PixelWizard: Towards Efficient High-Fidelity Video Generation at Ultra-Large Spatial Resolution
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
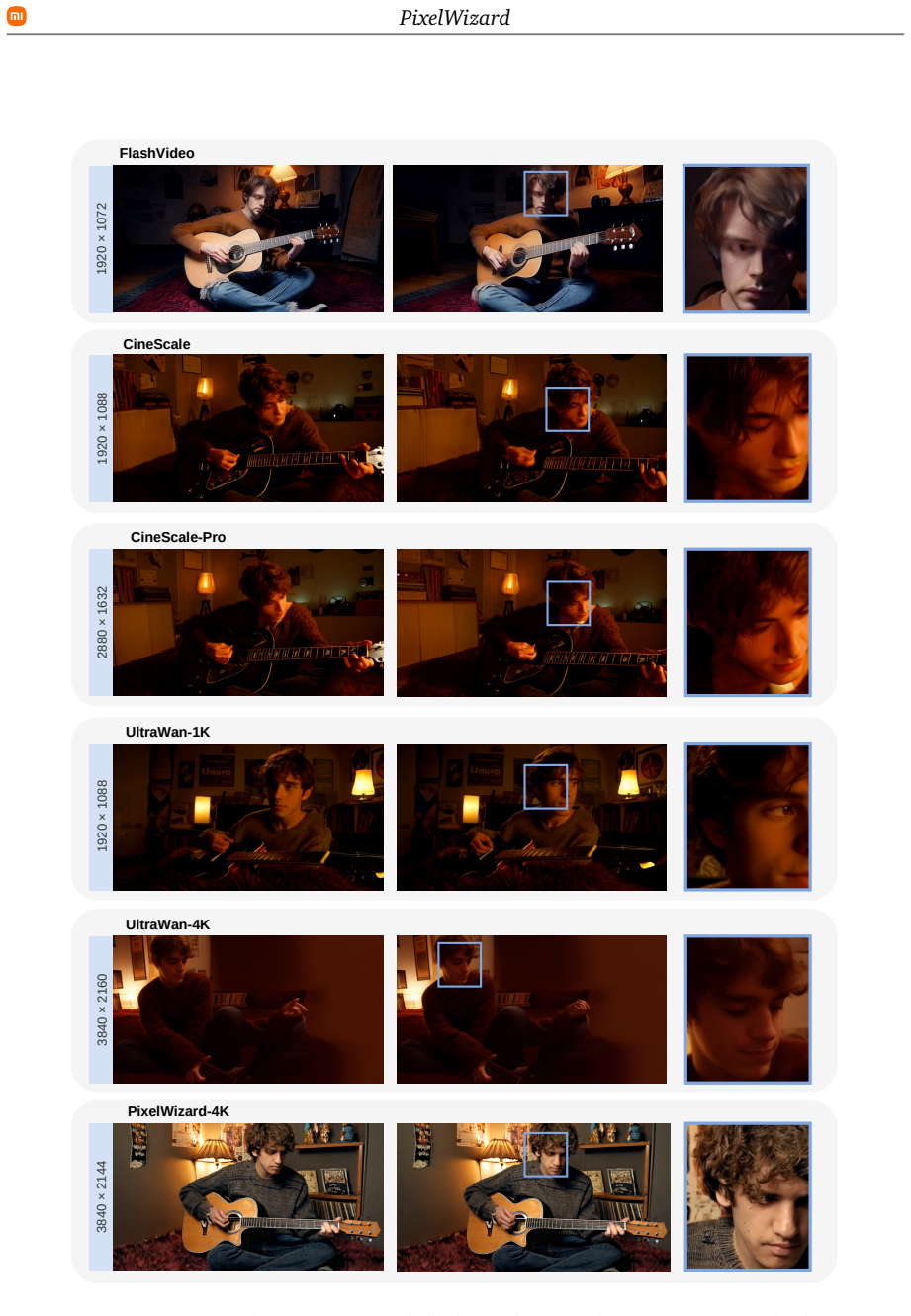
PixelWizard decouples global structure from local details to enable over 10x faster generation of native 2K and 4K videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
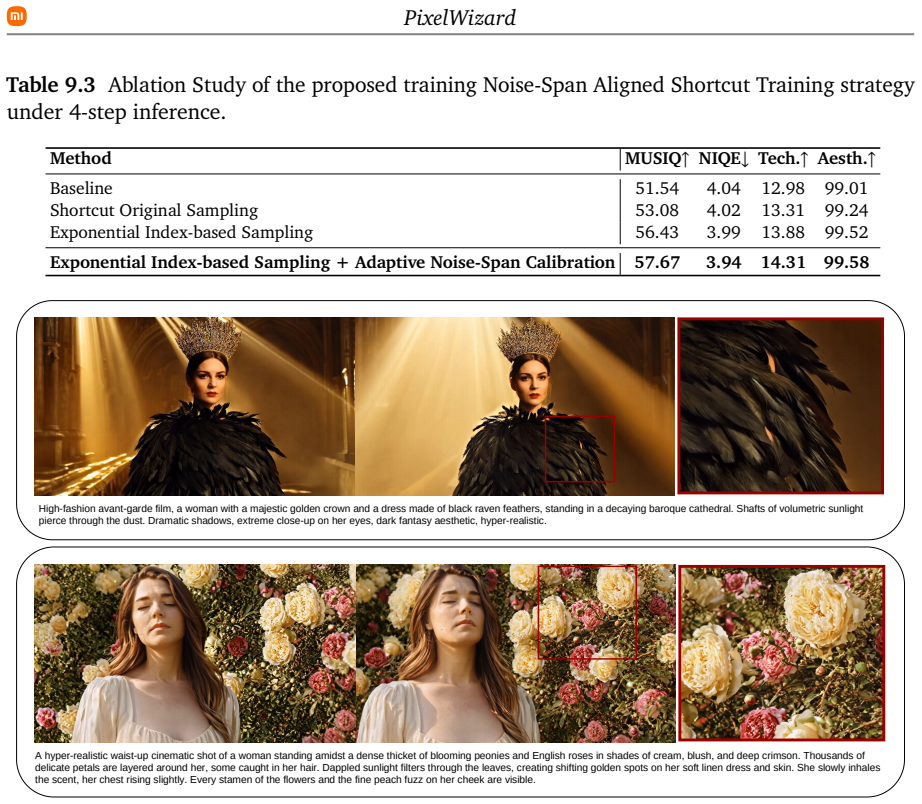
PixelWizard hierarchically decouples global structure modeling from fine-grained detail synthesis. It establishes a compact spatiotemporal anchor to concentrate dense structural priors which then guides fine-grained generation at high resolution to mitigate local optimization bias. Leveraging this, Noise-Span Aligned Shortcut Training with Exponential Index-Biased Sampling and Adaptive Noise-Span Calibration enables the model to traverse the generation trajectory with large steps for robust few-step inference, resulting in superior visual quality and over 10x acceleration for native 2K/4K videos.
What carries the argument
Compact spatiotemporal anchor for concentrating structural priors to guide high-resolution generation, combined with Noise-Span Aligned Shortcut Training for large-step inference.
If this is right
- High-resolution video generation avoids structural collapse from local texture bias.
- Generative sampling for 2K and 4K videos accelerates by over 10 times.
- Few-step inference becomes robust without the need for heavy distillation techniques.
- High-frequency details remain preserved while maintaining structural stability.
Where Pith is reading between the lines
- This hierarchical decoupling could be tested on other high-dimensional generation tasks like 3D scenes.
- The sampling alignment methods may reduce training time in related diffusion models.
- Applications in real-time video synthesis become more feasible if the speedup holds across datasets.
Load-bearing premise
That a compact spatiotemporal anchor can reliably concentrate dense structural priors to guide fine-grained high-resolution generation without introducing new instabilities or losing high-frequency details.
What would settle it
Conducting inference on 4K video generation and finding that the speedup falls below 10x or that quality metrics are lower than standard methods.
