Does Continued Pretraining on a Learner Corpus Improve Automated Essay Scoring on English Proficiency Tests? Evidence from EFCAMDAT
Pith reviewed 2026-06-29 21:58 UTC · model grok-4.3
The pith
Targeted continued pretraining on CEFR-aligned learner writing improves in-domain automated essay scoring but does not reliably boost cross-dataset transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
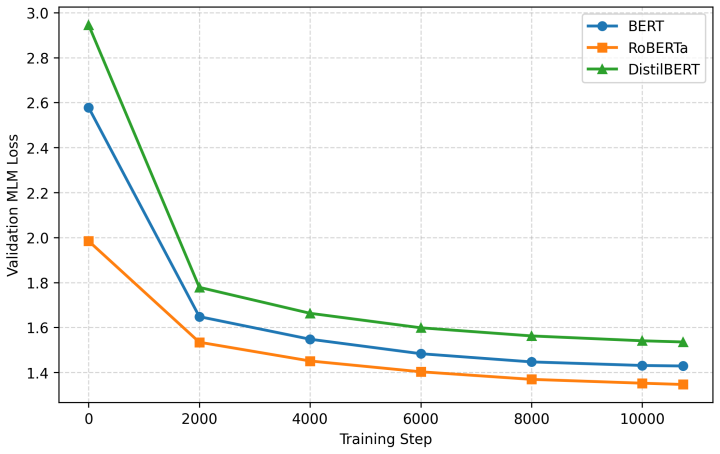
Domain-adaptive continued pretraining on the full EFCAMDAT learner corpus produces mixed effects on transformer-based automated essay scoring for FCE and IELTS. When pretraining data are instead restricted to CEFR-aligned subsets that match the target test's proficiency band, downstream scoring improves more consistently on in-domain tasks, with the clearest gains for FCE using B1-B2 data. These targeted gains, however, do not reliably enhance few-shot cross-dataset transfer between FCE and IELTS.
What carries the argument
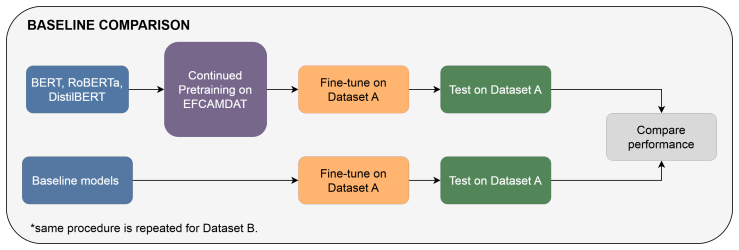
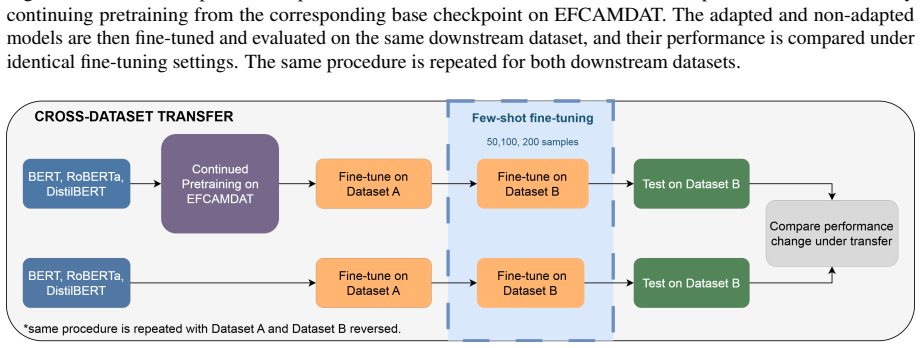
Proficiency-based ablation that selects CEFR-aligned subsets of EFCAMDAT for continued pretraining, compared against full-corpus DAPT on three transformer encoders.
If this is right
- AES systems for a specific proficiency test can be improved by continued pretraining on learner data drawn from the same CEFR band.
- Full-corpus learner pretraining is unlikely to be the default recipe for every downstream scoring task.
- Cross-dataset transfer between different English exams will require additional techniques beyond simple continued pretraining on any single learner corpus.
- Alignment checks on proficiency, genre, and purpose should precede any decision to apply DAPT to an AES model.
Where Pith is reading between the lines
- If alignment is the decisive factor, then constructing small, purpose-matched learner subsets may be more efficient than scaling up general learner corpora.
- The finding suggests that future AES work could treat continued pretraining as a data-selection problem rather than a scale problem.
- One testable extension is to measure whether adding genre or purpose filters on top of CEFR alignment further stabilizes transfer between exams.
Load-bearing premise
The mixed results of full-corpus DAPT are caused by mismatches in proficiency, genre, and communicative purpose between EFCAMDAT and the FCE or IELTS test sets.
What would settle it
A controlled experiment that applies the same CEFR-subset pretraining to a new English proficiency test whose genre and communicative purpose are deliberately mismatched with EFCAMDAT and measures whether in-domain gains disappear.
