Learning in Low-Dimensional Subspaces: Orthogonal Bottlenecks for Reinforcement Learning
Pith reviewed 2026-06-29 22:45 UTC · model grok-4.3
The pith
A fixed orthonormal projection in RL encoders constrains features to low-dimensional subspaces while preserving expressivity and gradient dynamics above the value function's intrinsic rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a linear realizability assumption, when the bottleneck dimension exceeds the intrinsic rank of the optimal value function in feature space, the bottleneck preserves expressivity and leaves the induced gradient dynamics unchanged up to an equivalent low-dimensional parameterization.
What carries the argument
The fixed orthonormal projection that constrains encoder features to a low-dimensional subspace.
Load-bearing premise
The optimal value function is linear in the encoder features.
What would settle it
Measure the intrinsic rank of the optimal value function in feature space and check whether performance or policy quality drops when the bottleneck dimension is set below that rank but holds when set above it.
Figures

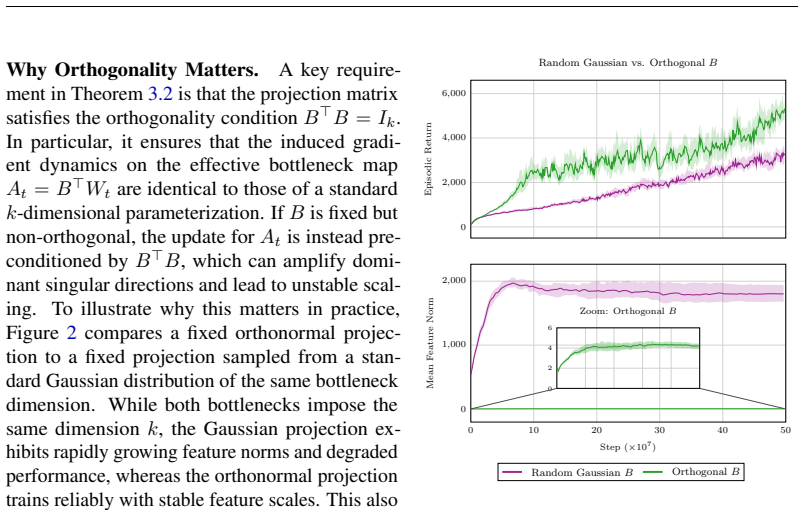
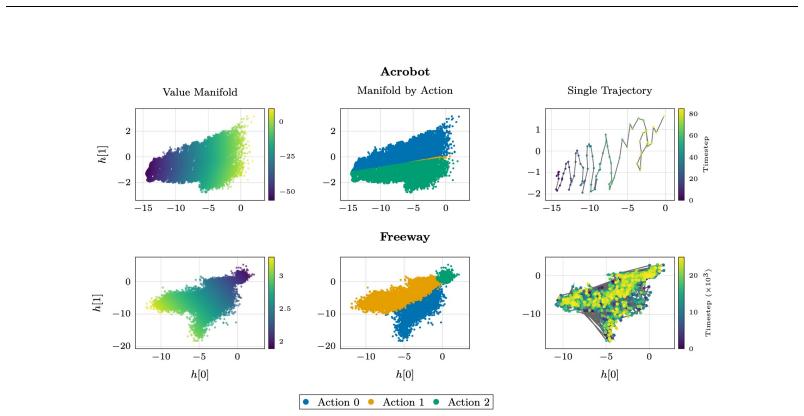
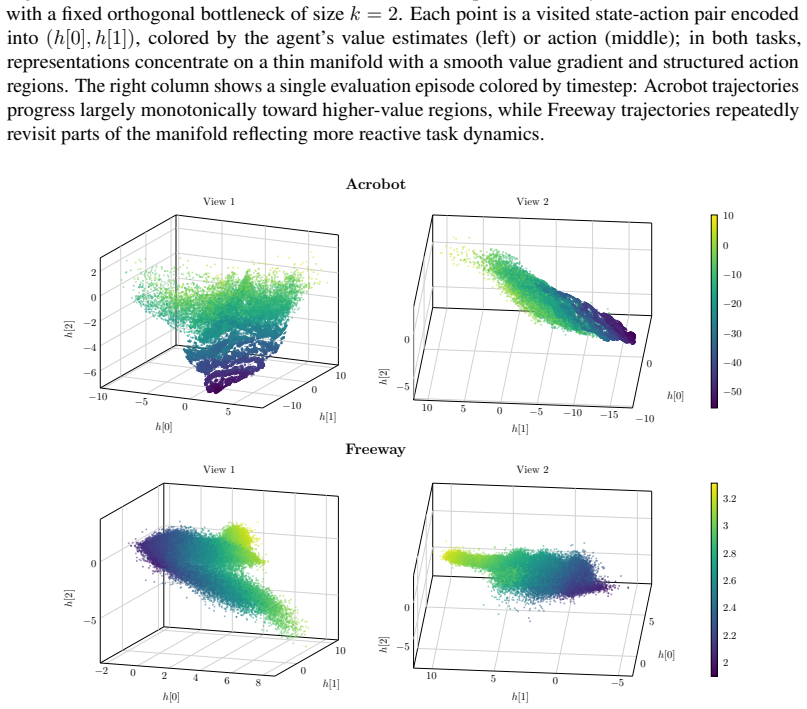
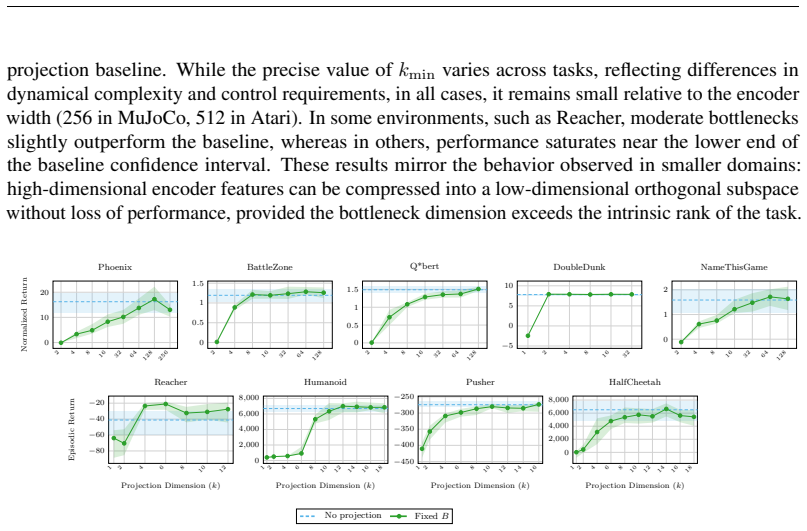
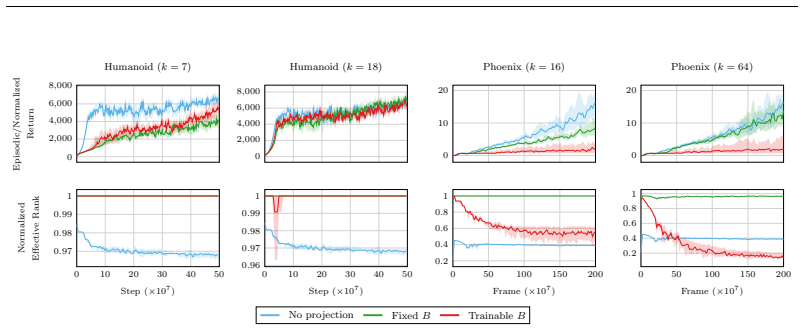
