MuNet: A Mutualistic Network for Joint 3D Human Mesh Recovery and 3D Clothed Human Reconstruction from Single Images
Pith reviewed 2026-06-29 22:58 UTC · model grok-4.3
The pith
MuNet jointly optimizes 3D human mesh recovery and clothed reconstruction by letting each task guide the other during training on shared graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
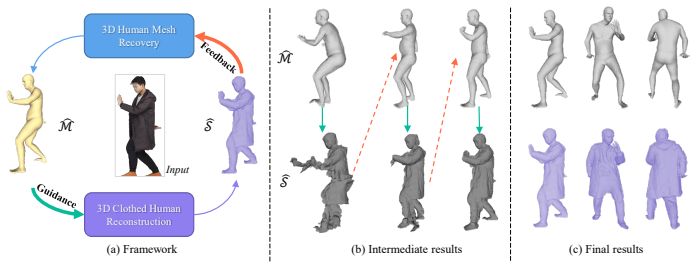
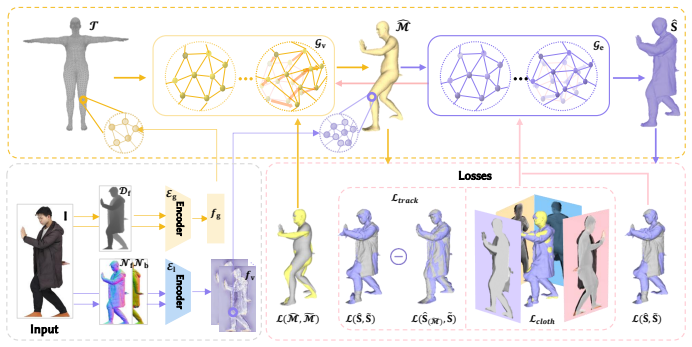
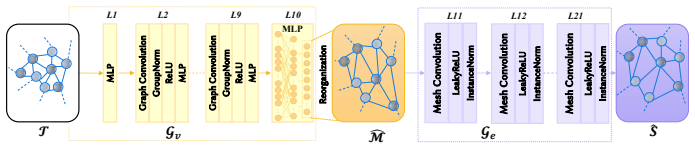
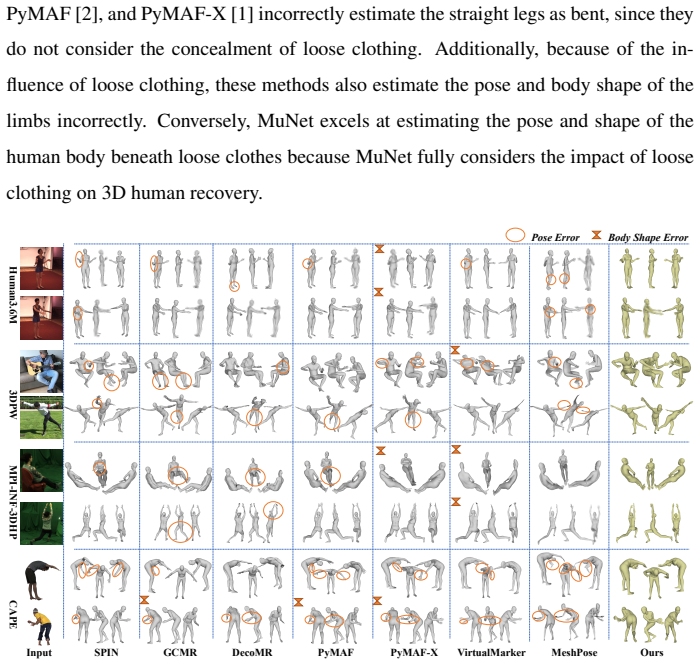
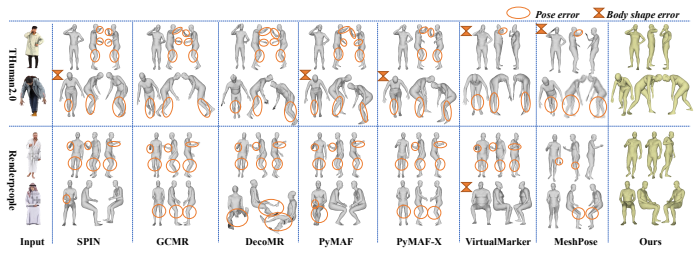
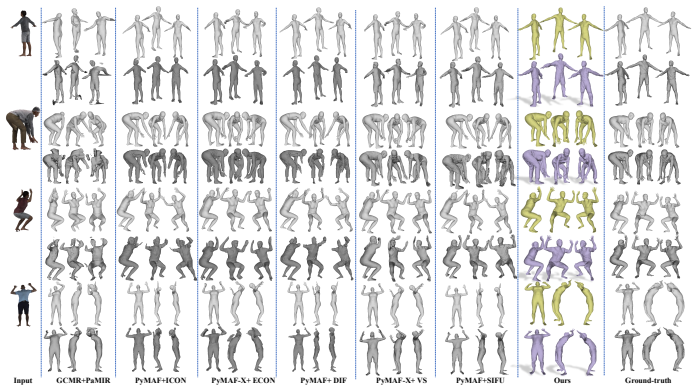
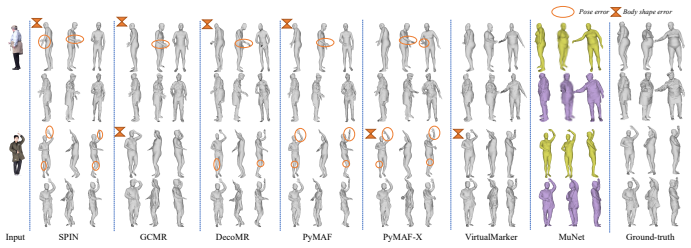
MuNet is a mutualistic network that solves 3D human mesh recovery and 3D clothed human reconstruction jointly from single images. It adopts 2-manifold graphs as a unified representation for consistent modeling, employs an end-to-end graph convolutional network that progressively deforms an initial graph into a 3D human mesh and then refines it into a detailed clothed model, and introduces a mutualistic mechanism for reciprocal interaction between the tasks during training where mesh recovery guides reconstruction and reconstruction refines mesh recovery. This yields state-of-the-art performance on both tasks across the Human3.6M, 3DPW, MPI-INF-3DHP, THuman2.0, CAPE, and RenderPeople datasets
What carries the argument
The mutualistic mechanism that enables reciprocal interaction between 3D human mesh recovery and 3D clothed human reconstruction during training on a shared 2-manifold graph representation.
If this is right
- Both tasks receive guidance from the other and reach higher accuracy than isolated training.
- A single end-to-end model produces both bare meshes and detailed clothed outputs without separate stages.
- The same 2-manifold graph representation supports consistent modeling for mesh recovery and clothed reconstruction.
- Training incorporates feedback between tasks to refine outputs progressively from coarse to detailed.
- The approach delivers state-of-the-art results on both tasks across indoor, outdoor, and synthetic datasets.
Where Pith is reading between the lines
- The shared graph representation could support adding further related tasks such as pose refinement or texture mapping without redesigning the backbone.
- Practitioners could reduce the number of separate models needed for 3D human pipelines by adopting the joint training loop.
- The progressive deformation strategy might generalize to other 3D reconstruction problems that move from coarse shape to fine surface detail.
- Real-world deployment on varied camera qualities could test whether the mutualistic gains persist outside controlled benchmark conditions.
Load-bearing premise
The mutualistic interaction mechanism during training produces measurable reciprocal benefits that are not achievable by standard multi-task or sequential training on the same graph representation.
What would settle it
An ablation experiment that removes the mutualistic interaction, trains with standard multi-task or sequential methods on the identical graph setup, and measures no performance drop on the metrics for either task across the evaluation datasets.
