Adaptive Graph Refinement and Label Propagation with LLMs for Cost-Effective Entity Resolution
Pith reviewed 2026-06-29 21:27 UTC · model grok-4.3
The pith
Alper unifies matching and clustering in entity resolution through iterative label propagation on an evolving graph that selectively incorporates LLM queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
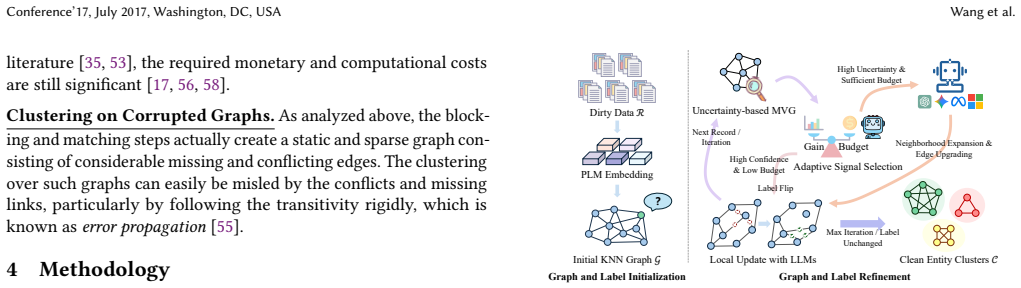
Alper integrates matching and clustering into an iterative probabilistic label propagation process over a global, evolving graph. Unlike disjoint blocking, Alper refines the graph structure and labels dynamically by adaptively integrating weak but cheap signals from graph propagation with strong but expensive LLM-based pairwise queries. The signal selection is formulated as a constrained optimization problem maximizing cumulative marginal gain under a query budget, solved via a greedy algorithm with provable theoretical guarantees.
What carries the argument
Iterative probabilistic label propagation over an evolving graph that adaptively mixes cheap propagation signals with budgeted LLM queries, solved by a greedy marginal-gain algorithm.
If this is right
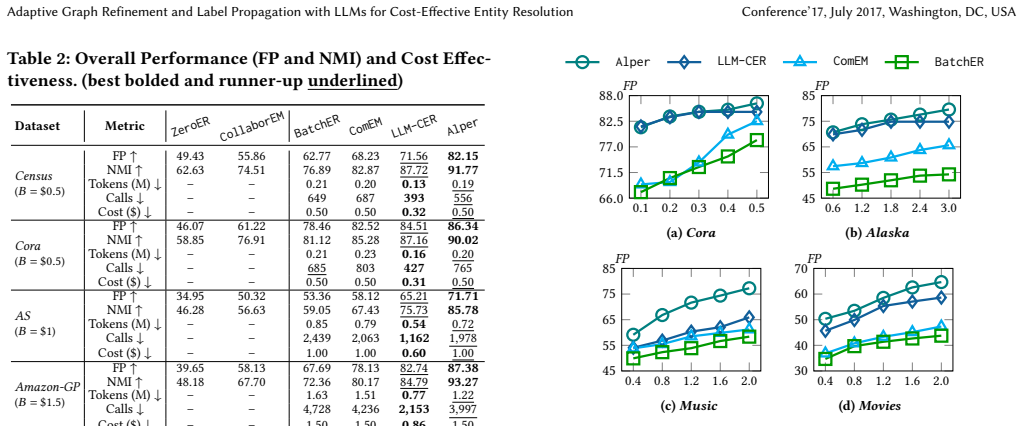
- Yields consistently higher cluster quality than state-of-the-art cascaded pipelines across eight benchmark datasets.
- Reduces error propagation that arises from static graphs produced by decoupled blocking, matching, and clustering steps.
- Achieves higher cost-effectiveness by selecting LLM queries that maximize cumulative marginal gain under a fixed budget.
- Supplies theoretical guarantees that the greedy algorithm for query selection is near-optimal.
- Produces a final entity graph whose edges and labels improve together rather than remaining fixed after early blocking decisions.
Where Pith is reading between the lines
- The same adaptive combination of cheap propagation signals and selective expensive queries could be tested on incremental or streaming entity-resolution settings where the graph grows over time.
- The framework might extend to other data-cleaning tasks such as deduplication in knowledge graphs where LLM calls are the dominant cost.
- If the marginal-gain formulation proves robust, similar budgeted optimization could replace heuristic query selection in active-learning pipelines for graph labeling.