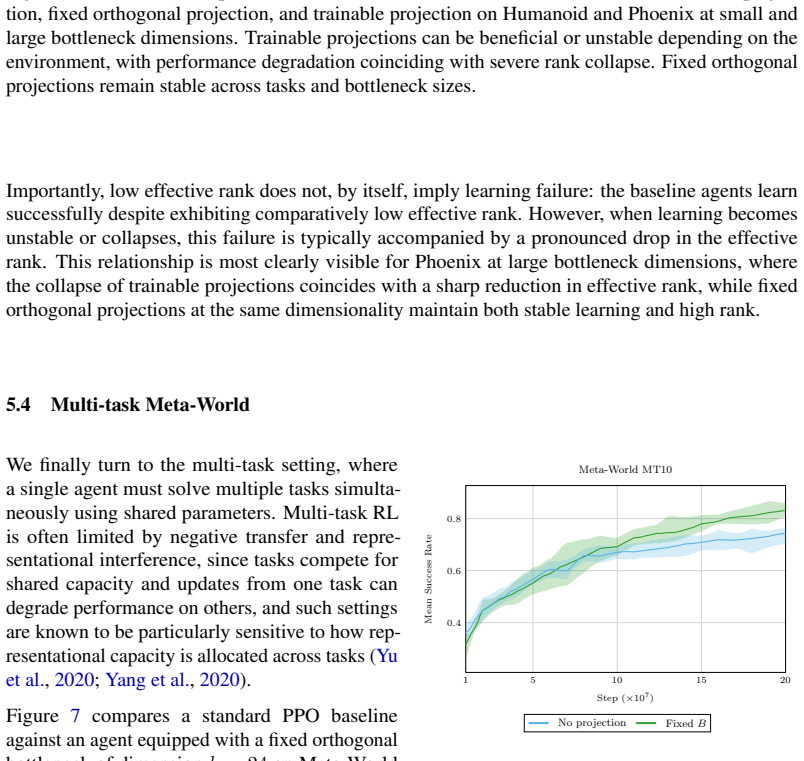
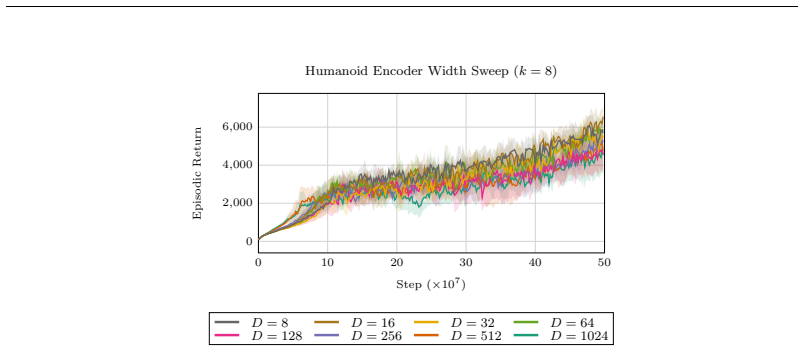
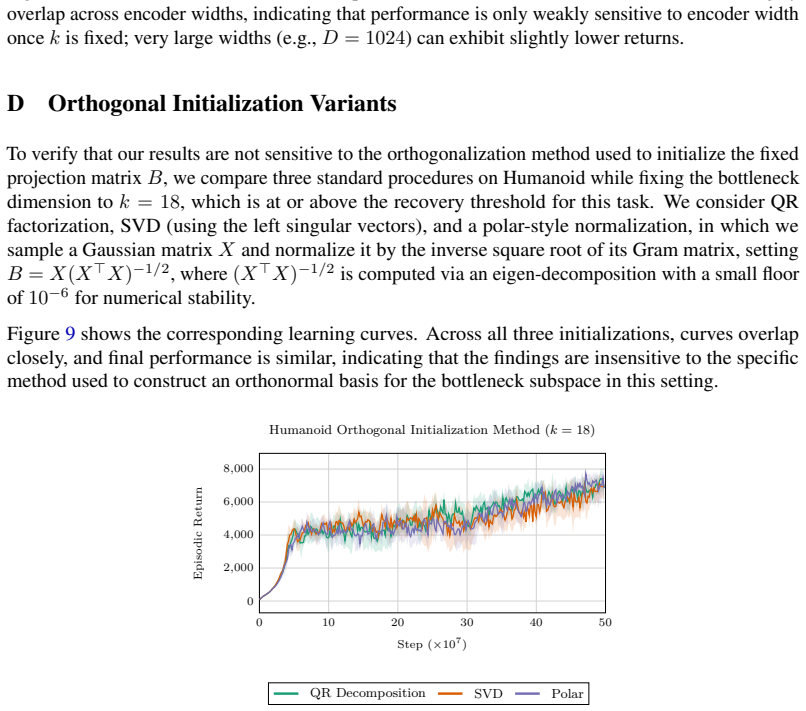
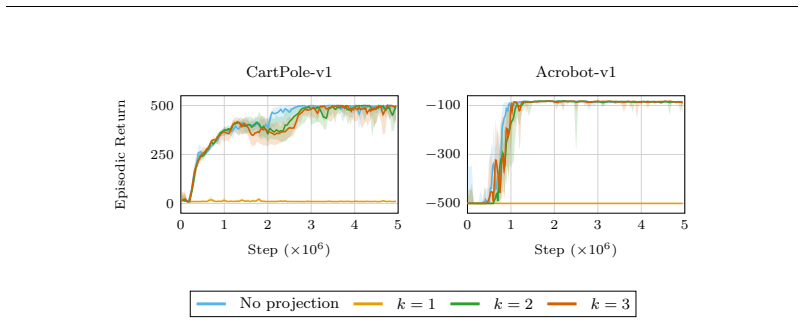
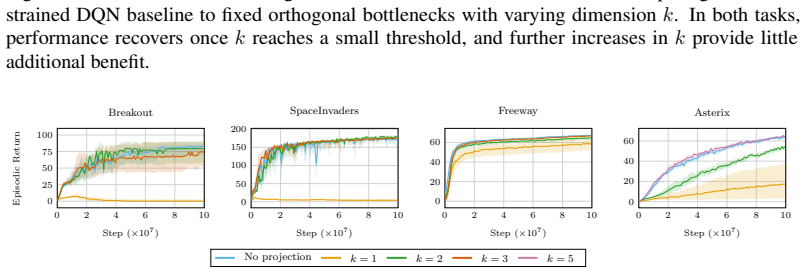
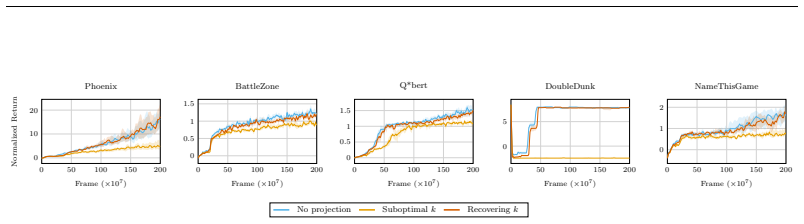
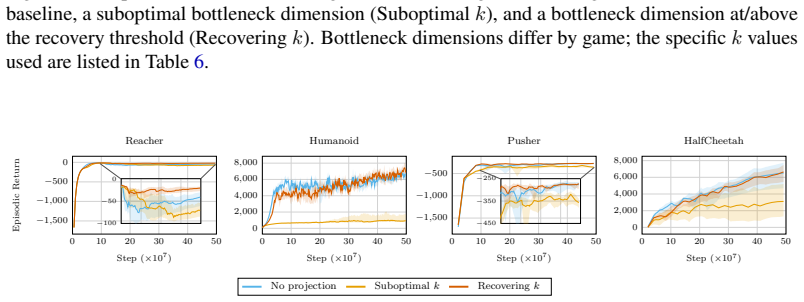
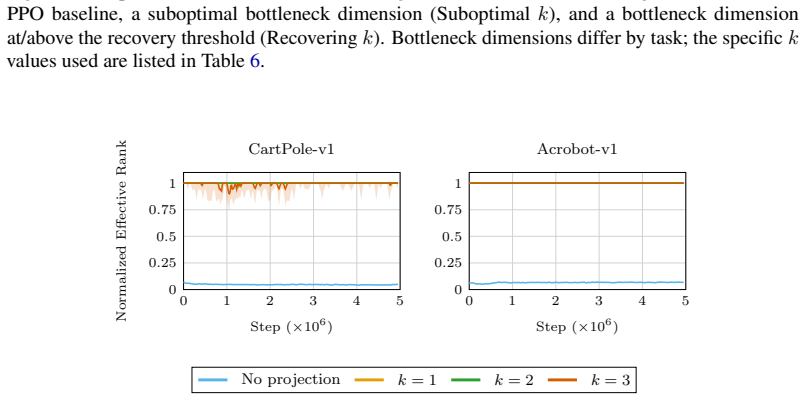
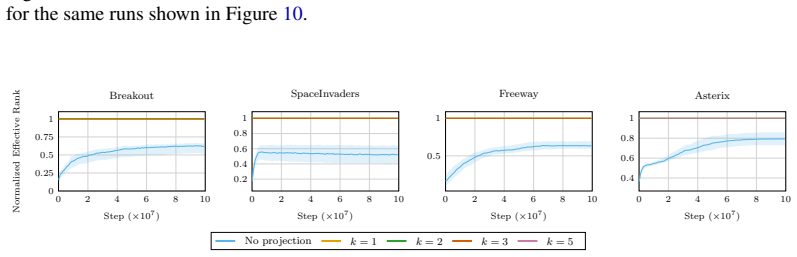
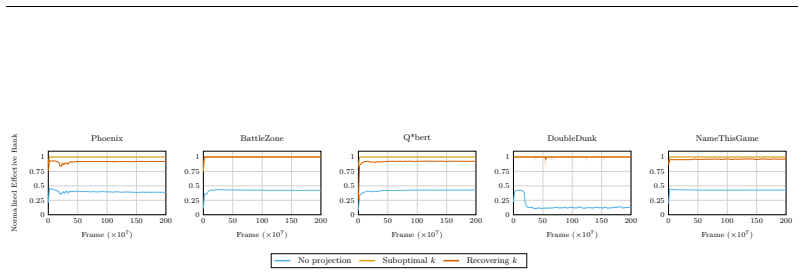
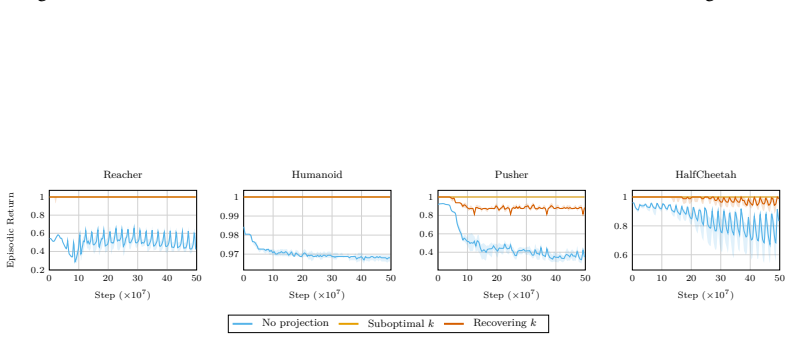
read the original abstract
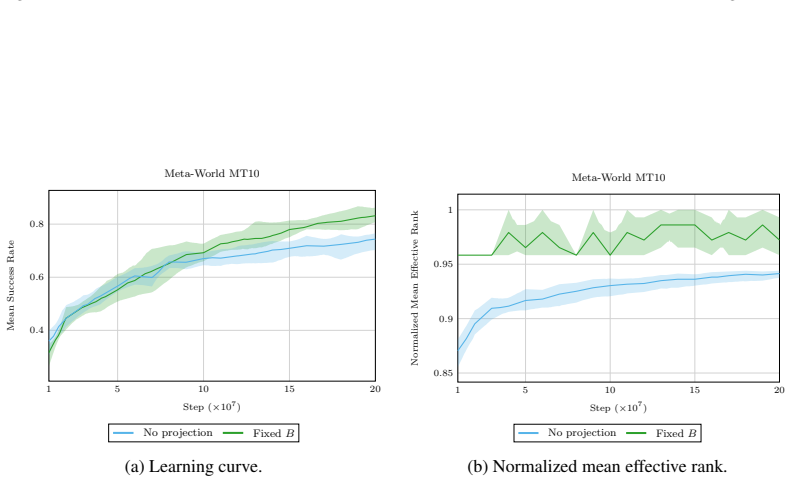
Deep reinforcement learning (RL) agents commonly rely on high-dimensional neural representations, despite growing evidence that task-relevant value and policy structure may be intrinsically low-dimensional. In this work, we present a simple yet effective representation-level prior that inserts a fixed orthonormal projection to constrain encoder features to a low-dimensional subspace, requiring no auxiliary objectives, pretraining, or changes to the underlying RL algorithm. Under a linear realizability assumption, we prove that when the bottleneck dimension exceeds the intrinsic rank of the optimal value function in feature space, the bottleneck preserves expressivity and leaves the induced gradient dynamics unchanged up to an equivalent low-dimensional parameterization. Empirically, we