Figures




read the original abstract
3D human mesh recovery and 3D clothed human reconstruction are inherently related, yet they have long been studied in isolation, thereby overlooking the potential gains of joint optimization. To overcome this limitation, we propose to address these two tasks within a unified framework, which allows their mutual dependencies to be effectively exploited. Building on this idea, we propose MuNet, a mutualistic network for joint 3D human mesh recovery and 3D clothed human reconstruction from single images. First, we adopt 2-manifold graphs as a unified representation for all 3D models, enabling consistent modeling across 3D human mesh recovery and clothed human reconstruction. Second, we design an end-to-end graph convolutional network that progressively deforms an initial graph into a 3D human mesh and refines it into a detailed 3D clothed human model. Third, we introduce a mutualistic mechanism that allows reciprocal interaction between the two tasks {during training}, where 3D human mesh recovery provides guidance for 3D clothed human reconstruction, and reconstruction feedback refines the 3D human mesh recovery. We extensively evaluate MuNet on six benchmark datasets for 3D human mesh recovery and 3D clothed human reconstruction, including Human3.6M, 3DPW, MPI-INF-3DHP, THuman2.0, CAPE, and RenderPeople. Experimental results demonstrate that MuNet achieves state-of-the-art performance on both tasks across all datasets. The code of MuNet is released for research purposes at https://github.com/starVisionTeam/MuNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MuNet, a mutualistic network for joint 3D human mesh recovery and 3D clothed human reconstruction from single images. It adopts 2-manifold graphs as a unified representation, designs an end-to-end progressive graph convolutional network that deforms an initial graph into a mesh and then a detailed clothed model, and introduces a mutualistic training mechanism for reciprocal interaction (mesh recovery guiding clothed reconstruction and vice versa). The work claims state-of-the-art results on both tasks across six datasets (Human3.6M, 3DPW, MPI-INF-3DHP, THuman2.0, CAPE, RenderPeople) and releases code.
Significance. If the mutualistic mechanism can be shown to deliver measurable reciprocal benefits beyond what is achievable by standard multi-task or sequential training on the same graph/GCN backbone, the result would be significant for 3D human modeling, as it would demonstrate concrete gains from exploiting task interdependencies in a unified framework rather than treating the problems in isolation. The code release is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim attributes SOTA gains specifically to the mutualistic interaction during training, yet no ablation studies are described that disable the reciprocal feedback loops while retaining the shared 2-manifold graph representation and progressive GCN; without such controls the attribution cannot be verified and the gains could instead arise from the unified representation or deformation pipeline alone.
- [Abstract] Abstract: the manuscript states SOTA performance on six datasets but provides no quantitative tables, implementation details on the mutualistic mechanism, loss functions, or training schedule, preventing verification of the claimed performance or the role of the mutualistic component.
minor comments (1)
- [Abstract] The phrase 'mutualistic mechanism that allows reciprocal interaction between the two tasks {during training}' contains stray braces that appear to be a formatting artifact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the role of the mutualistic mechanism and the placement of supporting details in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes SOTA gains specifically to the mutualistic interaction during training, yet no ablation studies are described that disable the reciprocal feedback loops while retaining the shared 2-manifold graph representation and progressive GCN; without such controls the attribution cannot be verified and the gains could instead arise from the unified representation or deformation pipeline alone.
Authors: The manuscript presents ablation studies comparing the full MuNet to variants using the same 2-manifold graph and progressive GCN but without the mutualistic training. To directly isolate the contribution of the reciprocal feedback, we will add a dedicated control experiment that disables the feedback loops while preserving all other components. This will be included in the revised version to strengthen verification of the mutualistic mechanism's role. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states SOTA performance on six datasets but provides no quantitative tables, implementation details on the mutualistic mechanism, loss functions, or training schedule, preventing verification of the claimed performance or the role of the mutualistic component.