- The evolving-graph view suggests that error modes introduced by early blocking decisions could be corrected later, an effect worth measuring separately from overall F1 scores.
Load-bearing premise
Matching and clustering can be jointly optimized through iterative probabilistic label propagation on an evolving graph without the integration itself introducing new error modes or instability.
What would settle it
If experiments on the eight benchmark datasets showed Alper producing clusters of equal or lower quality, or requiring equal or higher total LLM queries, than the best cascaded pipelines, the superiority claim would be falsified.
Figures



read the original abstract
Dirty entity resolution (ER), which identifies records referring to the same real-world entity from a single, messy dataset, is a fundamental task in data management and mining. However, the dominant blocking-matching-clustering paradigm for ER suffers from critical flaws. Its cascaded, decoupled workflow essentially produces a static, sparse graph plagued by missing edges (due to blocking failures) and noisy links (due to matching errors), causing error propagation and yielding suboptimal clusters, particularly when rigid transitivity is imposed in the clustering. We contend that matching and clustering are fundamentally synergistic, both optimizing for the construction of an ideal entity graph. Building upon this insight, we propose Alper, a unified framework that integrates these steps into an iterative probabilistic label propagation process over a global, evolving graph. Unlike disjoint blocking, Alper refines the graph structure and labels dynamically by adaptively integrating "weak but cheap" signals from graph propagation with "strong but expensive" LLM-based pairwise queries. For higher cost-effectiveness, we formulate the signal selection as a constrained optimization problem maximizing cumulative marginal gain under a query budget, solved via our greedy algorithm with provable theoretical guarantees. Our extensive experiments over eight benchmark datasets demonstrate that Alper is consistently superior to state-of-the-art cascaded pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Alper, a unified framework for dirty entity resolution that integrates matching and clustering via iterative probabilistic label propagation on an evolving graph. It adaptively combines cheap graph-based signals with expensive LLM pairwise queries under a query budget, formulated as a constrained optimization problem solved by a greedy algorithm claimed to have provable theoretical guarantees. The central empirical claim is that Alper is consistently superior to state-of-the-art cascaded blocking-matching-clustering pipelines across eight benchmark datasets.
Significance. If the reported superiority and the theoretical guarantees hold under rigorous evaluation, the work could meaningfully advance entity resolution by demonstrating that joint optimization of matching and clustering reduces error propagation compared to decoupled pipelines. The cost-effective use of LLMs via adaptive signal selection would be a practical contribution to hybrid graph-ML methods in data management. However, the absence of any experimental details, metrics, baselines, or derivation in the provided manuscript text prevents confirmation that the results support these implications.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent superiority' on eight benchmarks and 'provable theoretical guarantees' for the greedy algorithm is asserted without any metrics (e.g., F1, precision-recall), baselines, statistical tests, or derivation of the optimization problem or approximation ratio; this is load-bearing for both the empirical and theoretical contributions.
- [unified framework description] The section on the unified framework: the premise that matching and clustering are 'fundamentally synergistic' and that iterative label propagation integrates them without introducing new error modes or instability lacks any supporting ablation (e.g., non-iterative variant) or error-propagation analysis, which directly underpins the motivation for departing from the cascaded paradigm.
- [signal selection optimization] The optimization formulation: no equation defining the constrained optimization, marginal gain, or query budget constraint is supplied, so it is impossible to verify whether the greedy selector's guarantees are non-vacuous or whether the 'weak but cheap' vs. 'strong but expensive' integration is correctly modeled.
minor comments (1)
- [Abstract] The abstract refers to 'Alper' without expanding the acronym or providing a high-level system diagram, which would aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We agree that the provided manuscript text does not contain the requested equations, ablations, metrics, or derivations, and we will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent superiority' on eight benchmarks and 'provable theoretical guarantees' for the greedy algorithm is asserted without any metrics (e.g., F1, precision-recall), baselines, statistical tests, or derivation of the optimization problem or approximation ratio; this is load-bearing for both the empirical and theoretical contributions.
Authors: We will revise the abstract to include key quantitative results (e.g., average F1 improvements and baseline names) while preserving conciseness. Full metrics, statistical tests, and the theoretical derivation will be added to the main body and referenced from the abstract. revision: yes
-
Referee: [unified framework description] The section on the unified framework: the premise that matching and clustering are 'fundamentally synergistic' and that iterative label propagation integrates them without introducing new error modes or instability lacks any supporting ablation (e.g., non-iterative variant) or error-propagation analysis, which directly underpins the motivation for departing from the cascaded paradigm.