find that across both single and multi-task benchmarks, baseline performance is either matched or improved once the bottleneck dimension exceeds a small task-dependent threshold; in many cases, value representations can be compressed to extremely low dimensions without loss, and the minimal sufficient dimension depends far more on environment complexity than encoder width. In addition, we analyze representation geometry and find that orthogonal bottlenecks stabilize feature norms and are associated with higher effective rank. Together, these results support a representation-space interpretation of the manifold hypothesis in reinforcement learning and position orthogonal bottlenecks as a lightweight, architecture-agnostic mechanism for shaping RL representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes inserting a fixed orthonormal projection (orthogonal bottleneck) as a representation-level prior into RL encoders to constrain features to a low-dimensional subspace without auxiliary losses or algorithm changes. Under a linear realizability assumption on the optimal value function, it proves that when the bottleneck dimension exceeds the intrinsic rank of V* in feature space, expressivity is preserved and gradient dynamics remain unchanged up to an equivalent low-dimensional reparameterization. Empirically, across single- and multi-task RL benchmarks, baseline performance is matched or improved once the bottleneck dimension exceeds a small task-dependent threshold, with value representations compressible to very low dimensions; additional analysis shows the bottlenecks stabilize feature norms and increase effective rank.
Significance. If the linear realizability assumption holds, the result supplies a simple, architecture-agnostic mechanism for enforcing the manifold hypothesis in RL representations and yields a clean theoretical guarantee on expressivity and dynamics. The empirical observation that minimal sufficient dimension depends more on environment complexity than encoder width is potentially useful for practical design. The work is strengthened by its parameter-free nature and lack of extra objectives, but the explanatory link between the conditional theory and the reported robustness is weakened by the absence of any verification that the assumption approximately holds for the trained deep encoders.
major comments (2)
- [§3] §3 (theoretical guarantee): the claim that the bottleneck 'leaves the induced gradient dynamics unchanged up to an equivalent low-dimensional parameterization' is conditioned on the linear realizability assumption that V* is exactly linear