AgentGrounder: Zero-Shot 3D Visual Pointcloud Grounding using Multimodal Language Models
Pith reviewed 2026-06-29 22:44 UTC · model grok-4.3
The pith
AgentGrounder grounds natural language descriptions to objects in 3D point clouds without task-specific training by building an object lookup table offline and using an agent for selective retrieval and scoring online.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
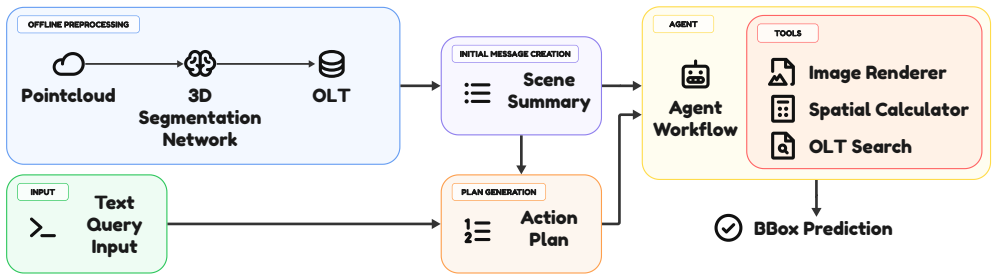
AgentGrounder is a zero-shot 3D visual grounding framework that operates directly on colored point clouds without task-specific 3D training. Our approach follows a two-stage design: an offline stage that applies a 3D model to build an Object Lookup Table with instance IDs, semantic labels, and 3D bounding boxes, and an online tool-driven agent that decomposes each query, retrieves only relevant candidates from the OLT, performs geometric scoring, and triggers image rendering on demand when additional visual evidence is required. This design reduces cascading matching errors and improves context-window efficiency by avoiding prompts overloaded with irrelevant objects.
What carries the argument
The Object Lookup Table paired with a tool-driven agent that decomposes queries, retrieves candidates, applies geometric scoring, and conditionally renders images for extra visual cues.
If this is right
- The selective retrieval reduces cascading matching errors compared with fixed anchor-target pipelines.
- Avoiding irrelevant objects in prompts improves context-window efficiency for the language model.
- The method produces +2.5% Acc@0.5 on ScanRefer and +6.3% on Nr3D over SeeGround, with a +6.3% gain on Nr3D view-independent queries.
- The combination of geometric reasoning and adaptive visual inspection supports open-vocabulary 3D grounding.
Where Pith is reading between the lines
- If a more accurate 3D segmentation model replaces the current offline step, the overall grounding accuracy would likely increase because the agent cannot recover from missed or mislabeled objects.
- The selective candidate retrieval could scale to much larger scenes where including every object would exceed language-model context limits.
- The on-demand rendering step suggests the framework may handle queries about color, material, or viewpoint-sensitive properties better than purely geometric baselines.
Load-bearing premise
The offline 3D segmentation step must correctly identify and label all relevant objects with accurate bounding boxes, because later retrieval and scoring steps have no way to fix segmentation mistakes.
What would settle it
Evaluating AgentGrounder on ScanRefer and Nr3D under the same zero-shot protocol as SeeGround and measuring no gain or a loss in Acc@0.5 would falsify the reported performance advantage.