Authors: Abstracts are subject to strict length limits and therefore omit tables and low-level implementation details. The full manuscript contains quantitative tables reporting results on all six datasets (Human3.6M, 3DPW, MPI-INF-3DHP, THuman2.0, CAPE, RenderPeople) in the Experiments section, together with explicit descriptions of the mutualistic mechanism, loss functions, and training schedule in the Method and Implementation sections. We will revise the abstract to add concise pointers to these sections. revision: partial
Circularity Check
No circularity: empirical architecture with external benchmarks
full rationale
The paper proposes MuNet as an empirical network architecture using 2-manifold graphs and a mutualistic training interaction for joint mesh recovery and clothed reconstruction. No equations, derivations, or first-principles claims are presented that reduce performance gains to fitted parameters, self-citations, or definitional equivalences. Results rest on evaluations across six independent external datasets (Human3.6M, 3DPW, etc.), with the mutualistic mechanism described as a training procedure rather than a mathematical identity. This is a standard empirical contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Zhang, Y . Tian, Y . Zhang, M. Li, L. An, Z. Sun, Y . Liu, PyMAF-X: To- wards well-aligned full-body model regression from monocular images, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2023) 1– 16doi:10.1109/TPAMI.2023.3271691
-
[2]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
H. Zhang, Y . Tian, X. Zhou, W. Ouyang, Y . Liu, L. Wang, Z. Sun, PyMAF: 3D human pose and shape regression with pyramidal mesh alignment feedback loop, in: IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 11426–11436. doi:10.1109/ICCV48922.2021.01125
-
[3]
A. Kanazawa, M. J. Black, D. W. Jacobs, J. Malik, End-to-end recovery of hu- man shape and pose, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7122–7131. doi:10.1109/CVPR.2018.00744
-
[5]
Y . Tian, H. Zhang, Y . Liu, L. Wang, Recovering 3D human mesh from monocular images: A survey, IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (TPAMI) 45 (12) (2023) 15406 – 15425. doi:10.1109/TPAMI.2023.3298850
-
[6]
N. Kolotouros, G. Pavlakos, K. Daniilidis, Convolutional mesh regression for single-image human shape reconstruction, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4501–4510. doi:10.1109/CVPR.2019.00463
-
[7]
W. Zeng, W. Ouyang, P. Luo, W. Liu, X. Wang, 3D human mesh re- gression with dense correspondence, in: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2020, pp. 7054–7063. doi:10.1109/CVPR42600.2020.00708. 28
-
[8]
S. K. Dwivedi, Y . Sun, P. Patel, Y . Feng, M. J. Black, Tokenhmr: Advancing hu- man mesh recovery with a tokenized pose representation, in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 1323–1333. doi:10.1109/CVPR52733.2024.00132
-
[9]
E.-T. Le, A. Kakolvris, P. Koutras, H. Tam, E. Skordos, G. Papandreou, R. A. Güler, I. Kokkinos, Meshpose: Unifying densepose and 3D body mesh recon- struction, in: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2024, pp. 2405–2414. doi:10.1109/CVPR52733.2024.00233
-
[10]
ACM Transactions on Graphics (TOG)34(6), 1–16 (2015).https://doi.org/10.1145/2816795.2818013
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, M. J. Black, SMPL: A skinned multi-person linear model, ACM Transactions on Graphics (TOG) 34 (6) (2015) 1–16. doi:10.1145/2816795.2818013
-
[11]
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, M. J. Black, Expressive body capture: 3D hands, face, and body from a single image, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10975–10985. doi:10.1109/CVPR.2019.01123
-
[12]
F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, M. J. Black, Keep it SMPL: Automatic estimation of 3D human pose and shape from a single im- age, in: European Conference on Computer Vision (ECCV), 2016, pp. 561–578. doi:10.1007/978-3-319-46454-1_34
-
[13]
Center -based 3D Object Detection and Tracking,
A. Zanfir, E. G. Bazavan, M. Zanfir, W. T. Freeman, R. Sukthankar, C. Sminchis- escu, Neural descent for visual 3D human pose and shape, in: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14484– 14493. doi:10.1109/CVPR46437.2021.01425
-
[14]
