Hidden in Plain Tokens: Simply Robust, Gradient-Free Watermark for Synthetic Audio
Pith reviewed 2026-06-29 23:06 UTC · model grok-4.3
The pith
Reducing the audio tokenizer vocabulary via community detection on redundant tokens creates a gradient-free watermark with orders-of-magnitude higher detectability and built-in robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
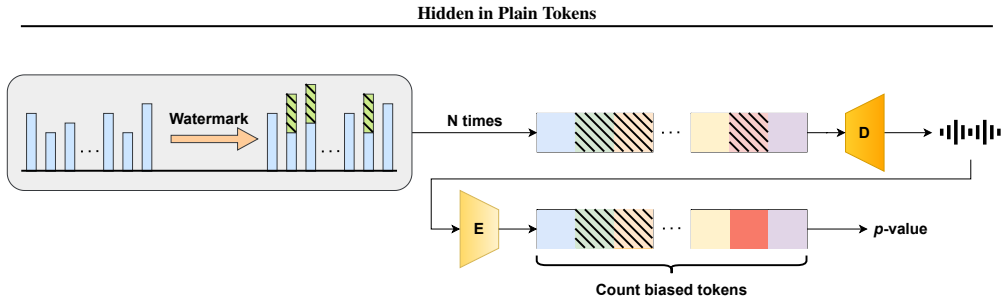
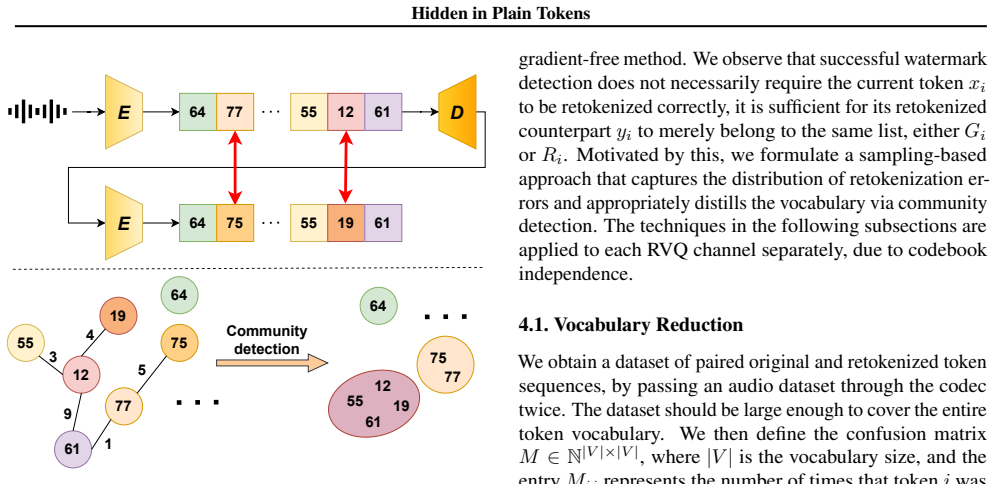
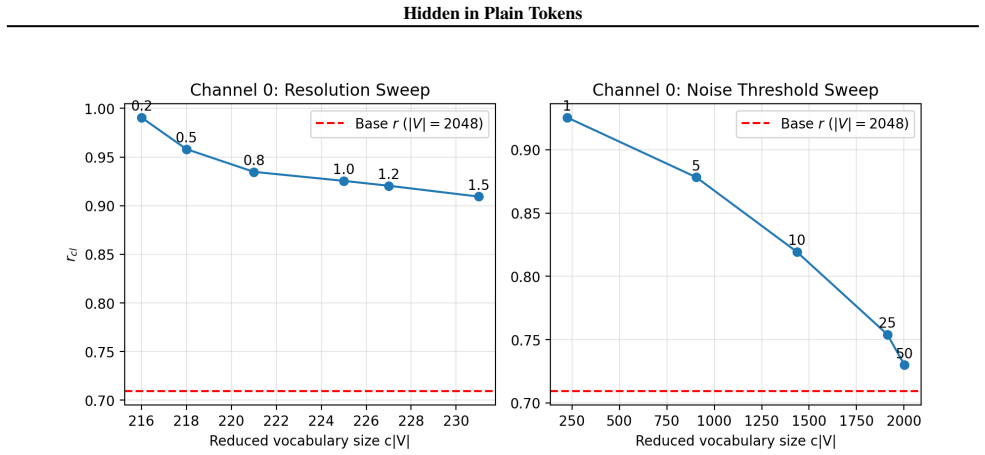
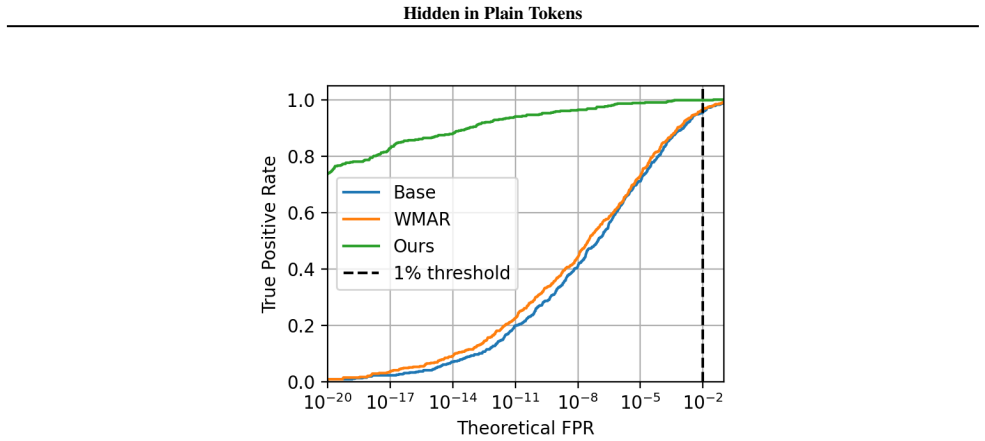
Motivated by vocabulary redundancy in discretization, the authors reduce the effective vocabulary through community detection on token redundancy; this reduction mitigates the impact of token errors on watermark detection, enabling a gradient-free method that boosts detectability by several orders of magnitude while providing built-in robustness to audio