Figures

read the original abstract
3D Visual Grounding (3DVG) is an essential capability for embodied AI, requiring agents to localize objects in 3D scenes based on natural language descriptions. Recent zero-shot methods leverage 2D vision-language models (LVLMs). However, they often rely on existing sets of multi-view images and struggle with the limited semantic and spatial details provided by standard 3D segmentation tools. We present $\textbf{AgentGrounder}$, a zero-shot 3D visual grounding framework that operates directly on colored point clouds without task-specific 3D training. Our approach follows a two-stage design: (1) an offline stage that applies 3D model to build an Object Lookup Table (OLT) with instance IDs, semantic labels, 3D bounding boxes; and (2) an online tool-driven agent that decomposes each query, retrieves only relevant candidates from the OLT, performs geometric scoring, and triggers image rendering on demand when additional visual evidence (e.g., color, material, or viewpoint-sensitive cues) is required. Compared with fixed anchor-target matching pipelines, this design reduces cascading matching errors and improves context-window efficiency by avoiding prompts overloaded with irrelevant objects. We evaluate on ScanRefer and Nr3D under a zero-shot setting and observe consistent improvements over SeeGround in our setup, including +2.5% Acc@0.5 on ScanRefer and +6.3% on Nr3D, with a notable +6.3% gain on Nr3D view-independent queries. These results show that combining selective retrieval, geometric reasoning, and adaptive visual inspection yields a practical and robust foundation for open-vocabulary 3D grounding. Our code is available at https://github.com/be2rlab/AgentGrounder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AgentGrounder, a zero-shot 3D visual grounding framework operating directly on colored point clouds. It uses a two-stage design consisting of (1) an offline stage that applies a 3D model to construct an Object Lookup Table (OLT) containing instance IDs, semantic labels, and 3D bounding boxes, and (2) an online tool-driven agent that decomposes natural language queries, selectively retrieves relevant OLT candidates, applies geometric scoring, and triggers on-demand image rendering for additional visual evidence such as color or viewpoint cues. The central claim is that this selective-retrieval design reduces cascading matching errors relative to fixed anchor-target pipelines and yields empirical gains of +2.5% Acc@0.5 on ScanRefer and +6.3% on Nr3D (including view-independent queries) over SeeGround under a true zero-shot regime without task-specific 3D training.
Significance. If the reported gains are shown to be robust, the combination of selective OLT retrieval, geometric reasoning, and adaptive rendering could supply a practical, training-free route to open-vocabulary 3D grounding that improves both accuracy and context-window efficiency. Public code release is noted as a reproducibility strength.
major comments (2)
- [Abstract] Abstract, paragraph 2: The claim that the two-stage design 'reduces cascading matching errors' presupposes that the offline OLT already contains the correct referent instance for every query. No evaluation or failure-rate analysis of the upstream 3D segmentation step on ScanRefer or Nr3D is provided; because partial scans and ambiguous boundaries are common on these benchmarks, any missed or mislabeled object leaves the agent with an empty candidate pool, rendering downstream retrieval and scoring irrelevant to the reported +2.5% and +6.3% gains.
- [Abstract] Abstract: The numeric improvements are stated without error bars, number of runs, statistical significance tests, exact baseline re-implementations, or component ablations, preventing verification that the gains are attributable to the selective-retrieval and on-demand-rendering mechanisms rather than implementation details or dataset splits.
minor comments (1)
- [Abstract] Abstract, paragraph 2: 'applies 3D model' is missing the indefinite article and should read 'applies a 3D model'.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 2: The claim that the two-stage design 'reduces cascading matching errors' presupposes that the offline OLT already contains the correct referent instance for every query. No evaluation or failure-rate analysis of the upstream 3D segmentation step on ScanRefer or Nr3D is provided; because partial scans and ambiguous boundaries are common on these benchmarks, any missed or mislabeled object leaves the agent with an empty candidate pool, rendering downstream retrieval and scoring irrelevant to the reported +2.5% and +6.3% gains.
Authors: We agree that AgentGrounder cannot recover if the upstream 3D segmentation model omits the referent from the OLT. Our claim about reducing cascading matching errors applies only to the online stage's selective retrieval among OLT candidates (avoiding context overload), not to segmentation failures. Such failures affect any method relying on 3D instance segmentation as a prerequisite. We will add an analysis of OLT coverage (fraction of queries where the referent appears in the OLT) on ScanRefer and Nr3D. revision: yes
-
Referee: [Abstract] Abstract: The numeric improvements are stated without error bars, number of runs, statistical significance tests, exact baseline re-implementations, or component ablations, preventing verification that the gains are attributable to the selective-retrieval and on-demand-rendering mechanisms rather than implementation details or dataset splits.
