ParkourFormer: Integrating Predictive Supervision and Sequence Modeling into Parkour Locomotion
Pith reviewed 2026-06-29 21:34 UTC · model grok-4.3
The pith
A Transformer policy with a supervised prediction head for future proprioceptive states achieves 93.85% success on diverse humanoid parkour terrains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
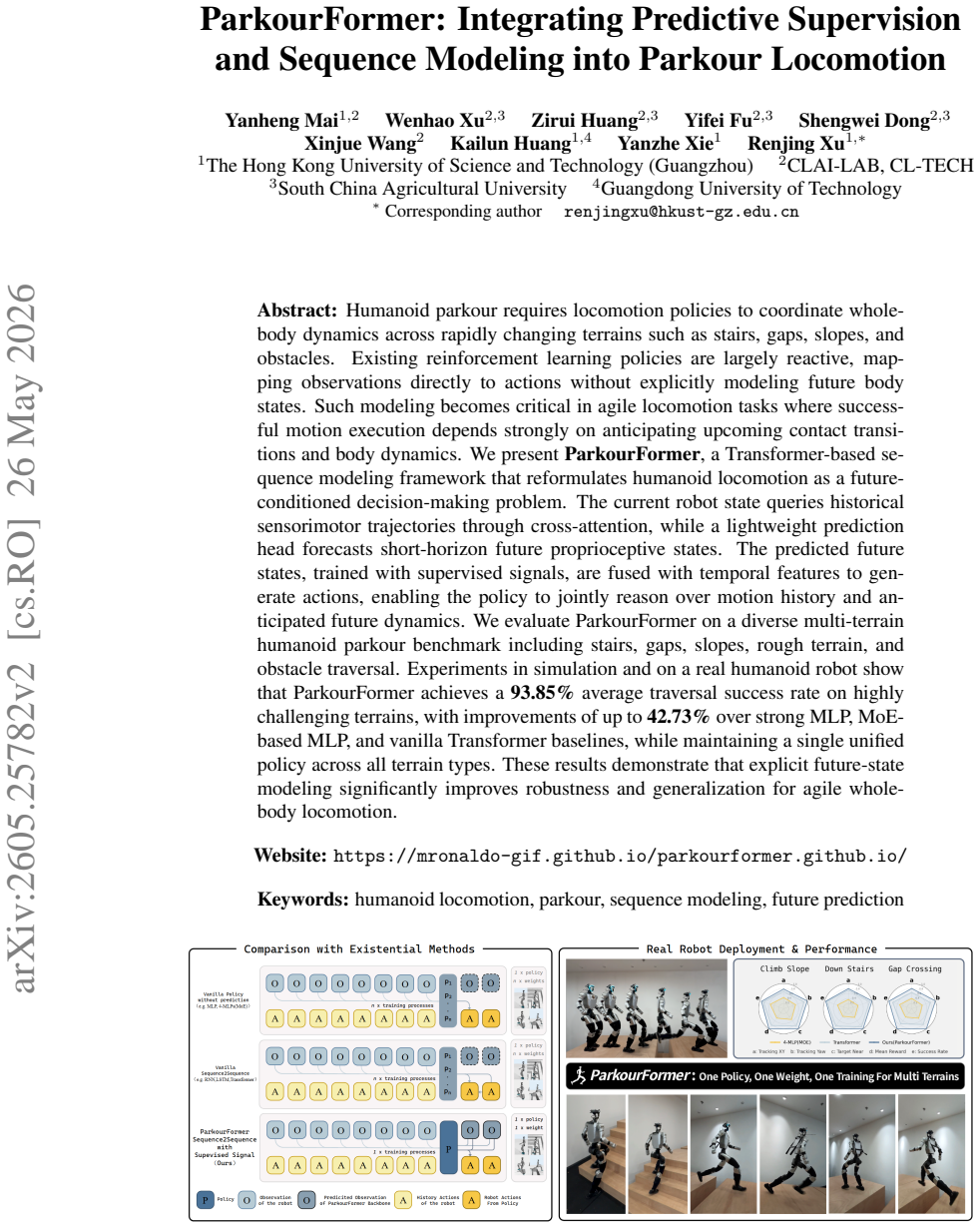
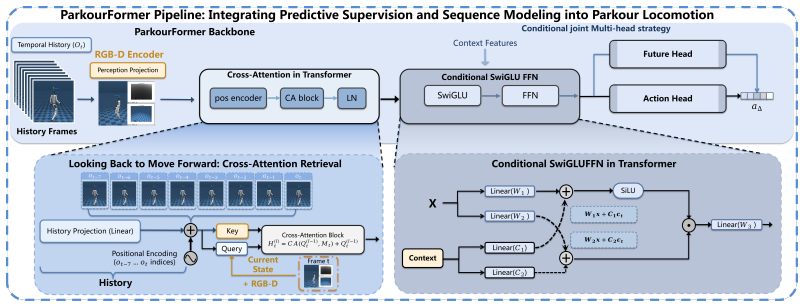
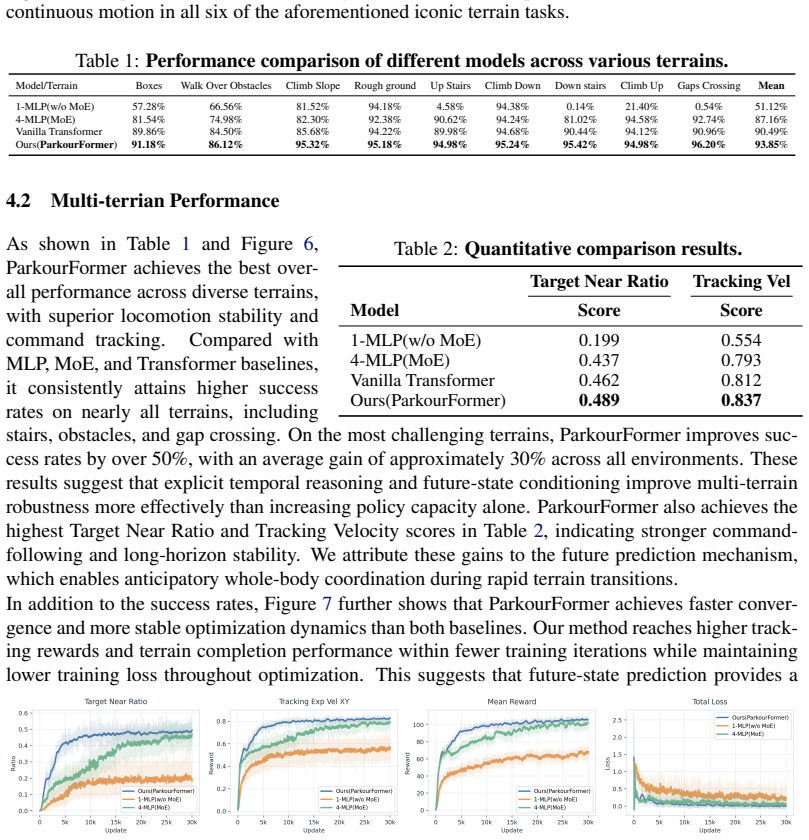
ParkourFormer reformulates humanoid locomotion as a future-conditioned decision-making problem. The current robot state queries historical sensorimotor trajectories through cross-attention, while a lightweight prediction head forecasts short-horizon future proprioceptive states. The predicted future states, trained with supervised signals, are fused with temporal features to generate actions, enabling the policy to jointly reason over motion history and anticipated future dynamics. Experiments show 93.85% average traversal success on a multi-terrain benchmark with up to 42.73% improvement over MLP, MoE-MLP, and vanilla Transformer baselines in simulation and on a real humanoid robot.
What carries the argument
Transformer cross-attention over historical trajectories combined with a supervised lightweight prediction head that forecasts short-horizon proprioceptive states and fuses them into action generation.