modifications and establishing a new state-of-the-art for token-level watermarks that arises directly from the nature of discrete representation learning.
What carries the argument
The reduced vocabulary obtained via community detection on token redundancy, which mitigates the impact of token errors on watermark detection.
If this is right
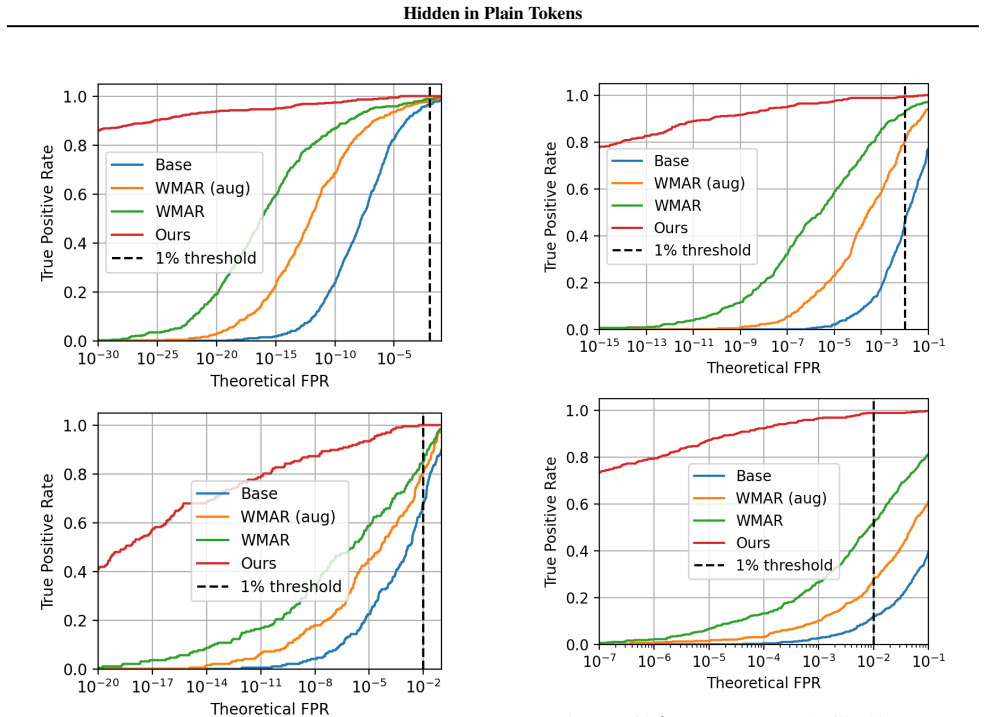
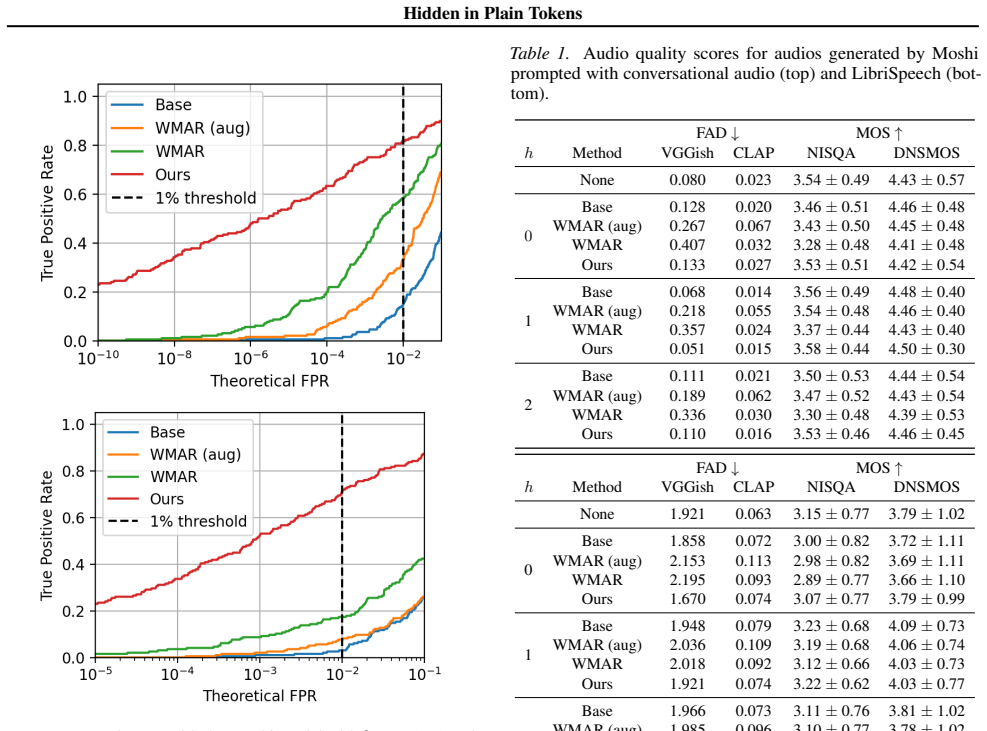
- Watermark detectability increases by several orders of magnitude compared with prior token-level methods.
- The watermark exhibits built-in robustness to audio modifications without any additional mechanisms.
- The entire procedure remains gradient-free and requires no finetuning of the modality tokenizer.
- The resulting performance sets a new state-of-the-art for token-level watermarks across multimedia modalities.
Where Pith is reading between the lines
- The same vocabulary-reduction step may transfer to other discretized continuous signals such as video frames or sensor data.
- Further gains could appear if future tokenizers are designed with explicit redundancy minimization rather than post-hoc community detection.
- Because the improvement stems from properties of discrete representations, advances in representation learning may automatically strengthen watermarking performance.
Load-bearing premise
Reducing the vocabulary via community detection on token redundancy effectively mitigates the impact of token errors on watermark detection.
What would settle it
Running the watermark detection test on the same set of generated audio clips before and after the vocabulary reduction, then applying standard modifications such as compression or additive noise, and observing whether the detection rate fails to rise by multiple orders of magnitude.