G. Pavlakos, L. Zhu, X. Zhou, K. Daniilidis, Learning to estimate 3D hu- man pose and shape from a single color image, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 459–468. doi:10.1109/CVPR.2018.00055. 29
-
[16]
L. Liu, Y . Gao, J. Sun, J. Chen, Single-image 3d human pose and shape estimation enhanced by clothed 3d human reconstruction, in: International Symposium on Artificial Intelligence and Robotics, 2023, pp. 33–44
2023
-
[17]
Y . Gao, L. Liu, Y . Li, C. Gao, Y . Liu, J. Chen, Clothhmr: 3D mesh recovery of humans in diverse clothing from single image, in: International Conference on Multimedia Retrieval (ICMR), Association for Computing Machinery, 2025, p. 368–377. doi:10.1145/3731715.3733288
-
[19]
Y . Xiu, J. Yang, D. Tzionas, M. J. Black, ICON: Implicit clothed humans obtained from normals, in: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2022, pp. 13296–13306. doi:10.1109/TPAMI.2021.3050505
-
[20]
X. Yang, Y . Luo, Y . Xiu, W. Wang, H. Xu, Z. Fan, D-IF: Uncertainty- aware human digitization via implicit distribution field, in: IEEE/CVF International Conference on Computer Vision, 2023, pp. 9122–9132. doi:10.1109/ICCV51070.2023.00837
-
[21]
Zhang, L
Z. Zhang, L. Sun, Z. Yang, L. Chen, Y . Yang, Global-correlated 3D-decoupling transformer for clothed avatar reconstruction, in: Advances in Neural Information Processing Systems (NeurIPS), 2023, pp. 7818 – 7830
2023
-
[22]
Y . Xiu, J. Yang, X. Cao, D. Tzionas, M. J. Black, ECON: Explicit clothed humans optimized via normal integration, in: IEEE/CVF Conference 30 on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 512–523. doi:10.1109/CVPR52729.2023.00057
-
[23]
L. Liu, Y . Li, Y . Gao, C. Gao, Y . Liu, J. Chen, VS: Reconstructing clothed 3D human from single image via vertex shift, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 10498–10507. doi:10.1109/CVPR52733.2024.00999
-
[24]
Y . Feng, V . Choutas, T. Bolkart, D. Tzionas, M. J. Black, Collaborative regression of expressive bodies using moderation, in: International Conference on 3D Vision (3DV), 2021, pp. 792–804
2021
-
[25]
A. O. Balan, L. Sigal, M. J. Black, J. E. Davis, H. W. Haussecker, Detailed human shape and pose from images, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2007, pp. 1–8. doi:10.1109/CVPR.2007.383340
-
[26]
D. Anguelov, P. Srinivasan, D. Koller, S. Thrun, J. Rodgers, J. Davis, SCAPE: Shape completion and animation of people, ACM Transactions on Graphics (TOG) 24 (3) (2005) 408–416. doi:10.1145/1073204.1073207
-
[27]
M. Loper, N. Mahmood, M. J. Black, MoSh: motion and shape cap- ture from sparse markers, ACM Trans. Graph. 33 (6) (Nov. 2014). doi:10.1145/2661229.2661273
-
[28]
C. Ionescu, D. Papava, V . Olaru, C. Sminchisescu, Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 36 (7) (2013) 1325–1339. doi:10.1109/TPAMI.2013.248
-
[29]
T. von Marcard, R. Henschel, M. J. Black, B. Rosenhahn, G. Pons-Moll, Re- covering accurate 3D human pose in the wild using imus and a moving cam- era, in: European Conference on Computer Vision (ECCV), 2018, p. 614–631. doi:10.1007/978-3-030-01249-6_37
-
[30]
URL https: //doi.org/10.1109/3DV.2017.00081
D. Mehta, H. Rhodin, D. Casas, P. Fua, O. Sotnychenko, W. Xu, C. Theobalt, Monocular 3D human pose estimation in the wild using improved cnn super- 31 vision, in: International Conference on 3D Vision (3DV), 2017, pp. 506–516. doi:10.1109/3DV .2017.00064
work page doi:10.1109/3dv 2017
-
[31]
Q. Ma, J. Yang, A. Ranjan, S. Pujades, G. Pons-Moll, S. Tang, M. J. Black, Learning to dress 3d people in generative clothing, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 6469–6478. doi:10.1109/CVPR42600.2020.00650
-
[32]
RenderPeople, www.renderpeople.com (2018)
2018
-
[33]
T. Yu, Z. Zheng, K. Guo, P. Liu, Q. Dai, Y . Liu, Function4D: Real-time human volumetric capture from very sparse consumer RGBD sensors, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 5746–5756. doi:10.1109/CVPR46437.2021.00569
-
[34]
M. Kocabas, N. Athanasiou, M. J. Black, Vibe: Video inference for human body pose and shape estimation, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5252–5262. doi:10.1109/CVPR42600.2020.00530
-
[35]