in the encoder features ϕ; this assumption is invoked for the guarantee but the manuscript supplies no diagnostic (e.g., residual of the linear fit or rank of the value matrix) to check whether it holds even approximately for the deep-network encoders used in the experiments.
- [§5] §5 (empirical evaluation): performance claims that 'baseline performance is either matched or improved' and that 'value representations can be compressed to extremely low dimensions without loss' are presented as summary statements without reported error bars, number of random seeds, dataset sizes, or statistical tests, making it impossible to assess whether the observed robustness to small bottleneck dimensions is reliable or could be explained by mechanisms other than the stated theory.
minor comments (2)
- Notation for the orthonormal projection matrix and the intrinsic rank of V* should be introduced with a single consistent symbol set in the theory section before being used in the experiments.
- Figure captions for the representation-geometry plots should explicitly state the number of environments and seeds averaged.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (theoretical guarantee): the claim that the bottleneck 'leaves the induced gradient dynamics unchanged up to an equivalent low-dimensional parameterization' is conditioned on the linear realizability assumption that V* is exactly linear in the encoder features ϕ; this assumption is invoked for the guarantee but the manuscript supplies no diagnostic (e.g., residual of the linear fit or rank of the value matrix) to check whether it holds even approximately for the deep-network encoders used in the experiments.
Authors: We agree that the theoretical guarantee is conditioned on linear realizability and that the manuscript would be strengthened by empirical diagnostics assessing how well the assumption holds approximately for the trained encoders. In the revision we will add an appendix that reports the effective rank of the value function in feature space together with the residual of the linear fit on representative tasks. revision: yes
-
Referee: [§5] §5 (empirical evaluation): performance claims that 'baseline performance is either matched or improved' and that 'value representations can be compressed to extremely low dimensions without loss' are presented as summary statements without reported error bars, number of random seeds, dataset sizes, or statistical tests, making it impossible to assess whether the observed robustness to small bottleneck dimensions is reliable or could be explained by mechanisms other than the stated theory.