Authors: We will add an ablation comparing iterative vs. non-iterative variants and an explicit error-propagation analysis in the revised manuscript to support the unified framework motivation. revision: yes
-
Referee: [signal selection optimization] The optimization formulation: no equation defining the constrained optimization, marginal gain, or query budget constraint is supplied, so it is impossible to verify whether the greedy selector's guarantees are non-vacuous or whether the 'weak but cheap' vs. 'strong but expensive' integration is correctly modeled.
Authors: We will insert the formal constrained optimization equation, marginal gain definition, budget constraint, and the greedy algorithm's approximation ratio derivation in the revised Section 4. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation introduces a unified iterative label propagation framework for ER, formulates signal selection as a budgeted optimization solved by a greedy algorithm with stated theoretical guarantees, and validates via external experiments on eight benchmarks. No load-bearing step reduces by construction to fitted inputs, self-definitions, or self-citation chains; the empirical superiority claim is independent of internal parameter definitions. The framework and guarantees are presented as novel contributions without the patterns of self-definitional equivalence or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nikhil Bansal, Avrim Blum, and Shuchi Chawla. 2004. Correlation clustering. Machine learning56, 1 (2004), 89–113
2004
-
[2]
Omar Benjelloun, Hector Garcia-Molina, David Menestrina, Qi Su, Steven Eui- jong Whang, and Jennifer Widom. 2009. Swoosh: a generic approach to entity resolution.The VLDB Journal18, 1 (2009), 255–276
2009
-
[3]
Brenda Betancourt, Giacomo Zanella, Jeffrey W Miller, Hanna Wallach, Abbas Zaidi, and Rebecca C Steorts. 2016. Flexible models for microclustering with application to entity resolution.Advances in neural information processing systems 29 (2016)
2016
-
[4]
Christoph Böhm, Gerard De Melo, Felix Naumann, and Gerhard Weikum. 2012. LINDA: distributed web-of-data-scale entity matching. InProceedings of the 21st ACM international conference on Information and knowledge management. 2104– 2108
2012
-
[5]
Chengliang Chai, Guoliang Li, Jian Li, Dong Deng, and Jianhua Feng. 2016. Cost- effective crowdsourced entity resolution: A partial-order approach. InProceedings of the 2016 International Conference on Management of Data. 969–984
2016
-
[6]
Deeparnab Chakrabarty, Yunhong Zhou, and Rajan Lukose. 2008. Online knap- sack problems. InWorkshop on internet and network economics (WINE). 1–9
2008
-
[7]
Zhaoqi Chen, Dmitri V Kalashnikov, and Sharad Mehrotra. 2005. Exploiting relationships for object consolidation. InProceedings of the 2nd international workshop on Information quality in information systems. 47–58
2005
-
[8]
Peter Christen. 2011. A survey of indexing techniques for scalable record linkage and deduplication.IEEE transactions on knowledge and data engineering24, 9 (2011), 1537–1555
2011
-
[9]
Peter Christen. 2012. The data matching process. InData matching: concepts and techniques for record linkage, entity resolution, and duplicate detection. Springer, 23–35
2012
-
[10]
Vassilis Christophides, Vasilis Efthymiou, Themis Palpanas, George Papadakis, and Kostas Stefanidis. 2020. An overview of end-to-end entity resolution for big data.ACM Computing Surveys (CSUR)53, 6 (2020), 1–42
2020
- [11]
-
[12]
Gianluca Demartini, Djellel Eddine Difallah, and Philippe Cudré-Mauroux. 2012. Zencrowd: leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking. InProceedings of the 21st international conference on World Wide Web. 469–478
2012
-
[13]
Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Mur- phy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. InProceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 601–610
2014
-
[14]