Figures
read the original abstract
As policy catches up with the capabilities of generative AI, watermarking is central to content provenance efforts. Inference-time watermarks for autoregressive models are unfit for continuous modalities due to discretization inconsistencies. Existing methods overcome this by finetuning the modality tokenizers, nullifying the watermark's training-free advantage. In this work, motivated by the vocabulary redundancy of discretization, we propose an elegant solution for powerful and robust watermarking of synthetic audio. We theoretically analyze the impact of token errors on watermark detection, and effectively mitigate them using a reduced vocabulary obtained via community detection. Thorough experiments showcase that our gradient-free method can boost detectability by several orders of magnitude, while also achieving built-in robustness to audio modifications. Broadly, we discover a new state-of-the-art for token-level watermarks in multimedia, which simply arises from the nature of discrete representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims a gradient-free watermark for synthetic audio that exploits vocabulary redundancy via community detection to produce a reduced vocabulary. It theoretically analyzes token-error impact on detection and mitigates it through this reduction, yielding orders-of-magnitude detectability gains plus built-in robustness to audio edits, all without tokenizer finetuning.
Significance. If the central mechanism holds, the result would be significant: it preserves the training-free property of inference-time watermarks while extending them to continuous modalities, potentially establishing a new baseline for token-level multimedia watermarking by directly using properties of discrete representation learning.
major comments (2)
- [Abstract / theoretical analysis] Abstract (theoretical analysis paragraph): the claim that community detection on token redundancy produces a reduced vocabulary whose error statistics enable several-orders-of-magnitude detectability gains is load-bearing. The argument requires that the communities align with the actual substitution patterns induced by waveform modifications; if the detected communities instead reflect only static token co-occurrence rather than edit-induced errors, the theoretical mitigation does not transfer and the empirical boost cannot be attributed to the proposed mechanism.
- [Abstract / experiments] Abstract (experiments paragraph): the reported orders-of-magnitude gains are presented without reference to error bars, number of trials, or explicit comparison against the strongest existing token-level baselines under identical audio-edit conditions. This leaves open whether post-hoc vocabulary choices or dataset-specific redundancy drive the result rather than the community-detection step itself.
minor comments (1)
- [Abstract] Abstract: the sentence 'Broadly, we discover a new state-of-the-art' should be replaced by a precise statement of the quantitative improvement relative to prior token-level methods, with the supporting table or figure cited.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, providing clarifications and committing to revisions that strengthen the presentation of the theoretical mechanism and experimental results.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract (theoretical analysis paragraph): the claim that community detection on token redundancy produces a reduced vocabulary whose error statistics enable several-orders-of-magnitude detectability gains is load-bearing. The argument requires that the communities align with the actual substitution patterns induced by waveform modifications; if the detected communities instead reflect only static token co-occurrence rather than edit-induced errors, the theoretical mitigation does not transfer and the empirical boost cannot be attributed to the proposed mechanism.
Authors: We appreciate this important clarification request. Community detection is performed on pairwise token embedding similarities from the audio tokenizer, which encode acoustic redundancies; these similarities correlate with substitution patterns under waveform edits because edits (e.g., noise, compression) induce confusions primarily among acoustically similar tokens. The theoretical analysis then shows how the reduced vocabulary lowers effective token-error rates. We will revise the manuscript to include an explicit discussion of this alignment, supported by a new analysis comparing detected communities against empirical substitution matrices obtained from edited audio samples. revision: partial
-
Referee: [Abstract / experiments] Abstract (experiments paragraph): the reported orders-of-magnitude gains are presented without reference to error bars, number of trials, or explicit comparison against the strongest existing token-level baselines under identical audio-edit conditions. This leaves open whether post-hoc vocabulary choices or dataset-specific redundancy drive the result rather than the community-detection step itself.
Authors: We agree that additional statistical detail and controls are warranted. The revised manuscript will report all detection metrics with error bars computed over multiple independent trials (specifying the exact number of runs), and will add head-to-head comparisons against the strongest published token-level audio watermarking baselines under identical audio-edit conditions. These additions will help isolate the contribution of the community-detection procedure. revision: yes
Circularity Check
No circularity: derivation relies on external algorithms and independent theoretical analysis
full rationale
The paper motivates its method from vocabulary redundancy in discretization (an external property of tokenizers) and mitigates token errors via community detection (a standard graph algorithm) after a theoretical analysis of error impact. No equations or claims reduce a prediction or result to a fitted parameter or self-definition by construction. No load-bearing self-citations or uniqueness theorems from the authors are invoked; the central detectability claim is presented as an empirical and theoretical consequence of the proposed reduction step rather than a renaming or tautology. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The token vocabulary of audio discretization contains sufficient redundancy that community detection can produce a reduced set mitigating token errors.