If this is right
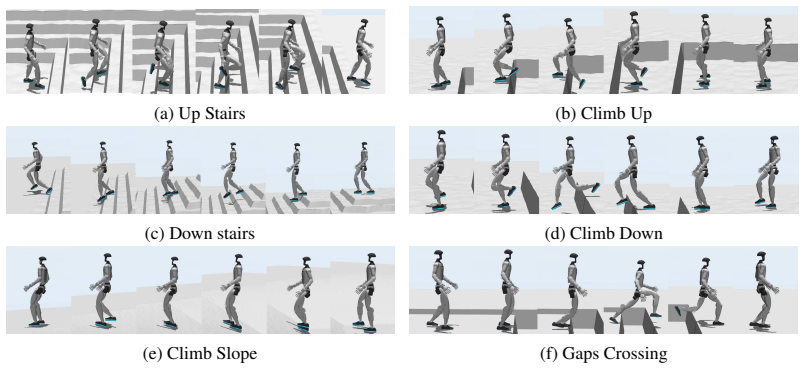
- A single policy can traverse stairs, gaps, slopes, rough terrain, and obstacles without per-terrain specialization.
- Robustness and generalization improve for agile whole-body locomotion in both simulation and real-robot tests.
- Explicit future-state modeling outperforms purely reactive approaches including MLP, MoE-based MLP, and vanilla Transformer policies.
- Supervised prediction of short-horizon proprioceptive states can be integrated into sequence models for decision making without requiring terrain-specific retraining.
Where Pith is reading between the lines
- If prediction accuracy were measured independently, the results could clarify how much of the performance lift comes from accurate forecasts versus the attention architecture itself.
- The same future-conditioning pattern could apply to other dynamic control problems where anticipation of body or contact states matters, such as object manipulation under uncertainty.
- Comparing the method against baselines that receive the same future information through different fusion mechanisms would isolate the contribution of the supervised head.
Load-bearing premise
That fusing outputs from the supervised future-state prediction head with temporal features will produce measurably better actions than reactive baselines, without separate checks that the predictions are accurate or causally responsible for the gains.
What would settle it
An ablation that removes the prediction head while keeping the rest of the Transformer architecture identical, then measures whether success rates on the multi-terrain benchmark drop by a comparable margin to the reported improvements.
Figures



read the original abstract
Humanoid parkour requires locomotion policies to coordinate whole-body dynamics across rapidly changing terrains such as stairs, gaps, slopes, and obstacles. Existing reinforcement learning policies are largely reactive, mapping observations directly to actions without explicitly modeling future body states. Such modeling becomes critical in agile locomotion tasks where successful motion execution depends strongly on anticipating upcoming contact transitions and body dynamics. We present ParkourFormer, a Transformer-based sequence modeling framework that reformulates humanoid locomotion as a future-conditioned decision-making problem. The current robot state queries historical sensorimotor trajectories through cross-attention, while a lightweight prediction head forecasts short-horizon future proprioceptive states. The predicted future states, trained with supervised signals, are fused with temporal features to generate actions, enabling the policy to jointly reason over motion history and anticipated future dynamics. We evaluate ParkourFormer on a diverse multi-terrain humanoid parkour benchmark including stairs, gaps, slopes, rough terrain, and obstacle traversal. Experiments in simulation and on a real humanoid robot show that ParkourFormer achieves a 93.85% average traversal success rate on highly challenging terrains, with improvements of up to 42.73% over strong MLP, MoE-based MLP, and vanilla Transformer baselines, while maintaining a single unified policy across all terrain types. These results demonstrate that explicit future-state modeling significantly improves robustness and generalization for agile whole-body locomotion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ParkourFormer, a Transformer-based sequence modeling framework for humanoid parkour locomotion. It reformulates the task as future-conditioned decision making by using cross-attention over historical trajectories and a lightweight supervised prediction head that forecasts short-horizon proprioceptive states; these predictions are fused to produce actions. The work evaluates a single unified policy on a multi-terrain benchmark (stairs, gaps, slopes, rough terrain, obstacles) and reports a 93.85% average traversal success rate in simulation and on hardware, with gains of up to 42.73% relative to MLP, MoE-MLP, and vanilla Transformer baselines.
Significance. If the causal contribution of the predictive supervision is established, the result would strengthen the case for explicit short-horizon future-state modeling inside sequence-based policies for agile whole-body control. The single unified policy across heterogeneous terrains is a concrete practical advantage over terrain-specific reactive policies.
major comments (2)
- [Experiments] The central claim that explicit future-state modeling via the supervised prediction head drives the reported gains (up to 42.73% over the vanilla Transformer) is not supported by the required evidence. No ablation is presented that removes or corrupts the prediction head while holding the rest of the Transformer architecture fixed, and no quantitative prediction-error metrics (e.g., per-joint MSE or contact-timing error on a validation split) are reported. Without these, the performance delta cannot be attributed to forecast accuracy rather than extra capacity or training dynamics.