Uwe Draisbach, Peter Christen, and Felix Naumann. 2019. Transforming pairwise duplicates to entity clusters for high-quality duplicate detection.Journal of Data and Information Quality (JDIQ)12, 1 (2019), 1–30
2019
- [15]
-
[16]
Ahmed K Elmagarmid, Panagiotis G Ipeirotis, and Vassilios S Verykios. 2006. Duplicate record detection: A survey.IEEE Transactions on knowledge and data engineering19, 1 (2006), 1–16
2006
-
[17]
Meihao Fan, Xiaoyue Han, Ju Fan, Chengliang Chai, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Cost-effective in-context learning for entity resolution: A design space exploration. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 3696–3709
2024
-
[18]
Ivan P Fellegi and Alan B Sunter. 1969. A theory for record linkage.Journal of the American statistical association64, 328 (1969), 1183–1210
1969
-
[19]
Jiajie Fu, Haitong Tang, Arijit Khan, Sharad Mehrotra, Xiangyu Ke, and Yunjun Gao. 2025. In-context clustering-based entity resolution with large language models: A design space exploration.Proceedings of the ACM on Management of Data3, 4 (2025), 1–28
2025
-
[20]
Sainyam Galhotra, Donatella Firmani, Barna Saha, and Divesh Srivastava. 2018. Robust entity resolution using random graphs. InProceedings of the 2018 Interna- tional Conference on Management of Data. 3–18
2018
-
[21]
Congcong Ge, Pengfei Wang, Lu Chen, Xiaoze Liu, Baihua Zheng, and Yunjun Gao. 2021. CollaborEM: A self-supervised entity matching framework using multi- features collaboration.IEEE Transactions on Knowledge and Data Engineering35, 12 (2021), 12139–12152
2021
-
[22]
Oktie Hassanzadeh, Fei Chiang, Hyun Chul Lee, and Renée J Miller. 2009. Frame- work for evaluating clustering algorithms in duplicate detection.Proceedings of the VLDB Endowment2, 1 (2009), 1282–1293
2009
-
[23]
Mauricio A Hernández and Salvatore J Stolfo. 1995. The merge/purge problem for large databases.ACM Sigmod Record24, 2 (1995), 127–138
1995
-
[24]
Jeff Howe. 2006. The rise of crowdsourcing, Wired.http://www. wired. com/wired/archive/14.06/crowds. html(2006)
2006
- [25]
-
[26]
Anitha Kannan, Inmar E Givoni, Rakesh Agrawal, and Ariel Fuxman. 2011. Match- ing unstructured product offers to structured product specifications. InProceed- ings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 404–412
2011
-
[27]
Pradap Konda, Sanjib Das, Paul Suganthan G C, AnHai Doan, Adel Ardalan, Jeffrey R Ballard, Han Li, Fatemah Panahi, Haojun Zhang, Jeff Naughton, et al
-
[28]
Magellan: toward building entity matching management systems over data science stacks.Proceedings of the VLDB Endowment9, 13 (2016), 1581–1584
2016
-
[29]
Simon Lacoste-Julien, Konstantina Palla, Alex Davies, Gjergji Kasneci, Thore Graepel, and Zoubin Ghahramani. 2013. Sigma: Simple greedy matching for align- ing large knowledge bases. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 572–580
2013
-
[30]
Bing Li, Wei Wang, Yifang Sun, Linhan Zhang, Muhammad Asif Ali, and Yi Wang
-
[31]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Grapher: Token-centric entity resolution with graph convolutional neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8172–8179
- [32]
-
[33]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan
- [34]
-
[35]
Andrew McCallum, Kamal Nigam, and Lyle H Ungar. 2000. Efficient clustering of high-dimensional data sets with application to reference matching. InProceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining. 169–178
2000
-
[36]
Venkata Vamsikrishna Meduri, Lucian Popa, Prithviraj Sen, and Mohamed Sarwat
-
[37]
InProceedings of the 2020 ACM SIGMOD international conference on management of data
A comprehensive benchmark framework for active learning methods in entity matching. InProceedings of the 2020 ACM SIGMOD international conference on management of data. 1133–1147
2020
-
[38]
Barzan Mozafari, Purna Sarkar, Michael Franklin, Michael Jordan, and Samuel Madden. 2014. Scaling up crowd-sourcing to very large datasets: a case for active learning.Proceedings of the VLDB Endowment8, 2 (2014), 125–136