S. K. Dwivedi, N. Athanasiou, M. Kocabas, M. J. Black, Learning to regress bodies from images using differentiable semantic rendering, in: IEEE/CVF In- ternational Conference on Computer Vision (ICCV), 2021, pp. 11250–11259. doi:10.1109/ICCV48922.2021.01106
-
[36]
J. Li, C. Xu, Z. Chen, S. Bian, L. Yang, C. Lu, HybrIK: A hybrid analytical- neural inverse kinematics solution for 3D human pose and shape estimation, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 3382–3392. doi:10.1109/CVPR46437.2021.00339
-
[37]
H. Choi, G. Moon, J. Park, K. M. Lee, Learning to estimate robust 3D human mesh from in-the-wild crowded scenes, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1465–1474. doi:10.1109/CVPR52688.2022.00153. 32
-
[38]
Y . Liu, Z. Zhang, Stgformer: Spatio-temporal graphformer for 3d hu- man pose estimation in video, Pattern Recognition 171 (2026) 112239. doi:10.1016/j.patcog.2025.112239
-
[39]
Y . Luo, C. Yuan, L. Gao, W. Xu, X. Yang, P. Wang, Fatnet: Feature-alignment transformer network for human pose transfer, Pattern Recognition 165 (2025) 111626. doi:10.1016/j.patcog.2025.111626
-
[40]
C. Lassner, J. Romero, M. Kiefel, F. Bogo, M. J. Black, P. V . Gehler, Unite the People: Closing the loop between 3D and 2D human representations, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6050–6059. doi:10.1109/CVPR.2017.500
-
[41]
X. Ma, J. Su, C. Wang, W. Zhu, Y . Wang, 3D human mesh estimation from virtual markers, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 534–543. doi:10.1109/CVPR52729.2023.00059
-
[42]
Sengupta, I
A. Sengupta, I. Budvytis, R. Cipolla, Synthetic training for accurate 3D human pose and shape estimation in the wild, in: British Machine Vision Conference (BMVC), 2020
2020
-
[43]
Y . Zhou, M. Habermann, I. Habibie, A. Tewari, C. Theobalt, F. Xu, Monocular real-time full body capture with inter-part correlations, in: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 4809–4820. doi:10.1109/CVPR46437.2021.00478
-
[44]
Doersch, A
C. Doersch, A. Zisserman, Sim2real transfer learning for 3D human pose estima- tion: motion to the rescue, Curran Associates Inc., Red Hook, NY , USA, 2019
2019
-
[45]
R. A. Güler, N. Neverova, I. Kokkinos, Densepose: Dense human pose estimation in the wild, in: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018, pp. 7297–7306. doi:10.1109/CVPR.2018.00762
-
[46]
Center -based 3D Object Detection and Tracking,
Y . Jafarian, H. S. Park, Learning high fidelity depths of dressed humans by watching social media dance videos, in: IEEE/CVF Conference on 33 Computer Vision and Pattern Recognition (CVPR), 2021, pp. 12748–12757. doi:10.1109/CVPR46437.2021.01256
-
[48]
Bootstrapping SparseFormers from vision foundation models
Z. Zhang, Z. Yang, Y . Yang, SIFU: Side-view conditioned implicit function for real-world usable clothed human reconstruction, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 9936–9947. doi:10.1109/CVPR52733.2024.00948
-
[49]
Z. Huang, S. M. Erfani, S. Lu, M. Gong, Efficient neural implicit represen- tation for 3D human reconstruction, Pattern Recognition 156 (2024) 110758. doi:10.1016/j.patcog.2024.110758
-
[50]
R. B. Neupane, K. Li, Z. Mao, High-fidelity 3D reconstruction via unified nerf- mesh optimization with geometric and color consistency, Pattern Recognition 170 (2026) 112071. doi:10.1016/j.patcog.2025.112071
-
[51]
J. Pan, X. Li, J. Bai, J. Dai, Litenerfavatar: A lightweight nerf with local fea- ture learning for dynamic human avatar, Pattern Recognition 170 (2026) 112008. doi:10.1016/j.patcog.2025.112008
-
[52]
URLhttps://doi.org/10.1109/ICCV.2019.00943
S. Saito, Z. Huang, R. Natsume, S. Morishima, A. Kanazawa, H. Li, PIFu: Pixel-aligned implicit function for high-resolution clothed human digitization, in: IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 2304–2314. doi:10.1109/ICCV .2019.00239
-
[53]
Huang, H
J. Huang, H. Su, L. J. Guibas, Robust watertight manifold surface generation method for ShapeNet models, ArXiv (2018)
2018
-
[54]
T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, in: International Conference on Learning Representations (ICLR), 2016. 34
2016
-
[55]
Hanocka, A
R. Hanocka, A. Hertz, N. Fish, R. Giryes-Or, S. Fleishman, Daniel, MeshCNN: A network with an edge, ACM Transactions on Graphics (TOG) 38 (4) (2019) 90:1–90:12. 35
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.