- [Experiments] The manuscript provides no comparison of policy performance when ground-truth future states are substituted for the learned predictions. Such an oracle experiment would directly test whether the quality of the forecasts is causally responsible for the robustness improvements claimed in the abstract.
minor comments (2)
- Training procedure, loss weights for the supervised prediction head, and baseline implementation details (network sizes, training budgets) are not specified, preventing reproduction of the exact performance deltas.
- Results lack error bars or statistical significance tests across random seeds, which is especially important given the large reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key gaps in experimental validation. We address each point below and will revise the manuscript accordingly by adding the requested experiments and metrics.
read point-by-point responses
-
Referee: The central claim that explicit future-state modeling via the supervised prediction head drives the reported gains (up to 42.73% over the vanilla Transformer) is not supported by the required evidence. No ablation is presented that removes or corrupts the prediction head while holding the rest of the Transformer architecture fixed, and no quantitative prediction-error metrics (e.g., per-joint MSE or contact-timing error on a validation split) are reported. Without these, the performance delta cannot be attributed to forecast accuracy rather than extra capacity or training dynamics.
Authors: We agree that the current evidence does not fully isolate the contribution of the prediction head. In the revised manuscript we will add an ablation that removes the prediction head (or replaces its outputs with noise/random values) while freezing all other architectural components and training hyperparameters. We will also report quantitative prediction metrics including per-joint MSE and contact-timing error on a held-out validation split to demonstrate forecast accuracy. revision: yes
-
Referee: The manuscript provides no comparison of policy performance when ground-truth future states are substituted for the learned predictions. Such an oracle experiment would directly test whether the quality of the forecasts is causally responsible for the robustness improvements claimed in the abstract.
Authors: We acknowledge the value of an oracle baseline. In the revision we will run the requested experiment by substituting ground-truth future proprioceptive states for the learned predictions at inference time and report the resulting success rates across all terrains. This will directly quantify the performance gap attributable to prediction quality. revision: yes
Circularity Check
No circularity; architecture uses standard supervised prediction without self-referential reduction
full rationale
The described framework trains a lightweight prediction head via supervised signals on short-horizon proprioceptive states and fuses the outputs through cross-attention in a Transformer policy. No equations, fitted parameters, or self-citations are shown that would make any claimed prediction equivalent to its inputs by construction. Performance gains are presented as empirical results on a benchmark, not as a derivation that collapses to tautology. The approach is self-contained as a conventional predictive RL design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbabu, C. Pan, Z. Yi, G. Qu, K. Kitani, J. K. Hodgins, L. Fan, Y . Zhu, C. Liu, and G. Shi. ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills. In Proceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10. 15607...
2025
-
[2]
Hwangbo, J
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learn- ing agile and dynamic motor skills for legged robots.Science robotics, 4(26):eaau5872, 2019
2019
- [3]
-
[4]
S. Choi, G. Ji, J. Park, H. Kim, J. Mun, J. H. Lee, and J. Hwangbo. Learning quadrupedal locomotion on deformable terrain.Science Robotics, 8(74):eade2256, 2023
2023
-
[5]
Van Marum, A
B. Van Marum, A. Shrestha, H. Duan, P. Dugar, J. Dao, and A. Fern. Revisiting reward design and evaluation for robust humanoid standing and walking. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11256–11263. IEEE, 2024
2024
-
[6]
Zhang, N
C. Zhang, N. Rudin, D. Hoeller, and M. Hutter. Learning agile locomotion on risky terrains. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11864–11871. IEEE, 2024
2024
-
[7]
Holmes, R