Authors: The gains reflect single-run zero-shot evaluations; multiple runs and significance tests were omitted due to rendering and agent compute costs. Baselines follow the original papers. We will expand the experimental section with protocol details, component ablations for selective retrieval and geometric scoring, and a note on the single-run setup. The released code supports independent checks. revision: partial
Circularity Check
No significant circularity; method relies on external pretrained models and benchmarks without self-referential reductions.
full rationale
The paper presents a two-stage zero-shot 3D grounding framework (offline OLT construction via pretrained 3D model + online agent using LVLMs for selective retrieval and geometric scoring). No equations, fitted parameters, or 'predictions' appear in the text. Reported gains (+2.5% Acc@0.5 on ScanRefer, +6.3% on Nr3D) are measured against external public benchmarks and a prior method (SeeGround), with no reduction of results to quantities defined inside the paper. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. The derivation chain is therefore self-contained against external components.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing 3D segmentation tools produce reliable instance IDs, semantic labels, and bounding boxes for building the OLT
invented entities (1)
-
Object Lookup Table (OLT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gˆ 3-lq: Marrying hyperbolic alignment with explicit semantic-geometric modeling for 3d visual grounding,
Y . Wang, Y . Li, and S. Wang, “Gˆ 3-lq: Marrying hyperbolic alignment with explicit semantic-geometric modeling for 3d visual grounding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 917–13 926
2024
-
[2]
Multi-branch collaborative learning network for 3d visual grounding,
Z. Qian et al., “Multi-branch collaborative learning network for 3d visual grounding,” inEuropean Con- ference on Computer Vision, Springer, 2024, pp. 381– 398
2024
-
[3]
Chat-scene: Bridging 3d scene and large language models with object identifiers,
H. Huang et al., “Chat-scene: Bridging 3d scene and large language models with object identifiers,” Advances in Neural Information Processing Systems, vol. 37, pp. 113 991–114 017, 2024
2024
-
[4]
Video-3d llm: Learning position-aware video representation for 3d scene understanding,
D. Zheng, S. Huang, and L. Wang, “Video-3d llm: Learning position-aware video representation for 3d scene understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2025, pp. 8995–9006
2025
-
[5]
Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,
J. Yang et al., “Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,” in2024 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2024, pp. 7694–7701
2024
-
[6]
Visual programming for zero-shot open- vocabulary 3d visual grounding,
Z. Yuan, J. Ren, C.-M. Feng, H. Zhao, S. Cui, and Z. Li, “Visual programming for zero-shot open- vocabulary 3d visual grounding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 623–20 633
2024
-
[7]
Vlm-grounder: A vlm agent for zero-shot 3d visual grounding,
R. Xu, Z. Huang, T. Wang, Y . Chen, J. Pang, and D. Lin, “Vlm-grounder: A vlm agent for zero-shot 3d visual grounding,” inConference on Robot Learning, PMLR, 2025, pp. 3961–3985
2025
-
[8]
See- ground: See and ground for zero-shot open-vocabulary 3d visual grounding,
R. Li, S. Li, L. Kong, X. Yang, and J. Liang, “See- ground: See and ground for zero-shot open-vocabulary 3d visual grounding,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 3707–3717
2025
-
[9]
Solving zero-shot 3d visual grounding as constraint satisfaction problems,
Q. Yuan, K. Li, and J. Zhang, “Solving zero-shot 3d visual grounding as constraint satisfaction problems,” arXiv preprint arXiv:2411.14594, 2024
-
[10]
Sort3d: Spatial object-centric rea- soning toolbox for zero-shot 3d grounding using large language models,
N. Zantout et al., “Sort3d: Spatial object-centric rea- soning toolbox for zero-shot 3d grounding using large language models,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2025, pp. 2201–2208
2025
-
[11]
Transcrib3d: 3d referring expression resolution through large language models,
J. Fang et al., “Transcrib3d: 3d referring expression resolution through large language models,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2024, pp. 9737– 9744
2024
-
[12]
Scanrefer: 3d object localization in rgb-d scans using natural lan- guage,
D. Z. Chen, A. X. Chang, and M. Nießner, “Scanrefer: 3d object localization in rgb-d scans using natural lan- guage,” inEuropean conference on computer vision, Springer, 2020, pp. 202–221
2020
-
[13]
Referit3d: Neural listeners for fine- grained 3d object identification in real-world scenes,