Authors: We acknowledge that the empirical section would benefit from fuller statistical reporting. In the revised manuscript we will report error bars over five random seeds, specify evaluation episode counts, and include statistical tests supporting the performance claims. revision: yes
Circularity Check
No circularity; central claim conditioned on external linear realizability assumption
full rationale
The paper's theoretical guarantee is explicitly stated as holding 'under a linear realizability assumption' that the optimal value function is linear in the encoder features. This is an external modeling assumption invoked to prove preservation of expressivity, not a quantity defined or fitted inside the paper's own equations. No self-citations, fitted inputs renamed as predictions, or self-definitional reductions appear in the abstract or described derivation chain. The empirical sections are presented as separate validation and do not feed back into the proof. The derivation chain is therefore self-contained against the stated assumption.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear realizability assumption: the optimal value function is linear in the encoder features.
Reference graph
Works this paper leans on
-
[1]
URL https://proceedings.mlr.press/v80/chen18i.html. ISSN: 2640- 3498. Simon S. Du, Sham M. Kakade, Ruosong Wang, and Lin F. Yang. Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?, February 2020. URL http://arxiv.org/ abs/1910.03016. arXiv:1910.03016 [cs]. Ayoub Echchahed and Pablo Samuel Castro. A Survey of State Representa...
-
[2]
Plasticity Loss in Deep Reinforcement Learning: A Survey
ISBN 978-0-8218-5030-5 978-0-8218-7611-4. DOI: 10.1090/conm/026/737400. URL http://www.ams.org/conm/026/. 12 Timo Klein, Lukas Miklautz, Kevin Sidak, Claudia Plant, and Sebastian Tschiatschek. Plasticity Loss in Deep Reinforcement Learning: A Survey, November 2024. URL http://arxiv.org/ abs/2411.04832. arXiv:2411.04832 [cs]. Aviral Kumar, Rishabh Agarwal,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1090/conm/026/737400 2024
-
[3]
Tor Lattimore, Csaba Szepesvari, and Gellert Weisz
URL https://proceedings.neurips.cc/paper_files/paper/2022/ hash/debf482a7dbdc401f9052dbe15702837-Abstract-Conference.html. Tor Lattimore, Csaba Szepesvari, and Gellert Weisz. Learning with Good Feature Representations in Bandits and in RL with a Generative Model. InProceedings of the 37th International Conference on Machine Learning, pp. 5662–5670. PMLR, ...
-
[4]
Representational sufficiency.There exist encoder parameters and head parameters θ⋆ such that the network s7→H B⊤z(s);θ ⋆ exactly realizesV ⋆(s)for alls∈ S
-
[5]
Training (θ, W) by gradient descent on loss L evolves At identically to training the direct parameterizationh=Cϕ(s)on(θ, C), givenC 0 =A 0
Trainability:Let W∈R D×D be the encoder’s final layer and At =B ⊤Wt the composite feature-to-bottleneck map. Training (θ, W) by gradient descent on loss L evolves At identically to training the direct parameterizationh=Cϕ(s)on(θ, C), givenC 0 =A 0. Proof. For general notation, fix a feature map ϕ:S →R D as in Assumption 3.1. We focus on the last linear la...
-
[6]
The key point is thatΘ ⋆ has rankrand we assumek≥r
Representational sufficiency We will explicitly construct parameters(W ⋆, θ⋆)such that for alls, H B⊤W ⋆ϕ(s);θ ⋆ = Θ⋆ϕ(s) =V ⋆(s). The key point is thatΘ ⋆ has rankrand we assumek≥r. SinceΘ ⋆ ∈R m×D has rankr, it admits a singular value decomposition Θ⋆ =U rΣrV ⊤ r , where •U r ∈R m×r has orthonormal columns (U ⊤ r Ur =I r), •Σ r ∈R r×r is diagonal with s...
-
[7]
Consider an arbitrary (differentiable) training objective L computed from the head output
Trainability We now prove that training (θ, W) with the orthogonal bottleneck induces the same gradient de- scent dynamics on the composite map At =B ⊤Wt as training a direct bottleneck map Ct in the parameterizationh=Cϕ(s), providedC 0 =A 0. Consider an arbitrary (differentiable) training objective L computed from the head output. For example, L can be a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.