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
URL https://scottaaronson. blog/?p=6823. Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., Huang, Q., Jansen, A., Roberts, A., Tagliasacchi, M., Sharifi, M., Zeghidour, N., and Frank, C. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
D., Guillaume, J.-L., Lambiotte, R., and Lefeb- vre, E
Blondel, V . D., Guillaume, J.-L., Lambiotte, R., and Lefeb- vre, E. Fast unfolding of communities in large networks. Journal of statistical mechanics: theory and experiment, 2008(10):P10008,
2008
-
[3]
Audiolm: a lan- guage modeling approach to audio generation.arXiv preprint arXiv:2209.03143,
Borsos, Z., Marinier, R., Vincent, D., Kharitonov, E., Pietquin, O., Sharifi, M., Teboul, O., Grangier, D., Tagliasacchi, M., and Zeghidour, N. Audiolm: a lan- guage modeling approach to audio generation.arXiv preprint arXiv:2209.03143,
-
[4]
Wavmark: Watermarking for audio generation.arXiv preprint arXiv:2308.12770,
Chen, G., Wu, Y ., Liu, S., Liu, T., Du, X., and Wei, F. Wavmark: Watermarking for audio generation.arXiv preprint arXiv:2308.12770,
-
[5]
K., Sch¨uldt, C., and Chatterjee, S
Cumlin, F., Liang, X., Ungureanu, V ., Reddy, C. K., Sch¨uldt, C., and Chatterjee, S. Dnsmos pro: A reduced-size dnn for probabilistic mos of speech. In25th Interspeech Con- ferece 2024, Kos Island, Greece, Sep 1 2024-Sep 5 2024, pp. 4818–4822. International Speech Communication As- sociation,
2024
-
[6]
Moshi: a speech-text foundation model for real-time dialogue
D´efossez, A., Mazar ´e, L., Orsini, M., Royer, A., P ´erez, P., J ´egou, H., Grave, E., and Zeghidour, N. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Ding, D., Ju, Z., Leng, Y ., Liu, S., Liu, T., Shang, Z., Shen, K., Song, W., Tan, X., Tang, H., et al. Kimi-audio techni- cal report.arXiv preprint arXiv:2504.18425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Du, Z., Gao, C., Wang, Y ., Yu, F., Zhao, T., Wang, H., Lv, X., Wang, H., Shi, X., An, K., et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Unbiased watermark for large language models
Hu, Z., Chen, L., Wu, X., Wu, Y ., Zhang, H., and Huang, H. Unbiased watermark for large language models. In International Conference on Learning Representations, volume 2024, pp. 45408–45436,
2024
-
[10]
Liu, A., Pan, L., Hu, X., Li, S., Wen, L., King, I., and Yu, P. S. An unforgeable publicly verifiable watermark for large language models.arXiv preprint arXiv:2307.16230, 2023a. Liu, A., Pan, L., Hu, X., Meng, S., and Wen, L. A semantic invariant robust watermark for large language models. arXiv preprint arXiv:2310.06356, 2023b. Liu, C., Zhang, J., Zhang,...
