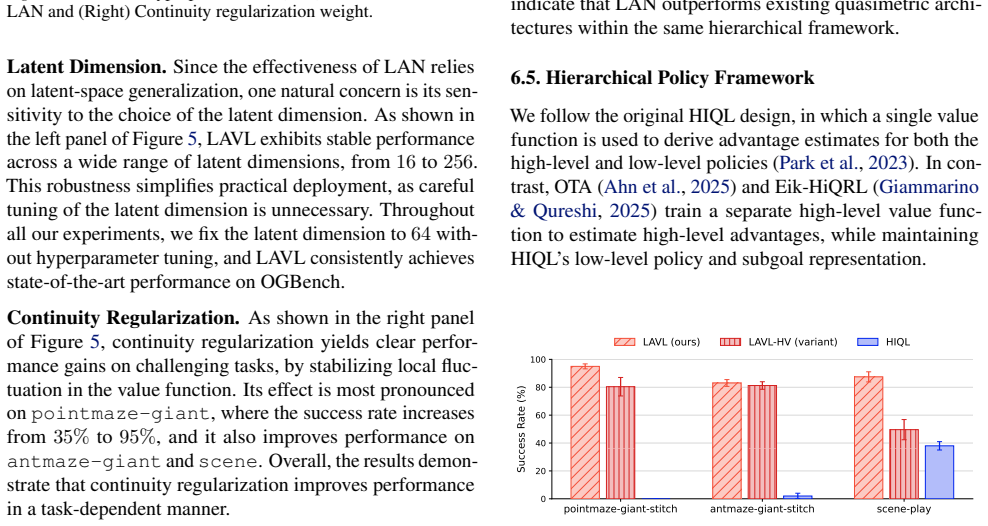
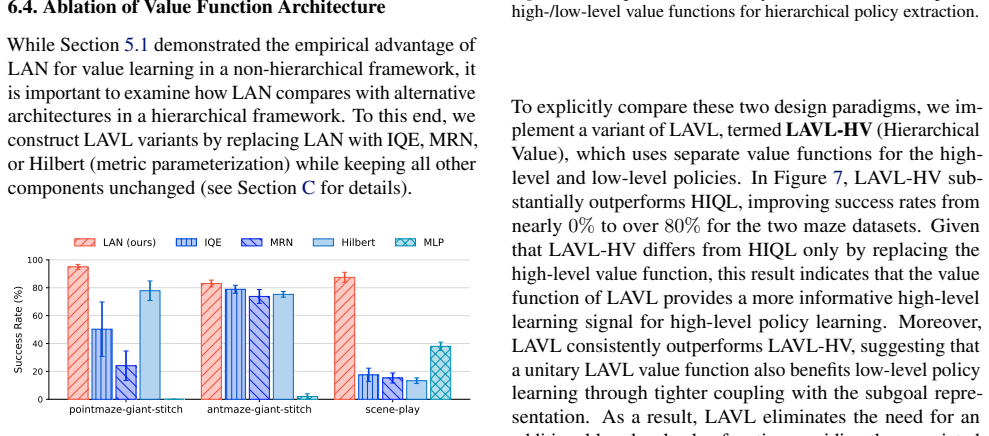
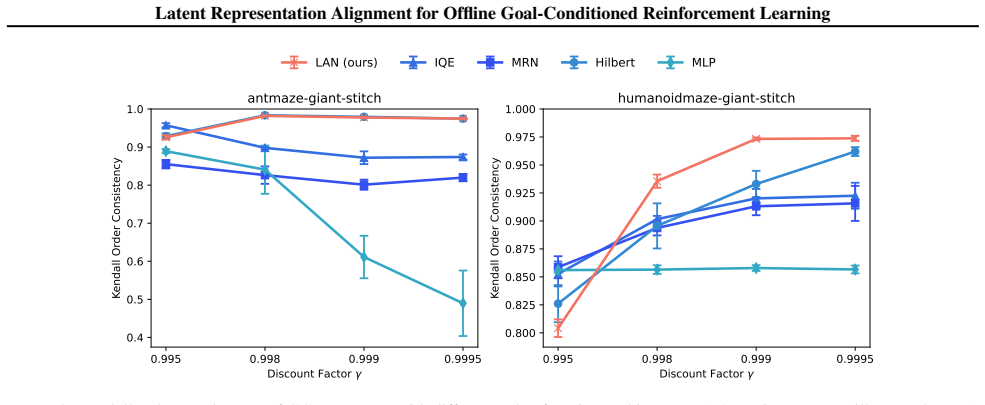
Offline goal-conditioned reinforcement learning (GCRL) provides a practical framework for obtaining goal-reaching policies from fixed datasets. However, learning a reliable goal-conditioned value function in long-horizon tasks remains challenging. In this paper, we identify erroneous generalization in goal-conditioned value functions as a fundamental bottleneck, and demonstrate that appropriate inductive bias in the value function is crucial for addressing the bottleneck. Building on these findings, we propose Latent-Aligned Value Learning (LAVL), an offline GCRL algorithm that integrates latent-representation-based value generalization with hierarchical planning in a unified framework. Extensive experiments on OGBench demonstrate that LAVL consistently outperforms existing offline GCRL methods, achieving the highest performance on 20 out of 22 datasets. Notably, LAVL exhibits strong performance in long-horizon tasks and trajectory stitching datasets, where prior methods suffer significant performance degradation. Our code is available at https://github.com/oh-lab/LAVL.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies erroneous generalization in goal-conditioned value functions as the core bottleneck for offline GCRL on long-horizon tasks. It proposes Latent-Aligned Value Learning (LAVL), a unified algorithm that combines latent-representation alignment for value generalization with hierarchical planning. Experiments on the OGBench benchmark show LAVL achieving the highest performance on 20 of 22 datasets, with particular gains on long-horizon and trajectory-stitching regimes where prior methods degrade.