Figures












read the original abstract
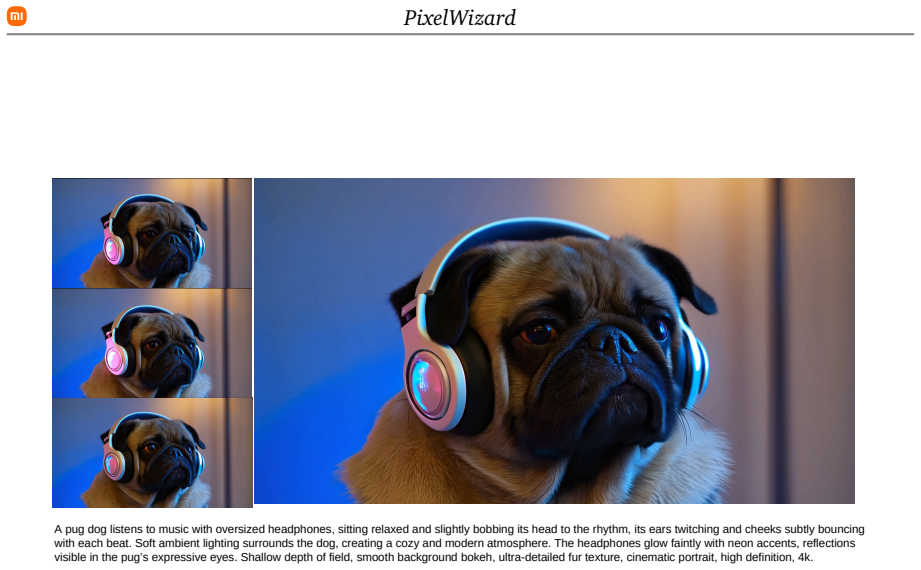
High-resolution video generation faces a coupled bottleneck of optimization instability and prohibitive computational costs. The massive expansion of the token sequence not only biases optimization toward local textures at the expense of global coherence, leading to structural collapse, but also imposes prohibitive training costs and severe inference latency. To address this, we propose PixelWizard, a framework that hierarchically decouples global structure modeling from fine-grained detail synthesis. PixelWizard first establishes a compact spatiotemporal anchor to concentrate dense structural priors, which then guides fine-grained generation at high resolution. This mitigates the local optimization bias to ensure structural stability without compromising high-frequency details. Leveraging this structural stability, we introduce Noise-Span Aligned Shortcut Training to break the inference bottleneck. By explicitly modeling the step size, this mechanism allows the model to traverse the generation trajectory with large steps. Crucially, we incorporate Exponential Index-Biased Sampling and Adaptive Noise-Span Calibration to align optimization with the shifted noise schedules of high-resolution grids, ensuring robust few-step inference without incurring the heavy overhead of distillation. Extensive experiments demonstrate that PixelWizard achieves superior visual quality while accelerating the generative sampling of native 2K/4K videos by over 10x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PixelWizard, a framework for efficient high-fidelity video generation at ultra-large spatial resolutions such as 2K and 4K. It hierarchically decouples global structure modeling from fine-grained detail synthesis by establishing a compact spatiotemporal anchor to concentrate structural priors, which guides the high-resolution generation. This is combined with Noise-Span Aligned Shortcut Training, Exponential Index-Biased Sampling, and Adaptive Noise-Span Calibration to enable robust few-step inference, claiming to achieve superior visual quality and over 10x acceleration in generative sampling without distillation.
Significance. If the results hold, the work would be significant for the field of generative AI, particularly in video synthesis, by addressing key bottlenecks in optimization stability and computational efficiency at high resolutions. The approach of using shortcut training without distillation could offer a more efficient alternative to existing methods for few-step generation.
major comments (2)
- [Abstract] Abstract: The central empirical claim that PixelWizard accelerates generative sampling of native 2K/4K videos by over 10x while achieving superior visual quality is not supported by any quantitative results, ablation tables, or experimental details in the provided manuscript text, which prevents verification of the claims.