-
[11]
Mittag, G., Naderi, B., Chehadi, A., and M¨oller, S
doi: 10.14722/ndss.2024.24200. Mittag, G., Naderi, B., Chehadi, A., and M¨oller, S. Nisqa: A deep cnn-self-attention model for multidimensional speech quality prediction with crowdsourced datasets. In Proc. Interspeech 2021, pp. 2127–2131,
-
[12]
Code drift: Towards idempotent neural audio codecs
O’Reilly, P., Seetharaman, P., Su, J., Jin, Z., and Pardo, B. Code drift: Towards idempotent neural audio codecs. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[13]
Robust Speech Recognition via Large-Scale Weak Supervision
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. Robust speech recognition via large-scale weak supervision. arxiv 2022.arXiv preprint arXiv:2212.04356, 10,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Sugiura, I., Kurita, S., Oda, Y ., and Higashinaka, R. Llama- mimi: Exploring the limits of flattened speech language modeling.arXiv preprint arXiv:2509.14882v2,
-
[15]
Training-free watermarking for autoregressive image generation.arXiv preprint arXiv:2505.14673,
Tong, Y ., Pan, Z., Yang, S., and Zhou, K. Training-free watermarking for autoregressive image generation.arXiv preprint arXiv:2505.14673,
-
[16]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y ., Wang, J., Zhang, F., Wang, Y ., Li, Z., Yu, Q., et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
URL https://arxiv.org/ abs/2503.01710. Wu, S., Liu, J., Huang, Y ., Guan, H., and Zhang, S. Adver- sarial audio watermarking: Embedding watermark into deep feature. In2023 IEEE International Conference on Multimedia and Expo (ICME), pp. 61–66. IEEE,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Wu, Y ., Chen, R., Hu, Z., Chen, Y ., Guo, J., Zhang, H., and Huang, H. Distortion-free watermarks are not truly distortion-free under watermark key collisions.arXiv preprint arXiv:2406.02603,
-
[19]
A watermark for auto-regressive speech generation models
Wu, Y ., Chen, R., Milis, G., Guo, J., and Huang, H. A watermark for auto-regressive speech generation models. InProc. Interspeech, pp. 3474–3478, 2025a. Wu, Y ., Milis, G., Chen, R., and Huang, H. Robust distortion-free watermark for autoregressive audio gen- eration models.The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025...
2019
-
[20]
Provable robust watermarking for ai-generated text.arXiv preprint arXiv:2306.17439,
Zhao, X., Ananth, P., Li, L., and Wang, Y .-X. Provable robust watermarking for ai-generated text.arXiv preprint arXiv:2306.17439,
-
[21]
Extensibility Our vocabulary distillation method could in principle be applied to other multimodal autoregressive models, such as Emu3 (Wang et al., 2024)
10 Hidden in Plain Tokens A. Extensibility Our vocabulary distillation method could in principle be applied to other multimodal autoregressive models, such as Emu3 (Wang et al., 2024). Since we consider the RVQ architecture of modern audio codecs, where each channel typically has a much smaller vocabulary size than image discretizers, we hypothesize that ...
2024
-
[22]
Our proposed method is still superior to the baselines despite the different architecture and task
13 Hidden in Plain Tokens Figure 7.Experiments with the MusicGen model with h= 0 , prompted by captions describing music. Our proposed method is still superior to the baselines despite the different architecture and task. Table 7.Audio quality scores for audios generated by MusicGen with music prompts. FAD↓ h-gram Method VGGish CLAP None 0.247 0.039 h= 0 ...
2023
-
[23]
We use themedium sized checkpoint for generation, and finetune in the non-augmented setting
and LibriTTS (Zen et al., 2019), respectively. We use themedium sized checkpoint for generation, and finetune in the non-augmented setting. As watermarking parameters, we follow Jovanovi´c et al. (2025) and use γ= 0.25 everywhere and δ= 2 for Moshi and Spark-TTS. We empirically attenuated the watermark strength to achieve a better detectability-quality tr...
2019
-
[24]
(2025), we apply the watermark on the first 4 audio streams of Moshi, leaving the semantic (text) stream untouched
Jovanovi´c et al. (2025), we apply the watermark on the first 4 audio streams of Moshi, leaving the semantic (text) stream untouched. Similarly, we apply the watermark on all 4 streams of MusicGen. For the robustness experiments, we use the following diverse attack suite: •Speed perturbation:Resamples the audio to increase playback speed by a factor of 1....
2025
-
[25]
325 164 9.412 Base 1 2048 9.044 c= 1 (0.5,
2048
-
[26]
201 718 10.059 Base 1 2048 9.876 c= 2 (1.2,
2048
-
[27]
119 1540 13.391 Base 1 2048 12.099 (0.5,
2048
-
[28]
56 1628 15.843 Base 1 2048 15.230 (0.5,
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.