Figures
read the original abstract
Recent automated essay scoring (AES) studies increasingly use pretrained transformer models, but these models are usually pretrained on general-domain English and may under-represent second-language learner writing. This study investigates whether domain-adaptive continued pretraining (DAPT) on the EFCAMDAT learner corpus improves transformer-based AES for English proficiency tests. We apply DAPT to three transformer encoders and evaluate them on FCE and IELTS in both in-domain scoring and few-shot cross-dataset transfer. Full-corpus DAPT produces mixed results across models, datasets, and metrics. Further analyses suggest that these mixed effects are partly explained by mismatches in proficiency, genre, and communicative purpose between EFCAMDAT and the downstream datasets. A proficiency-based ablation shows that targeted DAPT using CEFR-aligned subsets improves downstream scoring more reliably than full-corpus DAPT, especially for FCE with B1--B2 data. However, these gains do not consistently improve cross-dataset transfer. Overall, the findings suggest that continued pretraining on a learner-writing corpus can benefit in-domain AES for English assessment when the pretraining data is sufficiently aligned with the downstream assessment settings. However, it does not automatically improve transferability across different English proficiency test datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether domain-adaptive continued pretraining (DAPT) on the EFCAMDAT learner corpus improves transformer-based automated essay scoring (AES) for English proficiency tests (FCE and IELTS). Full-corpus DAPT yields mixed results across models, datasets, and metrics. Further analyses attribute these to mismatches in proficiency, genre, and communicative purpose. A proficiency-based ablation finds that targeted DAPT on CEFR-aligned subsets improves in-domain scoring more reliably than full-corpus DAPT (especially FCE with B1-B2 data), though gains do not consistently aid cross-dataset transfer. The conclusion is that aligned learner data can benefit in-domain AES but does not automatically improve transferability.
Significance. If the central empirical findings hold after controls, the work provides concrete evidence on the conditions for successful DAPT in educational NLP, showing that proficiency alignment can outperform untargeted pretraining on learner corpora for AES. It contributes to the literature on domain adaptation by highlighting that data volume alone does not explain outcomes and that targeted subsets matter for in-domain performance.
major comments (2)
- [proficiency-based ablation / results section] The proficiency-based ablation (described in the abstract and results) claims that CEFR-aligned subsets improve downstream AES more reliably than full-corpus DAPT. However, CEFR subsets are necessarily smaller; without explicit size-matched controls (e.g., random subsamples of equal token count) or reporting of exact pretraining data volumes per condition, the observed gains on FCE could arise from reduced exposure to mismatched data rather than positive alignment effects. This directly undercuts the inference that mismatches explain the mixed full-corpus results.
- [abstract and results] The abstract and further analyses report mixed results for full-corpus DAPT and attribute them to mismatches in proficiency/genre/purpose, but provide no details on statistical significance tests, exact metric deltas, or full baseline comparisons. This makes it difficult to evaluate the reliability and magnitude of the reported effects supporting the central claim.
minor comments (1)
- [abstract] The abstract could more explicitly name the three transformer encoders used and the specific metrics (e.g., QWK, Pearson) for which mixed results were observed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [proficiency-based ablation / results section] The proficiency-based ablation (described in the abstract and results) claims that CEFR-aligned subsets improve downstream AES more reliably than full-corpus DAPT. However, CEFR subsets are necessarily smaller; without explicit size-matched controls (e.g., random subsamples of equal token count) or reporting of exact pretraining data volumes per condition, the observed gains on FCE could arise from reduced exposure to mismatched data rather than positive alignment effects. This directly undercuts the inference that mismatches explain the mixed full-corpus results.
Authors: We agree this is a valid concern and a limitation of the current analysis. The manuscript reports token counts per condition but does not include size-matched random subsample controls from the full corpus. It is possible the observed gains reflect reduced exposure to mismatched data. We will add these controls via additional experiments on random subsets matched in token count to the B1-B2 CEFR subset and report the comparative results to better isolate alignment effects from data volume reduction. revision: yes
-
Referee: [abstract and results] The abstract and further analyses report mixed results for full-corpus DAPT and attribute them to mismatches in proficiency/genre/purpose, but provide no details on statistical significance tests, exact metric deltas, or full baseline comparisons. This makes it difficult to evaluate the reliability and magnitude of the reported effects supporting the central claim.
Authors: The full manuscript contains tables with all model conditions and baselines (no-DAPT). However, the abstract and narrative results do not include statistical significance tests or explicit delta values. We will revise both sections to report paired significance tests (e.g., t-tests), exact metric deltas, and ensure all baseline comparisons are highlighted with effect magnitudes. revision: yes
Circularity Check
No circularity: purely empirical ablation study
full rationale
The paper reports experimental results from domain-adaptive pretraining (DAPT) on EFCAMDAT subsets followed by AES evaluation on FCE and IELTS. No equations, derivations, predictions from first principles, or parameter-fitting steps are present that could reduce to inputs by construction. All claims rest on direct empirical comparisons of model performance metrics across conditions; the proficiency-based ablation is a controlled experiment, not a self-referential definition or fitted-input prediction. No self-citation chains or uniqueness theorems are invoked as load-bearing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain-adaptive continued pretraining improves model performance on downstream tasks when pretraining data sufficiently matches the target domain in proficiency and genre.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Twelfth Language Resources and Evaluation Conference, pages 6740– 6744, Marseille, France
Diverging divergences: Examining variants of Jensen Shannon divergence for corpus compari- son tasks. InProceedings of the Twelfth Language Resources and Evaluation Conference, pages 6740– 6744, Marseille, France. European Language Re- sources Association. Xiaofei Lu. 2010. Automatic analysis of syntactic com- plexity in second language writing.Internatio...
2010
-
[2]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Flexible domain adaptation for automated essay scoring using correlated linear regression. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 431– 439, Lisbon, Portugal. Association for Computational Linguistics. Zhuang Qiu, Peizhi Yan, and Zhenguang Cai. 2024. Large language models for second language English...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
On the use of bert for automated essay scoring: Joint learning of multi-scale essay representation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 3416–3425, Seattle, United States. Association for Computational Linguistics. Helen Yannakoudakis, Ted...
2022
-
[4]
InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 180–189, Portland, Oregon, USA
A new dataset and method for automatically grading ESOL texts. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 180–189, Portland, Oregon, USA. Association for Computational Linguistics. Helen Yannakoudakis and Ronan Cummins. 2015. Eval- uating the performance of automated text s...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.