Significance. If the reported performance ordering holds under the stated experimental protocol, the work supplies a concrete inductive bias (latent alignment) that demonstrably improves value generalization in offline GCRL. The public code release at https://github.com/oh-lab/LAVL.git is a clear strength that enables direct reproduction and extension.
minor comments (3)
- The abstract states that LAVL 'integrates latent-representation-based value generalization with hierarchical planning in a unified framework,' but the precise interface between the latent value head and the planner (e.g., whether the planner uses the aligned value estimates directly or only for subgoal selection) is not summarized; a one-sentence clarification would help readers.
- Table captions and axis labels in the experimental section use inconsistent abbreviations for the 22 datasets; expanding the first occurrence of each acronym in the caption would improve readability.
- The related-work section cites several offline GCRL baselines but does not explicitly contrast the latent-alignment objective with the contrastive or reconstruction losses used in prior representation-learning approaches for GCRL; a short paragraph would sharpen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work, the recognition of the core contribution on erroneous generalization in goal-conditioned value functions, and the recommendation for minor revision. We are pleased that the empirical gains on long-horizon and trajectory-stitching regimes in OGBench are viewed as a strength, along with the public code release.
Circularity Check
No significant circularity
full rationale
The paper is an empirical contribution proposing the LAVL algorithm for offline GCRL and reporting performance on 22 OGBench datasets. Its central claims rest on experimental results rather than a mathematical derivation chain. No equations, predictions, or first-principles results are shown to reduce by construction to fitted parameters or self-citations within the paper. The method description and empirical evaluation are self-contained against external benchmarks, with no load-bearing self-citation or renaming of known results as novel derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
URL https://openreview.net/forum? id=gfXBNBKx02. Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Pieter Abbeel, O., and Zaremba, W. Hindsight experience replay.Advances in neural information processing systems, 30, 2017. Chane-Sane, E., Schmid, C., and Laptev, I. Goal- conditioned reinforcement learning...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Gaussian Error Linear Units (GELUs)
URL https://openreview.net/forum? id=LRYgQuz7kY. 9 Latent Representation Alignment for Offline Goal-Conditioned Reinforcement Learning G¨urtler, N., B¨uchler, D., and Martius, G. Hierarchical re- inforcement learning with timed subgoals.Advances in Neural Information Processing Systems, 34:21732– 21743, 2021. Hendrycks, D. Gaussian error linear units (gel...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
URL https://openreview.net/forum? id=P23UMiw7iJ. Nachum, O., Gu, S. S., Lee, H., and Levine, S. Data-efficient hierarchical reinforcement learning.Advances in neural information processing systems, 31, 2018. Nair, S. and Finn, C. Hierarchical foresight: Self-supervised learning of long-horizon tasks via visual subgoal genera- tion. InInternational Confere...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Zhang, L., Yang, G., and Stadie, B
URL https://openreview.net/forum? id=KJztlfGPdwW. Zhang, L., Yang, G., and Stadie, B. C. World model as a graph: Learning latent landmarks for planning. In International conference on machine learning, pp. 12611– 12620. PMLR, 2021. 11 Latent Representation Alignment for Offline Goal-Conditioned Reinforcement Learning A. Experimental Details A.1. Details o...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.