- [Abstract] Abstract: The description of the compact spatiotemporal anchor states that it 'concentrate[s] dense structural priors' and 'mitigates the local optimization bias,' but provides no mechanism details, scaling analysis, or evidence that it remains stable at ultra-large resolutions without introducing instabilities or losing high-frequency details, which is critical for the hierarchical decoupling to succeed.
minor comments (1)
- [Abstract] Abstract: The abstract mentions 'Extensive experiments demonstrate' but without referencing specific sections or figures where these results are presented.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and outline revisions to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that PixelWizard accelerates generative sampling of native 2K/4K videos by over 10x while achieving superior visual quality is not supported by any quantitative results, ablation tables, or experimental details in the provided manuscript text, which prevents verification of the claims.
Authors: The abstract summarizes the key empirical outcomes from our experiments. The full manuscript contains the supporting quantitative results, including speedup measurements and quality metrics, in the Experiments section along with corresponding tables. To directly address the concern and enable verification from the abstract itself, we will revise the abstract to incorporate specific quantitative highlights (e.g., reported speedup factors and quality metrics) drawn from those experiments. revision: yes
-
Referee: [Abstract] Abstract: The description of the compact spatiotemporal anchor states that it 'concentrate[s] dense structural priors' and 'mitigates the local optimization bias,' but provides no mechanism details, scaling analysis, or evidence that it remains stable at ultra-large resolutions without introducing instabilities or losing high-frequency details, which is critical for the hierarchical decoupling to succeed.
Authors: The abstract provides a high-level overview of the anchor's role. The full manuscript details the mechanism in Section 3, including how the compact spatiotemporal anchor is constructed and its effect on optimization. Scaling behavior and stability at 2K/4K resolutions are examined through experiments and ablations in the main text and appendix. We agree that the abstract would benefit from a concise reference to these elements; we will add a brief clause on the mechanism and stability evidence to the abstract in revision. revision: yes
Circularity Check
No circularity; claims rest on empirical validation of proposed methods
full rationale
The paper advances a hierarchical decoupling architecture (compact spatiotemporal anchor + Noise-Span Aligned Shortcut Training + calibration) whose performance claims—superior 2K/4K quality and >10x few-step sampling—are presented strictly as outcomes of experiments rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the abstract or description; the anchor's role is described as an engineering choice whose stability is asserted via ablation and scaling results, not by construction. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205. 11 PixelWizard
2023
-
[2]
Kling 2.5 Turbo,
Kuaishou Technology, “Kling 2.5 Turbo,” https://app.klingai.com/cn/release-notes/, 2025, accessed: 2025-09-19
2025
-
[3]
Veo 3.1,
Google DeepMind, “Veo 3.1,” https://deepmind.google/technologies/veo/, 2025
2025
-
[4]
OpenAI, “Sora 2,” https://openai.com/sora, 2025
2025
-
[5]
HunyuanVideo 1.5 Technical Report
B. Wu, C. Zou, C. Li, D. Huang, F. Yang, H. Tan, J. Peng, J. Wu, J. Xiong, J. Jianget al., “Hunyuanvideo 1.5 technical report,”arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Y. HaCohen, B. Brazowski, N. Chiprut, Y. Bitterman, A. Kvochko, A. Berkowitz, D. Shalem, D. Lifschitz, D. Moshe, E. Poratet al., “Ltx-2: Efficient joint audio-visual foundation model,” arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Waver: Wave your way to lifelike video generation,