P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. Guibas, “Referit3d: Neural listeners for fine- grained 3d object identification in real-world scenes,” inEuropean conference on computer vision, Springer, 2020, pp. 422–440
2020
-
[14]
Four ways to improve verbo-visual fusion for dense 3d visual grounding,
O. Unal, C. Sakaridis, S. Saha, and L. Van Gool, “Four ways to improve verbo-visual fusion for dense 3d visual grounding,” inEuropean Conference on Computer Vision, Springer, 2024, pp. 196–213
2024
-
[15]
arXiv preprint arXiv:2306.13631 (2023) 1
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “Openmask3d: Open- vocabulary 3d instance segmentation,”arXiv preprint arXiv:2306.13631, 2023
-
[16]
Isbnet: A 3d point cloud instance segmentation network with instance-aware sampling and box-aware dynamic con- volution,
T. D. Ngo, B.-S. Hua, and K. Nguyen, “Isbnet: A 3d point cloud instance segmentation network with instance-aware sampling and box-aware dynamic con- volution,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 13 550–13 559
2023
-
[17]
Sam3d: Segment anything in 3d scenes,
Y . Yang, X. Wu, T. He, H. Zhao, and X. Liu, “Sam3d: Segment anything in 3d scenes,”arXiv preprint arXiv:2306.03908, 2023
-
[18]
Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,
P. Nguyen et al., “Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 4018–4028
2024
-
[19]
Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking,
P. Nguyen, M. Luu, A. Tran, C. Pham, and K. Nguyen, “Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 3636–3645
2025
-
[20]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu et al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Au- tomation (ICRA), IEEE, 2024, pp. 5021–5028
2024
-
[21]
Conceptfusion: Open-set multimodal 3d mapping,
K. M. Jatavallabhula et al., “Conceptfusion: Open-set multimodal 3d mapping,”arXiv preprint arXiv:2302.07241, 2023
-
[22]
Phygrasp: Generalizing robotic grasp- ing with physics-informed large multimodal models,
D. Guo et al., “Phygrasp: Generalizing robotic grasp- ing with physics-informed large multimodal models,” in2025 IEEE/RSJ International Conference on In- telligent Robots and Systems (IROS), IEEE, 2025, pp. 14 915–14 922
2025
-
[23]
Zero-shot object navigation with vision-language models reasoning,
C. Wen et al., “Zero-shot object navigation with vision-language models reasoning,” inInternational Conference on Pattern Recognition, Springer, 2025, pp. 389–404
2025
-
[24]
Iref-vla: A benchmark for interactive referen- tial grounding with imperfect language in 3d scenes,
H. Zhang, N. Zantout, P. Kachana, J. Zhang, and W. Wang, “Iref-vla: A benchmark for interactive referen- tial grounding with imperfect language in 3d scenes,” in2025 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2025, pp. 1677–1683
2025
-
[25]
Sceneverse: Scaling 3d vision-language learning for grounded scene understanding,
B. Jia et al., “Sceneverse: Scaling 3d vision-language learning for grounded scene understanding,” inEuro- pean Conference on Computer Vision, Springer, 2024, pp. 289–310
2024
-
[26]
Mask3d: Mask transformer for 3d semantic instance segmentation,
J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3d: Mask transformer for 3d semantic instance segmentation,” in2023 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2023, pp. 8216–8223
2023
-
[27]
A. Yang et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Using ollama,
F. S. Marcondes, A. Gala, R. Magalh ˜aes, F. Perez de Britto, D. Dur ˜aes, and P. Novais, “Using ollama,” in Natural Language Analytics with Generative Large- Language Models: A Practical Approach with Ollama and Open-Source LLMs, Springer, 2025, pp. 23–35
2025
-
[29]
Chase,Langchain,https : / / github
H. Chase,Langchain,https : / / github . com / langchain - ai / langchain, Version accessed via GitHub, Oct. 2022
2022
-
[30]
Gpt4scene: Understand 3d scenes from videos with vision-language models,
Z. Qi, Z. Zhang, Y . Fang, J. Wang, and H. Zhao, “Gpt4scene: Understand 3d scenes from videos with vision-language models,”arXiv preprint arXiv:2501.01428, 2025
-
[31]
Mikasa: Multi-key-anchor & scene-aware trans- former for 3d visual grounding,
C.-P. Chang, S. Wang, A. Pagani, and D. Stricker, “Mikasa: Multi-key-anchor & scene-aware trans- former for 3d visual grounding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 131–14 140
2024
-
[32]
Language conditioned spatial relation rea- soning for 3d object grounding,
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev, “Language conditioned spatial relation rea- soning for 3d object grounding,”Advances in neural information processing systems, vol. 35, pp. 20 522– 20 535, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.