2014
-
[39]
Avanika Narayan, Ines Chami, Laurel Orr, Simran Arora, and Christopher Ré
- [40]
-
[41]
Mahdi Niknam, Behrouz Minaei-Bidgoli, and Rouhollah Dianat. 2022. The role of transitive closure in evaluating blocking methods for dirty entity resolution. Journal of Intelligent Information Systems58, 3 (2022), 561–590
2022
-
[42]
Konstantinos Nikoletos, George Papadakis, and Manolis Koubarakis. 2022. py- JedAI: a Lightsaber for Link Discovery.. InISWC (Posters/Demos/Industry)
2022
-
[43]
George Papadakis, Dimitrios Skoutas, Emmanouil Thanos, and Themis Palpanas
-
[44]
9 Conference’17, July 2017, Washington, DC, USA Wang et al
Blocking and filtering techniques for entity resolution: A survey.ACM Computing Surveys (CSUR)53, 2 (2020), 1–42. 9 Conference’17, July 2017, Washington, DC, USA Wang et al
2020
-
[45]
George Papadakis, Leonidas Tsekouras, Emmanouil Thanos, George Gian- nakopoulos, Themis Palpanas, and Manolis Koubarakis. 2018. The return of jedai: End-to-end entity resolution for structured and semi-structured data.Pro- ceedings of the VLDB Endowment, Vol. 11, No. 1211, 12 (2018), 1950–1953
2018
-
[46]
Derek Paulsen, Yash Govind, and AnHai Doan. 2023. Sparkly: A simple yet surprisingly strong TF/IDF blocker for entity matching.Proceedings of the VLDB Endowment16, 6 (2023), 1507–1519
2023
-
[47]
Ralph Peeters and Christian Bizer. 2021. Dual-objective fine-tuning of BERT for entity matching.Proceedings of the VLDB Endowment14 (2021), 1913–1921
2021
-
[48]
Clifton Phua, Vincent Lee, Kate Smith, and Ross Gayler. 2010. A compre- hensive survey of data mining-based fraud detection research.arXiv preprint arXiv:1009.6119(2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[49]
Usha Nandini Raghavan, Réka Albert, and Soundar Kumara. 2007. Near linear time algorithm to detect community structures in large-scale networks.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics76, 3 (2007), 036106
2007
-
[50]
Alieh Saeedi, Markus Nentwig, Eric Peukert, and Erhard Rahm. 2018. Scalable matching and clustering of entities with FAMER.Complex Systems Informatics and Modeling Quarterly16 (2018), 61–83
2018
-
[51]
Alieh Saeedi, Eric Peukert, and Erhard Rahm. 2017. Comparative evaluation of distributed clustering schemes for multi-source entity resolution. InEuropean Conference on Advances in Databases and Information Systems. Springer, 278–293
2017
-
[52]
Claude E Shannon. 1948. A mathematical theory of communication.The Bell system technical journal27, 3 (1948), 379–423
1948
-
[53]
Fabian M Suchanek, Serge Abiteboul, and Pierre Senellart. 2011. Paris: Probabilis- tic alignment of relations, instances, and schema.arXiv preprint arXiv:1111.7164 (2011)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[54]
Saravanan Thirumuruganathan, Han Li, Nan Tang, Mourad Ouzzani, Yash Govind, Derek Paulsen, Glenn Fung, and AnHai Doan. 2021. Deep learning for blocking in entity matching: a design space exploration.Proceedings of the VLDB Endowment 14, 11 (2021), 2459–2472
2021
-
[55]
Samhita Vadrevu, Rakesh Nagi, JinJun Xiong, and Wen-mei Hwu. 2021. xER: An explainable model for entity resolution using an efficient solution for the clique partitioning problem. InProceedings of the First Workshop on Trustworthy Natural Language Processing. 34–44
2021
-
[56]
Vasilis Verroios and Hector Garcia-Molina. 2015. Entity resolution with crowd errors. In2015 IEEE 31st international conference on data engineering. IEEE, 219– 230
2015
-
[57]
Vasilis Verroios, Hector Garcia-Molina, and Yannis Papakonstantinou. 2017. Waldo: An adaptive human interface for crowd entity resolution. InProceedings of the 2017 ACM International Conference on Management of Data. 1133–1148
2017
-
[58]
Norases Vesdapunt, Kedar Bellare, and Nilesh Dalvi. 2014. Crowdsourcing algo- rithms for entity resolution.Proceedings of the VLDB Endowment7, 12 (2014), 1071–1082
2014
-
[59]