Y. Zhang, H. Yang, Y. Zhang, Y. Hu, F. Zhu, C. Lin, X. Mei, Y. Jiang, B. Peng, and Z. Yuan, “Waver: Wave your way to lifelike video generation,”arXiv preprint arXiv:2508.15761, 2025
-
[8]
LTX-Video: Realtime Video Latent Diffusion
Y. HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richardson, E. Levin, G. Shiran, N. Zabari, O. Gordonet al., “Ltx-video: Realtime video latent diffusion,”arXiv preprint arXiv:2501.00103, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Ultravideo: High-quality uhd video dataset with comprehensive captions,
Z. Xue, J. Zhang, T. Hu, H. He, Y. Chen, Y. Cai, Y. Wang, C. Wang, Y. Liu, X. Li, and D. Tao, “Ultravideo: High-quality uhd video dataset with comprehensive captions,” inNeurIPS, 2025
2025
-
[10]
Ultragen: High-resolution video generation with hierar- chical attention,
T. Hu, J. Zhang, Z. Su, and R. Yi, “Ultragen: High-resolution video generation with hierar- chical attention,”arXiv preprint arXiv:2510.18775, 2025
-
[11]
Y. Wu, J. Song, Z. Tan, Z. He, and S. Liu, “Freeswim: Revisiting sliding-window atten- tion mechanisms for training-free ultra-high-resolution video generation,”arXiv preprint arXiv:2511.14712, 2025
-
[12]
Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion,
H. Qiu, S. Zhang, Y. Wei, R. Chu, H. Yuan, X. Wang, Y. Zhang, and Z. Liu, “Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 16893–16903
2025
-
[13]
Flashvideo: Flowing fidelity to detail for efficient high-resolution video generation,
S. Zhang, W. Li, S. Chen, C. Ge, P. Sun, Y. Zhang, Y. Jiang, Z. Yuan, B. Peng, and P. Luo, “Flashvideo: Flowing fidelity to detail for efficient high-resolution video generation,” inAAAI, 2026
2026
-
[14]
Turbo2k: Towards ultra-efficient and high-quality 2k video synthesis,
J. Ren, W. Li, Z. Wang, H. Sun, B. Liu, H. Chen, J. Xu, A. Li, S. Zhang, B. Shao, Y. Guo, and L. Zhu, “Turbo2k: Towards ultra-efficient and high-quality 2k video synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 18155–18165
2025
-
[15]
Cinescale: Free lunch in high-resolution cinematic visual generation,
H. Qiu, N. Yu, Z. Huang, P. Debevec, and Z. Liu, “Cinescale: Free lunch in high-resolution cinematic visual generation,”arXiv preprint arXiv:2508.15774, 2025
-
[16]
Scalecrafter: Tuning-free higher-resolution visual generation with diffusion models,
Y. He, S. Yang, H. Chen, X. Cun, M. Xia, Y. Zhang, X. Wang, R. He, Q. Chen, and Y. Shan, “Scalecrafter: Tuning-free higher-resolution visual generation with diffusion models,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[17]
Ultra-resolution adaptation with ease,
R. Yu, S. Liu, Z. Tan, and X. Wang, “Ultra-resolution adaptation with ease,”International Conference on Machine Learning, 2025
2025
-
[18]
T. Ye, S. Fei, and L. Zhu, “Ultraflux: Data-model co-design for high-quality native 4k text-to- image generation across diverse aspect ratios,”arXiv preprint arXiv:2511.18050, 2025. 12 PixelWizard
-
[19]
Star: Spatial-temporal augmentation with text-to-video models for real-world video super- resolution,
R. Xie, Y. Liu, P. Zhou, C. Zhao, J. Zhou, K. Zhang, Z. Zhang, J. Yang, Z. Yang, and Y. Tai, “Star: Spatial-temporal augmentation with text-to-video models for real-world video super- resolution,” inICCV, 2025
2025
-
[20]
Seedvr: Seeding infinity in diffusion transformer towards generic video restoration,
J. Wang, Z. Lin, M. Wei, Y. Zhao, C. Yang, C. C. Loy, and L. Jiang, “Seedvr: Seeding infinity in diffusion transformer towards generic video restoration,” inCVPR, 2025
2025
-
[21]
Seedvr2: One-step video restoration via diffusion adversarial post-training,
J. Wang, S. Lin, Z. Lin, Y. Ren, M. Wei, Z. Yue, S. Zhou, H. Chen, Y. Zhao, C. Yang, X. Xiao, C. C. Loy, and L. Jiang, “Seedvr2: One-step video restoration via diffusion adversarial post-training,”arXiv preprint arXiv:2506.05301, 2025
-
[22]
Dove: Efficient one-step diffusion model for real-world video super-resolution,