P. Holmes, R. J. Full, D. E. Koditschek, and J. Guckenheimer. The dynamics of legged loco- motion: Models, analyses, and challenges.SIAM Review, 48(2):207–304, 2006
2006
-
[8]
Meduri, P
A. Meduri, P. Shah, J. Viereck, M. Khadiv, I. Havoutis, and L. Righetti. Biconmp: A nonlinear model predictive control framework for whole body motion planning.Robotics, IEEE Trans. on (T-RO), 39(2):18, 2023
2023
-
[9]
Farshidian, E
F. Farshidian, E. Jelavi, A. W. Winkler, and J. Buchli. Robust whole-body motion control of legged robots.IEEE, 2017
2017
-
[10]
D. Kim, S. J. Jorgensen, J. Lee, J. Ahn, J. Luo, and L. Sentis. Dynamic locomotion for passive- ankle biped robots and humanoids using whole-body locomotion control.The International Journal of Robotics Research, 39(8):936–956, 2020
2020
-
[11]
Sleiman, F
J.-P. Sleiman, F. Farshidian, M. V . Minniti, and M. Hutter. A unified mpc framework for whole-body dynamic locomotion and manipulation.IEEE Robotics and Automation Letters, 6 (3):4688–4695, 2021
2021
-
[12]
A. W. Winkler, C. D. Bellicoso, M. Hutter, and J. Buchli. Gait and trajectory optimization for legged systems through phase-based end-effector parameterization.IEEE Robotics and Automation Letters, 3(3):1560–1567, 2018
2018
-
[13]
Hochreiter and J
S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural computation, 9(8):1735– 1780, 1997
1997
-
[14]
J. L. Elman. Finding structure in time.Cognitive science, 14(2):179–211, 1990
1990
-
[15]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 9
2017
-
[16]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
2021
-
[17]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[18]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
M. Schwarzer, A. Anand, R. Goel, R. D. Hjelm, A. Courville, and P. Bachman. Data-efficient reinforcement learning with self-predictive representations.arXiv preprint arXiv:2007.05929, 2020
-
[20]
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler. Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters.ACM Transactions On Graphics (TOG), 41(4):1–17, 2022
2022
- [21]
- [22]
-
[23]
Radosavovic, B
I. Radosavovic, B. Zhang, B. Shi, J. Rajasegaran, S. Kamat, T. Darrell, K. Sreenath, and J. Ma- lik. Humanoid locomotion as next token prediction.Advances in neural information processing systems, 37:79307–79324, 2024
2024
-
[24]
K. Caluwaerts, A. Iscen, J. C. Kew, W. Yu, T. Zhang, D. Freeman, K.-H. Lee, L. Lee, S. Sal- iceti, V . Zhuang, et al. Barkour: Benchmarking animal-level agility with quadruped robots. arXiv preprint arXiv:2305.14654, 2023
-
[25]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. InConference on Robot Learning (CoRL), 2023
2023
-
[26]
Hoeller, N
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. Anymal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88), 2024
2024
-
[27]
Quadruped Parkour Learning: Sparsely Gated Mixture of Experts with Visual Input
M. Ziegltrum, J. Jiao, T. Peng, C. Zhou, and D. Kanoulas. Quadruped parkour learning: Sparsely gated mixture of experts with visual input.arXiv preprint arXiv:2604.19344, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991
1991
-
[29]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomo- tion over challenging terrain.Science robotics, 5(47):eabc5986, 2020
2020
-
[30]
J. Long, Z. Wang, Q. Li, L. Cao, J. Gao, and J. Pang. Hybrid internal model: Learning agile legged locomotion with simulated robot response. InInternational Conference on Learning Representations, volume 2024, pages 14084–14100, 2024
2024
-
[31]
RMA: Rapid Motor Adaptation for Legged Robots
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. arXiv preprint arXiv:2107.04034, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust percep- tive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022. 10
2022
-
[33]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9997–10003. IEEE, 2025
2025
-
[34]
H. Song, H. Zhu, T. Yu, Y . Liu, M. Yuan, W. Zhou, H. Chen, and H. Li. Gait-adaptive per- ceptive humanoid locomotion with real-time under-base terrain reconstruction.IEEE Robotics and Automation Letters, 2026
2026
-
[35]
H. Lai, W. Zhang, X. He, C. Yu, Z. Tian, Y . Yu, and J. Wang. Sim-to-real transfer for quadrupedal locomotion via terrain transformer. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5141–5147. IEEE, 2023
2023
-
[36]
Cheng, K
X. Cheng, K. Shi, A. Agarwal, and D. Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450. IEEE, 2024
2024
- [37]
-
[38]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[40]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.