Jiannan Wang, Tim Kraska, Michael J Franklin, and Jianhua Feng. 2012. Crowder: Crowdsourcing entity resolution.arXiv preprint arXiv:1208.1927(2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[60]
Jiannan Wang, Guoliang Li, Tim Kraska, Michael J Franklin, and Jianhua Feng
-
[61]
InProceedings of the 2013 ACM SIGMOD International Conference on Management of Data
Leveraging transitive relations for crowdsourced joins. InProceedings of the 2013 ACM SIGMOD International Conference on Management of Data. 229–240
2013
-
[62]
Sibo Wang, Xiaokui Xiao, and Chun-Hee Lee. 2015. Crowd-based deduplication: An adaptive approach. InProceedings of the 2015 ACM SIGMOD international conference on Management of Data. 1263–1277
2015
-
[63]
Tianshu Wang, Xiaoyang Chen, Hongyu Lin, Xuanang Chen, Xianpei Han, Le Sun, Hao Wang, and Zhenyu Zeng. 2025. Match, compare, or select? an investigation of large language models for entity matching. InProceedings of the 31st International Conference on Computational Linguistics. 96–109
2025
-
[64]
Yaoshu Wang, Jianbin Qin, and Wei Wang. 2017. Efficient approximate entity matching using jaro-winkler distance. InInternational conference on web infor- mation systems engineering. Springer, 231–239
2017
-
[65]
Steven Euijong Whang, Peter Lofgren, and Hector Garcia-Molina. 2013. Question selection for crowd entity resolution. (2013)
2013
-
[66]
William E Winkler et al. 2006. Overview of record linkage and current research directions.Bureau of the Census25, 4 (2006), 603–623
2006
-
[67]
Renzhi Wu, Alexander Bendeck, Xu Chu, and Yeye He. 2023. Ground truth inference for weakly supervised entity matching.Proceedings of the ACM on Management of Data1, 1 (2023), 1–28
2023
-
[68]
Renzhi Wu, Sanya Chaba, Saurabh Sawlani, Xu Chu, and Saravanan Thirumu- ruganathan. 2020. Zeroer: Entity resolution using zero labeled examples. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 1149–1164
2020
-
[69]
Vijaya Krishna Yalavarthi, Xiangyu Ke, and Arijit Khan. 2017. Select your ques- tions wisely: For entity resolution with crowd errors. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management. 317–326
2017
-
[70]
Dezhong Yao, Yuhong Gu, Gao Cong, Hai Jin, and Xinqiao Lv. 2022. Entity resolution with hierarchical graph attention networks. InProceedings of the 2022 International Conference on Management of Data. 429–442
2022
-
[71]
Li Yujian and Liu Bo. 2007. A normalized Levenshtein distance metric.IEEE transactions on pattern analysis and machine intelligence29, 6 (2007), 1091–1095
2007
-
[72]
Haochen Zhang, Yuyang Dong, Chuan Xiao, and Masafumi Oyamada. 2023. Large language models as data preprocessors.arXiv preprint arXiv:2308.16361(2023). 10 Adaptive Graph Refinement and Label Propagation with LLMs for Cost-Effective Entity Resolution Conference’17, July 2017, Washington, DC, USA A Additional Related Work In this section, we provide suppleme...
-
[73]
Please respond with ONLY the number (1, 2, ...) of the matching candidate, or "NONE" if no match is found
-
[74]
Input Prompt Query Entity: Intermezzo in B minor, Op
Your response should be a single number or "NONE", nothing else. Input Prompt Query Entity: Intermezzo in B minor, Op. 119 No. 1: Adago - Brahms: Complete Works Candidate Entities:
-
[75]
12 in B minor (HWV 330) - I
Opus 6 No. 12 in B minor (HWV 330) - I. Largo - Concerti Grossi op. 6
-
[76]
003-Symphony 1 in C minor, op. 11: III. Menuetto & Trio, Allegro di Molto
-
[77]
Intermezzo in B minor, Op. 119 No. 1: Adagio
-
[78]
017-Intermezzo in B minor, Op. 119 No. 1: Adagio
-
[79]
Johannes Brahms - Concerto for Violin and Orchestra in D major, Op. 77: II. Adagio Response 3 Figure 9: An example of the prompt used for LLM verification onMusic. C.13 Analysis of Error Correction A key advantage of Alper is its ability to mitigate early-stage LLM errors. “Cheap” LLMs risk generating false positives, but our frame- work absorbs these thr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.