Z. Chen, Z. Zou, K. Zhang, X. Su, X. Yuan, Y. Guo, and Y. Zhang, “Dove: Efficient one-step diffusion model for real-world video super-resolution,” inNeurIPS, 2025
2025
-
[23]
Flashvsr: Towards real-time diffusion-based streaming video super-resolution,
J. Zhuang, S. Guo, X. Cai, X. Li, Y. Liu, C. Yuan, and T. Xue, “Flashvsr: Towards real-time diffusion-based streaming video super-resolution,”arXiv preprint arXiv:2510.12747, 2025
-
[24]
Simplegvr: A simple baseline for latent-cascaded video super-resolution,
L. Xie, Y. Li, S. Du, M. Xia, X. Wang, F. Yu, Z. Chen, P. Wan, J. Zhou, and C. Dong, “Simplegvr: A simple baseline for latent-cascaded video super-resolution,”arXiv preprint arXiv:2506.19838, 2025
-
[25]
H. Bai, X. Chen, C. Yang, Z. He, S. Deng, and Y. Chen, “Vivid-vr: Distilling concepts from text-to-video diffusion transformer for photorealistic video restoration,”arXiv preprint arXiv:2508.14483, 2025. [Online]. Available: https://arxiv.org/abs/2508.14483
work page internal anchor Pith review arXiv 2025
-
[26]
Histream: Efficient high-resolution video generation via redundancy-eliminated streaming,
H. Qiu, S. Liu, Z. Zhou, Z. An, W. Ren, Z. Liu, J. Schult, S. He, S. Chen, Y. Conget al., “Histream: Efficient high-resolution video generation via redundancy-eliminated streaming,” arXiv preprint arXiv:2512.21338, 2025
-
[27]
One-step diffusion with distribution matching distillation,
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park, “One-step diffusion with distribution matching distillation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 6613–6623
2024
-
[28]
Dual-expertconsistencymodel for efficient and high-quality video generation,
Z.Lv, C.Si, T.Pan, Z.Chen, K.-Y.K.Wong, Y.Qiao, andZ.Liu, “Dual-expertconsistencymodel for efficient and high-quality video generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 14983–14993
2025
-
[29]
Osv: One step is enough for high-quality image to video generation,
X. Mao, Z. Jiang, F.-Y. Wang, J. Zhang, H. Chen, M. Chi, Y. Wang, and W. Luo, “Osv: One step is enough for high-quality image to video generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12585–12594
2025
-
[30]
Self forcing: Bridging the train-test gap in autoregressive video diffusion,
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman, “Self forcing: Bridging the train-test gap in autoregressive video diffusion,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[31]
Magicdistilla- tion: Weak-to-strong video distillation for large-scale few-step synthesis,
S. Shao, H. Yi, H. Guo, T. Ye, D. Zhou, M. Lingelbach, Z. Xu, and Z. Xie, “Magicdistilla- tion: Weak-to-strong video distillation for large-scale few-step synthesis,”arXiv preprint arXiv:2503.13319, 2025
-
[32]
Timestep embedding tells: It’s time to cache for video diffusion model,
F. Liu, S. Zhang, X. Wang, Y. Wei, H. Qiu, Y. Zhao, Y. Zhang, Q. Ye, and F. Wan, “Timestep embedding tells: It’s time to cache for video diffusion model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 13 PixelWizard
2024
-
[33]
Magcache: Fast video generation with magnitude-aware cache,
Z. Ma, L. Wei, F. Wang, S. Zhang, and Q. Tian, “Magcache: Fast video generation with magnitude-aware cache,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[34]
Less is enough: Training-free video diffusion acceleration via runtime-adaptive caching,
X. Zhou, D. Liang, K. Chen, , T. Feng, X. Chen, H. Lin, Y. Ding, F. Tan, H. Zhao, and X. Bai, “Less is enough: Training-free video diffusion acceleration via runtime-adaptive caching,” arXiv preprint arXiv:2507.02860, 2025
-
[35]
Sparsevideogen: Accelerating video diffusion transformers with spatial-temporal sparsity,
H.Xi,S.Yang,Y.Zhao,C.Xu,M.Li,X.Li,Y.Lin,H.Cai,J.Zhang,D.Lietal.,“Sparsevideogen: Accelerating video diffusion transformers with spatial-temporal sparsity,”International Conference on Machine Learning, 2025
2025
-
[36]
Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permu- tation,
S. Yang, H. Xi, Y. Zhao, M. Li, J. Zhang, H. Cai, Y. Lin, X. Li, C. Xu, K. Penget al., “Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permu- tation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[37]
Radial attention:O (𝑛log𝑛) sparse attention with energy decayforlongvideogeneration,
X. Li*, M. Li*, T. Cai, H. Xi, S. Yang, Y. Lin, L. Zhang, S. Yang, J. Hu, K. Peng, M. Agrawala, I. Stoica, K. Keutzer, and S. Han, “Radial attention:O (𝑛log𝑛) sparse attention with energy decayforlongvideogeneration,” inTheThirty-ninthAnnualConferenceonNeuralInformation Processing Systems, 2025
2025
-
[38]
Dc- videogen: Efficient video generation with deep compression video autoencoder,
J. Chen, W. He, Y. Gu, Y. Zhao, J. Yu, J. Chen, D. Zou, Y. Lin, Z. Zhang, M. Liet al., “Dc- videogen: Efficient video generation with deep compression video autoencoder,”arXiv preprint arXiv:2509.25182, 2025
-
[39]
One Step Diffusion via Shortcut Models
K. Frans, D. Hafner, S. Levine, and P. Abbeel, “One step diffusion via shortcut models,”arXiv preprint arXiv:2410.12557, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” in Forty-first international conference on machine learning, 2024
2024
-
[41]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, X....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Vbench: Comprehensive benchmark suite for video generative models,
Z. Huang, Y. He, J. Yu, F. Zhang, C. Si, Y. Jiang, Y. Zhang, T. Wu, Q. Jin, N. Chanpaisitet al., “Vbench: Comprehensive benchmark suite for video generative models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21807–21818
2024
-
[43]
Exploring video quality assessment on user generated contents from aesthetic and technical perspectives,
H. Wu, E. Zhang, L. Liao, C. Chen, J. H. Hou, A. Wang, W. S. Sun, Q. Yan, and W. Lin, “Exploring video quality assessment on user generated contents from aesthetic and technical perspectives,” inInternational Conference on Computer Vision (ICCV), 2023
2023
-
[44]
Musiq: Multi-scale image quality transformer,
J. Ke, Q. Wang, Y. Wang, P. Milanfar, and F. Yang, “Musiq: Multi-scale image quality transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 5148–5157. 14 PixelWizard
2021
-
[45]
Making a “completely blind
A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a “completely blind” image quality analyzer,”IEEE Signal processing letters, vol. 20, no. 3, pp. 209–212, 2012
2012
-
[46]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”International Conference on Learning Representations, 2023
2023
-
[47]
Vchitect-2.0: Parallel transformer for scaling up video diffusion models,
W. Fan, C. Si, J. Song, Z. Yang, Y. He, L. Zhuo, Z. Huang, Z. Dong, J. He, D. Panet al., “Vchitect-2.0: Parallel transformer for scaling up video diffusion models,”arXiv preprint arXiv:2501.08453, 2025
-
[48]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y. Yang, W. Hong, X. Zhang, G. Feng et al., “Cogvideox: Text-to-video diffusion models with an expert transformer,”arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Mochi 1,
G. Team, “Mochi 1,” https://github.com/genmoai/models, 2024
2024
-
[50]
Open-Sora: Democratizing Efficient Video Production for All
Z. Zheng, X. Peng, T. Yang, C. Shen, S. Li, H. Liu, Y. Zhou, T. Li, and Y. You, “Open-sora: Democratizing efficient video production for all,”arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Open-Sora Plan: Open-Source Large Video Generation Model
B. Lin, Y. Ge, X. Cheng, Z. Li, B. Zhu, S. Wang, X. He, Y. Ye, S. Yuan, L. Chenet al., “Open-sora plan: Open-source large video generation model,”arXiv preprint arXiv:2412.00131, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhanget al., “Hunyuanvideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024. 15 PixelWizard This is supplementary material forPixelWizard: Towards Efficient High-Fidelity Video Genera- tion at Ultra-Large Spatial Resolutions. 6 O...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.